目录
一、说明
二、什么是强化学习?
三、监督学习、无监督学习和强化学习之间的区别。
四、强化学习中使用的术语。
五、强化学习中的智能体-环境交互:一个迷宫示例。
六、贝尔曼方程。
七、马尔可夫决策过程 (MDP)
八、马尔可夫决策过程 (MDP) 的代码实现
九、代码说明
十、什么是Q Learning?
10.1 Q 学习
19.2 Q 学习说明:
十一、结论
关键要点:
一、说明
在我今天的中等帖子中,我将教您如何实现 Q-Learning 算法。但在此之前,我将首先解释 Q-Learning 背后的想法及其局限性。请务必具备一些强化学习 (RL) 基础知识。否则,请查看我之前关于 RL 背后的直觉和关键数学的文章。
二、什么是强化学习?
强化学习 (RL) 是一种机器学习 (ML) 技术,用于训练软件做出决策以实现最佳结果。它模仿了人类用来实现目标的试错学习过程。RL 算法在处理数据时使用奖励和惩罚范式。他们从每个动作的反馈中学习,并自行发现最佳处理路径,以实现最终结果。RL 是一种强大的方法,可帮助人工智能 (AI) 系统在看不见的环境中实现最佳结果。(来源:AWS)

强化学习框图
为了更好地理解强化学习,请考虑一只我们必须训练的狗。在这里,狗是代理人,房子是环境。

存在于其环境中的代理(狗)
我们可以通过提供狗饼干等奖励来让狗执行各种动作。

授予代理执行正确操作的奖励
狗会遵循一项政策来最大化它的奖励,因此会遵循每一个命令,甚至可能自己学习一个新的动作,比如乞讨。狗也会想跑来跑去,玩耍和探索它的环境。模型的这种质量称为探索。狗最大化奖励的倾向称为剥削。勘探和开发之间总是存在权衡取舍,因为勘探行动可能会导致较少的回报。

特工因做错事而受到处罚
三、监督学习、无监督学习和强化学习之间的区别。

描述监督学习、无监督学习和强化学习之间基本区别的表格
四、强化学习中使用的术语。
代理():一个可以感知/探索环境并对其采取行动的实体。
环境():代理在场或被包围的情况。在RL中,我们假设随机环境,这意味着它本质上是随机的。
操作():操作是代理在环境中执行的移动。
状态():状态是代理执行每次操作后环境返回的情况。
奖励():从环境返回给代理的反馈,用于评估代理的操作。
策略():策略是代理根据当前状态为下一步操作应用的策略。
值():预期长期回报与贴现因子相反,与短期回报相反。
Q 值():它与该值基本相似,但它需要一个附加参数作为当前操作 (a)。(来源:Javatpoint)
五、强化学习中的智能体-环境交互:一个迷宫示例。
想象一个迷宫环境,一个机器人特工试图找到宝藏,在这种情况下,让我们假设它是一颗钻石。以下是交互的展开方式:

- 初始状态:环境首先为代理提供初始状态。这种状态可以是机器人在迷宫中的当前位置(例如,“左下角”)之类的信息。
R = +1(奖励)
R = -1(惩罚)
2. 行动选择:根据当前状态及其内部策略(策略),代理人选择行动。该策略一开始可能是随机的,也可能有一些初始的探索策略。机器人可能的动作可以是“向前移动”、“向左转”或“向右转”。
3. 操作执行:代理执行所选操作并与环境交互。在我们的示例中,机器人根据其选择向前移动、向左转或向右转。
4. 状态转换:作为操作的结果,环境转换到新状态。新状态可以是机器人在迷宫中的更新位置(例如,“从左下角向前一步”)。
5. 奖励反馈:环境根据所采取的行动和结果状态为智能体提供奖励信号。在迷宫中,达到目标(出口)的奖励可能很高,撞到墙上的奖励可能为负。
6. 学习和策略更新:代理收到奖励和新状态信息。使用此信息,将更新代理的内部策略。随着时间的流逝,智能体会了解哪些行为会带来更高的回报,并改进其策略以选择最大化长期回报的行动(例如快速到达出口)。
7. 重复:状态观察、行动选择、行动执行、奖励接收和策略更新的循环一直持续到智能体实现其目标(找到出口)或学习过程结束。
对于代理来说,他应该上升还是下降将是一个困难的情况,因为每个区块都具有相同的值。因此,上述方法不适合代理到达目的地。因此,为了解决这个问题,引入了贝尔曼方程,这是强化学习背后的主要概念。
六、贝尔曼方程。
贝尔曼方程由数学家理查德·欧内斯特·贝尔曼于 1953 年提出,因此被称为贝尔曼方程。它与动态规划相关联,用于通过包含先前状态的值来计算决策问题在某个点的值。
它是一种在动态规划或环境中计算值函数的方法,导致了现代强化学习。
贝尔曼方程中使用的关键元素是:
·代理执行的操作称为“a”
·通过执行操作发生的状态为“s”。
·每个好动作和坏动作获得的奖励/反馈是“R”。
·折扣因子是 Gamma “γ”。
贝尔曼方程可以写成:

贝尔曼方程
这里
·V(s)= 在特定点计算的值。
·R(s,a) = 通过执行操作在特定状态 s 下的奖励。
·γ = 折扣系数
·V(s') = 前一状态的值。
所以现在,使用贝尔曼方程,我们将找到给定环境的每个状态的值。我们将从目标块旁边的块开始。

数值描述了贝尔曼方程在上述给定状态示例中的应用。

第 5 个块中的代理状态
现在,我们将进一步移动到第 6 个块,在这里代理可能会更改路线,因为它总是试图找到最佳路径。所以现在,让我们从火坑旁边的街区考虑。

具有 S7block 的 S6 块中的代理状态
现在,代理有三个移动选项;如果他移动到蓝色盒子,那么如果他移动到火坑,他会感觉到颠簸,那么他将获得 -1 奖励。但在这里,我们只获得积极的回报,因此,他只会向上移动。完整的块值将使用此公式计算。请看下图:

代理达到的最终状态,以及访问的所有状态代理的状态值。
(来源: Javatpoint)
七、马尔可夫决策过程 (MDP)
马尔可夫决策过程(MDP)用于形式化强化学习问题。如果环境是完全可观察的,那么它的动态可以建模为马尔可夫过程。在 MDP 中,代理不断与环境交互并执行操作;在每次操作中,环境都会响应并生成新状态。

