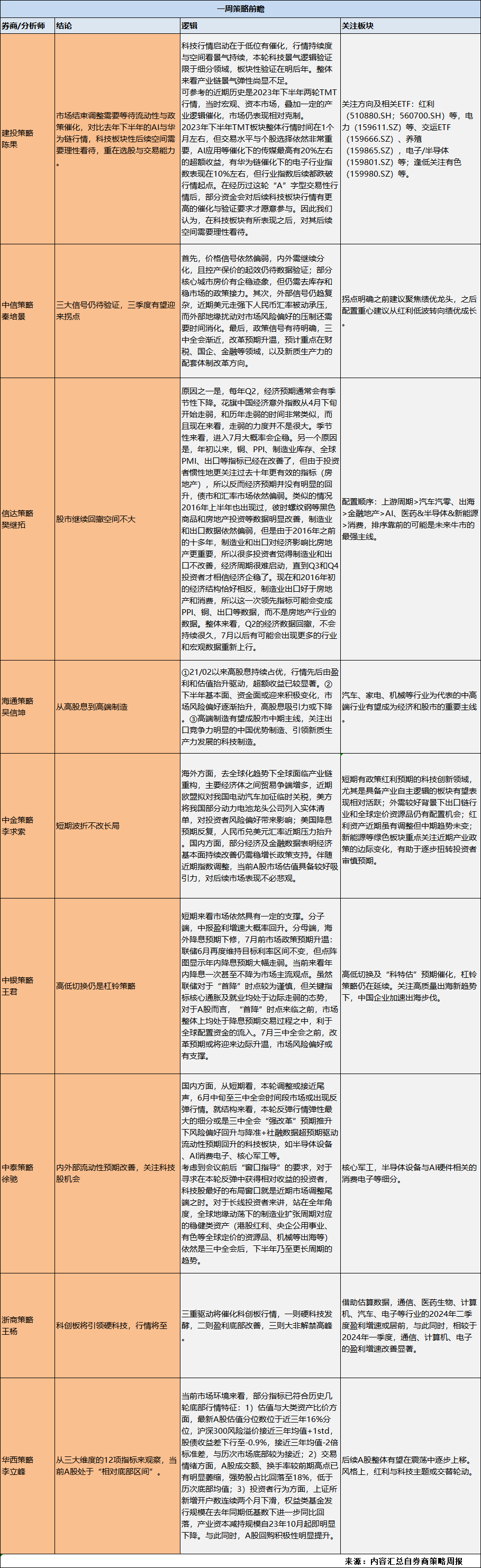
OCR相关的内容我在之前的工作中虽有所涉及,但是还是比较少的,最近正好需要用到OCR的一些技术,查了一些资料,发现国内的话百度这块做的还是比较全面系统深入的,抱着闲来无事学习了解的心态,这里花了点时间基于百度飞桨平台发布的PaddleOCR来开发构建了银行卡卡面文本检测识别系统。
首先看下实例效果:

简单了解了OCR是什么,OCR具体要做什么,以及OCR技术发展到现在都诞生了哪些技术:
OCR(Optical Character Recognition,光学字符识别)任务是计算机视觉领域的重要方向之一,旨在通过图像处理和识别技术,将图像中的文字内容转化为可编辑、可搜索的文本格式。OCR任务主要包括以下几个步骤:
- 图像预处理:对输入的图像进行去噪、灰度化、二值化等操作,以提升字符识别的准确性。对于不规则文本识别,可能还需要进行校正操作。
- 文字检测:在预处理后的图像中定位出文字区域,确定文字在图像中的位置和范围。
- 文字识别:识别出文字检测步骤中确定的文字区域中的具体文字内容。文本识别一般可以根据待识别文本形状分为规则文本识别和不规则文本识别两大类。
OCR技术广泛应用于多个领域,如车牌识别、银行卡信息识别、身份证信息识别、火车票信息识别等。此外,通用OCR技术也常用于多模态任务,如视频字幕自动翻译、内容安全监控等。
OCR技术发展历程
OCR技术的发展历程可以分为以下几个阶段:
- 早期阶段:OCR的概念最早由德国科学家Tausheck在1929年提出,但直到20世纪70年代,OCR技术才开始进入实际应用阶段。此时,OCR技术主要基于模板匹配法,识别率较低。
- 发展阶段:随着计算机技术和光学扫描技术的不断发展,OCR技术逐渐进入发展阶段。IBM公司的Casey和Nagy在1966年发表了第一篇关于汉字识别的文章,标志着OCR技术从理论到实际应用的初步实现。此后,各领域专家和学者对OCR技术进行了深入研究,推动了OCR技术的不断发展。
- 数字化时代:进入21世纪后,随着深度学习技术的兴起,OCR技术进入了数字化时代。深度学习技术为OCR技术带来了革命性的进步,使得OCR技术在文本检测、识别等方面取得了显著的提升。目前,OCR技术已经可以实现高准确率、高速率的文字识别,并支持多种语言、多种字体的识别。
PaddleOCR官方项目地址在这里,如下所示:

目前已经有将近4w的star量了,着实很强了。
PaddleOCR 旨在打造一套丰富、领先、且实用的 OCR 工具库,助力开发者训练出更好的模型,并应用落地。截止目前PaddleOCR已经迭代发展到了v4版本:
官方也提供了免费的在线使用地址,在这里,如下所示:

随便选择一张图片,效果如下:


PaddleOCR系列模型清单如下:
| 模型简介 | 模型名称 | 推荐场景 | 检测模型 | 方向分类器 | 识别模型 |
|---|---|---|---|---|---|
| 中英文超轻量 PP-OCRv4 模型(15.8M) | ch_PP-OCRv4_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 中英文超轻量 PP-OCRv3 模型(16.2M) | ch_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
| 英文超轻量 PP-OCRv3 模型(13.4M) | en_PP-OCRv3_xx | 移动端&服务器端 | 推理模型 / 训练模型 | 推理模型 / 训练模型 | 推理模型 / 训练模型 |
【中文检测模型】
