一、引言
随着企业业务的不断增长,日志管理成为了系统运维中不可或缺的一部分。ELK(Elasticsearch、Logstash、Kibana)作为一套开源的日志管理系统,以其高效、灵活、可扩展的特性,成为了众多企业的首选。本文将详细介绍如何搭建一套完整的ELK日志管理系统。
二、环境准备
- 准备至少一台Linux服务器(或者虚拟机),用于部署ELK组件。
- 确保服务器有足够的磁盘空间和网络带宽。
- 确保服务器已经安装好docker容器
三、Elasticsearch部署
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。
1. 版本选择
| 类型/版本 | 6.x | 7.x | 8.x | 建议 |
|---|---|---|---|---|
| Licence | Apache 2.0 | 7.0~7.10 Apache 2.07.11++ SSPL | SSPL | 建议选择更友好的Apache2.0版本,SSPL协议对于想要让ES做为PAAS对外提供服务的话,将会面临es厂商的限制 |
| 云厂商支持程度 | 腾讯、阿里云均支持,华为不支持 | 腾讯云最高版 7.10.x阿里云7.10.x,7.16.x华为云7.6.x,7.10.x | 均不支持 | 各云厂商也主要在推广7.x版本,稳定性及占用率更高 |
| 发版时间 | 2016 | 2019 | 2021 | 建议选择7.x版本,经历将近4年,稳定性已经经过验证,6.x和8.x一个太老一个太新 |
| 特性差异 | / | 集群配置简化,master选举进行了优化,能够避免集群脑裂Q问题;索引创建只 已经去除了type,更加简化;索引查询算法升级,查询性能有优化;提供安全策略;Kibana更轻量化,更易用; | ES API进行了升级方便后续升级使用更加安全,es默认开启了一些安全功能;新的搜索API特性比如支持NLP等; | 7.x基本也能满足目前需求,稳定性也更有保障 |
| SpringBoot兼容 | 2.1~2.2版本对6.x支持 | 2.3~2.7版本对7.x支持 | / | 看框架选择 |
博主这里使用 7.x 版本中的 7.10.1版本做演示
2. ES镜像部署
- ES镜像拉取 docker镜像地址
docker pull elasticsearch:7.10.1
- 修改JVM堆大小
默认情况下,Elasticsearch的JVM使用的堆大小为2GB,可以修改ES的jvm默认参数
find /var/lib/docker/overlay2/ -name jvm.options
修改jvm配置,根据服务器配置修改合适大小
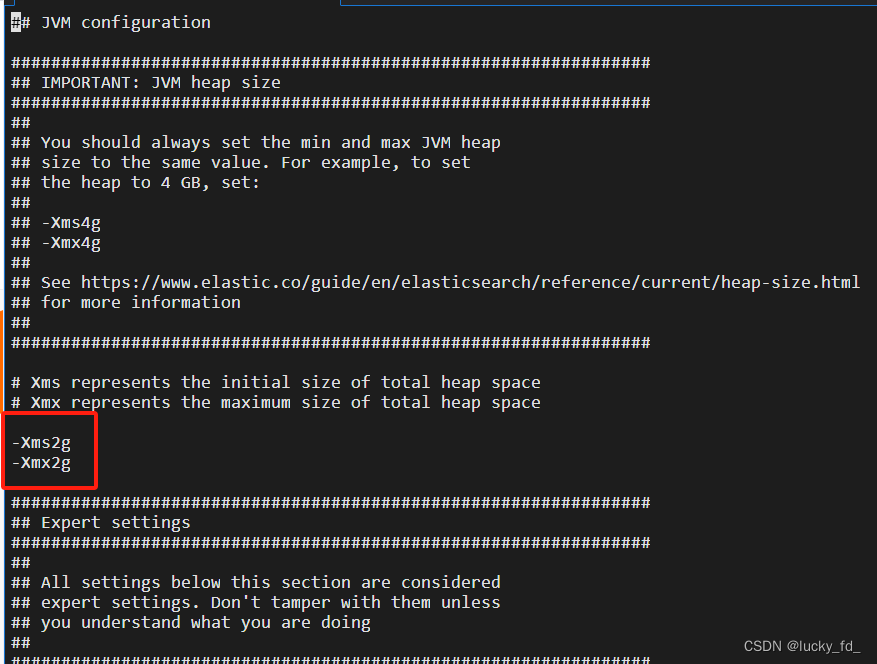
-Xms2g 改为 -Xms1g
-Xmx2g 改为 -Xmx1g
- 调整vm.max_map_count大小
这是一个设置内核参数的语法,vm.max_map_count 是内核参数的名称。它用于控制单个进程能够拥有的虚拟内存区域(即映射区域)的最大数量。
Elasticsearch使用了大量的内存映射文件来存储数据索引和缓存。为了保证Elasticsearch正常运行,在某些操作系统中需要增加 vm.max_map_count 的值。
通过将该参数设置为较大的值(例如262144),可以确保操作系统能够提供足够的虚拟内存区域供Elasticsearch使用,从而避免潜在的性能问题或错误。
vim /etc/sysctl.conf
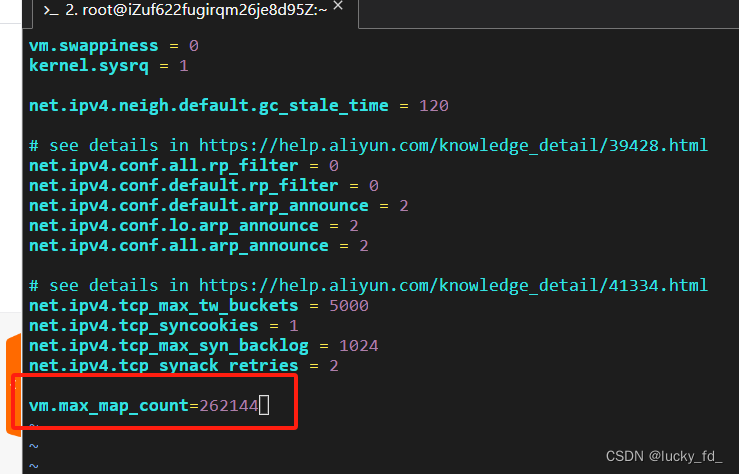
保存退出,查看配置是否生效
sysctl -p
- 创建es容器挂载目录
mkdir -p data config plugins
[fd@localhost es]$ mkdir -p data config
[fd@localhost es]$ ll
总用量 8.0K
drwxr-xr-x. 2 fd fd 4.0K 6月 14 21:15 config
drwxr-xr-x. 2 fd fd 4.0K 6月 14 21:15 data
