云布道师
引言:本文整理自阿里云高性能计算产品负责人黄泽辉在【HPC 优化实例商业化发布会】中的分享。
近日,全球领先的云计算厂商阿里云宣布最新 HPC 优化实例 hpc8ae 的正式商业化,该实例依托阿里云自研的「飞天+CIPU」架构体系,搭载第四代 AMD EPYC 处理器,专为高性能计算应用优化,特别适用于计算流体、有限元分析、多物理场模拟等仿真类应用,CAE 场景下的性价比最少提升 50%。
本文根据黄泽辉的主题分享整理而成。
高性能计算无所不在
过去多年,高性能计算在很多专业领域解决着各种各样的大型复杂计算问题,如分析地震数据、模拟汽车碰撞、设计药物靶点等等,以上的场景都需要巨大的计算能力才能够在可预期的时间内解决问题。

通过使用高性能计算能够有效加速科学研究发现的进展,帮助对日常使用的产品设计和研发上实现创新,高性能计算也成为了在当今社会无所不在且推动技术进步和经济发展的关键工具。
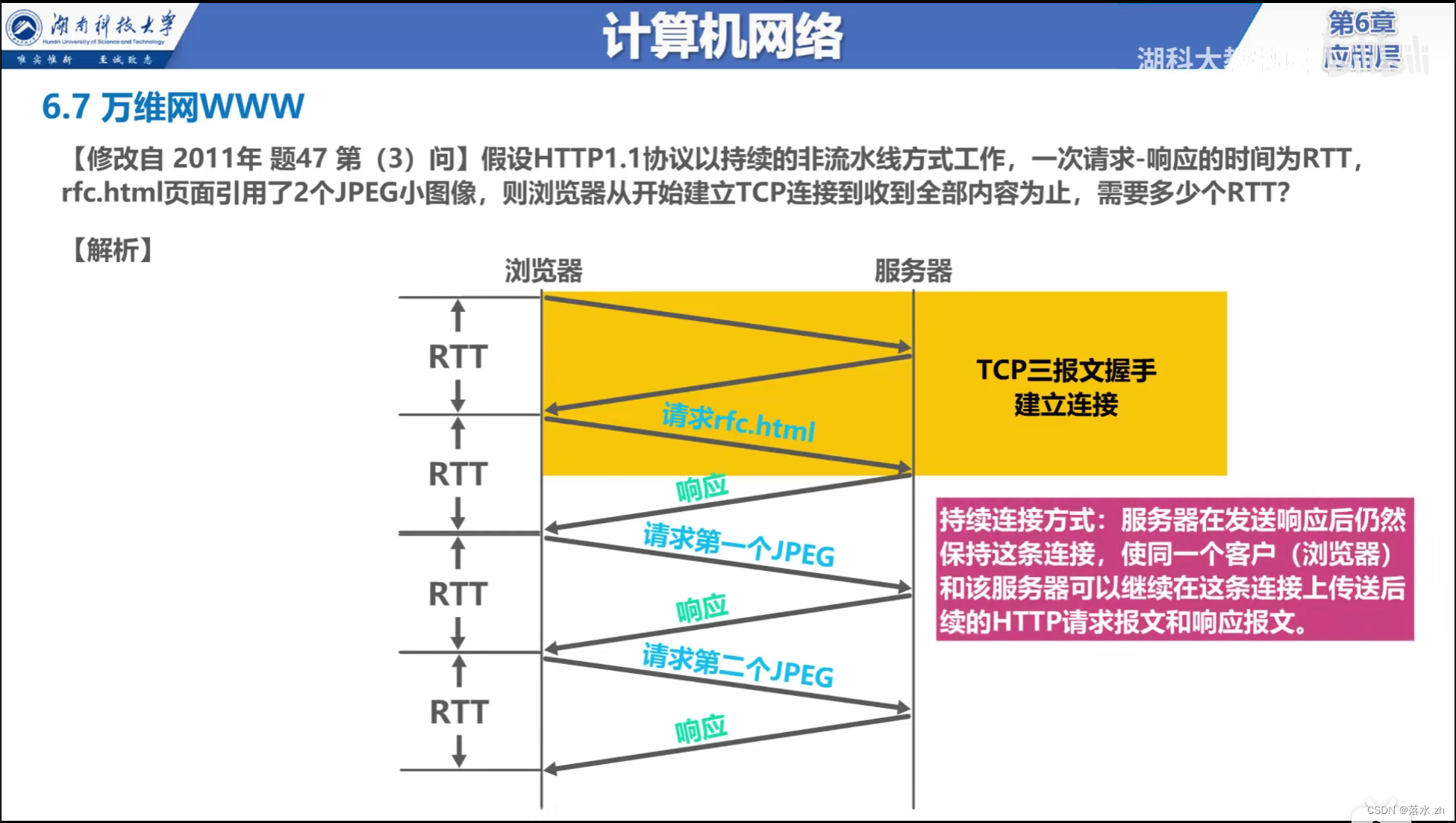
云上高性能计算正在加速普及
采用传统的自建线下 HPC 集群,采购及建设周期冗长,集群容量有限,在业务高峰时往往面临着资源不足和需要排队,浪费研发时间,集群硬件相对老旧,难更新,计算效率较低,性能上无法完全满足业务上的需求。这些都制约了高性能计算在全行业中发挥更大的作用。
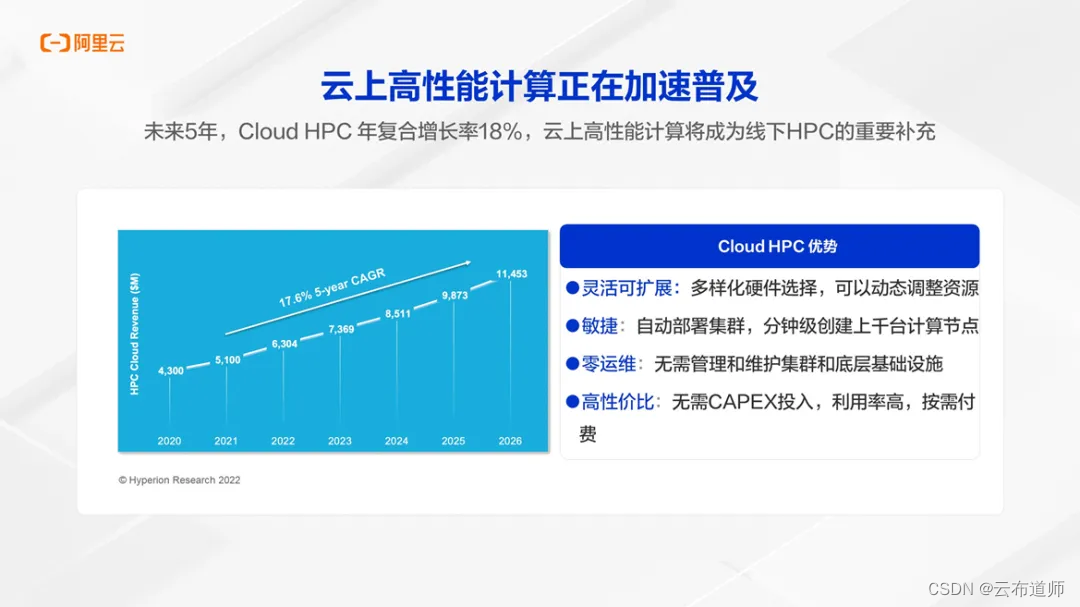
