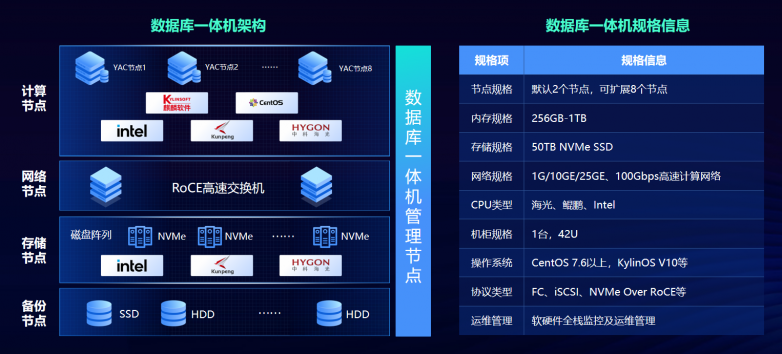
HGVS 概念
HGVS 人类基因组变异协会(Human Genome Variation Society)提出的转录本编号,cDNA 参考序列(以前缀“c.”表示)、氨基酸参考序列(以前缀“p.”表示)。cDNA 中一种碱基被另一种碱基取代,以“>”进行表示,如:c.2186A>G,表示与参考序列相比,在第 2186 位置的腺嘌呤(A)被鸟嘌呤(G)所取代;在氨基酸中 p.Asp729Gly,表示在第 729 位置的 Asp(天冬氨酸)被 Gly(甘氨酸)取代。
氨基酸字母与缩写转换表
python3.9实现算法。
# 氨基酸缩写与全称转换字典
dict_AA = {'A': {'Abbreviation': 'Ala', 'CN': '丙氨酸', 'EN': 'Alanine'},
'F': {'Abbreviation': 'Phe', 'CN': '苯丙氨酸', 'EN': 'Phenylalanine'},
'C': {'Abbreviation': 'Cys', 'CN': '半胱氨酸', 'EN': 'Cysteine'},
'U': {'Abbreviation': 'Sec', 'CN': '硒半胱氨酸', 'EN': 'Selenocysteine'},
'D': {'Abbreviation': 'Asp', 'CN': '天冬氨酸', 'EN': 'Aspartic acid / Aspartate'},
'N': {'Abbreviation': 'Asn', 'CN': '天冬酰胺', 'EN': 'Asparagine'},
'E': {'Abbreviation': 'Glu', 'CN': '谷氨酸', 'EN': 'Glutamic acid / Glutamate'},
'Q': {'Abbreviation': 'Gln', 'CN': '谷氨酰胺', 'EN': 'Glutamine'},
'G': {'Abbreviation': 'Gly', 'CN': '甘氨酸', 'EN': 'Glycine'},
'H': {'Abbreviation': 'His', 'CN': '组氨酸', 'EN': 'Histidine'},
'L': {'Abbreviation': 'Leu', 'CN': '亮氨酸', 'EN': 'Leucine'},
'I': {'Abbreviation': 'Ile', 'CN': '异亮氨酸', 'EN': 'Isoleucine'},
'K': {'Abbreviation': 'Lys', 'CN': '赖氨酸', 'EN': 'Lysine'},
'O': {'Abbreviation': 'Pyl', 'CN': '吡咯赖氨酸', 'EN': 'Pyrrolysine'},
'M': {'Abbreviation': 'Met', 'CN': '蛋氨酸', 'EN': 'Methionine'},
'P': {'Abbreviation': 'Pro', 'CN': '脯氨酸', 'EN': 'Proline'},
'R': {'Abbreviation': 'Arg', 'CN': '精氨酸', 'EN': 'Arginine'},
'S': {'Abbreviation': 'Ser', 'CN': '丝氨酸', 'EN': 'Serine'},
'T': {'Abbreviation': 'Thr', 'CN': '苏氨酸', 'EN': 'Threonine'},
'V': {'Abbreviation': 'Val', 'CN': '缬氨酸', 'EN': 'Valine'},
'W': {'Abbreviation': 'Trp', 'CN': '色氨酸', 'EN': 'Tryptophan'},
'Y': {'Abbreviation': 'Tyr', 'CN': '酪氨酸', 'EN': 'Tyrosine'},
}
# 写入文本
with open("AA_convert.txt", 'w') as fw:
fw.write("Letter\tAbbreviation\tCN\tEN\n")
for letter, abbr in dict_AA.items():
print(letter, ':', abbr)
line = "{0}\t{1}\t{2}\t{3}\n".format(letter,
abbr.get('Abbreviation', 'ERROR'),
abbr.get('CN', 'ERROR'),
abbr.get('EN', 'ERROR'))
fw.write(line)
# 从文本读取为字典
dict_AA = {}
with open("AA_convert.txt", 'r') as fr:
# 遍历每行
for line in fr.readlines():
# 跳过首行
if line.startswith('Letter'):
continue
line = line.strip().split('\t')
dict_AA[line[0]] = {'Abbreviation': line[1], 'CN': line[2], 'EN': line[3]}
# 打印字典
print(dict_AA)

打印全部氨基酸字母表
# 打印全部氨基酸字母表,用于后续re模块正则表达式
s = ''