- 部署单点es,创建es容器
docker run -d \
--restart=always \
--name elasticsearch \
--network elk-net \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-v /home/fd/dockerApp/es/data:/usr/share/elasticsearch/data \
-v /home/fd/dockerApp/es/plugins:/usr/share/elasticsearch/plugins \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms1024m -Xmx1024m" \
elasticsearch:7.10.1
命令解释:
-e “cluster.name=es-docker-cluster”:设置集群名称
-e “http.host=0.0.0.0”:监听的地址,可以外网访问
-e “ES_JAVA_OPTS=-Xms512m -Xmx512m”:分配内存大小
-e “discovery.type=single-node”:单节点模式
-v /home/fd/dockerApp/es/data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录
-v es-logs:/usr/local/elasticsearch7.12.1/logs:挂载逻辑卷,绑定es的日志目录
-v /home/fd/dockerApp/es/plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录
–privileged:授予逻辑卷访问权
–network elk-net :加入一个名为elk-net的网络中
-p 9200:9200:端口映射配置
容器运行后,复制配置文件到服务器
docker cp es:/usr/share/elasticsearch/config/elasticsearch.yml ./config/elasticsearch.yml
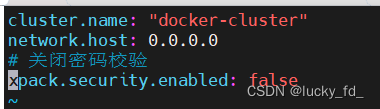
修改elasticsearch.yml配置
cluster.name: "docker-cluster"
network.host: 0.0.0.0
# 关闭密码校验
xpack.security.enabled: false
# 是否支持跨域,默认为false
http.cors.enabled: true
# 当设置允许跨域,默认为*,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使用正则表达式。比如只允许本地地址。 /https?:\/\/localhost(:[0-9]+)?/
http.cors.allow-origin: "*"
-
关闭密码验证
文件最后添加xpack.security.enabled: false关闭 密码安全验证
-
设置跨域访问
当设置允许跨域,默认为*,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使用正则表达式。比如只允许本地地址。 /https?😕/localhost(:[0-9]+)?/
http.cors.allow-origin: “*”

配置文件参数解释,根据需要添加
cluster.name: elasticsearch-cluster
# 节点名称
node.name: elasticsearch-node1
# # 绑定host,0.0.0.0代表当前节点的ip
network.host: 0.0.0.0
# # 设置其它节点和该节点交互的ip地址,如果不设置它会自动判断,值必须是个真实的ip地址(本机ip),因为我使用的是docker启动,不是简单127.0.0.1,要查看具体分配的ip
network.publish_host: 172.18.0.2
# # 设置对外服务的http端口,默认为9200
http.port: 9200
