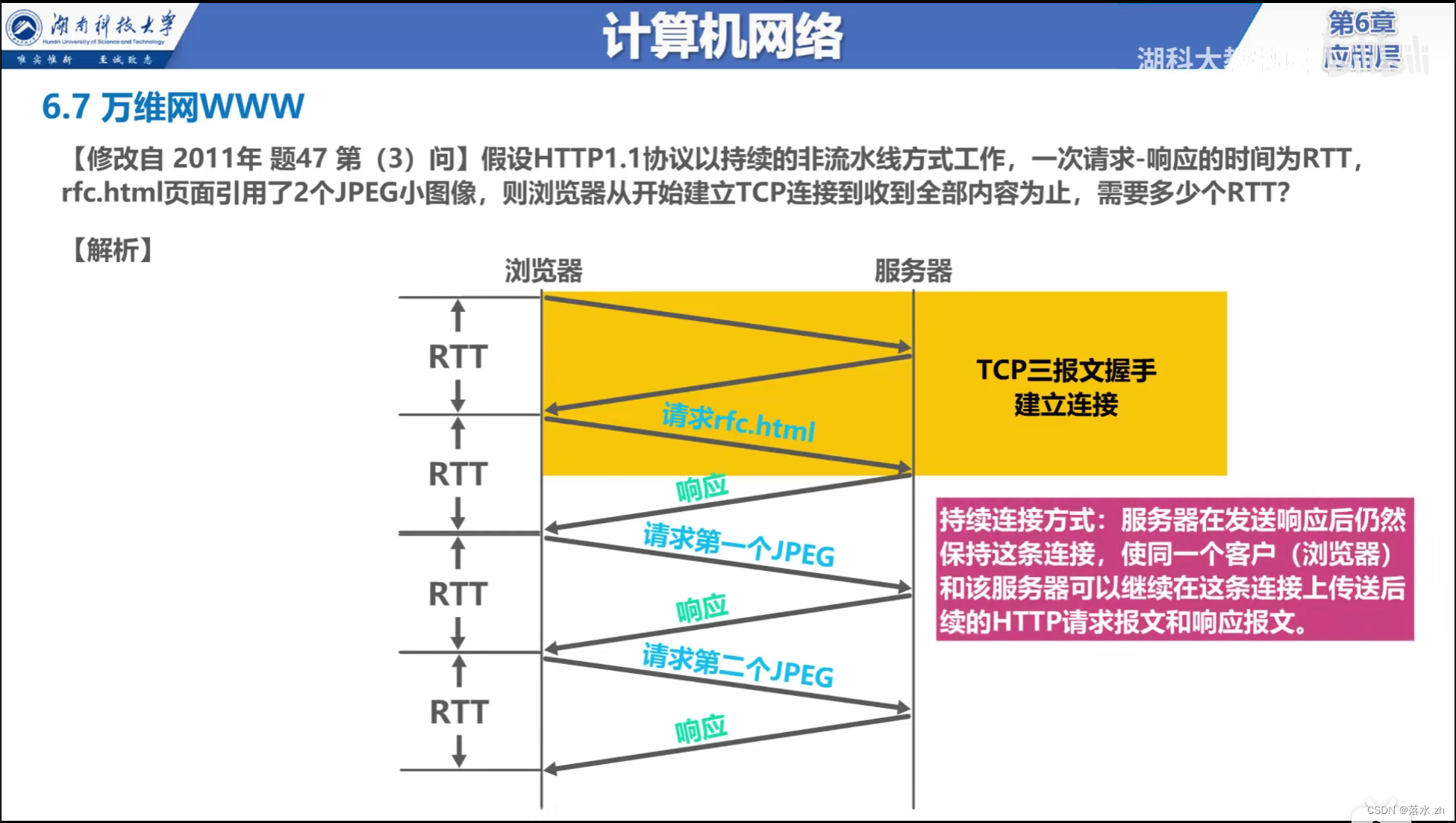
(一)RabbitMQ的简介
RabbitMq 是实现了高级消息队列协议(AMQP)的开源消息代理中间件。消息队列是一种应用程序对应用程序的通行方式,应用程序通过写消息,将消息传递于队列,由另一应用程序读取 完成通信。而作为中间件的 RabbitMq 无疑是目前最流行的消息队列之一。目前使用较多的消息队列有ActiveMQ,RabbitMQ,ZeroMQ,Kafka,MetaMQ,RocketMQ。
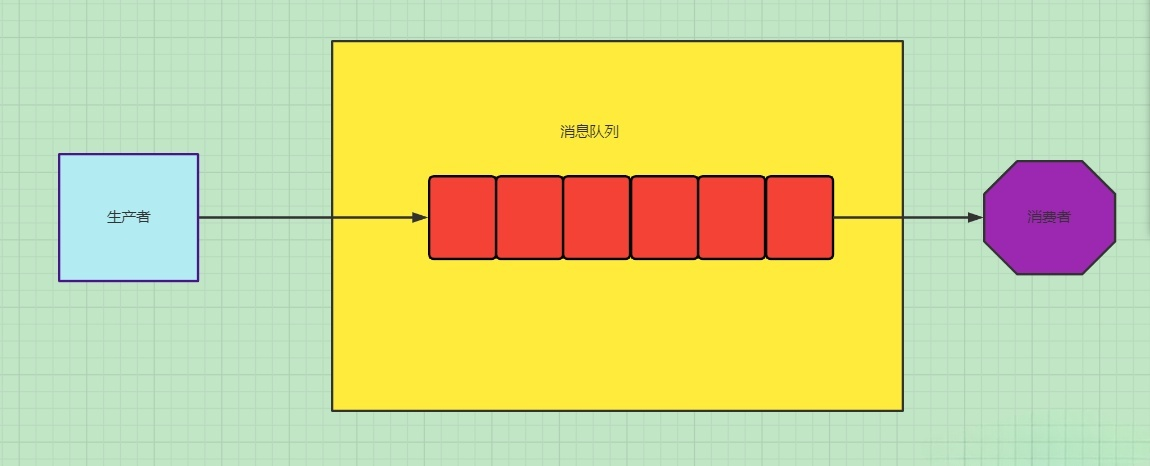
RabbitMQ总体架构

PS:生产者和消费者可能在不同的程序或主机中,当然也有可能一个程序有可能既是生产者,也是消费者。
RabbitMq 应用场景广泛:
1.系统的高可用:日常生活当中各种商城秒杀,高流量,高并发的场景。当服务器接收到如此大量请求处理业务时,有宕机的风险。某些业务可能极其复杂,但这部分不是高时效性,不需要立即反馈给用户,我们可以将这部分处理请求抛给队列,让程序后置去处理,减轻服务器在高并发场景下的压力。
2.分布式系统,集成系统,子系统之间的对接,以及架构设计中常常需要考虑消息队列的应用。(二)RabbitMQ的安装
apt-get update
apt-get install erlang
apt-get install rabbitmq-server
#启动rabbitmq: service rabbitmq-server start
#停止rabbitmq: service rabbitmq-server stop
#重启rabbitmq: service rabbitmq-server restart
#启动rabbitmq插件:rabbitmq-plugins enable rabbitmq_management启用rabbitmq_management插件后就可以登录后台管理页面了,浏览器输入ip:15672
自带的密码和用户名都是guest,但是只能本机登录
所以下面我们添加新用户,和自定义权限
#添加新用户
rabbitmqctl add_user 用户名 密码
#给指定用户添加管理员权限
rabbitmqctl set_user_tags 用户名 administrator
给用户添加权限
rabbitmqctl set_permissions -p / 用户名 ".*" ".*" ".*"在web页面输入用户名,和密码
(三)python操作RabbitMQ
python中使用pika操作RabbitMQ
pip install pika
#皮卡皮卡,哈哈(四)RabbitMQ简单模式
上代码
# coding=utf-8
### 生产者
import pika
import time
user_info = pika.PlainCredentials('root', 'root')#用户名和密码
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))#连接服务器上的RabbitMQ服务
# 创建一个channel
channel = connection.channel()
# 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作,官方推荐,每次使用时都可以加上这句
channel.queue_declare(queue='hello')
for i in range(0, 100):
channel.basic_publish(exchange='',#当前是一个简单模式,所以这里设置为空字符串就可以了
routing_key='hello',# 指定消息要发送到哪个queue