马尔可夫决策过程框图
MDP 用于描述 RL 的环境,几乎所有的 RL 问题都可以使用 MDP 进行形式化。
MDP 包含四个元素(S、A、Pa、Ra)的元组:
·一组有限状态 S
·一组有限动作 A
·从状态 S 过渡到状态 S' 后因行动 (Ra) 而获得的奖励。
·概率 (Pa)。
MDP 使用马尔可夫性质,为了更好地理解 MDP,我们需要了解它。
马尔可夫属性:
它说“如果代理处于当前状态 S1,执行操作 a1 并移动到状态 s2,则从 s1 到 s2 的状态转换仅取决于当前状态和未来操作,状态不依赖于过去的操作、奖励或状态。
马尔可夫过程:
马尔可夫过程是一个无内存过程,具有一系列使用马尔可夫性质的随机状态 S1、S2、.....、St。马尔可夫过程也称为马尔可夫链,它是状态 S 和转移函数 P 上的元组 (S, P)。这两个分量(S 和 P)可以定义系统的动力学。
八、马尔可夫决策过程 (MDP) 的代码实现
马尔可夫决策过程 (MDP) 的实施涉及需要注意的某些步骤:
实施步骤:
- 环境设置:定义环境,包括迷宫布局、开始状态、目标状态、障碍物和奖励。
- 定义 MDP 组件:根据环境设置指定状态、操作、转换概率和奖励。此步骤涉及将环境的动态编码到数学模型中。
- 策略迭代或值迭代:使用迭代算法(如策略迭代或值迭代)来查找导航迷宫的最佳策略。这些算法涉及迭代更新值函数或策略,直到收敛。
- 路径提取:确定最佳策略后,提取代理应遵循的最佳路径,以从开始状态到达目标状态。此路径表示最大化预期累积奖励的操作序列。
- 路径执行:在真实或模拟环境中执行从MDP算法获得的最优路径。这涉及根据规定的操作移动代理,并根据环境的动态更新代理的状态。
- 评估和改进:评估路径规划算法在效率、最优性和鲁棒性方面的性能。如有必要,请优化算法以提高其性能。
使用健身房
现在,让我们谈谈健身房。它是 OpenAI 提供的库,可以模拟各种环境并绘制它们,这有助于我们轻松可视化强化学习算法。
可以通过运行以下命令来安装它:
pip install gym您必须确保系统中也安装了 matplotlib。如果没有,您可以通过运行下面给出的命令来执行此操作:
%pip install matplotlib导入库
import gym
import pygame
import warnings
import numpy as np
from gym import spaces
from pygame import gfxdraw
from IPython import display
import matplotlib.pyplot as plt
from matplotlib import animation
from IPython.display import HTML
from gym.error import DependencyNotInstalled
from typing import Tuple, Dict, Optional, Iterable使用健身房创建迷宫
(来源:https://colab.research.google.com/github/deepmind/dm_control/blob/master/tutorial.ipynb)
class Maze(gym.Env):
def __init__(self, exploring_starts: bool = False,
shaped_rewards: bool = False, size: int = 5) -> None:
super().__init__()
self.exploring_starts = exploring_starts
self.shaped_rewards = shaped_rewards
self.state = (size - 1, size - 1)
self.goal = (size - 1, size - 1)
self.maze = self._create_maze(size=size)
self.distances = self._compute_distances(self.goal, self.maze)
self.action_space = spaces.Discrete(n=4)
self.action_space.action_meanings = {0: 'UP', 1: 'RIGHT', 2: 'DOWN', 3: "LEFT"}
self.observation_space = spaces.MultiDiscrete([size, size])
self.screen = None
self.agent_transform = None
def step(self, action: int) -> Tuple[Tuple[int, int], float, bool, Dict]:
reward = self.compute_reward(self.state, action)
self.state = self._get_next_state(self.state, action)
done = self.state == self.goal
info = {}
return self.state, reward, done, info
def reset(self) -> Tuple[int, int]:
if self.exploring_starts:
while self.state == self.goal:
self.state = tuple(self.observation_space.sample())
else:
self.state = (0, 0)
return self.state
def render(self, mode: str = 'human') -> Optional[np.ndarray]:
assert mode in ['human', 'rgb_array']
screen_size = 600
scale = screen_size / 5
if self.screen is None:
pygame.init()
self.screen = pygame.Surface((screen_size, screen_size))
surf = pygame.Surface((screen_size, screen_size))
surf.fill((22, 36, 71))
for row in range(5):
for col in range(5):
state = (row, col)
for next_state in [(row + 1, col), (row - 1, col), (row, col + 1), (row, col - 1)]:
if next_state not in self.maze[state]:
# Add the geometry of the edges and walls (i.e. the boundaries between
# adjacent squares that are not connected).
row_diff, col_diff = np.subtract(next_state, state)
left = (col + (col_diff > 0)) * scale - 2 * (col_diff != 0)
right = ((col + 1) - (col_diff < 0)) * scale + 2 * (col_diff != 0)
top = (5 - (row + (row_diff > 0))) * scale - 2 * (row_diff != 0)
bottom = (5 - ((row + 1) - (row_diff < 0))) * scale + 2 * (row_diff != 0)
gfxdraw.filled_polygon(surf, [(left, bottom), (left, top), (right, top), (right, bottom)], (255, 255, 255))
# Add the geometry of the goal square to the viewer.
left, right, top, bottom = scale * 4 + 10, scale * 5 - 10, scale - 10, 10
gfxdraw.filled_polygon(surf, [(left, bottom), (left, top), (right, top), (right, bottom)], (40, 199, 172))
# Add the geometry of the agent to the viewer.
agent_row = int(screen_size - scale * (self.state[0] + .5))
agent_col = int(scale * (self.state[1] + .5))
gfxdraw.filled_circle(surf, agent_col, agent_row, int(scale * .6 / 2), (228, 63, 90))
surf = pygame.transform.flip(surf, False, True)
self.screen.blit(surf, (0, 0))
return np.transpose(
np.array(pygame.surfarray.pixels3d(self.screen)), axes=(1, 0, 2)
)
def close(self) -> None:
if self.screen is not None:
pygame.display.quit()
pygame.quit()
self.screen = None
def compute_reward(self, state: Tuple[int, int], action: int) -> float:
next_state = self._get_next_state(state, action)
if self.shaped_rewards:
return - (self.distances[next_state] / self.distances.max())
return - float(state != self.goal)
def simulate_step(self, state: Tuple[int, int], action: int):
reward = self.compute_reward(state, action)
next_state = self._get_next_state(state, action)
done = next_state == self.goal
info = {}
return next_state, reward, done, info
def _get_next_state(self, state: Tuple[int, int], action: int) -> Tuple[int, int]:
if action == 0:
next_state = (state[0] - 1, state[1])
elif action == 1:
next_state = (state[0], state[1] + 1)
elif action == 2:
next_state = (state[0] + 1, state[1])
elif action == 3:
next_state = (state[0], state[1] - 1)
else:
raise ValueError("Action value not supported:", action)
if next_state in self.maze[state]:
return next_state
return state
@staticmethod
def _create_maze(size: int) -> Dict[Tuple[int, int], Iterable[Tuple[int, int]]]:
maze = {(row, col): [(row - 1, col), (row + 1, col), (row, col - 1), (row, col + 1)]
for row in range(size) for col in range(size)}
left_edges = [[(row, 0), (row, -1)] for row in range(size)]