# # 设置节点间交互的tcp端口,默认是9300
transport.tcp.port: 9300
# 是否支持跨域,默认为false
http.cors.enabled: true
# 当设置允许跨域,默认为*,表示支持所有域名,如果我们只是允许某些网站能访问,那么可以使用正则表达式。比如只允许本地地址。 /https?:\/\/localhost(:[0-9]+)?/
http.cors.allow-origin: "*"
# # 表示这个节点是否可以充当主节点
node.master: true
# # 是否充当数据节点
node.data: true
# # 所有主从节点ip:port
discovery.seed_hosts: ["172.18.0.2:9300"]
# # 这个参数决定了在选主过程中需要 有多少个节点通信 预防脑裂
discovery.zen.minimum_master_nodes: 1
# 跨域允许设置的头信息,默认为X-Requested-With,Content-Type,Content-Lengt
http.cors.allow-headers: Authorization
# 这条配置表示开启xpack认证机制,使用密码登录
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
重新运行容器
docker run -d \
--restart=always \
--name elasticsearch \
--network elk-net \
-p 9200:9200 \
-p 9300:9300 \
--privileged \
-v /home/fd/dockerApp/es/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/fd/dockerApp/es/data:/usr/share/elasticsearch/data \
-v /home/fd/dockerApp/es/plugins:/usr/share/elasticsearch/plugins \
-v /etc/localtime:/etc/localtime:ro \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms1024m -Xmx1024m" \
elasticsearch:7.10.1
- 测试elasticsearch
访问服务器地址+端口号,前面配置Elasticsearch 的端口号为:9200

- 配置es密码(看需求)
为什么要配置X-Pack,外网裸奔这么刺激容易被攻击。正式环境建议内网访问、内网访问、内网访问
打开 elasticsearch.yml文件,在最后增加如下参数
# 开启xpack密码认证机制
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true
接着进入容器中
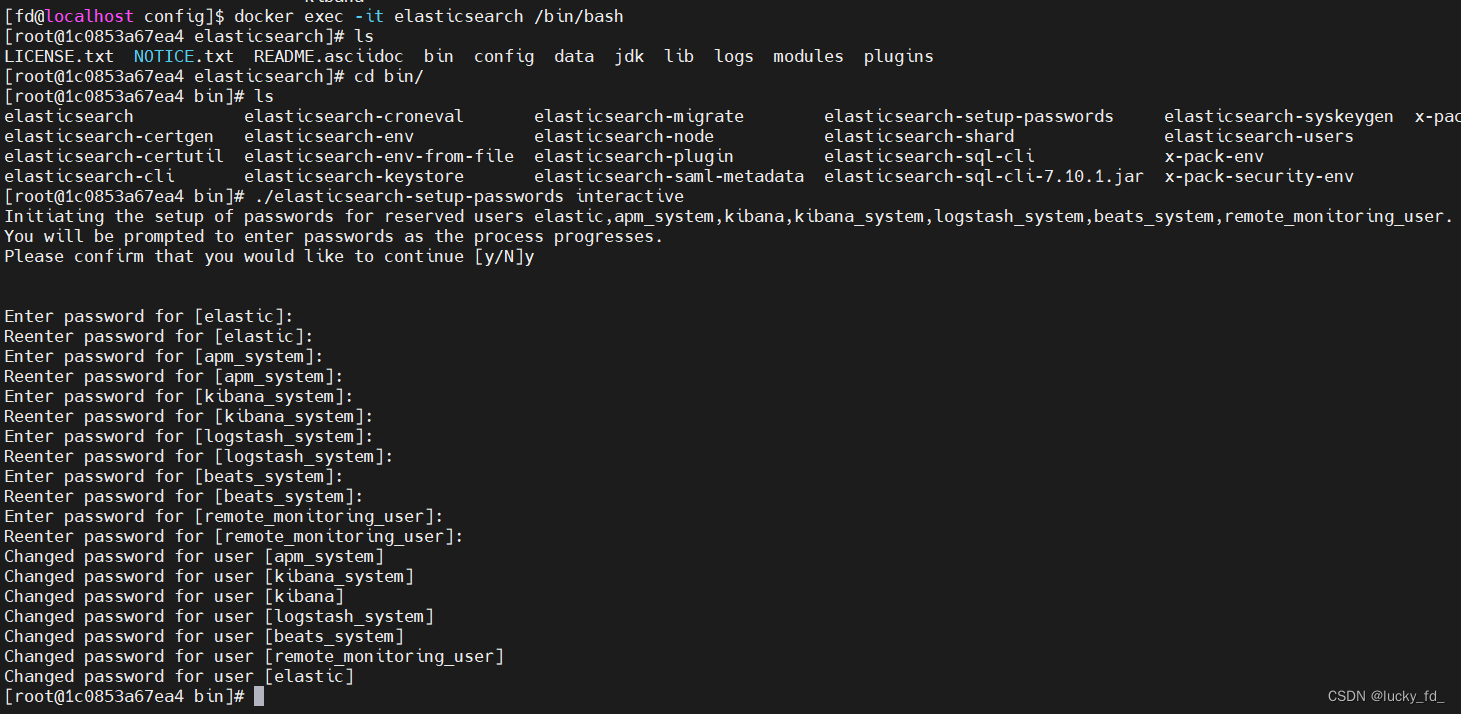
docker exec -it elasticsearch /bin/bash
到/usr/share/elasticsearch/bin目录执行
./elasticsearch-setup-passwords interactive
重启服务,访问如下便成功:
四、Kibana部署
Kibana是一个用于可视化Elasticsearch中数据的工具,使你能够轻松地创建和分享动态仪表板。安装Kibana如下:
- Kibana镜像拉取 docker镜像
docker pull kibana:7.10.1
- 创建挂载点目录
mkdir -p config data
[fd@localhost kibana]$ pwd
/home/fd/dockerApp/kibana
[fd@localhost kibana]$ ll
总用量 8.0K
drwxr-xr-x. 2 fd fd 4.0K 6月 17 11:15 config
drwxr-xr-x. 2 fd fd 4.0K 6月 17 11:15 data
