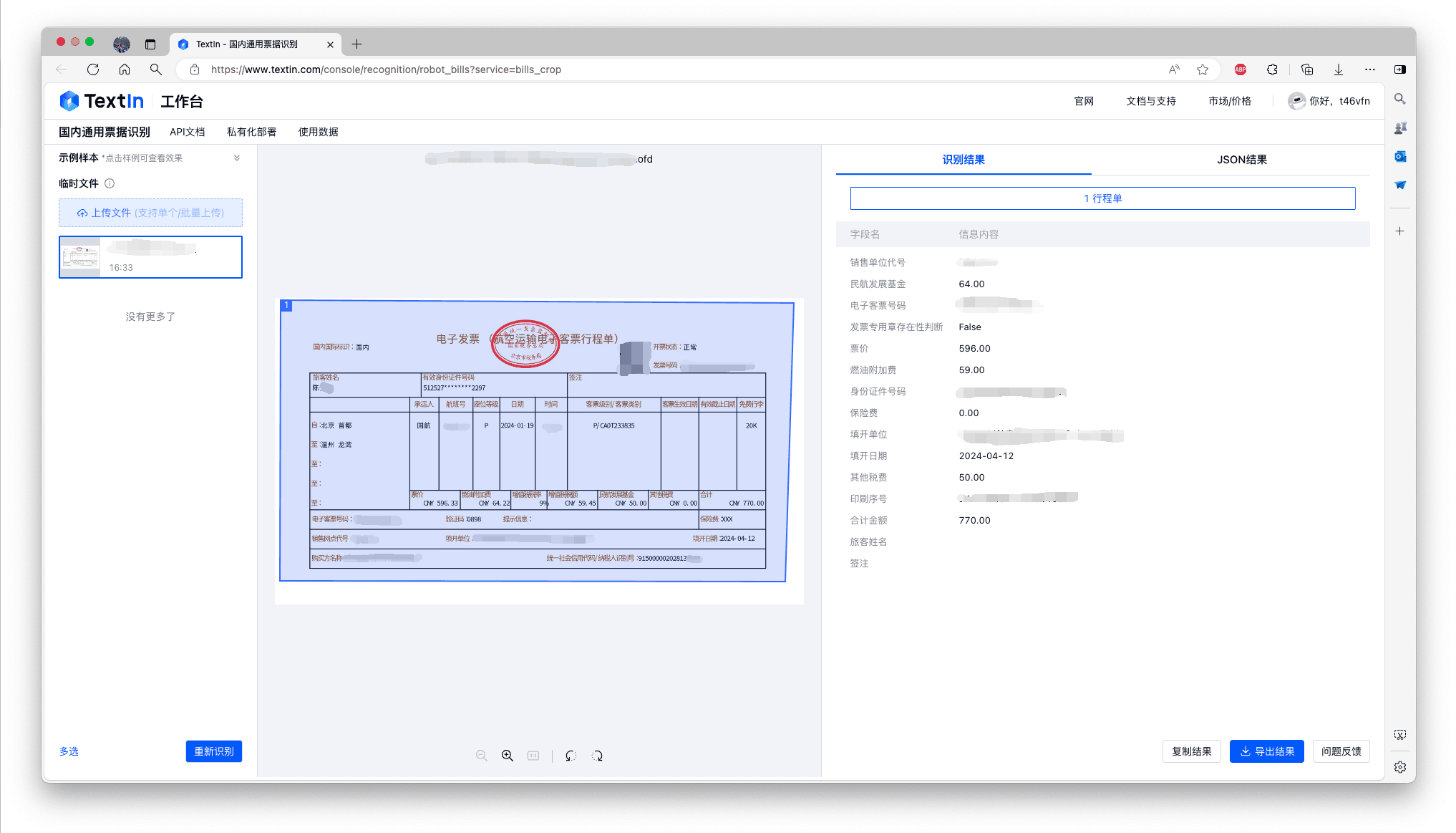
2024人工智能指数报告(一):研发
前言
全面分析人工智能的发展现状。
从2017年开始,斯坦福大学人工智能研究所(HAI)每年都会发布一份人工智能的研究报告,人工智能指数报告(AII),对上一年人工智能相关的数据进行跟踪、整理、提炼并进行可视化。这份指数报告被认为是关于全球人工智能发展状况最可信、最权威的来源之一。正值人工智能对社会的影响达到前所未有的时刻,前不久他们刚刚发布了第七份报告。今年的报告扩大了研究范围,以便更好地概括技术进步、公众看法等情况。整份报告分为八章,分别总结了人工智能的研发、技术性能、负责任的人工智能、经济、科学与医学、教育、政策与治理、多样性、舆论等方面的情况。我们选取部分编译出来,分四部分刊出,此为第一部分。
一、报告摘要
1. 人工智能在某些任务(但不是全部)的表现上超过了人类。
人工智能在多项基准测试的表现超越了人类,其中包括图像分类、视觉推理和英语理解的部分测试项目。不过,对于更复杂的任务,比如数学竞赛、视觉常识推理还有规划等任务,人工智能仍落后人类。
2. 人工智能研究前沿仍由产业界主导。
2023 年,产业界发布了 51 个知名机器学习模型,而学术界仅贡献了 15 个。此外,2023年产学研合作开发出 21 个知名模型,数量创下新高。
3. 先进模型研发成本大幅上升。
根据人工智能指数报告的估计,最先进人工智能模型的训练成本已达到前所未有的水平。比方说,训练OpenAI 的 GPT-4 使用的算力成本估计为 7800 万美元,而训练谷歌的 Gemini Ultra 的算力成本为 1.91 亿美元。
4. 美国是顶尖人工智能模型的主要来源地,领先于中国、欧盟+英国。
2023 年,源自美国机构的知名人工智能模型数量为 61 个,远超欧盟的 21 个以及中国的 15 个。
5. 对大语言模型 (LLM) 责任性评估严重缺乏健全性与标准化。
人工智能指数报告的最新研究发现了一个问题:负责任的人工智能报告在标准化方面严重不足。OpenAI、谷歌以及 Anthropic 等行业领先公司在测试自家模型时往往采用不同的人工智能责任性标准,导致很难系统性地对顶级人工智能模型的风险与局限进行比较。
6. 对生成式人工智能的投资暴增。
尽管去年对人工智能的私募投资是下降的,但对生成式人工智能的投资却大幅上升,比2022 年增长了近八倍,达到了 252 亿美元。OpenAI、Anthropic、Hugging Face 以及 Inflection 等生成式人工智能的重要玩家均宣布获得了大额融资。
7. 数据证明:人工智能提高了员工的生产效率,提升了工作质量。
2023 年的多项研究显示,人工智能可帮助员工加快完成任务,且工作成果质量也有所提升。这些研究还指出,人工智能可帮助缩小不同技能水平员工之间的差距。但同时也有研究提醒,如果没有进行适当监管,使用人工智能也可能会影响工作表现。
8. 人工智能加速了科学进步。
从2022 年开始,人工智能已经促进了科学发现,而到了 2023 年,更多科学相关的人工智能应用相继出现,比方说 AlphaDev 令算法排序变得更加高效,而 GNoME 则在材料发现方面发挥了自身作用。
9. 美国对人工智能的监管举措大幅增加。
从过去一年乃至过去五年的尺度看,美国人工智能相关的监管举措显著增加。2023 年,相关规定增至 25 项,相比之下, 2016 年只有一项。光是去年监管规定数量就增长了 56.3%。
10. 全球对人工智能的潜能更加了解了,但同时也更加不安了。
根据 Ipsos 的一项调查,过去一年,相信人工智能将在未来三至五年内极大影响自己生活的人数比例从 60% 提升到 66%。但同时,有 52% 的人对人工智能产品与服务感到不安,比 2022 年增加了 13%。根据皮尤的数据,有52% 的美国人表示,相比之下自己对人工智能的态度是担忧多于兴奋,高于 2022 年的 38%。
二、研发
本章摘要
人工智能研究前沿仍由产业界主导。