right_edges = [[(row, size - 1), (row, size)] for row in range(size)]
upper_edges = [[(0, col), (-1, col)] for col in range(size)]
lower_edges = [[(size - 1, col), (size, col)] for col in range(size)]
walls = [
[(1, 0), (1, 1)], [(2, 0), (2, 1)], [(3, 0), (3, 1)],
[(1, 1), (1, 2)], [(2, 1), (2, 2)], [(3, 1), (3, 2)],
[(3, 1), (4, 1)], [(0, 2), (1, 2)], [(1, 2), (1, 3)],
[(2, 2), (3, 2)], [(2, 3), (3, 3)], [(2, 4), (3, 4)],
[(4, 2), (4, 3)], [(1, 3), (1, 4)], [(2, 3), (2, 4)],
]
obstacles = upper_edges + lower_edges + left_edges + right_edges + walls
for src, dst in obstacles:
maze[src].remove(dst)
if dst in maze:
maze[dst].remove(src)
return maze
@staticmethod
def _compute_distances(goal: Tuple[int, int],
maze: Dict[Tuple[int, int], Iterable[Tuple[int, int]]]) -> np.ndarray:
distances = np.full((5, 5), np.inf)
visited = set()
distances[goal] = 0.
while visited != set(maze):
sorted_dst = [(v // 5, v % 5) for v in distances.argsort(axis=None)]
closest = next(x for x in sorted_dst if x not in visited)
visited.add(closest)
for neighbour in maze[closest]:
distances[neighbour] = min(distances[neighbour], distances[closest] + 1)
return distances
def display_video(frames):
orig_backend = matplotlib.get_backend()
matplotlib.use('Agg')
fig, ax = plt.subplots(1, 1, figsize=(5, 5))
matplotlib.use(orig_backend)
ax.set_axis_off()
ax.set_aspect('equal')
ax.set_position([0, 0, 1, 1])
im = ax.imshow(frames[0])
def update(frame):
im.set_data(frame)
return [im]
anim = animation.FuncAnimation(fig=fig, func=update, frames=frames,
interval=50, blit=True, repeat=False)
return HTML(anim.to_html5_video())将环境定义为迷宫
env = Maze()重置环境
env.reset()
这会将环境及其初始状态重置为其初始位置。
initial_state = env.reset()
print(f"The new episode will start in state: {initial_state}")渲染环境
env.render()
呈现环境。
支持的模式集因环境而异。(某些第三方环境可能根本不支持渲染。
frame = env.render(mode = 'rgb_array')
plt.axis('off')
plt.title(f"State: {initial_state}")
plt.imshow(frame)
代理处于状态时提供的输出:(0,0)
代理在给定环境中执行操作
env.step()
接受操作并返回元组(观察、奖励、完成、信息)。
Args:action(对象):代理提供的操作
返回值: 观察值 (object):代理对当前环境的观察 奖励 (float) : 完成先前操作后返回的奖励金额 (bool):事件是否已结束,在这种情况下,进一步的 step() 调用将返回未定义的结果 info (dict):包含辅助诊断信息(有助于调试、日志记录,有时还有学习)
action = 2
next_state, reward, done, info = env.step(action)
print(f"After moving down 1 row, the agent is in state: {next_state}")
print(f"After moving down 1 row, we got a reward of: {reward}")
print("After moving down 1 row, the task is" , "" if done else "not", "finished")frame = env.render(mode = 'rgb_array')
plt.axis('off')
plt.title(f"State: {next_state}")
plt.imshow(frame)
代理移动到状态时提供的输出:(1,0)
关闭环境
env.close()
env = Maze()print(f"For example, the initial state is: {env.reset()}")
print(f"The space state is of type: {env.observation_space}")例如,初始状态为:(0, 0) 空间状态的类型为:MultiDiscrete([5 5])
print(f"An example of a valid action is: {env.action_space.sample()}")
print(f"The action is of type: {env.action_space}")有效操作的示例如下: 3 该操作的类型为:Discrete(4)
定义智能体在其状态空间中运动的第一条轨迹
env = Maze()
state = env.reset()
trajectory = []
for _ in range(3):
action = env.action_space.sample()
next_state, reward, done, extra_info = env.step(action)
trajectory.append([state, action, reward, done, next_state])
state = next_state
env.close()
print(f"First Trajectory:\n {trajectory}")第一个轨迹:[[(0, 0), 1, -1.0, False, (0, 1)], [(0, 1), 3, -1.0, False, (0, 0)], [(0, 0), 0, -1.0, False, (0, 0)]]
定义代理运动在其状态空间中的第一集
env = Maze()
state = env.reset()
episode = []
done = False
while not done:
action = env.action_space.sample()
next_state, reward, done, extra_info = env.step(action)
episode.append([state, action, reward, done, next_state])
state = next_state
env.close()
print(f"First Episode:\n {episode}")First Episode: [[(0, 0), 3, -1.0, False, (0, 0)], [(0, 0), 2, -1.0, False, (1, 0)], [(1, 0), 3, -1.0, False, (1, 0)], [(1, 0), 1, -1.0, False, (1, 0)], [(1, 0), 3, -1.0, False, (1, 0)], [(1, 0), 2, -1.0, False, (2, 0)], [(2, 0), 0, -1.0, False, (1, 0)], [(1, 0), 1, -1.0, False, (1, 0)], [(1, 0), 0, -1.0, False, (0, 0)], [(0, 0), 0, -1.0, False, (0, 0)], [(0, 0), 0, -1.0, False, (0, 0)], [(0, 0), 0, -1.0, False, (0, 0)], [(0, 0), 3, -1.0, False, (0, 0)], [(0, 0), 0, -1.0, False, (0, 0)], [(0, 0), 0, -1.0, False, (0, 0)], [(0, 0), 3, -1.0, False, (0, 0)], [(0, 0), 2, -1.0, False, (1, 0)], [(1, 0), 2, -1.0, False, (2, 0)], [(2, 0), 3, -1.0, False, (2, 0)], [(2, 0), 2, -1.0, False, (3, 0)], [(3, 0), 1, -1.0, False, (3, 0)], [(3, 0), 0, -1.0, False, (2, 0)], [(2, 0), 3, -1.0, False, (2, 0)], [(2, 0), 2, -1.0, False, (3, 0)], [(3, 0), 2, -1.0, False, (4, 0)], [(4, 0), 2, -1.0, False, (4, 0)], [(4, 0), 3, -1.0, False, (4, 0)], [(4, 0), 1, -1.0, False, (4, 1)], [(4, 1), 0, -1.0, False, (4, 1)], [(4, 1), 1, -1.0, False, (4, 2)], [(4, 2), 0, -1.0, False, (3, 2)], [(3, 2), 1, -1.0, False, (3, 3)], [(3, 3), 2, -1.0, False, (4, 3)], [(4, 3), 1, -1.0, True, (4, 4)]]
获取代理在其状态空间中执行的操作的输出
env = Maze()
state = env.reset()
action = env.action_space.sample()
_, reward, _, _ = env.step(action)
print(f"We achived a reward of {reward} by taking action {action} in state {state}")我们通过在状态 (0, 0) 中执行操作 1 获得了 -1.0 的奖励
计算代理从迷宫中找到出口所需的移动量以及它获得的奖励/惩罚。
env = Maze()
state = env.reset()
done = False
gamma = 0.99
G_0 = 0
t = 0
while not done:
action = env.action_space.sample()
_, reward, done, _ = env.step(action)
G_0 += gamma ** t * reward
t += 1
env.close()
print(f"It took us {t} moves to find the exit, and each reward r(s,a) = -1, so the return amounts to {G_0}")我们花了 32 步才找到出口,每个奖励 r(s,a) = -1,因此回报为 -27.501966404214624
输出