基于云的高性能计算(Cloud HPC),与传统 HPC 相比更加灵活、高效。用户可以利用云计算多样化、最新、最符合业务需求的计算硬件,保证计算效率最高。并可以根据业务负载动态增加/减少计算资源。用户只用为已使用的资源付费,具有更好的成本效益;同时,不需要专业 IT 人员创建、部署集群,也不需要管理维护底层基础设施,用户使用起来更加简单和可靠。
Cloud HPC 是一种更加普惠、更加民主化的 HPC 使用方式。任何一个初创企业,都可以通过云使用高性能计算,进行产品研发和设计,而不是只有大型企业/政府机构才具备这个能力。根据 Hyperion Research 的研究报告,2022 年 Cloud HPC 的市场份额已经能够占到整个市场份额的 17%,接下来的 5 年,都会以 18%/年复合增长率继续快速增长。所以说, Cloud HPC 正在加速普及,并成为线下超算的重要补充。
针对 HPC 工作负载专门优化云的基础设施
如何在云上开展高性能计算,是一件十分有挑战的事情。HPC 作为计算机科学皇冠上的明珠,对于计算性能、存储性能、网络性能都有极高的要求。以工业仿真最常用的Fluent 软件为例,它属于计算密集型的应用,需要很高的 CPU 主频。同时它的性能也受内存带宽大小约束,只有内存带宽足够大,才能快速处理数据。
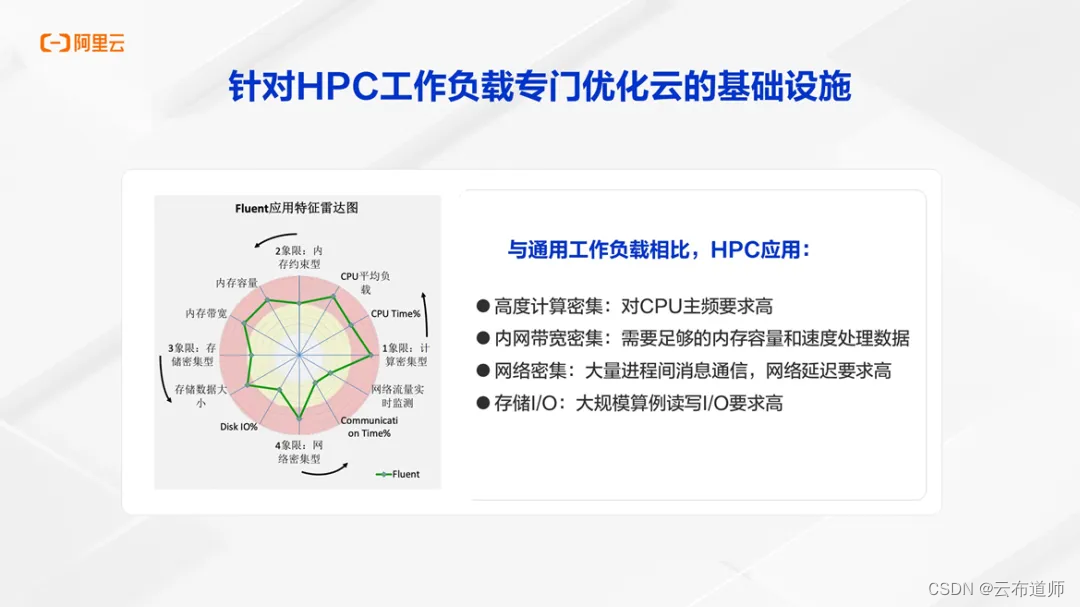