2023 年,产业界发布了 51 个关注度很高的机器学习模型,而学术界仅贡献了 15 个。此外,2023年产学研合作开发出 21 个知名模型,数量创下新高。
更多的基础模型与开源基础模型。
2023 年共发布了 149 个基础模型,是 2022 年的两倍多。在这些新发布的模型当中,有 65.7% 都是开源的,相比之下,2022 年只有 44.4%,2021 年为 33.3%。
先进模型研发成本大幅上升。
根据人工智能指数报告的估计,最先进人工智能模型的训练成本已达到前所未有的水平。比方说,训练OpenAI 的 GPT-4 使用的算力成本估计为 7800 万美元,而训练谷歌的 Gemini Ultra 的算力成本为 1.91 亿美元。
美国是顶尖人工智能模型的主要来源地,领先于中国、欧盟和英国。 2023 年,源自美国机构的知名人工智能模型数量为 61 个,远超欧盟的 21 个以及中国的 15 个。
人工智能专利数量暴增。
2021 年至 2022 年间,全球获授权的人工智能专利数量大幅增加了 62.7%。自 2010 年以来,获授权的人工智能专利数量已增长了 31 倍多。
中国在人工智能专利方面占据主导地位。
2022 年中国在全球人工智能专利的占比达 61.1% ,位居首位,远超美国的 20.9%。2010 年美国在 人工智能专利的占比仍为有54.1% 之多,此后便逐年下降。
开源人工智能研究爆发。
Github上面人工智能相关的项目数量持续上升,从2011 年的845 个涨到 2023 年的约 180 万个。尤其是 2023 年,数量同比猛增了 59.3%。与此同时,Github上人工智能相关项目获得的星星数梁也增至 1220 万,比前一年增加了三倍多。
人工智能文献发表数量继续上涨。
2010 至 2022 年间,人工智能相关文献的发表数量增加了近三倍,从约 88000 篇增至 240000 篇以上,但最近一年仅增长了 1.1%。
1.1 论文发表情况
概述
下图展示的是 2010 至 2022 年间全球中英文人工智能论文的发表情况统计,分按隶属类型和跨界合作进行分类。同时,本节还详细介绍了人工智能期刊文章与会议论文的相关数据。
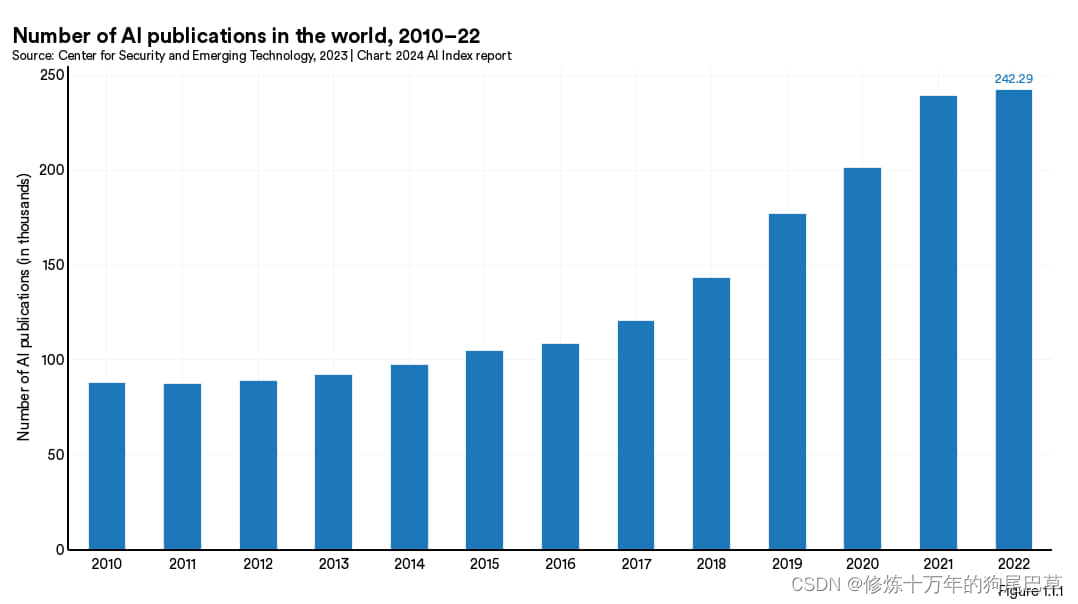
人工智能文献总量
图1.1.1展示的是全球人工智能文献数量。 2010 年至 2022 年间,人工智能文献总数几乎增加了两倍,从2010 年的约 88000 篇增加到 2022 年的超过 240000 篇。但去年同比增幅仅为 1.1% 。
按文献类型
图 1.1.2 展示的是全球不同类型人工智能文献的发表情况。2022 年,期刊类文章约有 230000 篇,会议论文约为 42000 篇。从 2015 年起,期刊与会议论文的增长速度是相当的,2022 年会议论文数是 2015 年的 2.6 倍,2022年期刊文章数为2015年的 2.4 倍
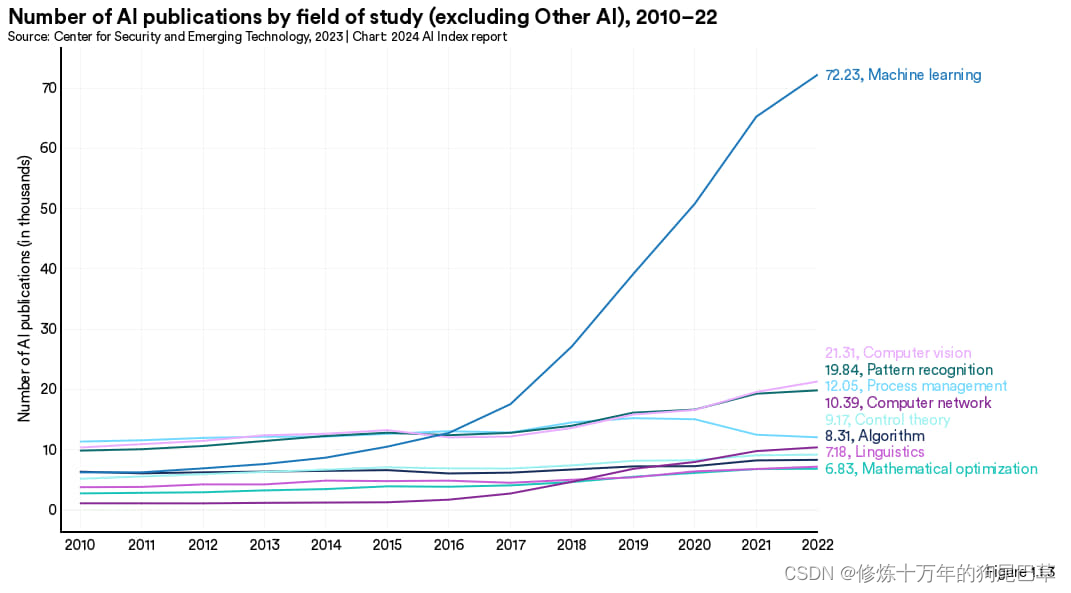
按研究领域
图 1.1.3 展示的是从 2010 年至今不同研究领域人工智能文献发表数量情况。最近十年机器学习的发表数量增速最高,自 2015 年起增长了近七倍。计算机视觉(21309 篇)、模式识别(19841 篇)以及过程管理 (12052 篇)紧随其后。
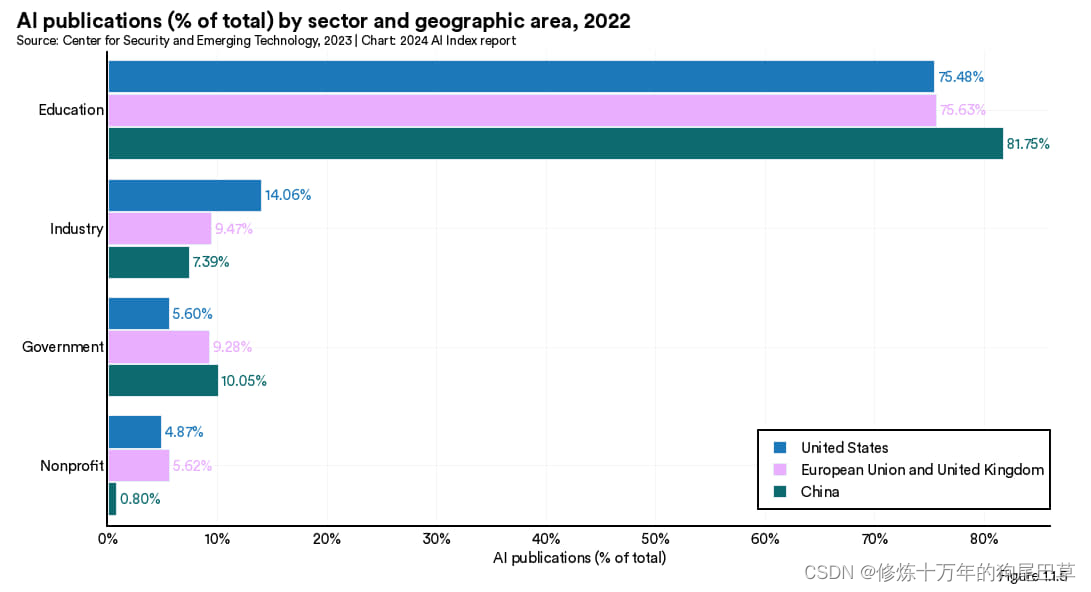
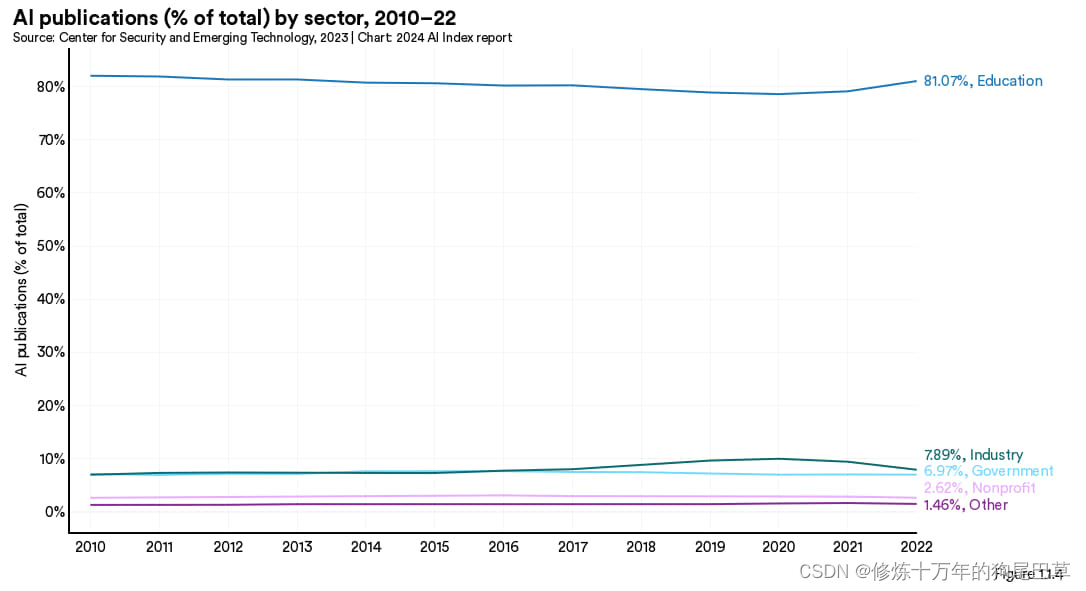
按行业
本节展示的是按行业的文献发表分布情况,分别统计了全球以及美国、中国、欧盟及英国的情况。2022 年学术界贡献了 81.1% 的人工智能文献,是过去十年全球各地人工智能研究的主力军(图 1.1.4 和 1.1.5)。在人工智能文献发表上美国的产业界最为活跃,其次是欧盟、英国以及中国。(图1.1.5)
人工智能期刊发表情况
图1.1.6展示的是2010至2022年间人工智能期刊发表数量情况。2010年至2015年间人工智能期刊发表数量增长情况不大,但2015年后增长了2.4被。2021至2022年间,人工智能期刊发表增长率为4.5%。