代理已达到目标状态
九、代码说明
1. 初始化:“__init__”方法通过指定环境的特征来设置环境,例如是否采用探索开始、形状奖励和迷宫的大小。它初始化状态、目标、迷宫结构、动作空间和观察空间。
2. 步骤函数:“步骤”方法定义了环境如何随着代理采取的每个操作而演变。它计算奖励,根据操作更新状态,并检查剧集是否完成。
3. 重置功能:“重置”方法重置环境,使代理恢复到其启动状态。如果启用了“exploring_starts”,则代理可以从目标以外的任何状态启动。
4. 渲染:“渲染”方法将环境可视化。它创建迷宫的图形表示,包括代理的位置和目标。它返回图像(如果“mode”设置为“rgb_array”)或将其显示在屏幕上(如果“mode”设置为“human”)。
5. 奖励计算:“compute_reward”方法计算代理在给定状态和操作下收到的奖励。如果启用了“shaped_rewards”,则会根据与目标的距离计算奖励;否则,如果代理未达到目标,则它会提供 -1 的稀疏奖励。
6. 效用函数:有“_get_next_state”、“_create_maze”和“_compute_distances”等效用函数,分别有助于计算下一个状态、创建迷宫结构和计算与目标的距离。
7.显示视频功能:此功能从一系列帧生成HTML视频。它用于显示代理轨迹的可视化表示。
十、什么是Q Learning?
Q-Learning 是一种算法,旨在找到给定当前状态的最佳决策。让我们想象一下,如果一个孩子只是保持在一个随机的状态,在它周围的某个地方,躺着一块巧克力,它会做什么。孩子会多次尝试站立、爬行,失败很多次,最终会得到巧克力。这类似于 q-learning 算法的作用。代理暴露在完全未知的环境中。它采取一些随机行动,因这些行动而获得奖励或惩罚,并学会做出进一步的决定。(来源:甲骨文)
10.1 Q 学习
Q-learning 是一种 Off policy RL 算法,用于时间差 Learning。时间差异学习方法是比较时间连续预测的方法。它学习值函数 Q (S, a),这意味着在特定状态 “s” 下采取行动 “a” 有多好。

