本文是自己的学习笔记。主要参考资料如下:
马士兵
- 1、Redis的慢查询
- 1.1、慢查询的相关参数
- 1.1.1、设置阈值
- 1.1.2、慢查询日志存储长度
- 1.1.2.1、慢查询日志解析
- 1.2、生产环境下慢查询的配置
- 2、Pipeline
- 2.1、简单的pipeline代码示例
- 2.2、使用Pipeline的注意事项
- 3、事务
- 3.1、redis事务开启的三个阶段
- 3.2、redis事务的特性
- 4、Redis实现乐观锁
- 4.1、watch关键字(乐观锁)
- 5、LUA脚本
- 5.1、redis中使用LUA简单示例
- 5.2、Redis + LUA实现限流
1、Redis的慢查询
Redis是基于TCP的,所以当redis查询速度过慢时,原因可能出在下面四步中,即网络时间,命令排队,执行时间。
redis对慢查询的分析是集中在下图的第3步。

慢查询是指redis查询速度过慢时,我们可以根据redis的内部工具定位原因。
redis中如果开启了慢查询,它的默认时间是10ms,即如果查询超过这个时间,相关的预警会启动。
1.1、慢查询的相关参数
1.1.1、设置阈值
我们总共有两种方式设置redis慢查询的阈值,一是在配置文件中,二是使用命令。
- 配置文件:
slowlog-log-slower-than 10000
- 命令
config set slowlog-log-slower-than 10000
# Don't execute below unless you want change this configuration permanently
config rewrite
1.1.2、慢查询日志存储长度
当慢查询发生时,redis会记录相关的日志到内存中,数据结构是队列,如果队列满了又有新的慢查询,那旧的慢查询记录就会被pop消失。
redis默认可以存储128条慢查询,我们也是可以通过配置文件和命令修改队列长度。
- 配置文件:
slowlog-max-len 128
- 命令
config set slowlog-max-len 128
# Don't execute below unless you want change this configuration permanently
config rewrite
我们可以手动清空慢查询日志队列。slowlog reset。执行后,慢查询只会记录slowlog reset这一条指令。
1.1.2.1、慢查询日志解析
下面会具体分析慢查询日志中有什么信息。为了方便测试,先将slowlog-log-slower-than设为0,让每条语句都能被慢查询日志记录。
slowlog get num,获取最新的num条慢查询记录,下面是例子。
127.0.0.1:6379> slowlog get 1
1) 1) (integer) 2
2) (integer) 1674827308
3) (integer) 3
4) 1) "get"
2) "k1"
5) "127.0.0.1:52429"
6) ""
下面是返回值的解析。
- 命令序列号,递增的,这里2意思是这是第2条执行的语句。
- 一串时间戳,该命令执行的时间。
- 命令的执行时间,单位是微秒。
- 命令的具体内容和返回值
- 客户端(请求执行命令方)的IP。
- 客户端的名称。
1.2、生产环境下慢查询的配置
我们需要关注的配置就两个,阈值和日志队列长度。
阈值默认值是10ms,队列长度128。
对于阈值,这个具体需要看系统对查询的要求。对于要求非常高的系统将其设为1ms或者0.1ms也是可以的。需要结合实际数据,确保阈值合适,太低查询日志会记录太多不属于慢查询的命令;太高则会导致真正的慢查询不被记录,所以需要根据测试来决定数值。
对于日志队列长度,一般来说128太小,设为1000,2000都可。日志虽然存储在内存中,但是每条日志所占用的空间不大,所以队列长度设大一点也没关系。
2、Pipeline
redis 命令执行主要是下面4步,通常情况下排队和执行命令的时间是很快的,都是微秒级。相反网络开销却比较大,很多时候都是毫秒级别。
为了优化执行速度,redis便有了pipeline。这相当于是一个批处理机制,一次网络请求带来多条指令,大量redis命令执行的情景可以节省大量时间。
2.1、简单的pipeline代码示例
下面是使用pipeline进行set和get的示例。
简单来说通过Jedis#pipelined()获得Pipeline对象。如果需要获取命令的返回值就使用Pipeline#syncAndReturnAll()方法,不需要返回值就执行Pipeline#sync()即可。
//get
Jedis jedis = jedisPool.getResource();
Pipeline pipeline = jedis.pipelined();
for(String key: keys) {
pipelined.get(key);
}
return pipelined.syncAndReturnAll();
//set
Jedis jedis = jedisPool.getResource();
Pipeline pipeline = jedis.pipelined();
for(String key: map.keySet()) {
pipelined.set(key, map.get(key));
}
pipelined.sync();
2.2、使用Pipeline的注意事项
我自己做实验,Pipeline对10000次字符串类型的set操作耗时13ms;不使用Pipeline则耗时1023ms。
虽然理论上Pipeline在一次性处理越多的命令,节约的时间就越多,但是我们也不能无限制地在一个Pipeline里塞入太多的数据,他是有瓶颈的。
因为Redis是基于TCP的,并且命令执行的主要耗时是在网络方面,所以我们需要考虑一个TCP报文能携带多少数据。如果我们一次性塞入太多指令,TCP协议会将这些指令分成多个报文分开传输,也就造成多次网络传输。
所以我们一次性执行的指令的字节数不应该超过TCP报文的最大值。
单个TCP报文是1500字节,IP头占20字节,TCP头占20字节,所以一个报文可供我们使用的空间就是1500 - 20 - 20 = 1460字节。
注意pipeline一次携带命令的不要超过1460字节即可。
3、事务
3.1、redis事务开启的三个阶段
- 开启事务:
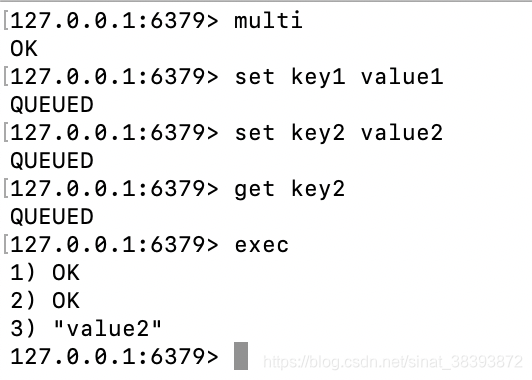
multi。 - 命令入队:开始写命令,这里写的所有命令都是放入队列的操作,不执行。命令的执行只有执行事务时才会开始顺序执行。
- 取消事务:
discard。如果取消了事务就不能执行事务,要重新开启事务。放弃了事务那事务里的命令就没有执行。 - 执行事务:
exec。只有执行事务,命令才会被顺序执行,然后会顺序返回各命令的返回值。
3.2、redis事务的特性
Redis的事务不完全和其它架构的事务一致。一般来说,在其他框架中的事务中,只要有一条语句执行失败,无论什么原因导致失败,该事务中的所有语句都会回滚。
redis有一条语句发生错误的时候,redis并不会回滚事务中的其它语句,所以一般我们不会使用redis来做事务的控制。
- 语法错误:这种就是指令的语法错误。发生这种异常的时候,事务会被直接取消。下面是例子。