body='{}'.format(i)# 指定要发送的消息
)
time.sleep(1)
# 关闭连接
# connection.close()PS:RabbitMQ中所有的消息都要先通过交换机,空字符串表示使用默认的交换机
# coding=utf-8
### 消费者
import pika
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作,生产者和消费者都做这一步的好处是
# 这样生产者和消费者就没有必要的先后启动顺序了
channel.queue_declare(queue='hello')
# 回调函数
def callback(ch, method, properties, body):
print('消费者收到:{}'.format(body))
# channel: 包含channel的一切属性和方法
# method: 包含 consumer_tag, delivery_tag, exchange, redelivered, routing_key
# properties: basic_publish 通过 properties 传入的参数
# body: basic_publish发送的消息
channel.basic_consume(queue='hello', # 接收指定queue的消息
auto_ack=True, # 指定为True,表示消息接收到后自动给消息发送方回复确认,已收到消息
on_message_callback=callback # 设置收到消息的回调函数
)
print('Waiting for messages. To exit press CTRL+C')
# 一直处于等待接收消息的状态,如果没收到消息就一直处于阻塞状态,收到消息就调用上面的回调函数
channel.start_consuming()
对于上面的这种模式,有一下两个不好的地方:
一个是在我们的消费者还没开始消费完队列里的消息,如果这时rabbitmq服务挂了,那么消息队列里的消息将会全部丢失,解决方法是在声明队列时,声明队列为可持久化存储队列,并且在生产者将消息插入到消息队列时,设置消息持久化存储,具体如下
# coding=utf-8
### 生产者
import pika
import time
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
# 创建一个channel
channel = connection.channel()
# 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作,官方推荐,每次使用时都可以加上这句
channel.queue_declare(queue='durable_queue',durable=True)
#PS:这里不同种队列不允许名字相同
for i in range(0, 100):
channel.basic_publish(exchange='',
routing_key='durable_queue',
body='{}'.format(i),
properties=pika.BasicProperties(delivery_mode=2)
)
# 关闭连接
# connection.close()消费者与上面的消费者没有什么不同,具体的就是消费声明的队列,也要是可持久化的队列,还有就是,即使在生产者插入消息时,设置当前消息持久化存储(properties=pika.BasicProperties(delivery_mode=2)),并不能百分百保证消息真的被持久化,因为RabbitMQ挂掉的时候它可能还保存在缓存中,没来得及同步到磁盘中
在生产者插入消息后,立刻停止rabbitmq,并重新启动,其实我们在web管理页面也可看到未被消费的信息,当然在启动消费者后也成功接收到了消息