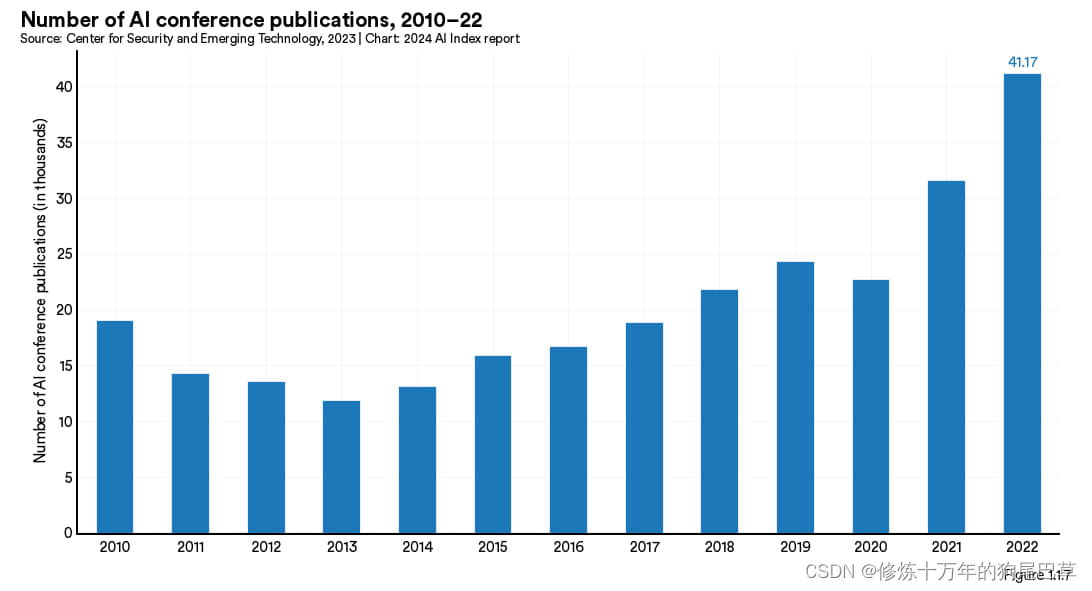
人工智能会议论文发表情况
图 1.1.7 展示的是从 2010 年至今人工智能会议论文发表数量情况。最近两年论文数量出现暴涨:2020 年有 22727 篇,2021 年增至 31629 篇, 2022 年则高达 41174 篇。仅去年增长率就达到了 30.2%。自 2010 年起,发表的会议论文数量已经增加了一倍以上。
1.2 专利
概述
图 1.2.1 展示的是 2010 年至 2022 年间全球人工智能专利授权数量的增长趋势。过去十年,获授权的专利数量有了显著提升,最近几年增长情况尤其显著。比方说,2010 年至 2014 年间,获授权的人工智能专利数增长了 56.1%。但 2021 年到 2022 年的短短一年内,人工智能专利数量就增长了 62.7%。