- 创建容器
docker run -d \
--restart=always \
--name kibana \
--network elk-net \
-p 5601:5601 \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
kibana:7.10.1
复制配置文件到挂载目录
docker cp kibana:/usr/share/kibana/config/kibana.yml kibana.yml
#
# ** THIS IS AN AUTO-GENERATED FILE **
#
# Default Kibana configuration for docker target
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://elasticsearch:9200" ]
monitoring.ui.container.elasticsearch.enabled: true
# 语言
i18n.locale: "zh-CN"
编辑配置文件
server.name: kibana
# kibana的主机地址 0.0.0.0可表示监听所有IP
server.host: "0.0.0.0"
# kibana访问es的URL
elasticsearch.hosts: [ "http://192.168.253.10:9200" ]
#这里是在elasticsearch设置密码时的值,没有密码可不配置
elasticsearch.username: 'elastic'
elasticsearch.password: '**************'
# # 显示登陆页面
xpack.monitoring.ui.container.elasticsearch.enabled: true
# 语言配置中文
i18n.locale: "zh-CN"
重启容器
docker run -d \
--restart=always \
--name kibana \
--network elk-net \
-p 5601:5601 \
-e ELASTICSEARCH_HOSTS=http://elasticsearch:9200 \
-v /home/fd/dockerApp/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml \
kibana:7.10.1
- 测试Kibana是否安装成功
访问服务器地址+端口号,前面配置Kibana 的端口号为:5601
例如:http://192.168.253.10:5601
五、Logstash部署
Logstash是一个用于日志数据的集中收集、处理和传输的工具。
- Logstash镜像拉取 docker镜像
docker pull logstash:7.10.1
- 启动容器,创建挂载目录
docker run -d --name=logstash logstash:7.10.1
mkdir -p logstash/config
复制容器内配置文件到挂载目录
docker cp logstash:/usr/share/logstash/config/logstash.yml /home/fd/dockerApp/logstash/config/logstash.yml
编辑logstash.yml如下
http.host: "0.0.0.0"
#根据实际修改es的ip:port
xpack.monitoring.elasticsearch.hosts: [ "http://elasticsearch:9200" ]
# 主管道的Logstash配置路径,如果指定目录或通配符,配置文件将按字母顺序从目录中读取
# path.config: /usr/share/logstash/config/*.conf
path.config: /usr/share/logstash/config/logstash.conf
#Logstash将其日志写到的目录
