写在前面
最近,微信中加的群有点多,信息根本看不过来。如果不看,怕遗漏了有价值的信息;如果一条条向上翻阅,实在是太麻烦。
有没有办法一键导出所有聊天记录?
一来翻阅更方便一点,二来还可以让 AI 帮我总结一下,避免遗漏有价值的内容。
网上翻阅了很多资料,完全有效的不多,而且很多工具都需要收费。
最终找到一个开源项目(传送门),本文将参考这个项目,分享给大家:导出微信聊天记录的几个关键步骤。
-
- 手机微信数据库导入电脑端
-
- 破解数据库密码
-
- 导出数据库
-
- 提取联系人信息和聊天记录
希望给有类似需求的小伙伴带来帮助。
话不多说,直接上实操!
关键步骤拆解
1. 手机微信数据库导入电脑端
对于很少用电脑端微信的小伙伴,首先需要先把手机微信的数据迁移到电脑端:
在手机端微信,依次点击**「我-设置-聊天-聊天记录迁移与备份-迁移」**,选择迁移到电脑微信;
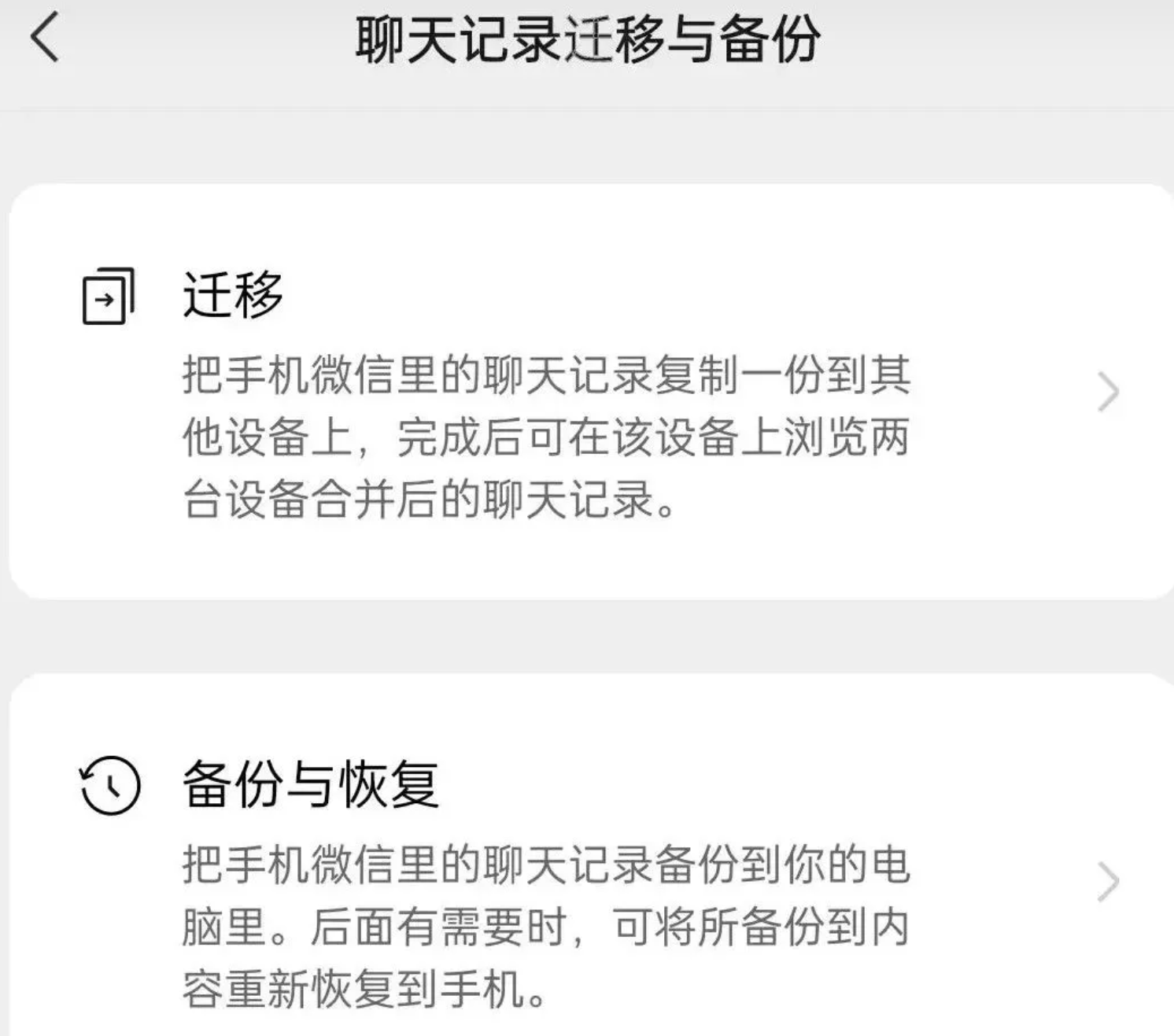
继续选择部分 或者 全部聊天记录,如果聊天数据较多,可能需要稍等一段时间~
2. 破解数据库密码
电脑端自己的微信数据存放在哪?