按申请状态与地区分类
这一小节按照申请状态(是否获得授权)和所在地区对人工智能专利进行了分类。图 1.2.2 展示了全球各地人工智能专利申请情况的对比。截至 2022 年,未获授权的人工智能专利数量 (128952) 是获授权专利 (62264) 的两倍多。过去几年人工智能专利的许可情况发生了明显变化。 2015 年前,提交的人工智能专利大部分都能成功获得授权。但此后,未获授权变成主流,且未获授权的比例在逐年增大。比方说,2015 年时,有 42.2% 的人工智能专利申请未获授权,而到了 2022 年,这一比例增至 67.4%。

从全球主要的专利来源地—包括中国、欧洲联盟与英国及美国(图 1.2.3)来看,获授权与未获授权的人工智能专利之间的差距十分明显。最近几年,这些地区的人工智能专利申请总数及获授权数都有所上升。
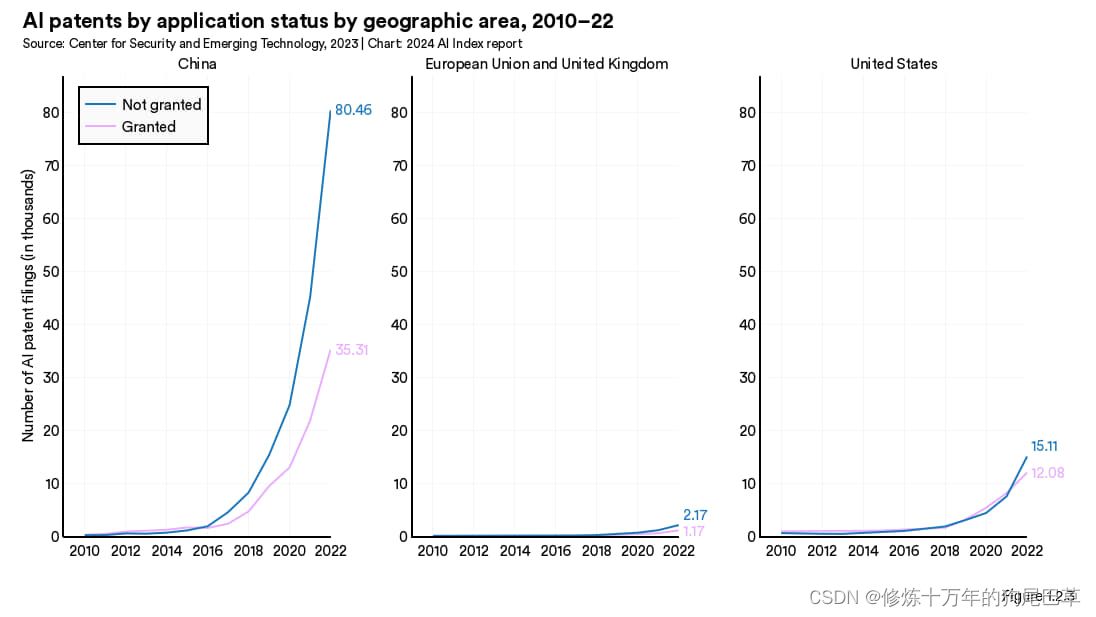
图 1.2.4 对获授权的人工智能专利进行了地区分析。2022 年的数据显示,全球大部分的获授权人工智能专利(75.2%)来自亚太地区,其次是北美,占比为 21.2%。2011 年以前,北美在全球人工智能专利注册数量中一直领先。但此后亚太地区占比有了显著增长。
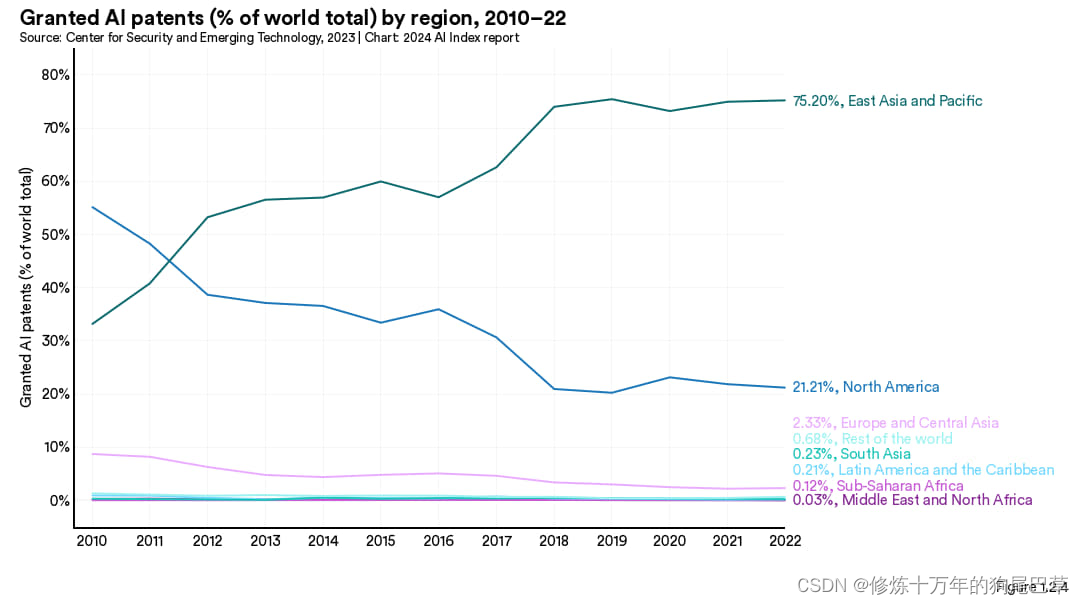
从地区分布情况看,获授权的人工智能专利大部分出自中国 (61.1%) 和美国 (20.9%) (图 1.2.5)。 2010 年的 54.1% 是美国的最高点,此后美国的获授权专利占比就一直在下降。
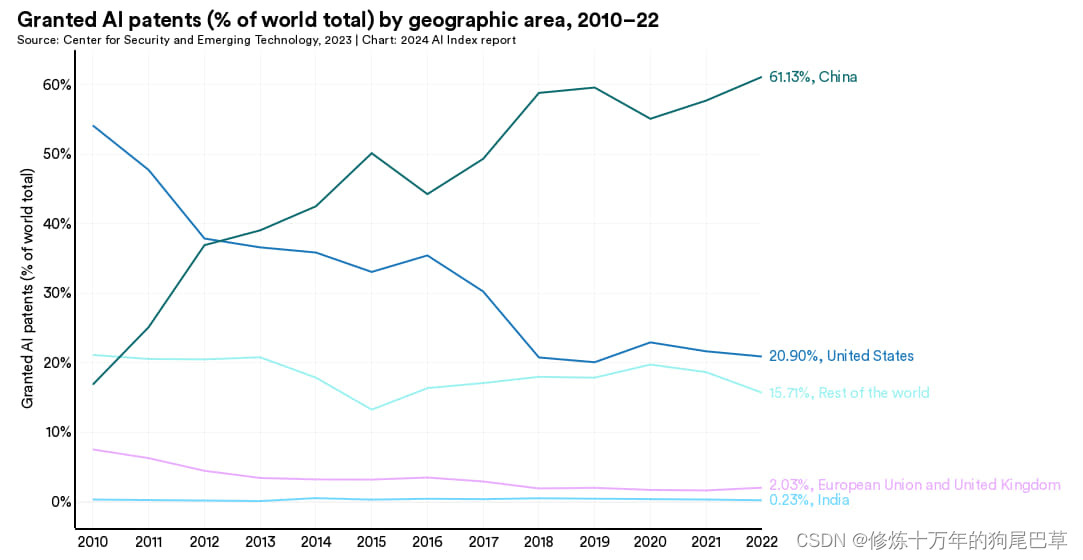
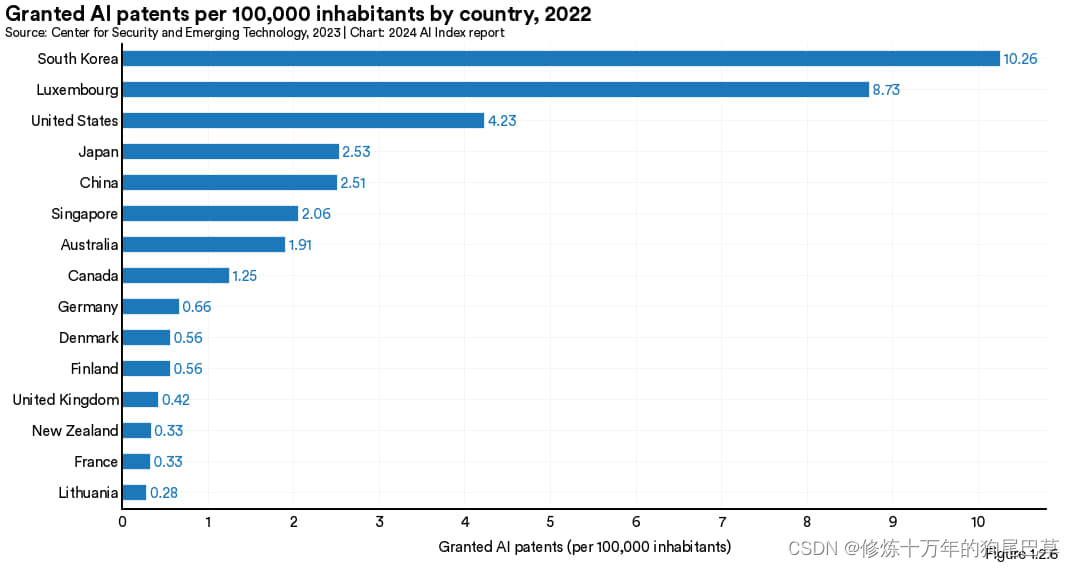
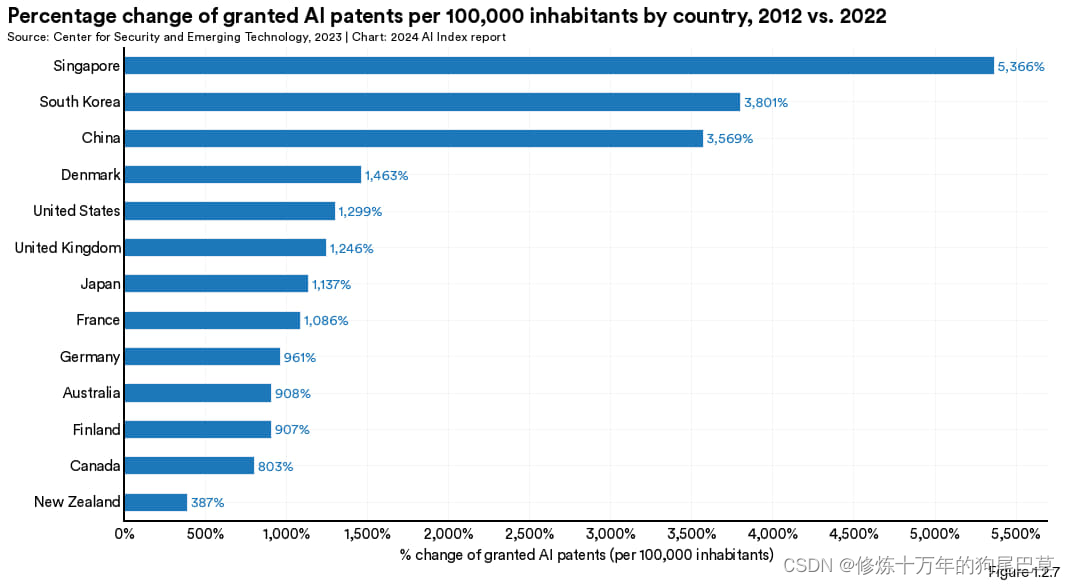
图 1.2.6 及 图 1.2.7展示的是人均人工智能专利数的领先国家。2022 年,韩国 以10.3件/10万人的人均专利拥有数指标位居全球榜首,其次是卢森堡 (8.8) 与美国 (4.2) (见图 1.2.6)。图 1.2.7 反映出 2012 年至 2022 年间新加坡、韩国及中国在人均人工智能专利拥有量有了显著提升。
1.3 人工智能前沿研究
本节深入探索人工智能研究的前沿。尽管每年都会推出大量新的人工智能模型,但只有一小部分能代表研究的最前沿。诚然,对前沿或先进的定义有其主观性:一个模型在某项基准测试创下新高,或引入了某种创新架构,或展现出新的、令人瞩目的能力,这些或许都可以是前沿研究的体现。
本人工智能指数跟踪了两类前沿人工模型的动态:“知名模型”(notable models)与基础模型。数据提供商 Epoch 对精选出来的“知名机器学习模型”(notable machine learning models)的定义是在人工智能/机器学习生态体系有特殊影响力的模型。相比之下,基础模型则是指那些用庞大数据集训练而来,可执行多种任务的人工智能大模型,如 GPT-4, Claude 3以及 Gemini 等。虽然很多基础模型也被视为知名模型,但反之并不亦然。
本节将从多个维度分析知名模型与基础模型的趋势,包括模型的来源机构、所在国、参数数量以及算力使用情况等。分析最后用机器学习的训练成本来做总结。
概述
Epoch AI ,一个专门研究预测先进人工智能进展的研究团队。其建立了一个数据库,里面收录了从 1950 年代起发布的各种人工智能与机器学习模型,选取标准包括先进性、历史意义或高引用次数等。分析这些模型可对机器学习领域(包括近年来以及过去几十年的)演进概况有一个全面的了解。虽然部分模型可能未被纳入,但该数据集仍能揭示相关的发展趋势。
行业分析
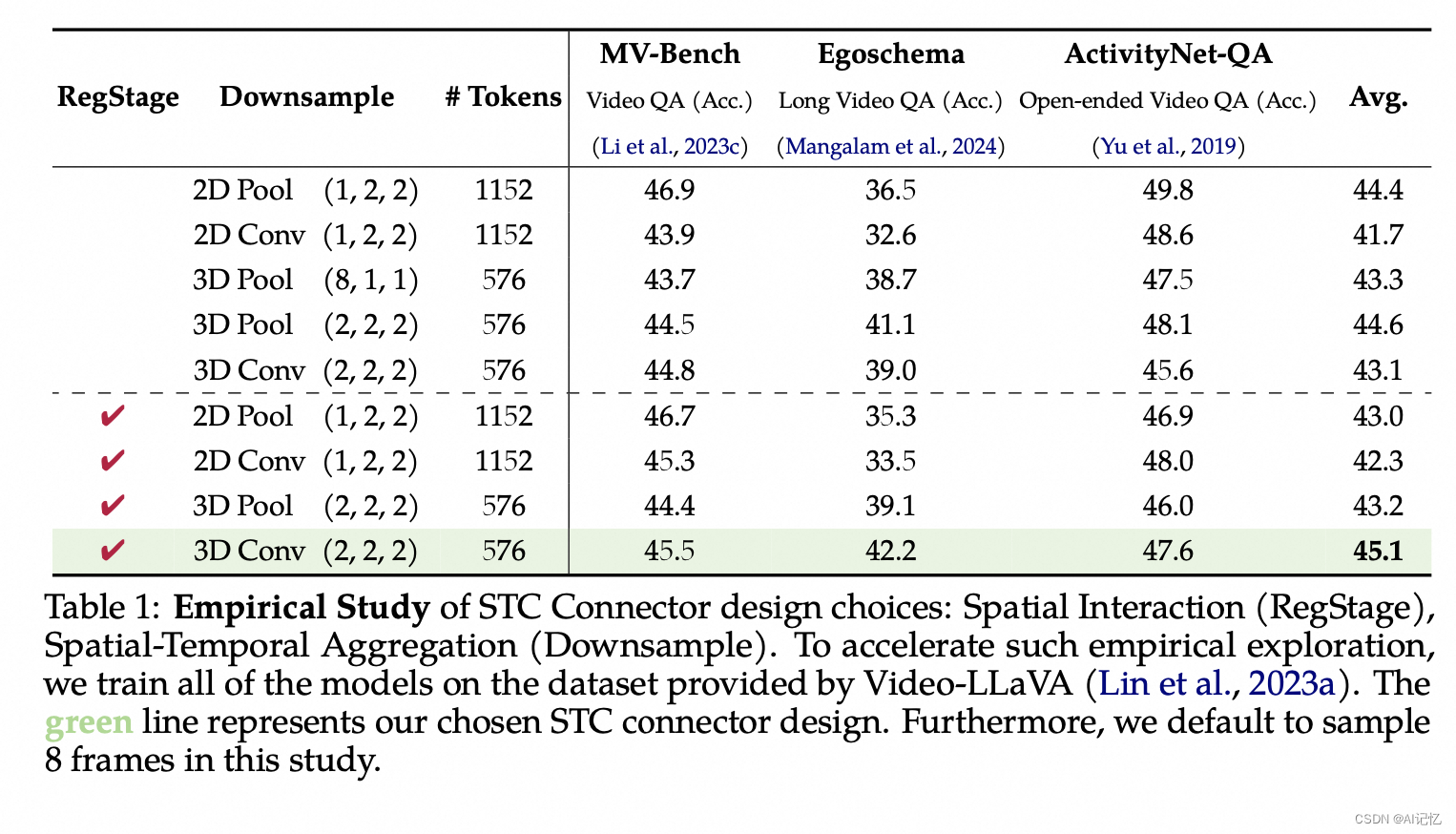
2014 年以前,发布机器学习模型的主力军在学术界。但此后,产业界开始占据主导。2023 年,有51个知名机器学习模型是由产业界制作的,相比之下,学术界只发布了 15 个 (图 1.3.1)。值得注意的是,同年产学合作还做出21个模型,创下新高。创建尖端人工智能模型需要大量数据、算力及资金支持,而这些往往是学术界不具备的。我们去年的报告首度突出展示这种转变趋势,尽管今年产学间的差距有所减小,但这种趋势依旧。