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ch_PP-OCRv4_det | 【最新】原始超轻量模型,支持中英文、多语种文本检测 | ch_PP-OCRv4_det_cml.yml | 4.70M | 推理模型 / 训练模型 |
| ch_PP-OCRv4_server_det | 【最新】原始高精度模型,支持中英文、多语种文本检测 | ch_PP-OCRv4_det_teacher.yml | 110M | 推理模型 / 训练模型 |
| ch_PP-OCRv3_det_slim | slim量化+蒸馏版超轻量模型,支持中英文、多语种文本检测 | ch_PP-OCRv3_det_cml.yml | 1.1M | 推理模型 / 训练模型 / nb模型 |
| ch_PP-OCRv3_det | 原始超轻量模型,支持中英文、多语种文本检测 | ch_PP-OCRv3_det_cml.yml | 3.80M | 推理模型 / 训练模型 |
| ch_PP-OCRv2_det_slim | slim量化+蒸馏版超轻量模型,支持中英文、多语种文本检测 | ch_PP-OCRv2_det_cml.yml | 3.0M | 推理模型 |
| ch_PP-OCRv2_det | 原始超轻量模型,支持中英文、多语种文本检测 | ch_PP-OCRv2_det_cml.yml | 3.0M | 推理模型 / 训练模型 |
| ch_ppocr_mobile_slim_v2.0_det | slim裁剪版超轻量模型,支持中英文、多语种文本检测 | ch_det_mv3_db_v2.0.yml | 2.60M | 推理模型 |
| ch_ppocr_mobile_v2.0_det | 原始超轻量模型,支持中英文、多语种文本检测 | ch_det_mv3_db_v2.0.yml | 3.0M | 推理模型 / 训练模型 |
| ch_ppocr_server_v2.0_det | 通用模型,支持中英文、多语种文本检测,比超轻量模型更大,但效果更好 | ch_det_res18_db_v2.0.yml | 47.0M | 推理模型 / 训练模型 |
【英文检测模型】
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| en_PP-OCRv3_det_slim | 【最新】slim量化版超轻量模型,支持英文、数字检测 | ch_PP-OCRv3_det_cml.yml | 1.1M | 推理模型 / 训练模型 / nb模型 |
| en_PP-OCRv3_det | 【最新】原始超轻量模型,支持英文、数字检测 | ch_PP-OCRv3_det_cml.yml | 3.8M | 推理模型 / 训练模型 |
【多语言检测模型】
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ml_PP-OCRv3_det_slim | 【最新】slim量化版超轻量模型,支持多语言检测 | ch_PP-OCRv3_det_cml.yml | 1.1M | 推理模型 / 训练模型 / nb模型 |
| ml_PP-OCRv3_det | 【最新】原始超轻量模型,支持多语言检测 | ch_PP-OCRv3_det_cml.yml | 3.8M | 推理模型 / 训练模型 |
【中文识别模型】
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ch_PP-OCRv4_rec | 【最新】超轻量模型,支持中英文、数字识别 | ch_PP-OCRv4_rec_distill.yml | 10M | 推理模型 / 训练模型 |