在电脑端微信,左下角依次点击「设置-文件管理」,找到自己的微信数据存放位置,然后打开对应的文件夹。
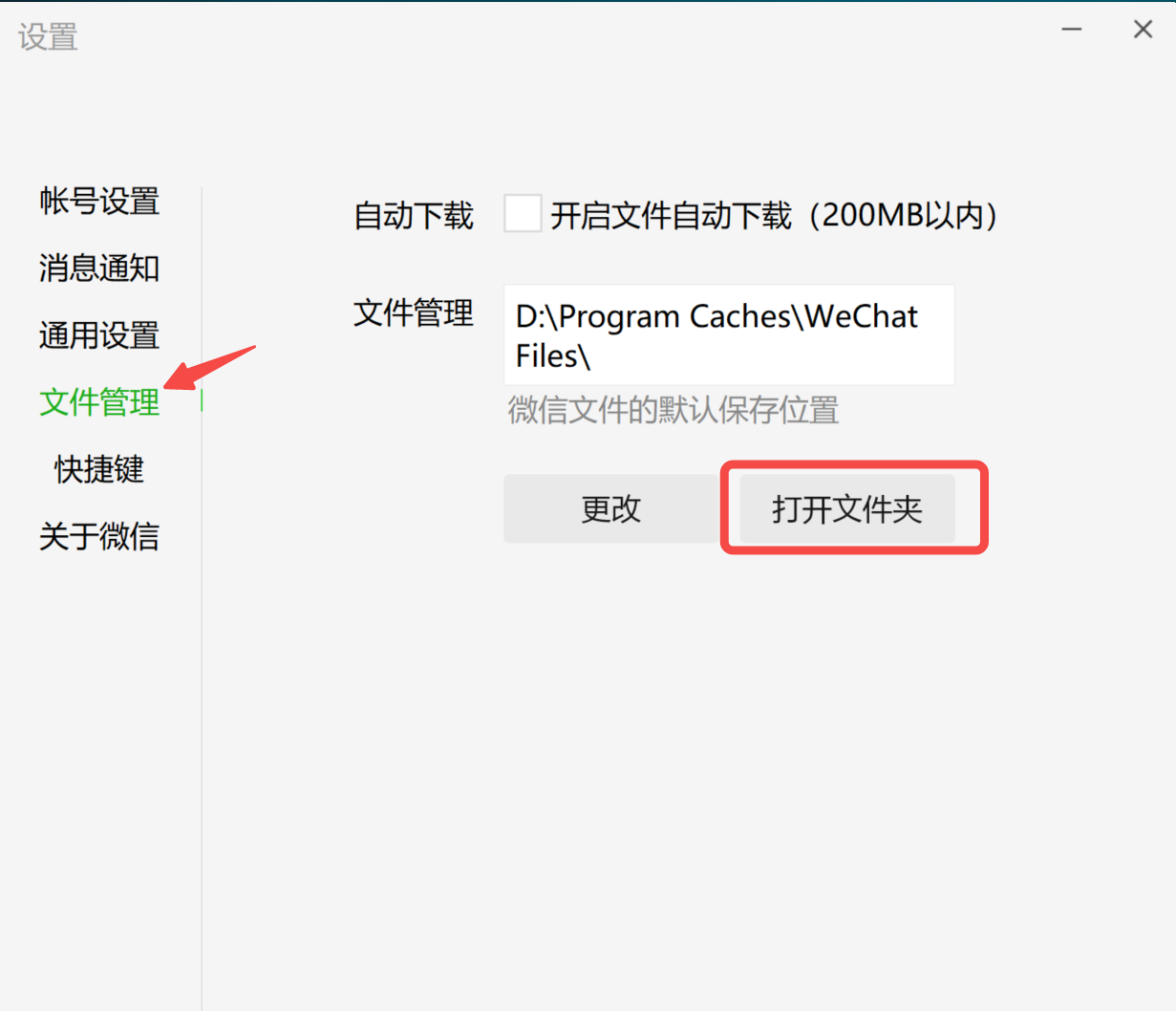
文件最后一级目录就是自己的微信号,如果登录过多个微信账号的需要注意切换,比如下面这张就是我的微信数据存放位置,其中的 Msg 