目录
- GT-BERT
- 结束语
- 代码实现
- 整个项目源码(数据集模型)
GT-BERT
在为了使 BERT 模型能够得到广泛的应用,在保证模型分类准确率不降低的情况下,减少模型参数规模并降低时间复杂度,提出一种基于半监督生成对抗网络与 BERT 的文本分类模型 GT-BERT。模型的整体框架如图3所示。
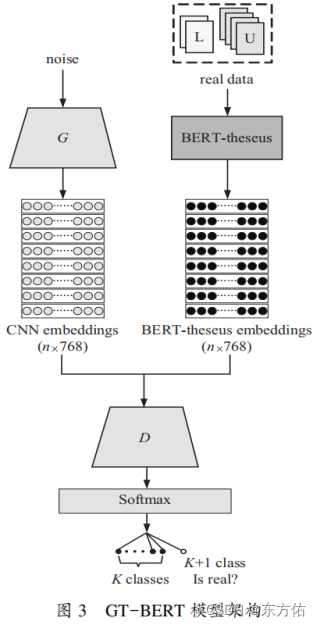
首先,对BERT进行压缩,通过实验验证选择使用BERT-of-theseus方法进行压缩得到BERT-theseus模型。损失函数设定为文本分类常用的交叉熵损失:
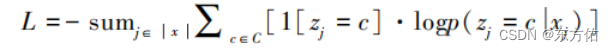
其中,为训练集的第j个样本,是的标签,C和c表示标签集合和一个类标签。接着,在压缩之后,从SS-GANs角度扩展BERT-theseus模型进行微调。在预训练过的BERT-theseus模型中添加两个组件:(1)添加特定任务层;(2)添加SS-GANs层来实现半监督学习。本研究假定K类句子分类任务,给定输入句子s=(, ,…,),其中开头的为分类特殊标记“[CLS]”,结尾的为句子分隔特殊标记“[SEP]”,其余部分对输入句子进行切分后标记序列输入BERT模型后得到编码向量序列为=(,…,)。
将生成器G生成的假样本向量与真实无标注数据输入BERT-theseus中所提取的特征向量,分别输入至判别器D中,利用对抗训练来不断强化判别器D。与此同时,利用少量标注数据对判别器D进行分类训练,从而进一步提高模型整体质量。
其中,生成器G输出服从正态分布的“噪声”,采用CNN网络,将输出空间映射到样本空间,记作∈。 判别器D也为CNN网络,它在输入中接收向量∈,其中可以为真实标注或者未标注样本 ,也可以为生成器生成的假样本数据。在前向传播阶段,当样本为真实样本时,即=,判别器D会将样本分类在K类之中。当样本为假样本时,即=,判别器D会把样本相对应的分类于K+1类别中。在此阶段生成器G和判别器D的损失分别被记作和,训练过程中G和D通过相互博弈而优化损失。
在反向传播中,未标注样本只增加。标注的真实样本只会影响,在最后和都会受到G的影响,即当D找不出生成样本时,将会受到惩罚,反亦然。在更新D时,改变BERT-theseus的权重来进行微调。训练完成后,生成器G会被舍弃,同时保留完整的BERT-theseus模型与判别器D进行分类任务的预测。
结束语
该文提出了一种用于文本分类任务的GT-BERT模型。首先,使用 theseus方法对BERT进行压缩,在不降低分类性能的前提下,有效降低了BERT 的参数规模和时间复杂度。然后,引人SS-GAN框架改进模型的训练方式,使 BERT-theseus模型能有效利用无标注数据,并实验了多组生成器与判别器的组合方式,获取了最优的生成器判别器组合配置,进一步提升了模型的分类性能。
代码实现
import torch
from transformers import BertTokenizer, BertModel
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import torch.nn as nn
import torch.optim as optim
import os
from glob import glob
torch.autograd.set_detect_anomaly(True)
# 定义数据集类
class TextDataset(Dataset):
def __init__(self, texts, labels, tokenizer, max_len):
self.texts = texts
self.labels = labels
self.tokenizer = tokenizer
self.max_len = max_len
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
label = self.labels[idx]
encoding = self.tokenizer.encode_plus(
text,
add_special_tokens=True,
max_length=self.max_len,
return_token_type_ids=False,
padding='max_length',
truncation=True,
return_attention_mask=True,
return_tensors='pt',
)
return {
'text': text,
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'label': torch.tensor(label, dtype=torch.long)
}
# 加载数据集函数
def load_data(dataset_name):
if dataset_name == '20ng':
dirs = glob("E:/python_project/GT_BERT/dateset/20_newsgroups/20_newsgroups/*")
texts = []
labels = []
for i, d in enumerate(dirs):
for j in glob(d + "/*")[:10]:
try:
with open(j, "r", encoding="utf-8") as f:
one = f.read()
except:
continue
texts.append(one)
labels.append(i)
elif dataset_name == 'sst5':
data_dir = 'path/to/sst/data'
def load_sst_data(data_dir, split):
sentences = []
labels = []
with open(os.path.join(data_dir, f'{split}.txt')) as f:
for line in f:
label, sentence = line.strip().split(' ', 1)
sentences.append(sentence)
labels.append(int(label))
return sentences, labels
texts, labels = load_sst_data(data_dir, 'train')
elif dataset_name == 'mr':
file_path = 'path/to/mr/data'
def load_mr_data(file_path):
sentences = []
labels = []
with open(file_path) as f:
for line in f:
label, sentence = line.strip().split(' ', 1)
sentences.append(sentence)
labels.append(int(label))
return sentences, labels
texts, labels = load_mr_data(file_path)
elif dataset_name == 'trec':
file_path = 'path/to/trec/data'
def load_trec_data(file_path):
sentences = []
labels = []
with open(file_path) as f:
for line in f:
label, sentence = line.strip().split(' ', 1)
sentences.append(sentence)
labels.append(label)
return sentences, labels
texts, labels = load_trec_data(file_path)
else:
raise ValueError("Unsupported dataset")
return texts, labels
# 默认加载 20 News Group 数据集
dataset_name = '20ng'
texts, labels = load_data(dataset_name)
label_encoder = LabelEncoder()
labels = label_encoder.fit_transform(labels)
# 使用BERT的tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
max_len = 128
# 将数据集划分为训练集和验证集
train_texts, val_texts, train_labels, val_labels = train_test_split(texts, labels, test_size=0.2)
train_dataset = TextDataset(train_texts, train_labels, tokenizer, max_len)
val_dataset = TextDataset(val_texts, val_labels, tokenizer, max_len)