| ch_PP-OCRv4_server_rec | 【最新】高精度模型,支持中英文、数字识别 | ch_PP-OCRv4_rec_hgnet.yml | 88M | 推理模型 / 训练模型 |
| ch_PP-OCRv3_rec_slim | slim量化版超轻量模型,支持中英文、数字识别 | ch_PP-OCRv3_rec_distillation.yml | 4.9M | 推理模型 / 训练模型 / nb模型 |
| ch_PP-OCRv3_rec | 原始超轻量模型,支持中英文、数字识别 | ch_PP-OCRv3_rec_distillation.yml | 12.4M | 推理模型 / 训练模型 |
| ch_PP-OCRv2_rec_slim | slim量化版超轻量模型,支持中英文、数字识别 | ch_PP-OCRv2_rec.yml | 9.0M | 推理模型 / 训练模型 |
| ch_PP-OCRv2_rec | 原始超轻量模型,支持中英文、数字识别 | ch_PP-OCRv2_rec_distillation.yml | 8.50M | 推理模型 / 训练模型 |
| ch_ppocr_mobile_slim_v2.0_rec | slim裁剪量化版超轻量模型,支持中英文、数字识别 | rec_chinese_lite_train_v2.0.yml | 6.0M | 推理模型 / 训练模型 |
| ch_ppocr_mobile_v2.0_rec | 原始超轻量模型,支持中英文、数字识别 | rec_chinese_lite_train_v2.0.yml | 5.20M | 推理模型 / 训练模型 / 预训练模型 |
| ch_ppocr_server_v2.0_rec | 通用模型,支持中英文、数字识别 | rec_chinese_common_train_v2.0.yml | 94.8M | 推理模型 / 训练模型 / 预训练模型 |
【英文识别模型】
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| en_PP-OCRv4_rec | 【最新】原始超轻量模型,支持英文、数字识别 | en_PP-OCRv4_rec.yml | 9.7M | 推理模型 / 训练模型 |
| en_PP-OCRv3_rec_slim | slim量化版超轻量模型,支持英文、数字识别 | en_PP-OCRv3_rec.yml | 3.2M | 推理模型 / 训练模型 / nb模型 |
| en_PP-OCRv3_rec | 原始超轻量模型,支持英文、数字识别 | en_PP-OCRv3_rec.yml | 9.6M | 推理模型 / 训练模型 |
| en_number_mobile_slim_v2.0_rec | slim裁剪量化版超轻量模型,支持英文、数字识别 | rec_en_number_lite_train.yml | 2.7M | 推理模型 / 训练模型 |
| en_number_mobile_v2.0_rec | 原始超轻量模型,支持英文、数字识别 | rec_en_number_lite_train.yml | 2.6M | 推理模型 / 训练模型 |
【多语言识别模型】
| 模型名称 | 字典文件 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|---|
| korean_PP-OCRv3_rec | ppocr/utils/dict/korean_dict.txt | 韩文识别 | korean_PP-OCRv3_rec.yml | 11.0M | 推理模型 / 训练模型 |