- 逻辑错误:指令都没问题,但是运行时发生错误。这种异常不会影响事务,事务中其他正常的指令都会被执行。比如下面的例子,我们给一个字符串执行
incr操作,使其发生错误,而事务中的其他指令也能被执行。

4、Redis实现乐观锁
- 悲观锁:很悲观,认为共有数据任何时候都会被修改,于是在共有数据的整个操作过程都会加上锁,哪怕这些操作过程中还包含其他操作,共有数据等会才会操作。我们熟知的
sychronized就这悲观锁的代表,锁住的代码区域即使没有对共有数据操作,也不允许别人操作数据。这种锁很安全,但影响性能。 - 乐观锁:很乐观,相信整个过程数据不会被改动,只会在操作共有数据的时候才会去检查数据有没有被改动。常见的版本号version就是乐观锁的代表。这种锁安全性低一些,但是性能很高
Redis可以通过watch关键字来实现乐观锁。
4.1、watch关键字(乐观锁)
watch关键字的语法是watch key,可以有多个key。表示对一个key进行监控(可以同时监控多个key),实际上可以理解成对这个key加上一个版本号记录。与此相反的unwatch是放弃监视,放弃监视不能指定,只能放弃所有监视。
watch要和事务一起使用。当使用watch监听一个key后,就会影响下一个开启的事务。如果在这个事务执行之前,watch的key有过写入操作(版本号变化),那么这个事务就一定提交失败。
watch影响的只有紧接着watch语句的一个事务,后面的事务不会被watch影响。
下面是示例,左边的标签页会watch k1执行事务,右边的标签页模拟一条新线程,在左标签页执行事务之前对k1写入。然后左标签的事务执行失败,事务中的k3没有存进去。
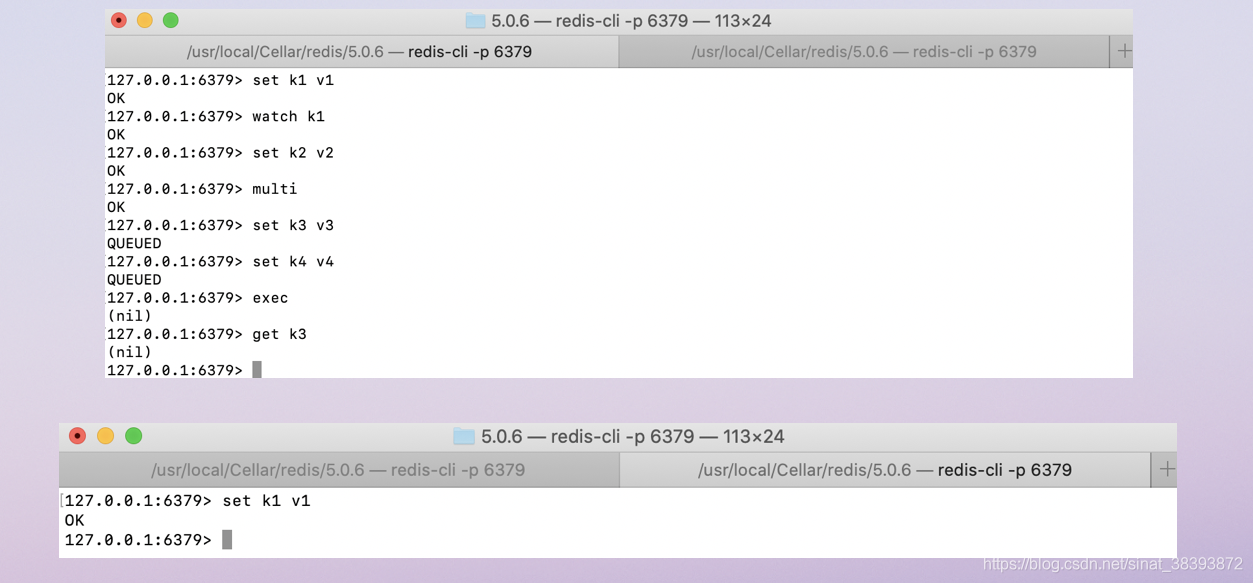
由上可以看出,Redis中watch关键字本身就具有乐观锁的性质,可以直接用watch实现乐观锁。
5、LUA脚本
LUA脚本是由C语言编写的,可以看成是一种语言,可以在在其他平台上执行,比如Java,Redis。
在redis中使用LUA语言有下面三点好处
- 减少网络开销:LUA可以吧多条命令放入一个脚本中执行。
- 原子性: redis以一个脚本为整体执行,中间不会被其他东西插入。
- 复用性:客户端发送的LUA脚本会存储在redis中,其他客户端可以复用这一脚本完成同样的逻辑。