展示Q Learning实施的流程图
19.2 Q 学习说明:
Q-learning是一种流行的基于贝尔曼方程的无模型强化学习算法。Q-learning的主要目标是学习策略,该策略可以告知智能体在什么情况下应该采取什么行动来最大化奖励。
·它是一种非策略 RL,它试图找到在当前状态下要采取的最佳操作。
·Q-learning 中智能体的目标是最大化 Q 的值。
·Q-learning的值可以从贝尔曼方程中推导出来。
请看下图:

Q- 表示每个状态下操作的质量。因此,我们将使用一对状态和动作,即 Q(s, a),而不是在每个状态下使用一个值。Q 值指定哪个动作比其他动作更具润滑性,根据最佳 Q 值,智能体采取下一步行动。贝尔曼方程可用于推导 Q 值。
要执行任何操作,智能体将获得奖励 R(s, a),并且他最终将处于某种状态,因此 Q 值方程为:
![]()
从贝尔曼最优方程推导的 Q 学习方程
· 问:a:这是当前的 Q 值,表示在状态 s 中执行操作 a 的预期未来奖励。
· R(s, a):这是代理在状态 s 中执行操作 a 时收到的即时奖励。
· γ(伽玛):这是折扣系数(介于 0 和 1 之间)。它控制着代理对未来奖励的重视程度。较高的伽玛值更看重未来,而较低的伽玛值则侧重于眼前的奖励。
· 最大(Q(s', a')):这表示从下一个状态 s' 可获得的最大预期未来奖励,考虑到代理在该状态下可以采取的所有可能操作。