使用 Fluent 进行整车仿真时,需要多个节点并行计算。这些计算节点之间,必须要有低延时、高带宽的网络通信能力;计算集群使用的存储也必须需要有更强的 I/O 读写能力才能不阻塞计算的进行。云厂商目前更多考虑的还是互联网类的应用,性能更加通用和均衡,难以满足高性能计算的要求,特别是一些计算流体、气象预报等高精尖场景。
在摩尔定律逐渐放缓甚至失效的今天,已经很难只凭芯片的先进制程,来应对各行各业的算力爆发性增长。云计算厂商必须能够围绕特定的应用场景,比如典型的 HPC、AI 领域,来针对性优化云的基础设施。只有这样才能既最大限度的提升应用性能,又降低大规模使用的成本。
阿里云弹性计算技术持续创新
阿里云作为国内最早的云计算服务厂商,在过去十几年间。一直在持续不断的进行技术创新。从最早的 Xen 架构,KVM 架构,演变到自主研发的神龙架构,以及最新专为数据中心研发的 CIPU 架构。对于这些产品技术,阿里云一直都是最成熟和领先的云服务商。借助这些技术创新,也成功的将高性能计算融入到云计算领域,满足所有主流 HPC 主流应用的性能需求。
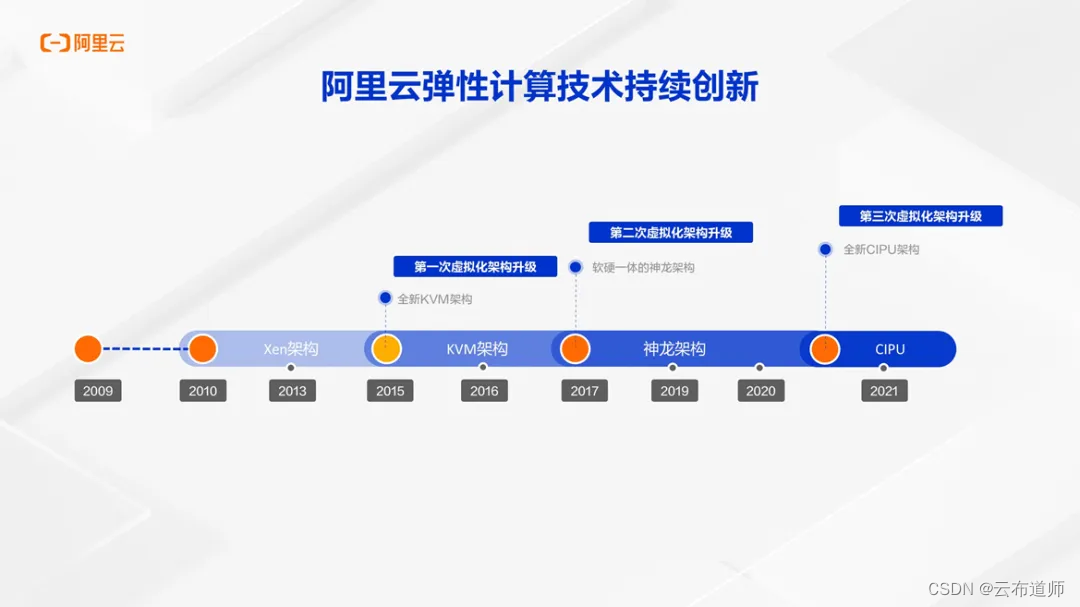
从 2017 年的神龙架构开始,包括上汽、吉利在内的汽车行业客户,就开始在阿里云上进行云上的工业仿真。2021 年发布的 CIPU 架构,能够让我们的客户,进一步用更低成本、更高效率、更大规模的方式来运行 HPC 业务,大大增强阿里云 Cloud HPC 的产品竞争力。