上面说的第二点不好就是,如果在消费者获取到队列里的消息后,在回调函数的处理过程中,消费者突然出错或程序崩溃等异常,那么就会造成这条消息并未被实际正常的处理掉。为了解决这个问题,我们只需在消费者basic_consume(auto_ack=False),并在回调函数中设置手动应答即可ch.basic_ack(delivery_tag=method.delivery_tag),具体如下
# coding=utf-8
### 消费者
import pika
import time
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作,生产者和消费者都做这一步的好处是
# 这样生产者和消费者就没有必要的先后启动顺序了
channel.queue_declare(queue='queue')
# 回调函数
def callback(ch, method, properties, body):
time.sleep(5)
ch.basic_ack(delivery_tag=method.delivery_tag)
print('消费者收到:{}'.format(body.decode('utf-8')))
# channel: 包含channel的一切属性和方法
# method: 包含 consumer_tag, delivery_tag, exchange, redelivered, routing_key
# properties: basic_publish 通过 properties 传入的参数
# body: basic_publish发送的消息
channel.basic_consume(queue='queue', # 接收指定queue的消息
auto_ack=False, # 指定为False,表示取消自动应答,交由回调函数手动应答
on_message_callback=callback # 设置收到消息的回调函数
)
# 应答的本质是告诉消息队列可以将这条消息销毁了
print('Waiting for messages. To exit press CTRL+C')
# 一直处于等待接收消息的状态,如果没收到消息就一直处于阻塞状态,收到消息就调用上面的回调函数
channel.start_consuming()这里只需要配置消费者,生产者并不要修改
还有就是在上的使用方式在,都是一个生产者和一个消费者,还有一种情况就是,一个生产者和多个消费者,即多个消费者同时监听一个消息队列,这时候队列里的消息就是轮询分发(即如果消息队列里有100条信息,如果有2个消费者,那么每个就会收到50条信息),但是在某些情况下,不同的消费者处理任务的能力是不同的,这时还按照轮询的方式分发消息并不是很合理,那么只需要再配合手动应答的方式,设置消费者接收的消息没有处理完,队列就不要给我放送新的消息即可,具体配置方式如下:
# coding=utf-8
### 消费者
import pika
import time
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 如果指定的queue不存在,则会创建一个queue,如果已经存在 则不会做其他动作,生产者和消费者都做这一步的好处是
# 这样生产者和消费者就没有必要的先后启动顺序了
channel.queue_declare(queue='queue')
# 回调函数
def callback(ch, method, properties, body):