文件夹中存放的就是微信中所有的联系人和聊天信息。
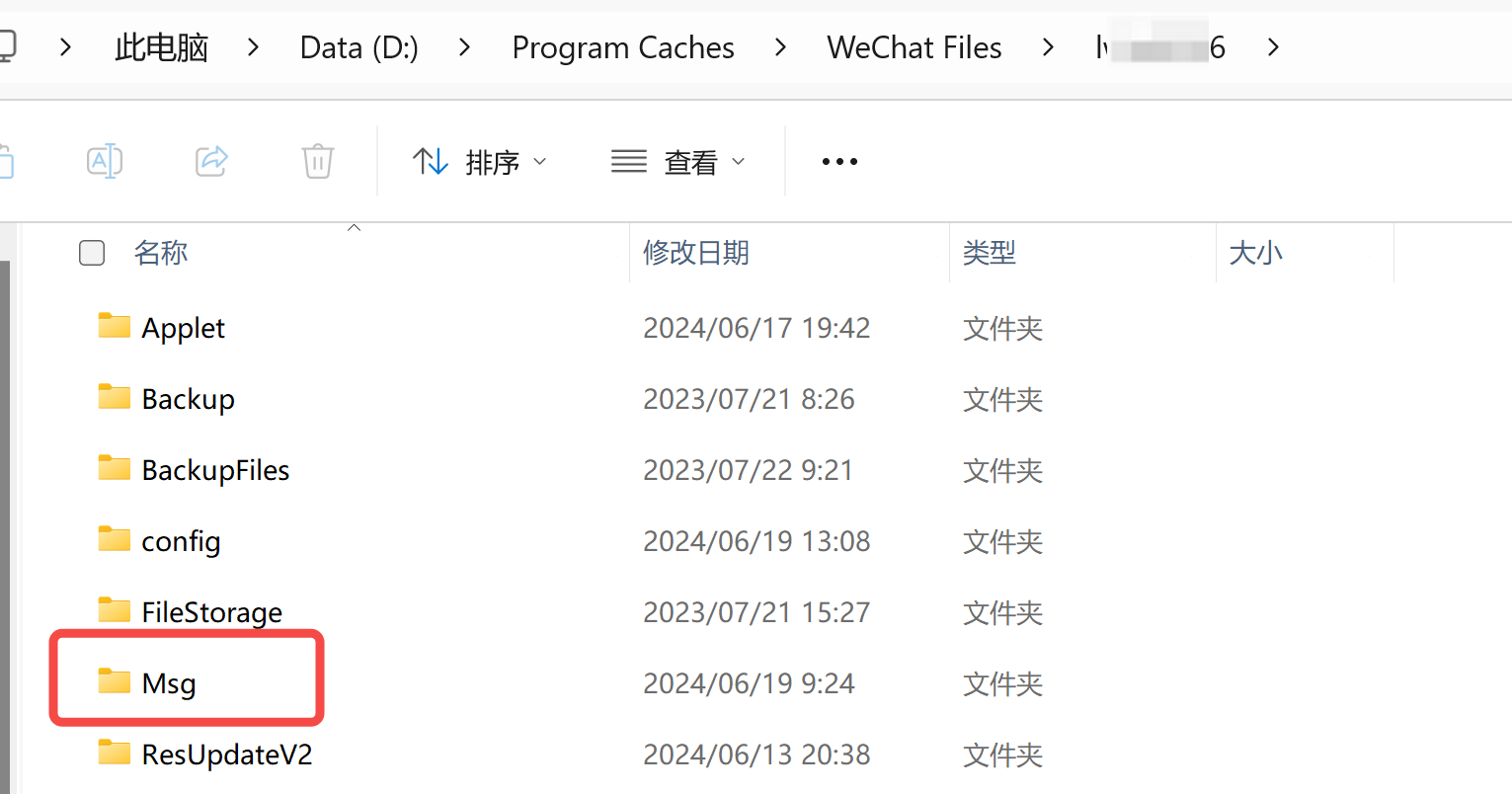
打开 Msg 文件夹,会发现这里有很多 .db 结尾的,就是微信数据存放的数据库文件。如果你用任何数据库软件打开,这时是打不开的。
因为还需要数据库密码。
怎么破解数据库密码?