高性能计算优化实例 hpc8ae 规格族
基于 CIPU 架构,专为 HPC 设计和优化的高性能计算实例 hpc8ae,采用第四代的AMD EPYC 处理器,能够提供 64 个物理核心,256GiB 内存,基础频率 3.4GHz,最高可以到 3.75,还有 500GB/s 的内存带宽优化。整体超强配置使得 hpc8ae 特别适用于包含计算流体、有线元分析在内的典型工业仿真应用。

与其他通用计算类实例不同的是,hpc8ae 有两大专为 HPC 应用设计的重要功能特性:
第一,hpc8ae 直接提供物理核心,性能更加稳定,而且不支持启用超线程,避免了超线程切换影响到 HPC 应用性能。虽然 hpc8ae 是虚拟机,但借助CIPU架构,虚拟机的性能基本零损耗,和物理机等同。和其他 ECS 企业级实例一样,hpc8ae 的可靠性为 99.975%,能够实现自动的故障切换和自愈恢复,非常稳定可靠。
第二,hpc8ae 提供了高带宽、低延时,低抖动的 eRDMA 网络,最低时延达到 8us。能够兼容传统的 RDMA ,应用的软件不需要改动可以直接使用。从应用的 E2E 的性能角度来说,eRDMA 能在云上完全替代传统的 RDMA 网络,支持用户在阿里云的任意可用区,就可以构建云上大规模仿真集群,加速并行计算的任务。