time.sleep(0)#通过设置休眠时间来模拟不同消费者的处理时间
ch.basic_ack(delivery_tag=method.delivery_tag)
print('消费者收到:{}'.format(body.decode('utf-8')))
# prefetch_count表示接收的消息数量,当我接收的消息没有处理完(用basic_ack标记消息已处理完毕)之前不会再接收新的消息了
channel.basic_qos(prefetch_count=1) # 还有就是这个设置必须在basic_consume之上,否则不生效
channel.basic_consume(queue='queue', # 接收指定queue的消息
auto_ack=False, # 指定为False,表示取消自动应答,交由回调函数手动应答
on_message_callback=callback # 设置收到消息的回调函数
)
# 应答的本质是告诉消息队列可以将这条消息销毁了
print('Waiting for messages. To exit press CTRL+C')
# 一直处于等待接收消息的状态,如果没收到消息就一直处于阻塞状态,收到消息就调用上面的回调函数
channel.start_consuming()PS:这种情况必须关闭自动应答ack,改成手动应答。使用basicQos(perfetch=1)限制每次只发送不超过1条消息到同一个消费者,消费者必须手动反馈告知队列,才会发送下一个
(五)RabbitMQ发布订阅模式
发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中
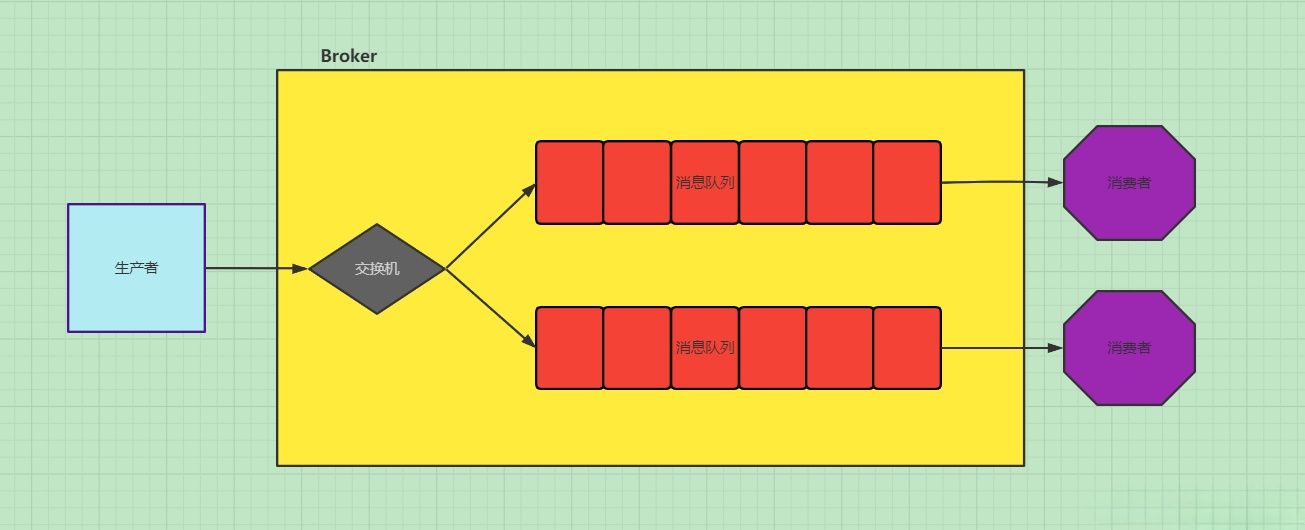
这个模式中会引入交换机的概念,其实在RabbitMQ中,所有的生产者都不会直接把消息发送到队列中,甚至生产者都不知道消息在发出后有没有发送到queue中,事实上,生产者只能将消息发送给交换机,由交换机来决定发送到哪个队列中。
交换机的一端用来从生产者中接收消息,另一端用来发送消息到队列,交换机的类型规定了怎么处理接收到的消息,发布订阅模式使用到的交换机类型为 fanout ,这种交换机类型非常简单,就是将接收到的消息广播给已知的(即绑定到此交换机的)所有消费者。
当然,如果不想使用特定的交换机,可以使用 exchange=‘’ 表示使用默认的交换机,默认的交换机会将消息发送到 routing_key 指定的queue,可以参考简单模式。
上代码:
#生产者
import pika
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 创建一个指定名称的交换机,并指定类型为fanout,用于将接收到的消息广播到所有queue中
channel.exchange_declare(exchange='交换机', exchange_type='fanout')
# 将消息发送给指定的交换机,在fanout类型中,routing_key=''表示不用发送到指定queue中,
# 而是将发送到绑定到此交换机的所有queue
channel.basic_publish(exchange='交换机', routing_key='', body='这是一条测试消息')#消费者
import pika
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
channel.exchange_declare(exchange='交换机', exchange_type='fanout')