参考这个项目,我把其中破解数据库密码部分的代码提取出来了,方便大家直接使用:
def get_key(db_path, addr_len):
def read_key_bytes(h_process, address, address_len=8):
array = ctypes.create_string_buffer(address_len)
if ReadProcessMemory(h_process, void_p(address), array, address_len, 0) == 0: return "None"
address = int.from_bytes(array, byteorder='little') # 逆序转换为int地址(key地址)
key = ctypes.create_string_buffer(32)
if ReadProcessMemory(h_process, void_p(address), key, 32, 0) == 0: return "None"
key_bytes = bytes(key)
return key_bytes
def verify_key(key, wx_db_path):
if not wx_db_path or wx_db_path.lower() == "none":
return True
KEY_SIZE = 32
DEFAULT_PAGESIZE = 4096
DEFAULT_ITER = 64000
with open(wx_db_path, "rb") as file:
blist = file.read(5000)
salt = blist[:16]
byteKey = hashlib.pbkdf2_hmac("sha1", key, salt, DEFAULT_ITER, KEY_SIZE)
first = blist[16:DEFAULT_PAGESIZE]
mac_salt = bytes([(salt[i] ^ 58) for i in range(16)])
mac_key = hashlib.pbkdf2_hmac("sha1", byteKey, mac_salt, 2, KEY_SIZE)
hash_mac = hmac.new(mac_key, first[:-32], hashlib.sha1)
hash_mac.update(b'\x01\x00\x00\x00')
if hash_mac.digest() != first[-32:-12]:
return False
return True
phone_type1 = "iphone\x00"
phone_type2 = "android\x00"
phone_type3 = "ipad\x00"
pm = pymem.Pymem("WeChat.exe")
module_name = "WeChatWin.dll"
MicroMsg_path = os.path.join(db_path, "MSG", "MicroMsg.db")
type1_addrs = pm.pattern_scan_module(phone_type1.encode(), module_name, return_multiple=True)
type2_addrs = pm.pattern_scan_module(phone_type2.encode(), module_name, return_multiple=True)
type3_addrs = pm.pattern_scan_module(phone_type3.encode(), module_name, return_multiple=True)
type_addrs = type1_addrs if len(type1_addrs) >= 2 else type2_addrs if len(type2_addrs) >= 2 else type3_addrs if len(
type3_addrs) >= 2 else "None"
# print(type_addrs)
if type_addrs == "None":
return "None"
for i in type_addrs[::-1]:
for j in range(i, i - 2000, -addr_len):
key_bytes = read_key_bytes(pm.process_handle, j, addr_len)
if key_bytes == "None":
continue
if db_path != "None" and verify_key(key_bytes, MicroMsg_path):
return key_bytes.hex()
return "None"
3. 导出数据库
上一步中,得到数据库的密码后,就可以将源文件中的数据库导出来,核心代码如下:
# 通过密钥解密数据库
def decrypt(key: str, db_path, out_path):
"""
通过密钥解密数据库
:param key: 密钥 64位16进制字符串
:param db_path: 待解密的数据库路径(必须是文件)
:param out_path: 解密后的数据库输出路径(必须是文件)
:return:
"""
if not os.path.exists(db_path) or not os.path.isfile(db_path):
return False, f"[-] db_path:'{db_path}' File not found!"
if not os.path.exists(os.path.dirname(out_path)):
return False, f"[-] out_path:'{out_path}' File not found!"
if len(key) != 64:
return False, f"[-] key:'{key}' Len Error!"
password = bytes.fromhex(key.strip())
with open(db_path, "rb") as file:
blist = file.read()
salt = blist[:16]
byteKey = hashlib.pbkdf2_hmac("sha1", password, salt, DEFAULT_ITER, KEY_SIZE)
first = blist[16:DEFAULT_PAGESIZE]
if len(salt) != 16:
return False, f"[-] db_path:'{db_path}' File Error!"