依赖 CIPU 的强大性能和普惠特性,hpc8ae 实例对 CAE 类应用至少实现50% 以上性价比提升,是用户 HPC 工作负载的最佳选择。
全新 CIPU 架构提供高性能计算、网络和存储
作为阿里云弹性计算最重要的技术创新 CIPU,即云基础设施的处理单元,它是一种 DPU 的实现,专门设计用来提高云计算的效率和安全。CIPU 可以将包含虚拟化在内的网络、安全、存储等等,非计算密集型的任务卸载到一个专用的软硬件上,不占用主 CPU 处理能力,让其只应用于核心应用逻辑处理,大大提升整体云计算在网络、存储、性能以及安全方面的表现。

例如实例的存储 IOPS 可以达到 300 万,本盘接近零的延迟损耗,网络的PPS 也可以到 4000 万水平。CIPU 在阿里云已经得到了大规模应用,所有的 CPU、GPU 存储网络都是通过 CIPU 统一管理和调度。通过 CIPU,阿里云在通用计算性能方面优于同类产品 20%-60%,大数据 AI 也比同类产品高 30% 以上。同样的, 在 HPC 领域,基于 CIPU 架构的 hpc8ae 实例也实现了大幅度的性能提升和成本优化。
免费 eRDMA 网络提供低延时、低抖动的节点通信
Cloud HPC 另外一个关键点就是网络。传统的 TCP/IP 一直是业界主流的网络通信实例。很多应用都是基于 TPC/IP 构建,但是 HPC 的应用对于网络的性能,比如延迟、吞吐要求很高,TCP/IP 的网络通信能力是一个瓶颈。