path.logs: /usr/share/logstash/logs
创建配置文件logstash.conf,配置日志收集功能,logstash.conf的路径要和上面配置的路径对应
vim logstash.conf
input {
# 读取文件数据
file {
#采集点(这里一定要注意,由于我是docker启动的logstash,这里是容器内的文件,如果要生成外面日志索引,那么文件的路径一定要挂载正确)
path => ["/usr/share/logstash/file/*.log"]
#从文件的开头开始读取,也可以选择'end'从文件末尾开始读取
start_position => "beginning"
#扫描间隔时间,默认是1s,建议5s
stat_interval => "5"
# sincedb文件路径,用于记录读取位置,确保在Logstash重启后不会重复读取数据,
# 该路径必须指定到文件不能指定到文件的目录 ,不指定会默认创建
# sincedb_path => "/usr/share/logstash/file/sincedb.txt"
# 利用linux黑洞可以达到每次重头读取日志文件
sincedb_path => "/dev/null"
}
}
output {
elasticsearch {
#集群的话,直接添加多个url
hosts => ["192.168.253.10:9200"]
#es的用户名和密码(无密码则不需要)
#user =>"elastic"
#password =>"elastic"
#建立的索引以日期区分
index => "logstash-log-%{+YYYY.MM.dd}"
}
#在控制台输出logstash的日志
stdout { codec=> rubydebug }
}
Logstash是以管道方式运行的,一个Logstash实例可以启动多个管道。每个管道包含输入(input),输出(output),过滤器(filter)三个部分,这种结构同时也体现在.conf配置文件上
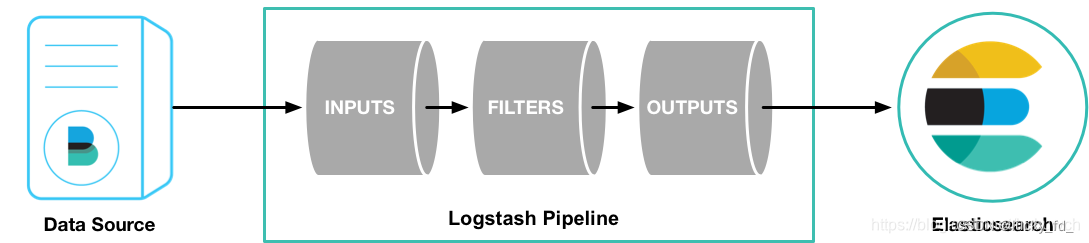 注:图片来自网络
注:图片来自网络
配置文件示例
Logstash.conf 配置文件示例,从filebeat读取数据
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
#集群的话,直接添加多个url
hosts => ["elasticsearch:9200"]
#建立的索引以日期区分
index => "logstash-log-%{+YYYY.MM.dd}"
}
#在控制台输出logstash的日志
stdout { codec=> rubydebug }
}
从日志文件读取数据
# Logstash.conf 配置文件示例
input {
# 定义一个file类型的输入插件
file {
# 指定要监控的日志文件路径
path => "/var/log/myapp/mylog.log"
# 指定从文件的哪个位置开始读取
start_position => "beginning"
# 是否启用sincedb(记录文件读取位置的文件)
sincedb_path => "/dev/null"
# 读取文件的类型,这里假设是plain文本
codec => "plain"
# 添加一些额外的字段
add_field => { "type" => "mylog" }
}
}
filter {
# 定义一个grok类型的过滤器插件
grok {
# 定义匹配模式
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:loglevel} %{GREEDYDATA:message}" }
# 如果匹配成功,则添加tag
add_tag => [ "grok_success" ]
}
# 定义一个date类型的过滤器插件,用于解析时间戳
date {
# 指定时间戳字段
match => [ "timestamp", "ISO8601" ]
# 设置目标字段
target => "@timestamp"