mac_salt = bytes([(salt[i] ^ 58) for i in range(16)])
mac_key = hashlib.pbkdf2_hmac("sha1", byteKey, mac_salt, 2, KEY_SIZE)
hash_mac = hmac.new(mac_key, first[:-32], hashlib.sha1)
hash_mac.update(b'\x01\x00\x00\x00')
if hash_mac.digest() != first[-32:-12]:
return False, f"[-] Key Error! (key:'{key}'; db_path:'{db_path}'; out_path:'{out_path}' )"
newblist = [blist[i:i + DEFAULT_PAGESIZE] for i in range(DEFAULT_PAGESIZE, len(blist), DEFAULT_PAGESIZE)]
with open(out_path, "wb") as deFile:
deFile.write(SQLITE_FILE_HEADER.encode())
t = AES.new(byteKey, AES.MODE_CBC, first[-48:-32])
decrypted = t.decrypt(first[:-48])
deFile.write(decrypted)
deFile.write(first[-48:])
for i in newblist:
t = AES.new(byteKey, AES.MODE_CBC, i[-48:-32])
decrypted = t.decrypt(i[:-48])
deFile.write(decrypted)
deFile.write(i[-48:])
return True, [db_path, out_path, key]
def parse_db(key, db_path, output_dir):
close_db()
os.makedirs(output_dir, exist_ok=True)
tasks = []
for root, dirs, files in os.walk(db_path):
for file in files:
if '.db' == file[-3:]:
if 'xInfo.db' == file:
continue
inpath = os.path.join(root, file)
output_path = os.path.join(output_dir, file)
tasks.append([key, inpath, output_path])
else:
try:
name, suffix = file.split('.')
if suffix.startswith('db_SQLITE'):
inpath = os.path.join(root, file)
# print(inpath)
output_path = os.path.join(output_dir, name + '.db')
tasks.append([key, inpath, output_path])
except:
continue
for i, task in enumerate(tasks):
flag, msg = decrypt(*task)
print(f"[{i+1}/{len(tasks)}] {flag} {msg}")
print('开始数据库合并...')
# 目标数据库文件
target_database = os.path.join(output_dir, 'MSG.db')
# 源数据库文件列表
source_databases = [os.path.join(output_dir, f"MSG{i}.db") for i in range(1, 50)]
if os.path.exists(target_database):
os.remove(target_database)
shutil.copy2(os.path.join(output_dir, 'MSG0.db'), target_database) # 使用一个数据库文件作为模板
merge_databases(source_databases, target_database)
此时,会在当前目录下生成全新的数据库文件,用任何一种数据库软件都可以打开查看详细信息。比如我这里采用的是 VS Code 中的 SQLite Viewer 插件,以下图为例,在 Misc.db 中,存放的是所有联系人的信息,包括:用户名、头像和创建时间等。
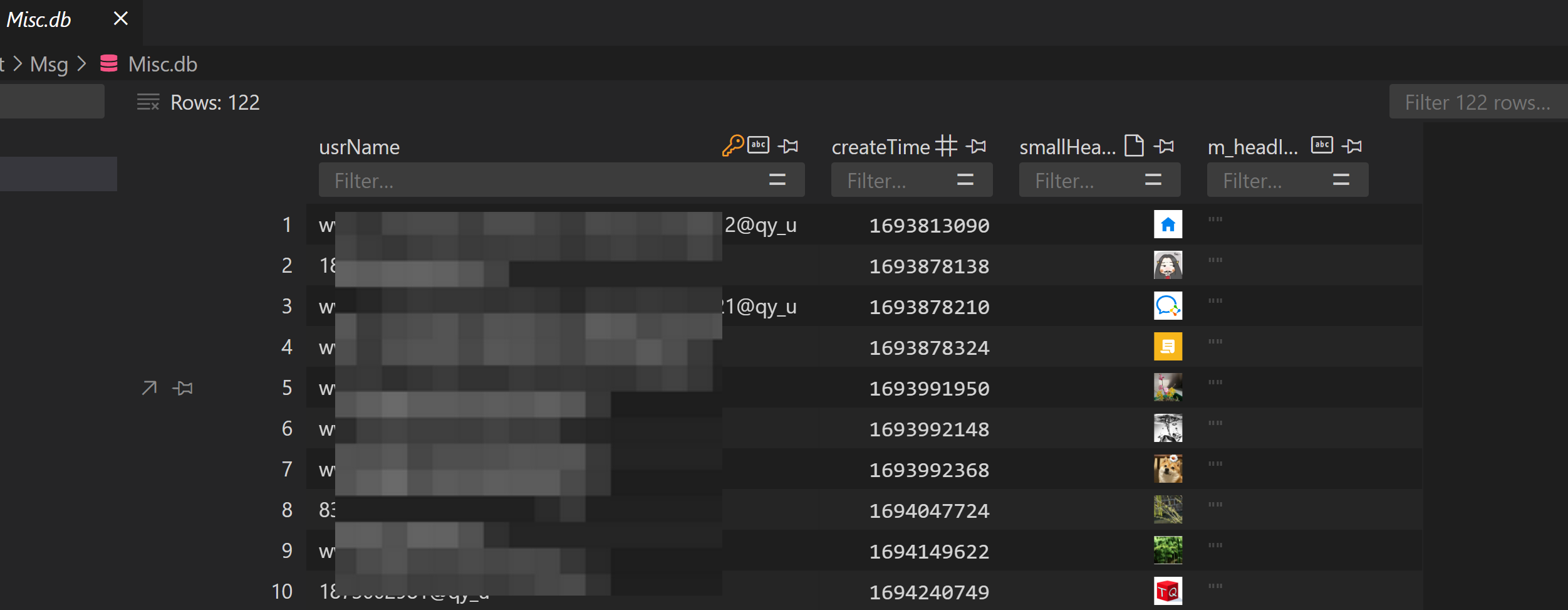
上图中,CreateTime 就是加为好友的时间,其含义是从1970年1月1日00:00:00 UTC到当前时间的秒数,可以通过如下代码转换成字符串类型的时间,方便查看。
from datetime import datetime
def covert_time2num(datetime_str, datetime_format="%Y-%m-%d %H:%M:%S"):
dt_obj = datetime.strptime(datetime_str, datetime_format)