# 使用RabbitMQ给自己生成一个专有的queue
result = channel.queue_declare(queue='333')
# result = channel.queue_declare(queue='', exclusive=True)
queue_name = result.method.queue
# 这里如果设置exclusive=True参数,那么该队列就是一个只有队列,在消费者结束后,该专有队列也会自动清除,如果queue=''没有设置名字的话,那么就会自动生成一个
# 不会重复的队列名
# 将queue绑定到指定交换机
channel.queue_bind(exchange='交换机', queue=queue_name)
print(' [*] Waiting for message.')
def callback(ch, method, properties, body):
print("消费者收到:{}".format(body.decode('utf-8')))
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()该模式与简单模式的还有一个区别就是,这里的消息队列都是由消费者声明的,所以如果是生产者先启动,并将消息发给交换机的画,这里的消息就会丢失,所以我们也可以在消费者端声明队列并绑定交换机(不能是专有队列),所以仔细想想,其实这所谓的发布订阅模式并没有说什么了不起,它不过是让交换机同时推送多条消息给绑定的队列,我们当然也可以在简单模式的基础上多进行几次basic_publish发送消息到指定的队列。当然我们这样做的话,可能就没办法做到由交换机的同时发送了,效率可能也没有一次basic_publish的高
(六)RabbitMQ RPC模式
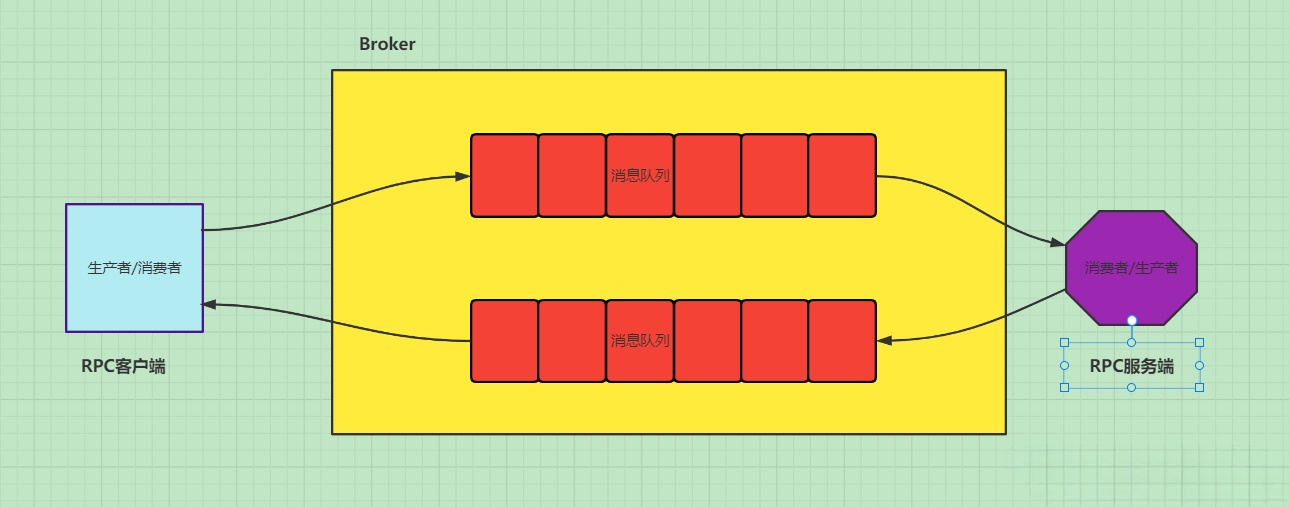
下面实现由rpc远程调用加减运算
客户端
import pika
import uuid
import json
class RPC(object):
def __init__(self):
self.call_id = None
self.response = None
user_info = pika.PlainCredentials('root', 'root')
self.connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
self.channel = self.connection.channel()
# 创建一个此客户端专用的queue,用于接收服务端发过来的消息
result = self.channel.queue_declare(queue='', exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(
queue=self.callback_queue,
on_message_callback=self.on_response,
auto_ack=True)
def on_response(self, ch, method, props, body):
# 判断接收到的response是否属于对应request
if self.call_id == props.correlation_id:
self.response = json.loads(body.decode('utf-8')).get('result')
def call(self, func, param):
self.response = None
self.call_id = str(uuid.uuid4()) # 为该消息指定uuid,类似于请求id
self.channel.queue_declare(queue='rpc_queue')