按国家归属
为了揭示人工智能地缘政治格局的变化趋势,AI Index 研究团队分析了知名模型的来源国。图 1.3.2 展示的是各国(模型研究者所属机构所在地)开发的知名机器学习模型数量情况。2023 年美国以产出 61 个知名机器学习模型领先,中国有 15 个,法国为 8 个。在产出知名模型的数量上,欧盟+英国自 2019 年以来首次超过了中国(图 1.3.3)。美国产出的模型数量领先于英国、中国及加拿大等其他主要地区(图 1.3.4),这种情况从2003 年就开始了。



参数趋势
机器学习模型的参数是指在训练过程中学到的数值,可用来确定模型对输入数据的解读及预测方式。一般来说,用更多数据训练的模型的参数也更多。同理,参数更多的模型往往表现更佳。
图 1.3.5 展示的是Epoch数据集的机器学习模型的参数统计,按模型源自什么行业分类。自2010年代以来,参数的数量有了显著增长,这反映出 人工智能模型要处理的任务越来越复杂,数据可用性的提高,硬件的改善,以及大模型的效能得到了验证。在行业板块,高参数模型尤其突出,展现了像 OpenAI、Anthropic 以及谷歌等公司对训练海量数据所需的计算成本的承受能力。

算力趋势
在人工智能领域,“算力” (compute) 是指训练及运行机器学习模型需要的算力资源。模型复杂度与数据量是影响算力需求的两大因素:复杂度越高数据量越大,需要的算力也就越大。如图 1.3.6 所示,过去 20 年许多知名机器学习模型训练过程所需算力有了显著增长。近年来,这种需求甚至呈指数级的增加,最近五年尤其如此。模型需要更多算力不仅对环境产生了较大影响,在算力资源的获取上,企业往往比学术界更有优势。

图 1.3.7 聚焦的是训练知名机器学习所需的算力(自 2012 年以来)。比方说,用GPU 提升人工智能模型效率的做法是AlexNet 这项研究率先采用的,其训练估计消耗了 470 petaFLOPs。2017年首个 Transformer 模型推出时,所需算力约为 7400 petaFLOPs 。最近发布的顶尖模型,谷歌的 Gemini Ultra所需算力已经达到约 500 亿 petaFLOPs。

特别聚焦:模型会用光数据吗?
如前所述,最近算法取得的进步,包括强大的大语言模型(LLM)取得的进步,很大一部分是通过用更多数据训练模型取得的。Anthropic 联合创始人兼 AI Index 指导委员会成员杰克·克拉克(Jack Clark) 最近指出,基础模型的训练基本上把互联网上能找到的绝大部分数据都用上了。
人工智能模型对数据的依赖性日益增强,这不仅让人担心将来计算机科学家可能没有足够的数据来扩展和提升系统。Epoch 的研究显示,这种担忧不无道理。Epoch已经给出了数据耗尽可能的时间表预测,包括基于历史数据的预测以及基于算力的预测。
比方说,研究者预测,到 2024 年,高质量的语言数据可能就会被用尽,二十年后,低质量的语言数据也将耗尽,而图像数据可能到 2030 年代末至 2040 年代中就会被完全用光(图 1.3.8)。用 人工智能生成的合成数据理论上可以解决数据不足的问题。比方说,可以用一个大语言模型生成的文本来训练另一个模型。用合成数据训练人工智能系统尤其有吸引力,不仅是可以作为数据可能耗尽的解决方案,也是因为在自然产生的数据很稀少的情况下(比方说罕见病或代表性不足群体),生成式人工智能系统原则上可以生成这种数据尽管如此,直到最近,大家对使用合成数据训练生成式人工智能的有效性和可行性还知之甚少。但是,最新研究指出,这种方法在实践上有其局限性。
比方说,来自英国和加拿大的研究团队发现,主要靠合成数据训练出来的模型会出现所谓的“模型坍塌” (model collapse) 现象,也就是这些模型会逐渐忘记真实原始数据的分布情况,开始生成范围狭窄的输出。图 1.3.9 展示的是变分自编码器 (VAE,一种常用的生成式人工智能架构)模型坍塌的过程。每一代的模型在接触到更多的合成数据指后,能生成的输出类型会越来越局限。如图 1.3.10 所示,从统计角度看,随着合成数据代数的增加,输出分布曲线的尾部逐渐消失,而数据集中度开始趋近中位数。这说明依赖合成数据的模型,其输出多样性和分布广度随时间减少。

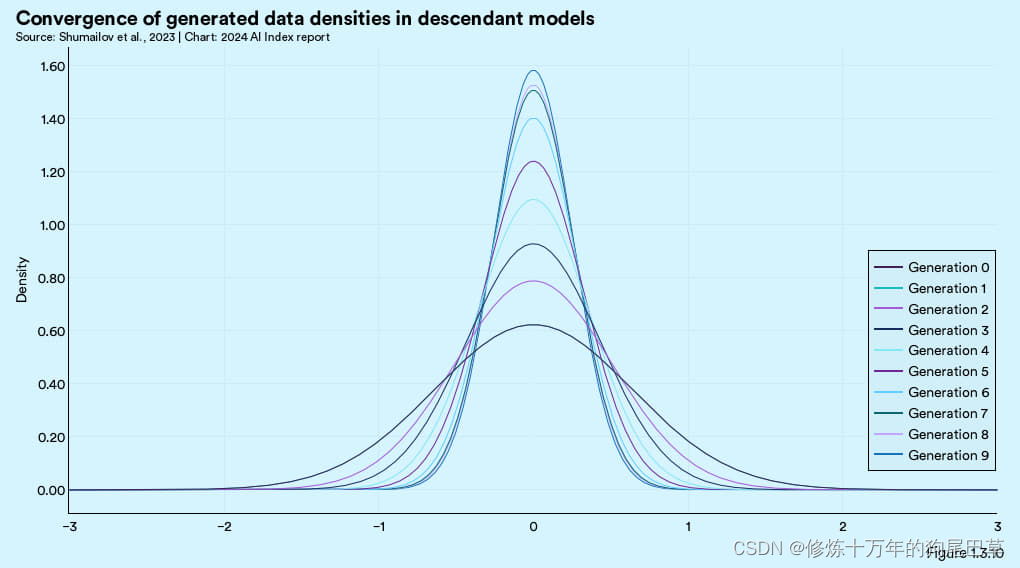
2023 年对使用合成数据的生成式图像模型还进行过一项类似研究,研究发现,如果仅靠循环调用合成数据,获缺乏真正的人类数据支持,则模型的输出质量会明显下降。研究者称之为“模型自噬症” (Model Autophagy Disorder, MAD,与疯牛病有异曲同工之妙)。
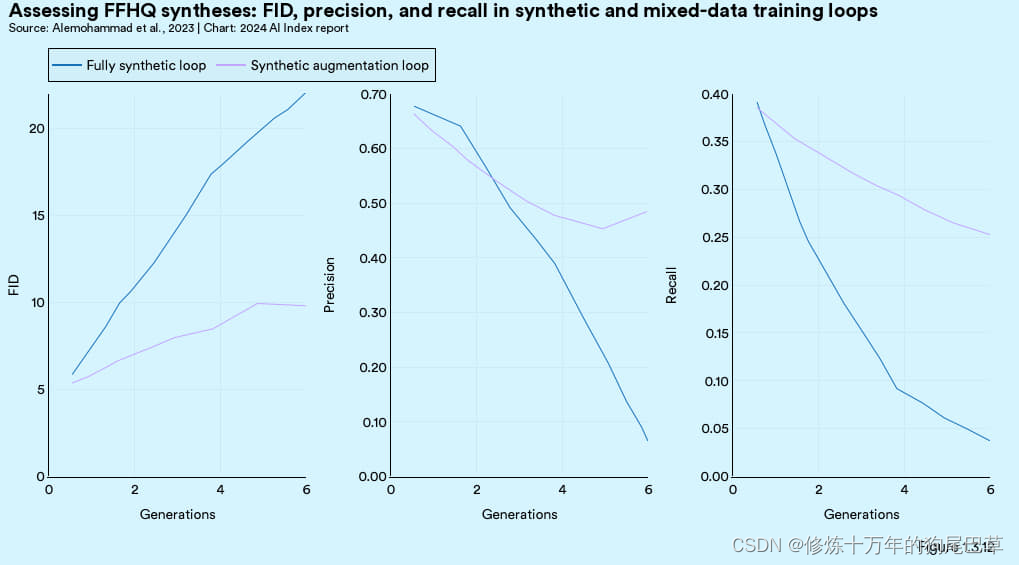
本研究探讨了两种类型的训练方法:一种是完全合成 (fully synthetic) 法,也就是模型只用合成数据进行训练;另一种是合成增强 (synthetic augmentation) 法,也就是结合合成数据与真实数据对模型进行训练。这两种方法都会出现随着训练次数的增加,生成图像的质量逐渐下降的情况。图 1.3.11 展示的是用合成增强法图像生成出现逐步退化的情况,比方说在训练的第 7 和第 9 步里,生成的人脸图像出现了越来越多的不规则散点。从统计角度看,这些使用合成数据和合成增强方法生成的图像,其 FID 分数较高,意味着与真实图像的差异增大;精确度和召回率分数较低,表明图像的真实感和多样性都有所下降 (见图 1.3.12)。尽管添加了部分真实数据的合成增强法相较于完全合成法在图像退化上有所改善,但两者在进一步训练后都出现了效果递减的趋势。