5.1、redis中使用LUA简单示例
使用eval关键字,之后是LUA的语句,之后的参数第一个数字1表示KEYS[]传一个参数,剩下的参数都是ARGV[]。

前面介绍LUA的好处提到了复用性,LUA脚本可以存储在redis中重复调用。这里的实现是通过script load "LUA script"实现的。
这句话会将LUA脚本存储到redis中,返回一字符串,表示脚本的唯一id。之后通过evalsha就可以调用LUA脚本了。

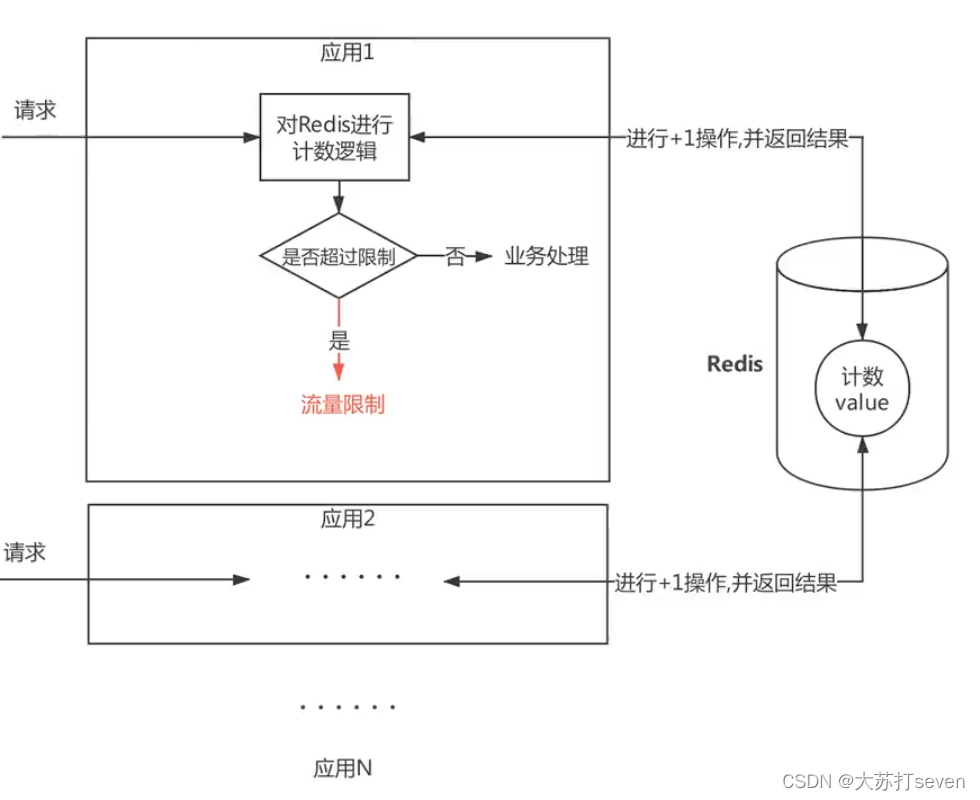
5.2、Redis + LUA实现限流