}
# 其他可能的过滤器插件,如mutate、json等
# ...
}
output {
# 定义一个elasticsearch类型的输出插件
elasticsearch {
# Elasticsearch集群的主机地址和端口
hosts => ["localhost:9200"]
# 索引名称
index => "mylog-%{+YYYY.MM.dd}"
# 如果需要,可以配置其他参数,如user、password等
# ...
}
# 其他可能的输出插件,如stdout、file、kafka等
# ...
}
启动logstash容器
docker run -d \
--name logstash \
-p 9600:9600 \
-p 5044:5044 \
--network elk-net \
-v /home/fd/dockerApp/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml \
-v /home/fd/dockerApp/logstash/config/logstash.conf:/usr/share/logstash/config/logstash.conf \
-v /home/fd/dockerApp/logstash/logFile:/usr/share/logstash/logFile \
logstash:7.10.1
- Logstash的监控API默认使用9600端口。通过映射这个端口,你可以使用HTTP接口来监控Logstash的状态、配置和管理。
- Logstash的Beats输入插件(如Filebeat、Metricbeat等)默认使用5044端口来接收通过TCP协议发送的数据。
启动成功,读取日志数据并输出到控制台
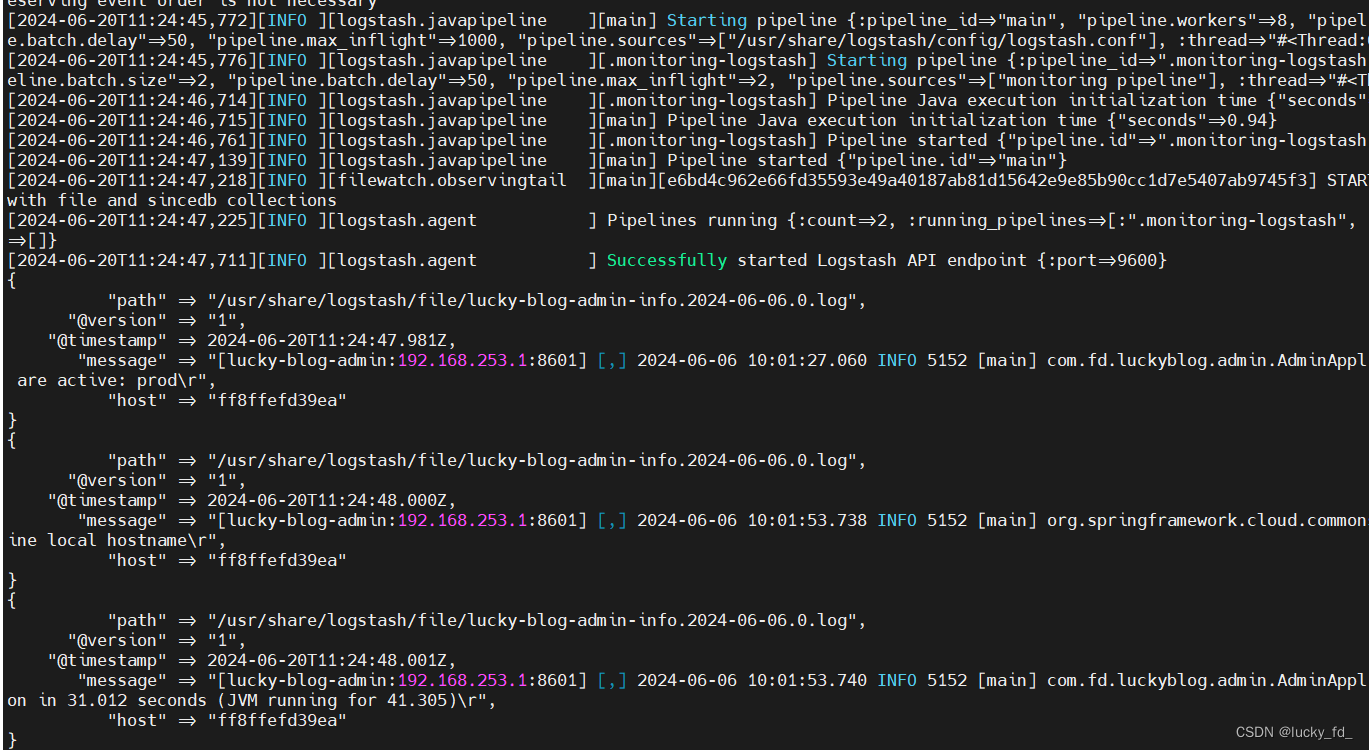
启动完成后,会占用9600端口~,同时经过logstash的数据都会发送到ElasticSearch中
六、Filebeat部署
Filebeat是Elasticsearch公司提供的一个轻量级日志收集器,用于从各种源(例如日志文件、系统日志等)抓取数据,并将其传输到Elasticsearch或Logstash等数据处理和分析工具。Filebeat的轻量级特性使其适用于各种规模的环境,并且与Elastic Stack(如Elasticsearch、Logstash和Kibana)的其他组件集成紧密,提供了一个强大的日志分析解决方案。
- 下载filebeat Download Filebeat
我们首先需要下载到我们应用所在服务器中。
#进入到filebeat目录
cd /soft/beats/filebeat
查看我们的配置文件filebeat.yml
# Filebeat配置文件示例
filebeat.inputs:
- type: log # 指定输入类型为日志
# 指定要收集的日志文件的路径
paths:
- /var/log/java/test-java.log
- /var/log/java/*.log
- /var/log/*/*.log
# 可选字段,用于向输出添加额外的信息
fields:
log_topic: java_log
# 多行日志配置
multiline.pattern: '^\[' # 匹配以"["开头的行作为多行日志的开始
multiline.negate: true
multiline.match: after # 将匹配到的行与之前的行合并
# 启用此输入
enabled: true
setup.template.settings:
index.number_of_shards: 1
# Filebeat输出配置
output.logstash:
# Logstash的主机地址和端口
hosts: ["localhost:5044"]
# 其他可选配置(如Elasticsearch输出、Kafka输出等)
# output.elasticsearch:
# hosts: ["localhost:9200"]
# 如果需要,可以配置Filebeat的其他参数,如日志级别、队列大小等
# logging.level: info
# queue.mem.events: 4096
# ... 其他可能的配置参数 ...
配置文件关键点解释:
1.filebeat.inputs:定义Filebeat的输入源,即要监视的日志文件或位置。可以定义多个输入源,每个输入源可以指定不同的路径、解析规则等。
2.type:输入类型,对于日志文件,通常使用log。
3.paths:指定要收集的日志文件的路径。可以使用通配符来匹配多个文件。
4.fields:可选字段,用于向输出添加额外的信息。这些信息可以在输出时用于过滤、路由或标记日志。
5.multiline:用于处理多行日志的配置。通过指定模式、否定和匹配选项,可以将多行日志合并为一个事件。
6.enabled:启用或禁用此输入源。
7.output:定义Filebeat的输出目标。在示例中,日志数据被发送到Logstash进行进一步处理。但也可以配置为直接发送到Elasticsearch或其他支持的目标。
8.hosts:指定输出目标的主机地址和端口。
启动我们的filebeat
# 前台启动
./filebeat -e -c filebeat.yml
# 后台启动
#!/bin/bash
nohup ./filebeat -e -c filebeat.yml > catalina.out 2>&1 &
启动完成后,我们能够看到日志文件已经被加载。
Logstash和Filebeat在日志收集和分析领域各自扮演着不同的角色:
1.功能定位:
- Logstash:作为一个开源数据收集引擎,Logstash具有实时管道功能,能够动态地将来自不同数据源的数据统一起来,并进行数据标准化。它主要侧重于数据的集中、转换和存储,可以同时从多个数据源获取数据,并对其进行转换,然后发送到目的地。
- Filebeat:Filebeat是一个轻量级的日志数据收集器,主要用于将日志数据从服务器发送到中央日志存储或分析系统。它是Elastic Stack(Elasticsearch、Logstash、Kibana)中的一部分,专注于实时收集和发送日志数据,确保数据的及时性。
2.性能与资源消耗:
- Logstash:尽管Logstash在性能方面已有显著提升,但与替代方案相比,如Filebeat,它在大数据量的情况下可能会表现出更高的资源消耗和相对较慢的性能。Logstash的默认堆大小是1GB,这在大规模部署中可能成为一个考虑因素。
- Filebeat:Filebeat占用资源较少,是一个轻量级的代理,易于部署和管理。由于其简单性,它几乎没有可以出错的地方,因此具有很高的可靠性。
3.使用场景:
- Logstash:Logstash适用于需要强大数据处理和转换能力的场景。它提供了丰富的过滤器插件,可以实时解析和转换数据,不受格式或复杂度的影响。Logstash还支持多种输入和输出插件,可以与各种数据源和存储系统集成。
- Filebeat:Filebeat更适用于实时日志收集和传输的场景。它可以轻松地从服务器上的各种日志源(如日志文件、系统日志等)收集数据,并实时发送到指定的目的地。由于其轻量级和高效性,Filebeat特别适合在分布式系统中进行日志收集。
4.优势与劣势:
- Logstash:优势在于其强大的数据处理和转换能力,以及丰富的插件生态系统。劣势在于性能和资源消耗相对较高,可能不适用于所有场景。