timestamp = int(dt_obj.timestamp())
return timestamp
def covert_time2str(timestamp, datetime_format="%Y-%m-%d %H:%M:%S"):
dt_obj = datetime.fromtimestamp(timestamp)
return dt_obj.strftime(datetime_format)
4. 提取联系人信息和聊天记录
有了数据库之后,就可以着手提取其中的信息了。
想看看自己都加了哪些好友?他们都来自哪里?
看这里:所有联系人的信息存放在 Misc.db 中。下面这段代码展示了数据库中都存了哪些字段:
# 获取所有联系人(包括群聊)信息
contact_info_lists = micro_msg_db.get_contact()
contact_infos = []
for contact_info_list in contact_info_lists:
detail = decodeExtraBuf(contact_info_list[9])
contact_info = {
'UserName': contact_info_list[0], # 微信id
'Alias': contact_info_list[1], # 微信号
'Type': contact_info_list[2], # 看不出来啥类型
'Remark': contact_info_list[3], # 备注名
'NickName': contact_info_list[4], # 昵称
'smallHeadImgUrl': contact_info_list[7], # 头像url
"detail": detail, # 包括地区,个性签名,电话,性别
"label_name": contact_info_list[10] # 标签名,用于给好友分组的标签,大部分人都没用过这个功能,所以通常没有
}
contact_infos.append(contact_info)
其中, ‘UserName’ 这个字段中如果包含 ‘@chatroom’ 就代表是群聊。下面我们看一条 联系人信息 的示例:
# 微信群
{'UserName': 'xxx@chatroom', 'Alias': '', 'Type': 2, 'Remark': '', 'NickName': 'xxx车主群', 'smallHeadImgUrl': 'https://wx.qlogo.cn/mmcrhead/xxx/0', 'label_name': 'None'}
# 微信好友
{'UserName': 'wxid_xxx22', 'Alias': 'Quiet_xx', 'Type': 8388611, 'Remark': '备注名', 'NickName': 'xx', 'smallHeadImgUrl': 'https://wx.qlogo.cn/mmhead/xxx/132', 'detail': {'region': ('CN', 'Beijing', 'Daxing'), 'signature': '德不孤 必有邻', 'telephone': '', 'gender': 2}, 'label_name': 'None'}
想一键获取和某个好友的聊天记录?
看这里:MicroMsg.db 中存放了所有用户的聊天记录,有很多张表。可以通过 ‘UserName’ 这个字段从数据库中检索,也可以指定信息类型和时间段,示例代码如下:
def get_chat_info(self, nickname='', remark='', alias='', time_range=None, output_type='txt', type_=None, out_path='output'):
"""
time_range: (start_time, end_time) ('2021-08-01 12:00:00', '2021-08-02 12:00:00')
"""
ret_info = self.get_contact_info(nickname, remark, alias)
self.is_chatroom = ret_info['UserName'].__contains__('@chatroom')
if type_ is None:
messages = msg_db.get_messages(ret_info['UserName'], time_range=time_range)
else:
messages = msg_db.get_messages_by_type(ret_info['UserName'], type_=type_, time_range=time_range)
每条 message 的类型是不一样的,微信中所有的信息类型列举如下:
types = {
'文本': 1,
'图片': 3,
'语音': 34,
'视频': 43,
'表情包': 47,
'音乐与音频': 4903,
'文件': 4906,
'分享卡片': 4905,
'转账': 492000,
'音视频通话': 50,
'拍一拍等系统消息': 10000,
}
善用自己的数据
看到这里的你,一定会有一个疑问:我拿到这些数据都有什么用?