更新了 Q 学习方程式(来源:Oracle AI 和数据科学博客)
Q表
在执行 Q 学习时创建 Q 表或矩阵。该表遵循状态和操作对,即 [s, a],并将值初始化为零。每次操作后,都会更新表,并将 q 值存储在表中。RL 代理使用此 Q 表作为参考表,根据 q 值选择最佳操作。
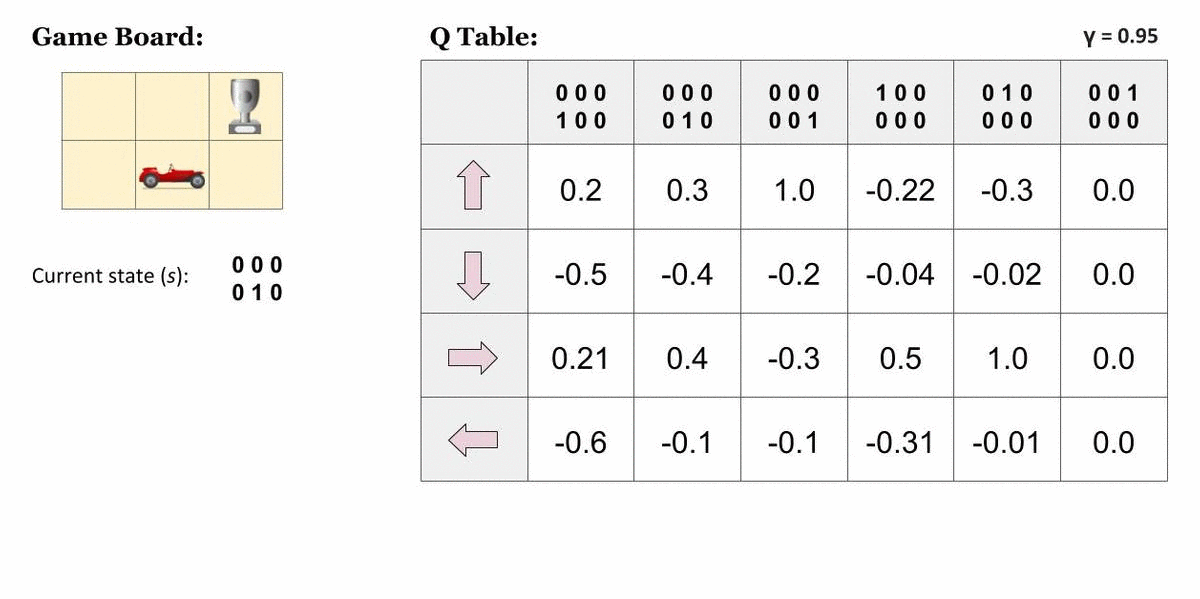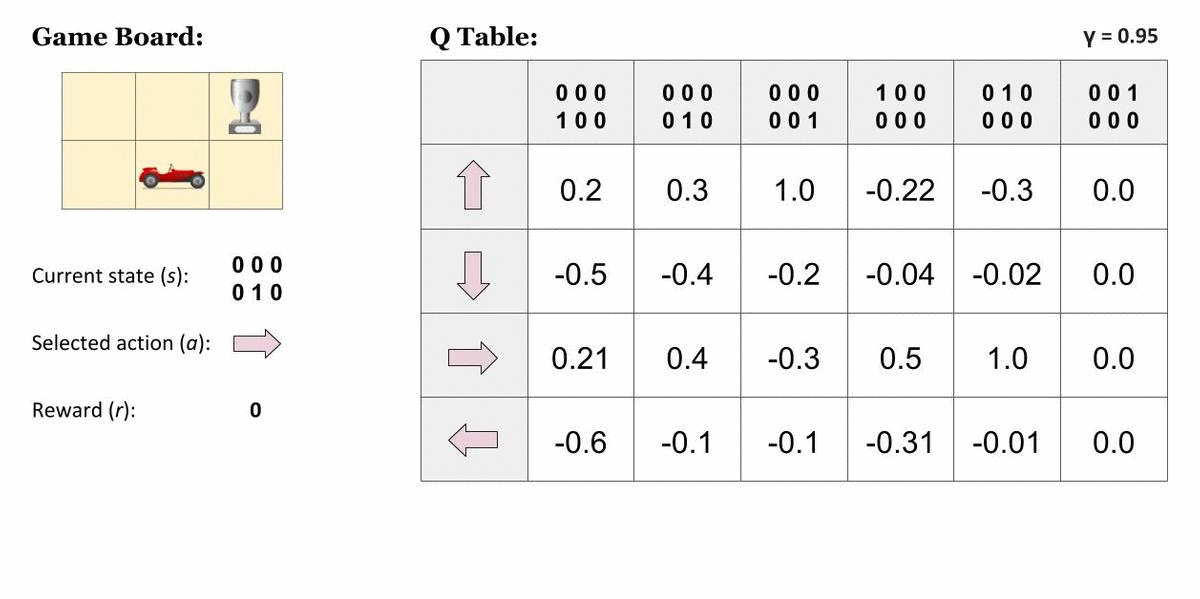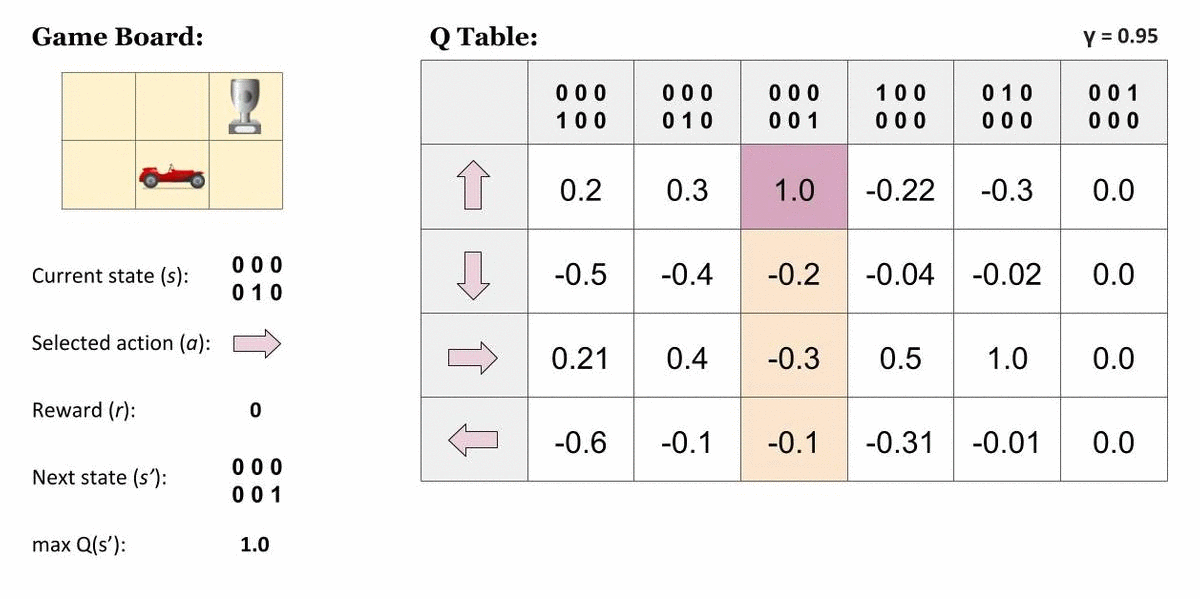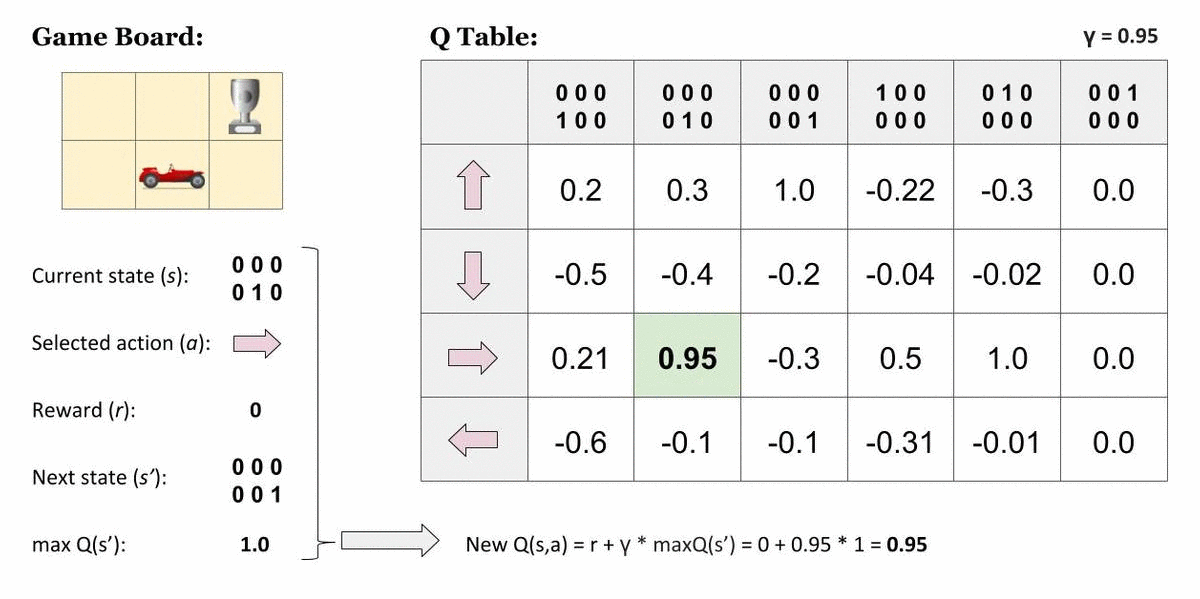
在代理计算状态操作值时更新 Q 表的图形表示。
十一、结论
强化学习 (RL) 提供了一种独特的方法来训练智能体。与使用标记数据的监督学习或使用未标记数据的无监督学习不同,RL 将智能体置于通过反复试验进行学习的环境中。通过与环境互动、采取行动和获得奖励(或惩罚),智能体逐渐学会最佳行动方案,以最大化其长期回报。
Q-Learning 是一种流行的 RL 算法,以其无模型特性而闻名。它不需要完整的环境地图,使其能够适应各种情况。Q-Learning 利用 Q 值,它表示在特定状态下采取特定操作的估计未来奖励。通过贝尔曼方程,代理会迭代更新这些 Q 值,使其能够了解哪些操作在不同场景中最有价值。
关键要点:
·RL 允许智能体通过交互和反馈进行学习,使其适用于复杂和动态的环境。
·Q-Learning 是一种功能强大的 RL 算法,在无法获得完整环境模型的情况下表现出色。
·通过学习 Q 值,智能体发现最佳行动方案,以最大化其长期回报。
超越Q-Learning:
虽然 Q-Learning 是一种流行的选择,但存在其他 RL 算法,每种算法都有其优点和缺点。一些例子包括:
1. SARSA(State-Action-Reward-State-Action):类似于Q-Learning,但它遵循特定的行动选择策略。
2. 深度问答:利用深度神经网络处理具有高维状态空间的复杂环境。
3. 策略梯度方法:专注于直接学习智能体的策略(行动选择策略)。
乌特卡什·拉斯托吉