- Filebeat:优势在于其轻量级、高效和可靠性,特别适用于实时日志收集。劣势在于功能相对较为单一,主要关注于数据的收集和传输。
综上所述,Logstash和Filebeat在日志收集和分析领域各自具有独特的功能和优势。Logstash更适合用于需要强大数据处理能力的场景,而Filebeat则更擅长于实时日志收集和传输。因此,Logstash不能完全取代Filebeat的作用,两者可以根据实际需求进行配合使用。
filebeat+logstash日志采集场景
filebeat配置(filebeat.yml)
展示如何使用 Logstash 和 Filebeat 来捕获日志,并将日志的某个特定字段(例如 log_id)作为 Elasticsearch 中的 _id:
filebeat.inputs:
- type: log
enabled: true
paths:
- /path/to/your/logfile.log
fields:
log_source: myapp
fields_under_root: true
json.keys_under_root: true # 如果你的日志是 JSON 格式的,并且你想要将其字段置于根级别
output.logstash:
hosts: ["localhost:5044"]
注意:在上面的配置中,我们添加了一个自定义字段 log_source,但它并不是我们想要用作 Elasticsearch
_id 的字段。在实际场景中,你可能有一个像 log_id 这样的字段。
Logstash 配置 (logstash.conf)
如果你的日志中确实有一个 log_id 字段,并且你希望将其用作 Elasticsearch 的 _id,你可以在 Logstash 的配置文件中通过 mutate 过滤器来添加或覆盖 @metadata[_id] 字段:
input {
beats {
port => 5044
}
}
filter {
if [log_id] {
mutate {
add_field => { "[@metadata][_id]" => "%{[log_id]}" }
}
}
# ... 其他可能的过滤器配置 ...
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "logstash-%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_id => "%{[@metadata][_id]}"
}
}
if [log_id] 条件来判断日志事件中是否存在 log_id 字段。如果存在,我们就使用 mutate 过滤器来添加一个名为 [@metadata][_id] 的新字段,并将其值设置为 log_id 字段的值。然后,在 Elasticsearch 输出中,我们使用 document_id => “%{[@metadata][_id]}” 来指定 Elasticsearch 文档的 _id 字段的值。
请注意,如果日志中没有 log_id 字段,或者该字段的值为空或不存在,那么 Elasticsearch 将会为文档生成一个随机的 _id。如果你希望在没有 log_id 的情况下使用其他策略(例如使用 Logstash 的内建 UUID 生成器),你可以在 Logstash 配置中进行相应的调整。




![【代码随想录】【算法训练营】【第44天】 [322]零钱兑换 [279]完全平方数 [139]单词拆分](https://img-blog.csdnimg.cn/direct/a980dc5b27414e33bc36127d485a11ee.png)