这里猴哥列举自己目前最常用的需求:
1.总结提炼群聊信息
一开始做这件事情,最主要的目的就是这个,因为群聊信息实在太多了,根本看不完。
而把上面的工作流搭建好,把所有信息提取出来就是一行脚本的事。
下面拿猴哥最近加入的一个群来举例。
把该群的所有聊天信息提取出来,保存为一个 txt 文件,左下角显示总共有1万多条聊天记录,这得看到猴年马月去?

接下来,我们把这份 txt 文件,发给 Kimi,让它帮忙总结一下,下面左图就是 Kimi 给到的分析。
为了验证它没有在胡说八道,我们还可以把所有聊天记录,做一个词云(右图)。
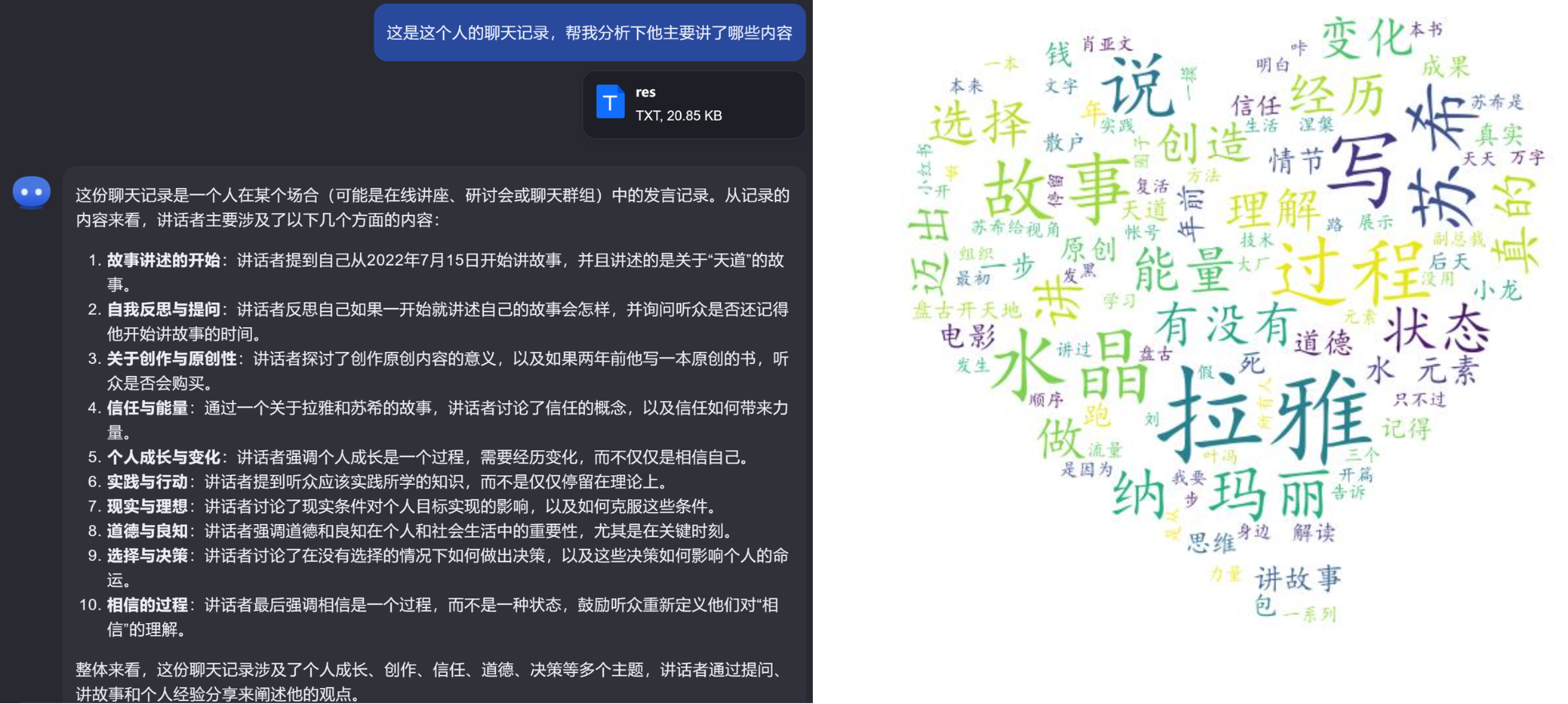
怎么样?Kimi 总结的还是相当到位的,根据它的总结内容,我就可以决定是否需要继续去看群聊信息。