基础模型
基础模型是人工智能模型当中发展很快且很受欢迎的一个类别。这些用大数据集训练的模型可适用于多种下游应用。比方说 GPT-4, Claude 3, 以及 Llama 2 等基础模型展现出的能力令人印象深刻,并正在逐步投入到实际应用当中。2023年斯坦福大学推出一个新的社区资源, Ecosystem Graphs,其目的是监测基础模型生态体系的动态,其中包括数据集、模型及其应用。本节内容利用率 Ecosystem Graphs 的数据来分析基础模型的发展趋势。
发布的模型情况
基础模型的访问有多种途径。比方说,有像谷歌的 PaLM-E 这样一般人访问不了,只有其开发者能访问的模型。也有像 OpenAI 的 GPT-4 这样提供有限访问的模型,可通过公共 API 提供部分访问权限。而像 Meta 的 Llama 2这类开放模型,不仅公开模型权重,还允许用户自由修改和使用这些模型。
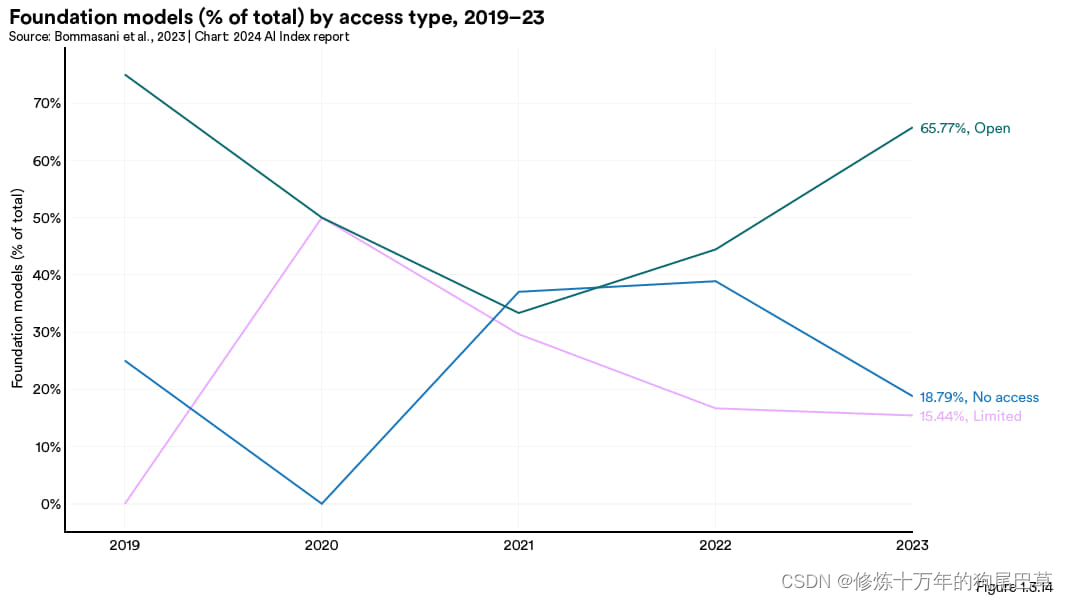
图 1.3.13 展示的是从 2019 年至今,不同访问类型的基础模型总量变化情况。近几年基础模型的数量急剧增加,自 2022 年来翻了一番,相对于 2019 年增加了近 38 倍。2023 年共发布了 149 个基础模型,其中开放模型 98 个,有限访问模型 23 个,不开放访问模型 28 个。

2023 年绝大部分的基础模型(65.8%)都采用了开放访问的策略,有18.8% 的模型不开放访问,15.4% 提供了有限访问(见图 1.3.14)。从 2021 年开始,开放访问的模型比例有了显著提升。
组织隶属情况
图 1.3.15 展示的是基础模型来源所属板块的情况(自 2019 年起)。 2023 年的情况是 72.5% 的基础模型都是由产业界开发的。相比之下,只有 18.8% 的基础模型出自学术界。近年来,来自产业界的基础模型数量呈上升趋势。

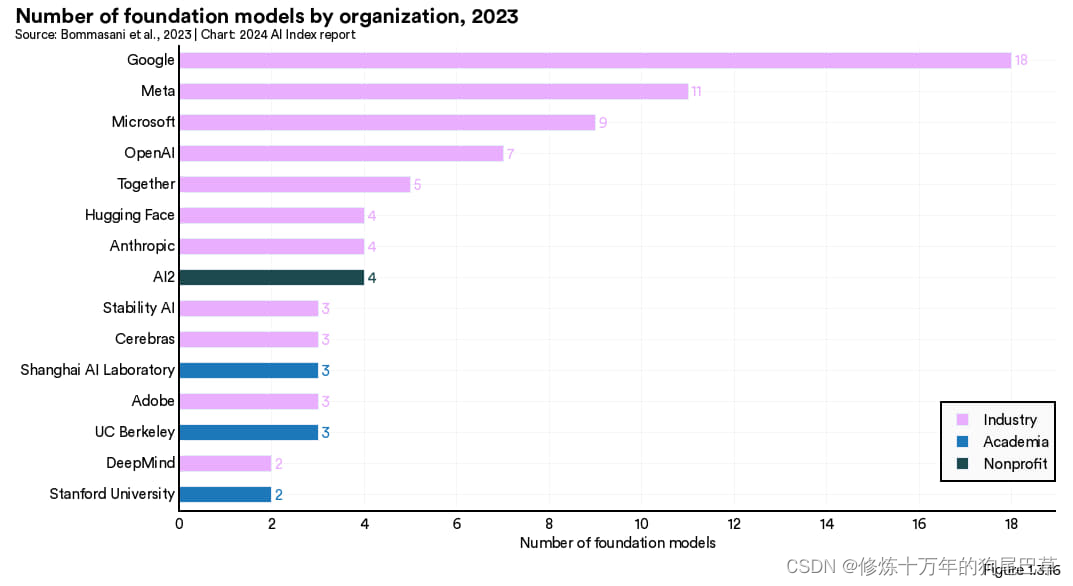
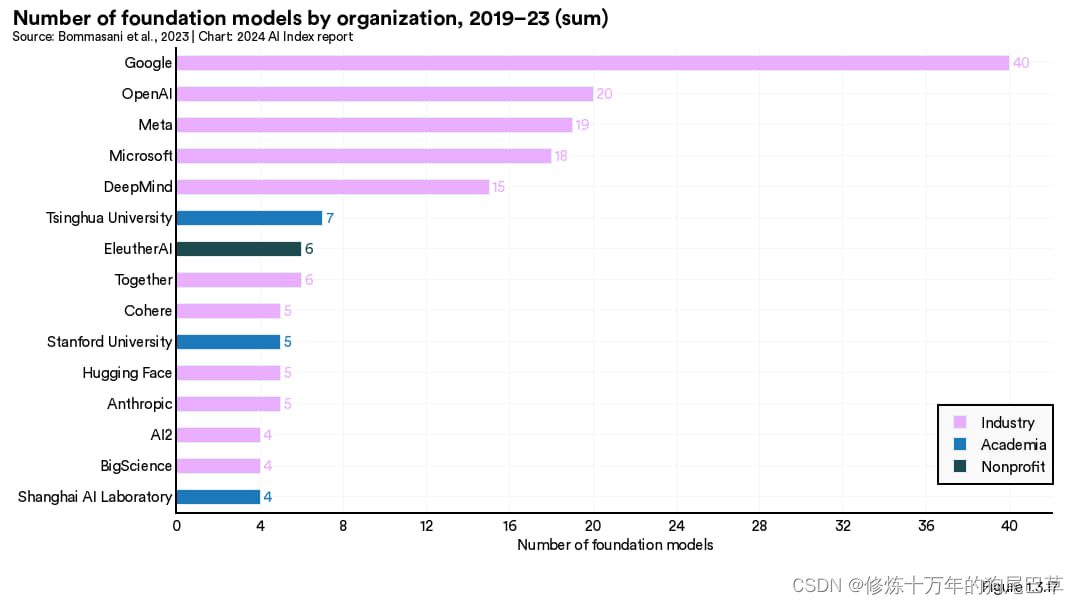
图 1.3.16 聚焦了 2023 年推出的各类基础模型的来源。谷歌以 18 个模型独占鳌头,发布11个模型的Meta 紧随其后,微软发布了 9 个模型。加州大学伯克利分校是 2023 年发布模型最多的学术机构,共发布了 3 个模型。
自 2019 年以来,谷歌宫发布了40个基础模型,发布数量位居第一。OpenAI 以 20 个模型位列第二。清华大学发布了 7 个基础模型领先,在非西方机构当中领先,斯坦福大学则发布了 5 个模型,位居美国学术机构首位。
国家分布情况
鉴于基础模型在人工智能前沿研究的重要地位,从地缘政治视角了解这些模型的国家归属就显得尤为关键。图 1.3.18、 1.3.19以及 1.3.20 展示的是不同基础模型的国家归属情况。与本章前面对知名模型的分析类似,一个模型如果有研究者与某个国家的总部机构有关联,则认为该模型属于该国。
2023 年大多数的基础模型都起源于美国,数量达到了 109,其次是中国的 20 个,以及英国(图 1.3.18)。这方面美国自2019 年起就一直领先,是大多数基础模型的发源地(图 1.3.19)。