传统的线下 HPC 集群会使用 RDMA 网络解决以上痛点,相比TCP/IP,eRDMA 可以实现零拷贝,bypass 内核等特性,可以减少频繁上下文切换带来的开销,实现低延迟,高吞吐的网络通信。
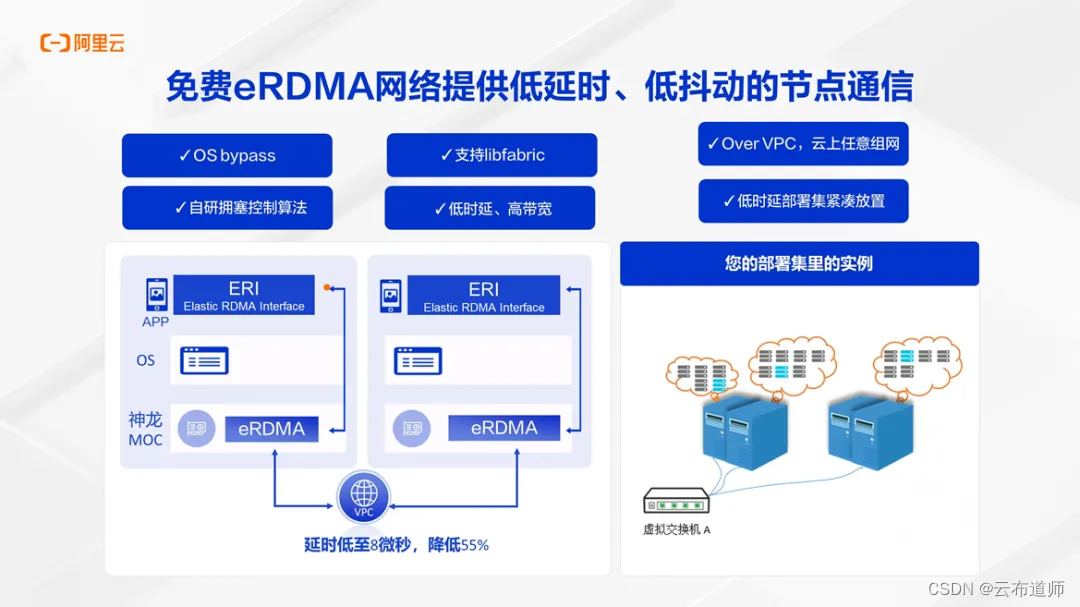
但是 RDMA 网络建设成本很高,受限于物理网络,它的扩展性和弹性能力也不足,因此无法在云上大规模使用。eRDMA 是阿里云自研的云上弹性RDMA 网络,底层链路复用 VPC 网络,利用 CIPU 卸载网络通信开销,bypass 操作系统,并结合自研的拥塞算法可以提供最低 8us 的低时延,有着更低长尾抖动。通过对 libfabric 的支持,传统应用也不需要改动就能够直接使用。
和传统 RDMA 网络不同,阿里云的 eRDMA 网络基于数据中心的 VPC 网络,所以用户在阿里云的任何一个可用区,比如北京、上海,秒级实现大规模 eRDMA 组网。同时,为了保证所有计算节点的低延时网络通信性能,用户可以使用 ECS 部署集能力,来保证创建的 hpc8ae 实例紧凑放置。也就是说,同一个部署集的 ECS 实例,在创建时会保证物理距离接近,从而来保证 eRDMA 低延时通信效果。
CAE 应用性能提升 30%,性价比提升 50%
了解 hpc8ae 的实例规格参数以及背后的技术创新之后,我们来看一下hpc8ae的具体性能表现如何:
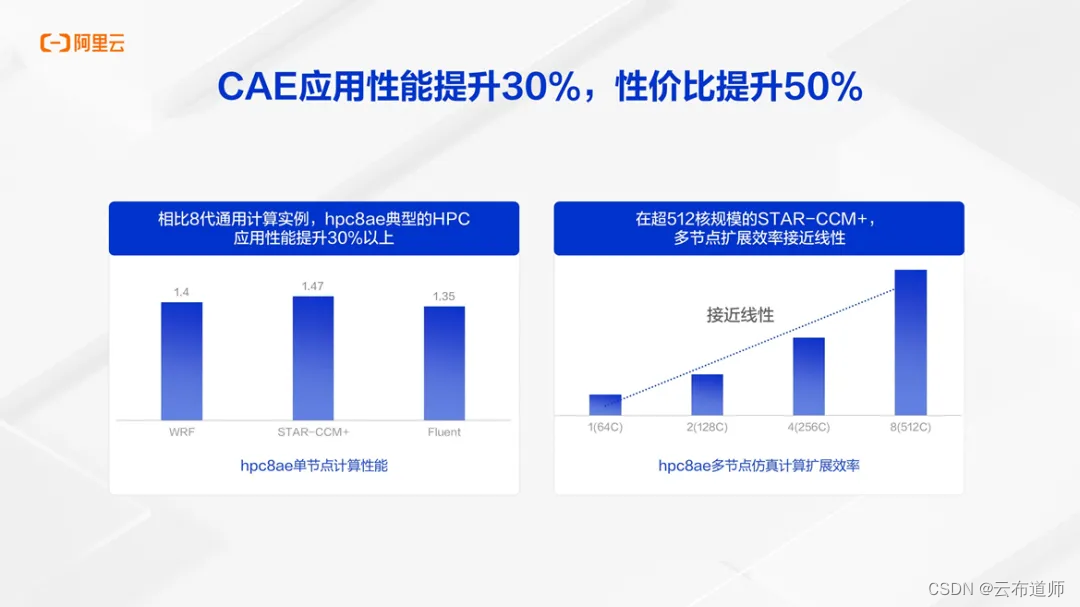
使用常见的HPC软件进行单节点benchmark 性能测试中,相比八代通用计算实例,专门优化的hpc8ae实例,WRF性能提升了40%,STAR-CCM提升了47%,Fluent提升了35%,普遍至少提升了30%以上。使用STAR-CCM+测试超过512核的多节点作业,应用性能基本上都可以实现线性提升,具有非常好的扩展效率。
使用 E-HPC一键创建 hpc8ae 仿真集群
不仅是计算实例 hpc8ae 的超高性价比优势,阿里云还为 hpc 客户提供了功能完善的弹性高性能计算产品 E-HPC。通过 E-HPC,用户可以自动化创建 HPC 集群,提供 SLURM、PBS 等常见调度器调度作业。
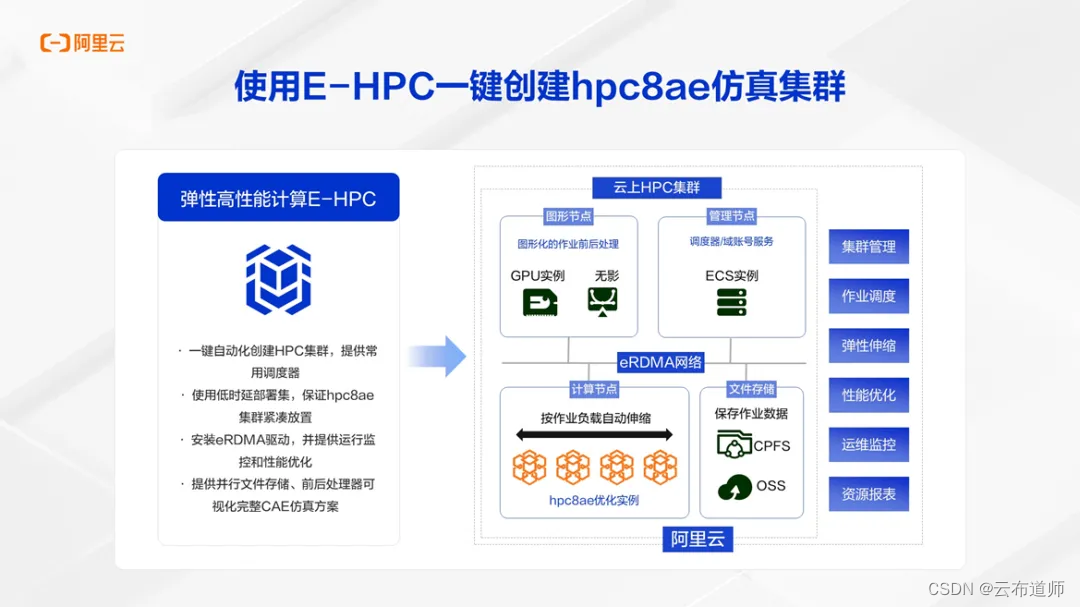
同时,E-HPC 还提供完整的云上运维、监控、告警、报表等服务,与阿里云其他云产品无缝对接,能够实现完整业务流程上云。对用户来说,E-HPC 可以安装部署软件,使用部署集创建 hpc8ae 实例集群,集成包含并行文件存储 CPFS、无影可视化节点等其他云产品,从而端到端的提供包含前处理、后处理、仿真在内的完整 CAE 云上方案,简单易用。
高性能计算优化实例 hpc8ae 规格族正式商业化
阿里云的高性能计算优化实例hpc8ae规格族正式商业化发布,支持北京、上海、杭州地域的开放购买。