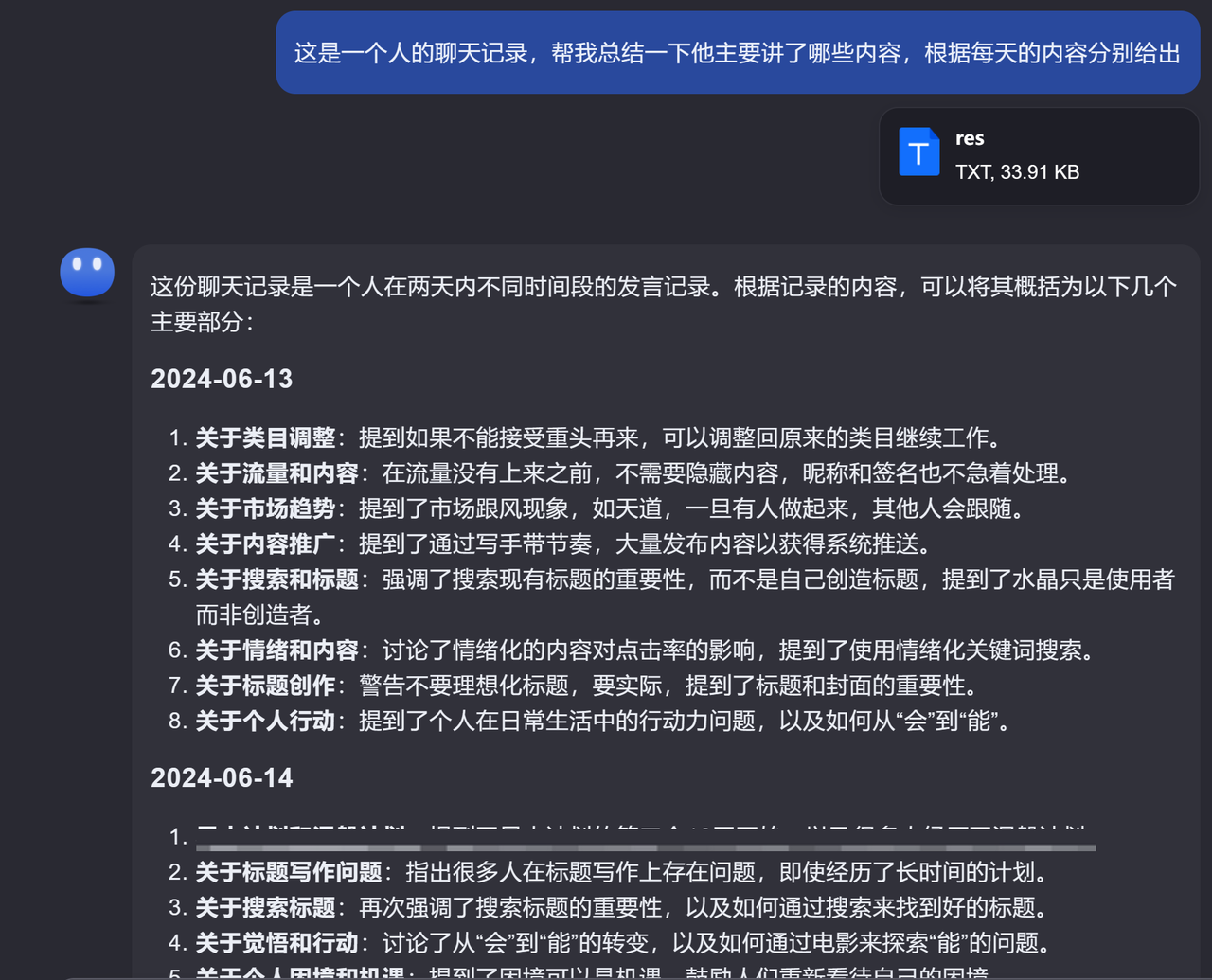
当然,我们还可以优化一下提示词,让它根据时间段来进行总结,便于我们定位到关键信息对应的时间段。
写在最后
把聊天记录和当前的 AI 大语言模型,结合在一起,一定还可以衍生出很多需求和有意思的应用场景,欢迎评论区给出你的想法和创意~
再次感谢 WeChatMsg 项目团队的开源精神 !
由于篇幅限制,本文用到的源码没有全部展示,需要源码的小伙伴,也可以在公众号【猴哥的AI知识库】后台私信我~
如果本文对你有帮助,欢迎点赞收藏备用!


![[Linux] Shell](https://img-blog.csdnimg.cn/direct/0bb7ba77b3c84fc8aa4a0daa5589805d.png)