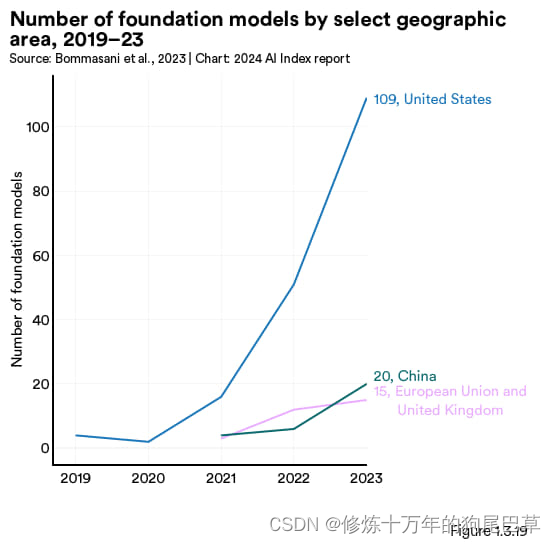
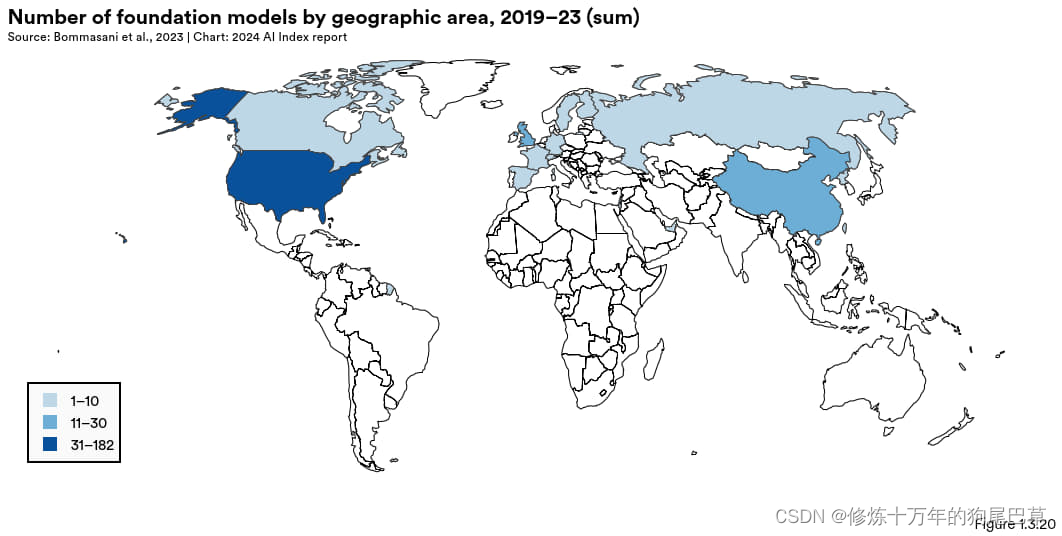
图 1.3.20 展示了自 2019 年以来各国发布的基础模型累计数量。在此期间,美国以发布 182 个模型领先,中国和英国的发布量分别是 30 和 21 。
训练成本
在关于基础模型的讨论中当中,成本推测是突出话题之一。虽然人工智能公司很少透露其模型训练的成本,但普遍认为达到了数百万美元,并且还在上升。比方说,OpenAI CEO 山姆·阿尔特曼(Sam Altman)曾提到 GPT-4 的训练成本超过了 1 亿美元。这种训练费成本的上涨实际上已经将传统的人工智能研究中心——大学拒之门外,导致后者很难开发自己的前沿基础模型。为此,已有一些政策举措试图打破这种产学失衡的情况,通过设立国家级的人工智能研究资源,将数据和算力授予给非产业界的行为人更,让其得以从事高级的人工智能研究。
了解人工智能模型训练成本很重要,但关于这些成本的详细信息仍然稀少。AI Index 是最早提供基础模型训练成本估算者之一。今年AI Index 与 人工智能研究机构Epoch AI进行了合作,使得我们的人工智能训练成本估算的健壮性得到了显著增强和巩固。为了估算前沿模型的成本,Epoch 团队分析了训练的持续时间,以及训练硬件的类型、数量和利用率,还利用了来自模型相关的出版物、新闻发布或技术报告的信息。
图 1.3.21 展示了按照所租用的云服务价格估算出来的人工智能模型训练成本。AI Index 的测算证实了近年来模型训练成本显著增加的猜测。比方说,2017 年初代 Transformer 模型(是几乎现代所有大语言模型架构的鼻祖)的训练成本约为 900 美元。2019年发布的(在SQuAD 、GLUE等众多权威理解基准测试中取得了最好成绩的)RoBERTa Large的训练成本约为 16 万美元。而到了 2023 年,OpenAI 的 GPT-4 与谷歌的 Gemini Ultra 的训练成本估计分别约为 7800 万美元和 1.91 亿美元。
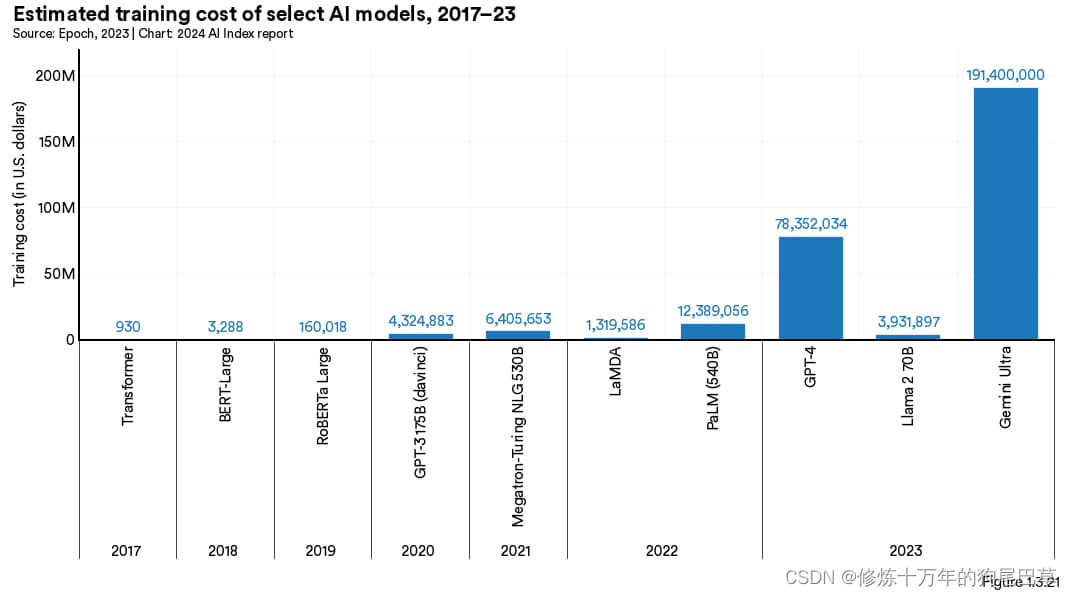
图 1.3.22 展示的是 AI Index 测算的各人工智能模型的训练成本。如图可见,随着时间的推延,模型训练成本急剧上升。
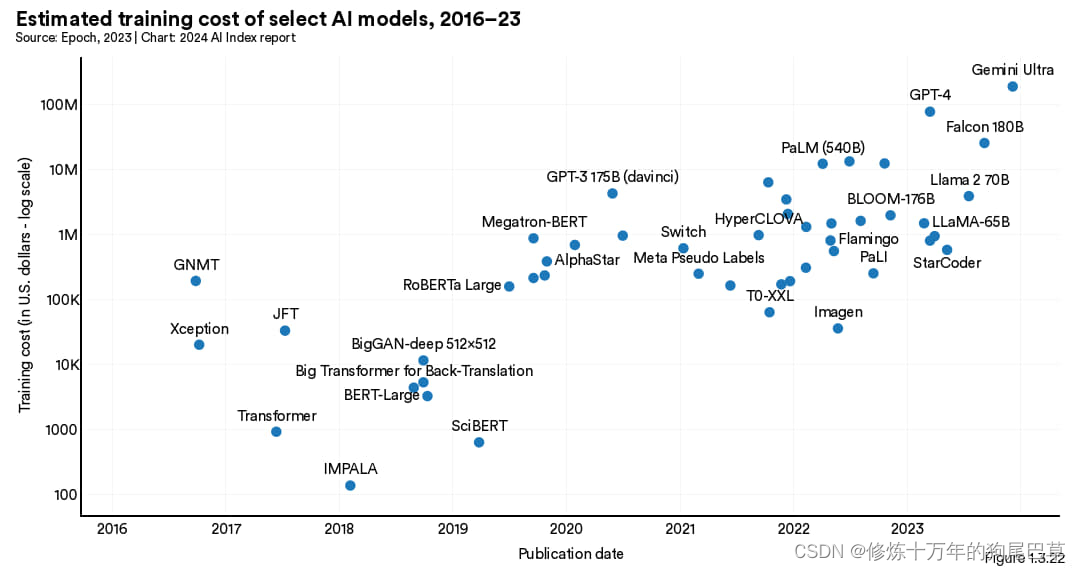
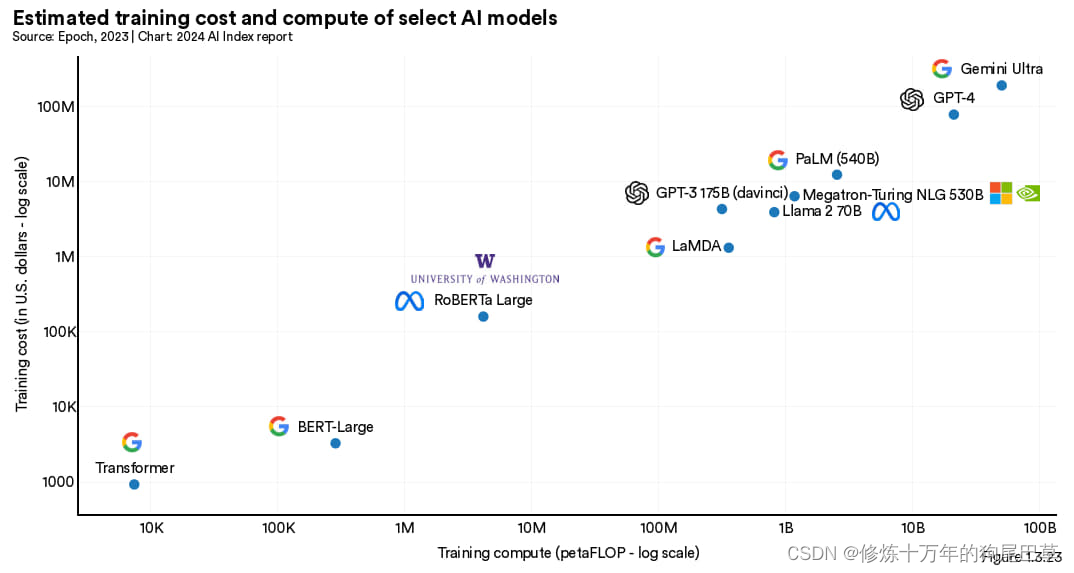
如之前的人工智能指数报告所证实那样,人工智能模型的训练成本与其算力需求之间存在着直接的关联关系。如图1.3.23所示,需更多计算资源的模型,训练成本也相对更高。
1.4 人工智能会议
人工智能会议是研究者展示研究成果,与同行及协作者间建立联系的关键平台。在过去二十年的时间里,这些会议在规模、数量以及名声等方面均有了长足发展。本节探究的是重大人工智能会议参会情况的趋势。
参会情况
图 1.4.1 展示的是自 2010 年以来多场选定的人工智能会议的参会情况。先是因为全面回归面对面会议模式导致出席人数下降,但从 2022 到 2023 年间,参会人数开始反弹。
具体而言,最近一年的参会人数增长了 6.7%。从 2015 年开始,每年的参会人数平均增加了 50000 名,这既表明公众对人工智能研究的日益关注,也反映出新兴人工智能会议的增多。