for letter, abbr in dict_AA.items():
if letter != 'Y':
s += f"{letter}|"
else:
s += f"{letter}"
print(s)
#A|F|C|U|D|N|E|Q|G|H|L|I|K|O|M|P|R|S|T|V|W|Y
HGVS写法转换
# 对HGVS写法进行转换
# ANNOVAR注释写法
# SLC25A13:NM_014251:exon1:c.T2C:p.M1T
# 转换后写法
# c.2T>C/p.Met1Thr (NM_014251.3) Exon1/18
import re
def convert_HGVS(hgvs: str, total_exon: int):
"""
hgvs: 待转换HGVS
total_exon: 基因的全部外显子数量
"""
# 按:符号分割输入hgvs
list_hgvs = hgvs.split(':')
gene = list_hgvs[0]
exon = nm = cds_change = aa_change = exon_change_position = aa_change_position = ref = alt = ref_aa = alt_aa = ''
for context in list_hgvs[1:]:
if 'exon' in context:
exon = context
if 'NM' in context:
nm = context
elif 'c.' in context:
cds_change = context
# 匹配ref碱基、外显子发生变异的坐标和alt碱基
match = re.search(r'([A|T|C|G]*)(\d+)([A|T|C|G]*)', cds_change)
if match:
# 获取ref碱基
ref = match.group(1)
# 获取位置
exon_change_position = match.group(2)
# 获取alt碱基
alt = match.group(3)
else:
raise Exception("ERROR!")
elif 'p.' in context:
aa_change = context
# 匹配ref氨基酸、外显子发生变异对应氨基酸改变的坐标和alt氨基酸
match = re.search(r'([A|F|C|U|D|N|E|Q|G|H|L|I|K|O|M|P|R|S|T|V|W|Y]*)(\d+)([A|F|C|U|D|N|E|Q|G|H|L|I|K|O|M|P|R|S|T|V|W|Y]*)', aa_change)
if match:
# 获取ref氨基酸
ref_aa = match.group(1)
# 氨基酸改变的坐标
aa_change_position = match.group(2)
# 获取alt氨基酸
alt_aa = match.group(3)
# 将字典简写氨基酸转换为三字母缩写氨基酸
ref_aa = dict_AA[ref_aa].get('Abbreviation', "ERROR")
alt_aa = dict_AA[alt_aa].get('Abbreviation', "ERROR")
else:
raise Exception("ERROR!")
# 调整写法 c.2T>C/p.Met1? (NM_014251.3) Exon1/18
hgvs_formated = 'c.{exon_change_position}{ref}>{alt}/p.{ref_aa}{aa_change_position}{alt_aa} ({nm}) {exon}/{total_exon}'.format(exon_change_position=exon_change_position,
ref=ref,
alt=alt,
ref_aa=ref_aa,
aa_change_position=aa_change_position,
alt_aa=alt_aa,
nm=nm,
exon= exon.capitalize(),
total_exon=total_exon)
# 打印中间变量
print(gene, exon, cds_change, aa_change, exon_change_position, ref, alt, aa_change_position, ref_aa, alt_aa)
return hgvs_formated
# 测试
print(convert_HGVS(hgvs='SLC25A13:NM_014251:exon1:c.T2C:p.M1T', total_exon=18))
# c.2T>C/p.Met1Thr (NM_014251) Exon1/18
print(convert_HGVS(hgvs='PKD1:NM_001009944:exon15:c.G3496A:p.G1166S', total_exon=46))
# c.3496G>A/p.Gly1166Ser (NM_001009944) Exon15/46
生信算法文章推荐
生信算法1 - DNA测序算法实践之序列操作
生信算法2 - DNA测序算法实践之序列统计
生信算法3 - 基于k-mer算法获取序列比对索引
生信算法4 - 获取overlap序列索引和序列的算法
生信算法5 - 序列比对之全局比对算法
生信算法6 - 比对reads碱基数量统计及百分比统计
生信算法7 - 核酸序列Fasta和蛋白PDB文件读写与检索