self.channel.basic_publish(
exchange='',
routing_key='rpc_queue', # 将消息发送到该queue
properties=pika.BasicProperties(
reply_to=self.callback_queue, # 从该queue中取消息
correlation_id=self.call_id, # 为此次消息指定uuid
),
body=json.dumps(
{
'func': func,
'param': {'a': param[0], 'b': param[1]}
}
)
)
self.connection.process_data_events(time_limit=3)# 与start_consuming()相似,可以设置超时参数
return self.response
rpc = RPC()
print("发送消息到消费者,等待返回结果")
response = rpc.call(func='del', param=(1, 2))
print("收到来自消费者返回的结果:{}".format(response))
服务端
import pika
import json
user_info = pika.PlainCredentials('root', 'root')
connection = pika.BlockingConnection(pika.ConnectionParameters('ip', 5672, '/', user_info))
channel = connection.channel()
# 指定接收消息的queue
channel.queue_declare(queue='rpc_queue')
def add_number(a, b):
return a + b
def del_num(a, b):
return a - b
execute_map = {
'add': add_number,
'del': del_num
}
def on_request(ch, method, props, body):
body = json.loads(body.decode('utf-8'))
func = body.get('func')
param = body.get('param')
result = execute_map.get(func)(param.get('a'), param.get('b'))
print('进行{}运算,并将结果返回个消费者'.format(func))
ch.basic_publish(exchange='', # 使用默认交换机
routing_key=props.reply_to, # response发送到该queue
properties=pika.BasicProperties(
correlation_id=props.correlation_id), # 使用correlation_id让此response与请求消息对应起来
body=json.dumps({'result': result}))
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
# 从rpc_queue中取消息,然后使用on_request进行处理
channel.basic_consume(queue='rpc_queue', on_message_callback=on_request)
print(" [x] Awaiting RPC requests")
channel.start_consuming()本次分享到此结束,感谢大家的阅读!