神经信息处理系统会议(NeurIPS)依旧是人气极高的人工智能会议之一,2023 年吸引了约 16380 名参会者(见图 1.4.2 与 图 1.4.3)。在众多重要的人工智能会议当中,NeurIPS、ICML、ICCV 和 AAAI 的参会人数仍持续增长。但在过去一年当中,CVPR、ICRA、ICLR 以及 IROS 的参会人数则略有下降。


1.5 开源人工智能软件
GitHub 是一个可让个人及团队对代码库进行托管、审查以及协作的web平台。作为被软件开发者广泛使用的工具,GitHub 可促进代码管理、项目协作及开源软件支持。本节内容基于 GitHub 的数据,发现了一些学术出版物未涉及的开源人工智能软件开发趋势。
项目
GitHub 的项目通常含有源代码、文档、配置文件以及图像等多种文件,这些文件共同构成一个完整的软件项目。图 1.5.1 展示的是从 2011 年到 2023 年间 GitHub 人工智能项目数量的增长趋势。2011 年只有 845 个人工智能项目,而到了 2023 年这个数字已经达到了近 180 万。仅去年人工智能项目数量就增长了 59.3%。
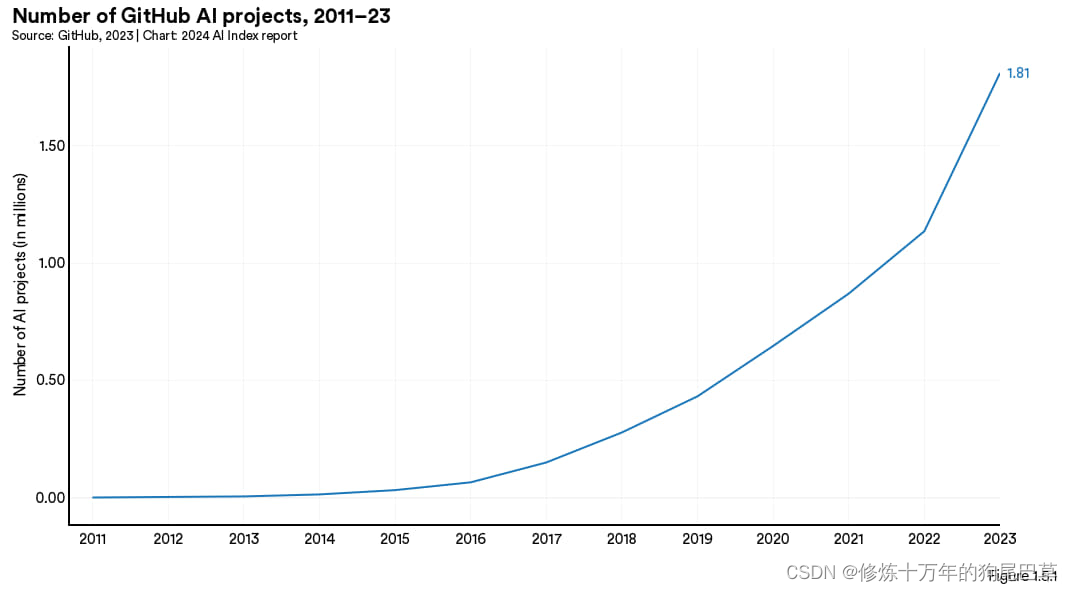
图 1.5.2 展示的是 2011 年以来 GitHub 上各国人工智能项目的分布情况。2023 年出自美国的人工智能项目占比为 22.9%,位居首位,印度以 19% 的占比紧随其后,欧盟+英国占比为 17.9%。从 2016 年开始,美国人工智能项目的占比就在持续减少。

星标情况
在 GitHub 上,用户可以通过“星标”(star)功能来表达对某个开源项目的喜爱和支持,就像在社交网络上给帖子点赞一样。在人工智能编程社区当中,像 TensorFlow、 OpenCV、 Keras及 PyTorch 等知名开源库尤其受欢迎,经常能获得大量星标。比方说,专门用来开发和部署机器学习模型的TensorFlow使用广泛, OpenCV 则提供了多种计算机视觉工具,其中包括对象识别和特征分析等功能。
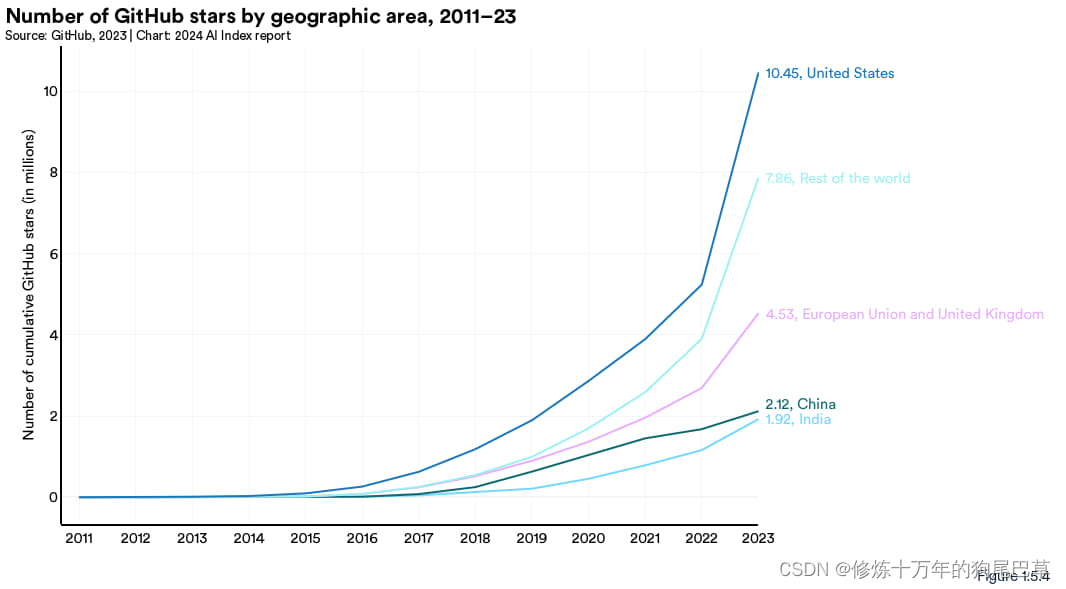
过去一年,GitHub 上人工智能项目的星标总数有了大幅增长,从 2022 年的400万增至 2023 年的1220万(参见图 1.5.3)。这种显著增长不仅体现出项目数量的增加,也标志着开源人工智能软件开发的发展之快。

2023 年美国获得星标数量最多,为约1050万(图 1.5.4)。欧盟+英国、中国、印度等各大地区的星标数同比也增加了。
本文翻译来自于神译局。