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=16, shuffle=False)
# 定义BERT编码器
class BERTTextEncoder(nn.Module):
def __init__(self):
super(BERTTextEncoder, self).__init__()
self.bert = BertModel.from_pretrained('bert-base-uncased')
def forward(self, input_ids, attention_mask):
outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)
pooled_output = outputs[1]
return pooled_output
# 定义生成器
class Generator(nn.Module):
def __init__(self, noise_dim, output_dim):
super(Generator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(noise_dim, 128),
nn.ReLU(),
nn.Linear(128, output_dim),
nn.Tanh()
)
def forward(self, noise):
return self.fc(noise)
# 定义判别器
class Discriminator(nn.Module):
def __init__(self, input_dim):
super(Discriminator, self).__init__()
self.fc = nn.Sequential(
nn.Linear(input_dim, 128),
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid()
)
def forward(self, features):
return self.fc(features)
# 定义完整的GT-BERT模型
class GTBERTModel(nn.Module):
def __init__(self, bert_encoder, noise_dim, output_dim, num_classes):
super(GTBERTModel, self).__init__()
self.bert_encoder = bert_encoder
self.generator = Generator(noise_dim, output_dim)
self.discriminator = Discriminator(output_dim)
self.classifier = nn.Linear(output_dim, num_classes)
def forward(self, input_ids, attention_mask, noise):
real_features = self.bert_encoder(input_ids, attention_mask)
fake_features = self.generator(noise)
disc_real = self.discriminator(real_features)
disc_fake = self.discriminator(fake_features)
class_output = self.classifier(real_features)
return class_output, disc_real, disc_fake
# 初始化模型和超参数
noise_dim = 100
output_dim = 768
num_classes = len(set(labels))
bert_encoder = BERTTextEncoder()
model = GTBERTModel(bert_encoder, noise_dim, output_dim, num_classes)
# 定义损失函数和优化器
criterion_class = nn.CrossEntropyLoss()
criterion_disc = nn.BCELoss()
optimizer_G = optim.Adam(model.generator.parameters(), lr=0.0002)
optimizer_D = optim.Adam(model.discriminator.parameters(), lr=0.0002)
optimizer_BERT = optim.Adam(model.bert_encoder.parameters(), lr=2e-5)
optimizer_classifier = optim.Adam(model.classifier.parameters(), lr=2e-5)
num_epochs = 10
# 训练循环
e_id = 1
for epoch in range(num_epochs):
model.train()
for batch in train_dataloader:
e_id += 1
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['label']
# 生成噪声
noise = torch.randn(input_ids.size(0), noise_dim)
# 获取模型输出
class_output, disc_real, disc_fake = model(input_ids, attention_mask, noise)
# 计算损失
real_labels = torch.ones(input_ids.size(0), 1)
fake_labels = torch.zeros(input_ids.size(0), 1)
loss_real = criterion_disc(disc_real, real_labels)
loss_fake = criterion_disc(disc_fake, fake_labels)
loss_class = criterion_class(class_output, labels)
if e_id % 5 == 0:
# 优化判别器
optimizer_D.zero_grad()
loss_D = (loss_real + loss_fake) / 2
loss_D.backward(retain_graph=True)
optimizer_D.step()
elif e_id % 2 == 0:
# 优化生成器
loss_G = criterion_disc(disc_fake, real_labels)
optimizer_G.zero_grad()
loss_G.backward(retain_graph=True)
optimizer_G.step()
else:
# 优化BERT和分类器
optimizer_BERT.zero_grad()
optimizer_classifier.zero_grad()
loss_class.backward()
optimizer_BERT.step()
optimizer_classifier.step()
print(
f'Epoch [{epoch + 1}/{num_epochs}], Loss D: {loss_D.item()}, Loss G: {loss_G.item()}, Loss Class: {loss_class.item()}')
# 验证模型
model.eval()
val_loss = 0
correct = 0
with torch.no_grad():
for batch in val_dataloader:
input_ids = batch['input_ids']
attention_mask = batch['attention_mask']
labels = batch['label']
noise = torch.randn(input_ids.size(0), noise_dim)
class_output, disc_real, disc_fake = model(input_ids, attention_mask, noise)
loss = criterion_class(class_output, labels)
val_loss += loss.item()
pred = class_output.argmax(dim=1, keepdim=True)
correct += pred.eq(labels.view_as(pred)).sum().item()
val_loss /= len(val_dataloader.dataset)
accuracy = correct / len(val_dataloader.dataset)
print(f'Validation Loss: {val_loss}, Accuracy: {accuracy}')
整个项目源码(数据集模型)
项目







![[Linux] 系统的基本架构特点](https://img-blog.csdnimg.cn/direct/421e306c0f70413e85e2a0ca5fa269ed.png)