| japan_PP-OCRv3_rec | ppocr/utils/dict/japan_dict.txt | 日文识别 | japan_PP-OCRv3_rec.yml | 11.0M | 推理模型 / 训练模型 |
| chinese_cht_PP-OCRv3_rec | ppocr/utils/dict/chinese_cht_dict.txt | 中文繁体识别 | chinese_cht_PP-OCRv3_rec.yml | 12.0M | 推理模型 / 训练模型 |
| te_PP-OCRv3_rec | ppocr/utils/dict/te_dict.txt | 泰卢固文识别 | te_PP-OCRv3_rec.yml | 9.6M | 推理模型 / 训练模型 |
| ka_PP-OCRv3_rec | ppocr/utils/dict/ka_dict.txt | 卡纳达文识别 | ka_PP-OCRv3_rec.yml | 9.9M | 推理模型 / 训练模型 |
| ta_PP-OCRv3_rec | ppocr/utils/dict/ta_dict.txt | 泰米尔文识别 | ta_PP-OCRv3_rec.yml | 9.6M | 推理模型 / 训练模型 |
| latin_PP-OCRv3_rec | ppocr/utils/dict/latin_dict.txt | 拉丁文识别 | latin_PP-OCRv3_rec.yml | 9.7M | 推理模型 / 训练模型 |
| arabic_PP-OCRv3_rec | ppocr/utils/dict/arabic_dict.txt | 阿拉伯字母 | arabic_PP-OCRv3_rec.yml | 9.6M | 推理模型 / 训练模型 |
| cyrillic_PP-OCRv3_rec | ppocr/utils/dict/cyrillic_dict.txt | 斯拉夫字母 | cyrillic_PP-OCRv3_rec.yml | 9.6M | 推理模型 / 训练模型 |
| devanagari_PP-OCRv3_rec | ppocr/utils/dict/devanagari_dict.txt | 梵文字母 | devanagari_PP-OCRv3_rec.yml | 9.9M | 推理模型 / 训练模型 |
【文本方向分类模型】
| 模型名称 | 模型简介 | 配置文件 | 推理模型大小 | 下载地址 |
|---|---|---|---|---|
| ch_ppocr_mobile_slim_v2.0_cls | slim量化版模型,对检测到的文本行文字角度分类 | cls_mv3.yml | 2.1M | 推理模型 / 训练模型 / nb模型 |
| ch_ppocr_mobile_v2.0_cls | 原始分类器模型,对检测到的文本行文字角度分类 | cls_mv3.yml | 1.38M | 推理模型 / 训练模型 |
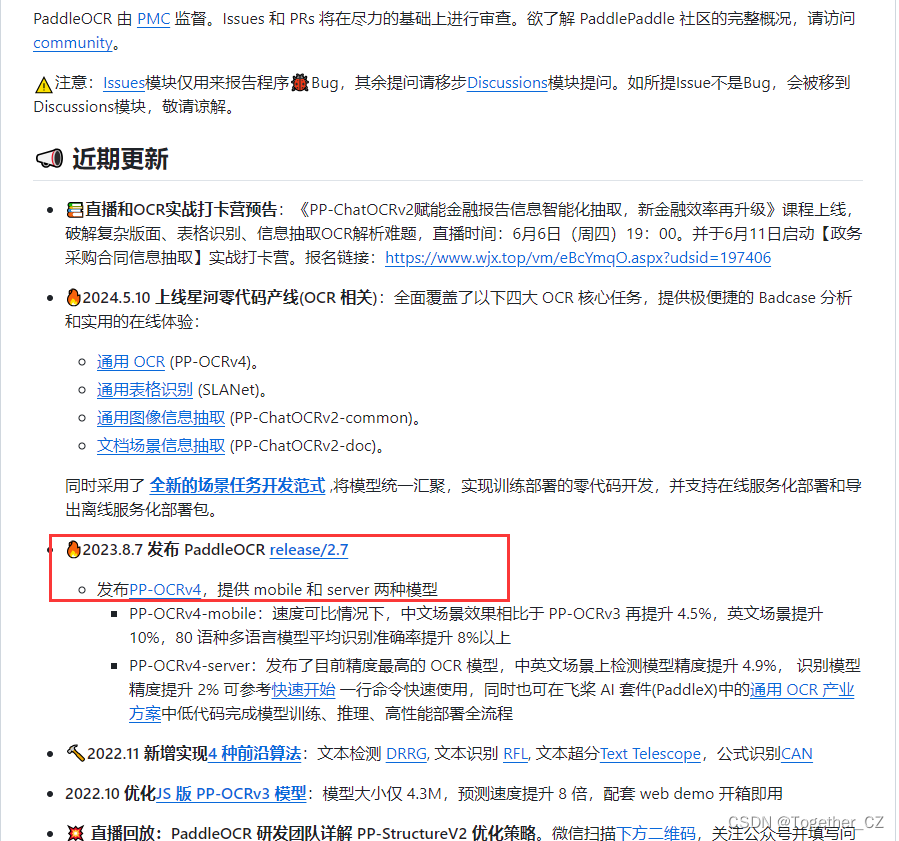
这里我们选择的是PaddleOCRv3模型来进行应用开发,PP-OCRv3在PP-OCRv2的基础上进一步升级。整体的框架图保持了与PP-OCRv2相同的pipeline,针对检测模型和识别模型进行了优化。其中,检测模块仍基于DB算法优化,而识别模块不再采用CRNN,换成了IJCAI 2022最新收录的文本识别算法SVTR,并对其进行产业适配。PP-OCRv3系统框图如下所示(粉色框中为PP-OCRv3新增策略):
从算法改进思路上看,分别针对检测和识别模型,进行了共9个方面的改进:
-
检测模块:
- LK-PAN:大感受野的PAN结构;
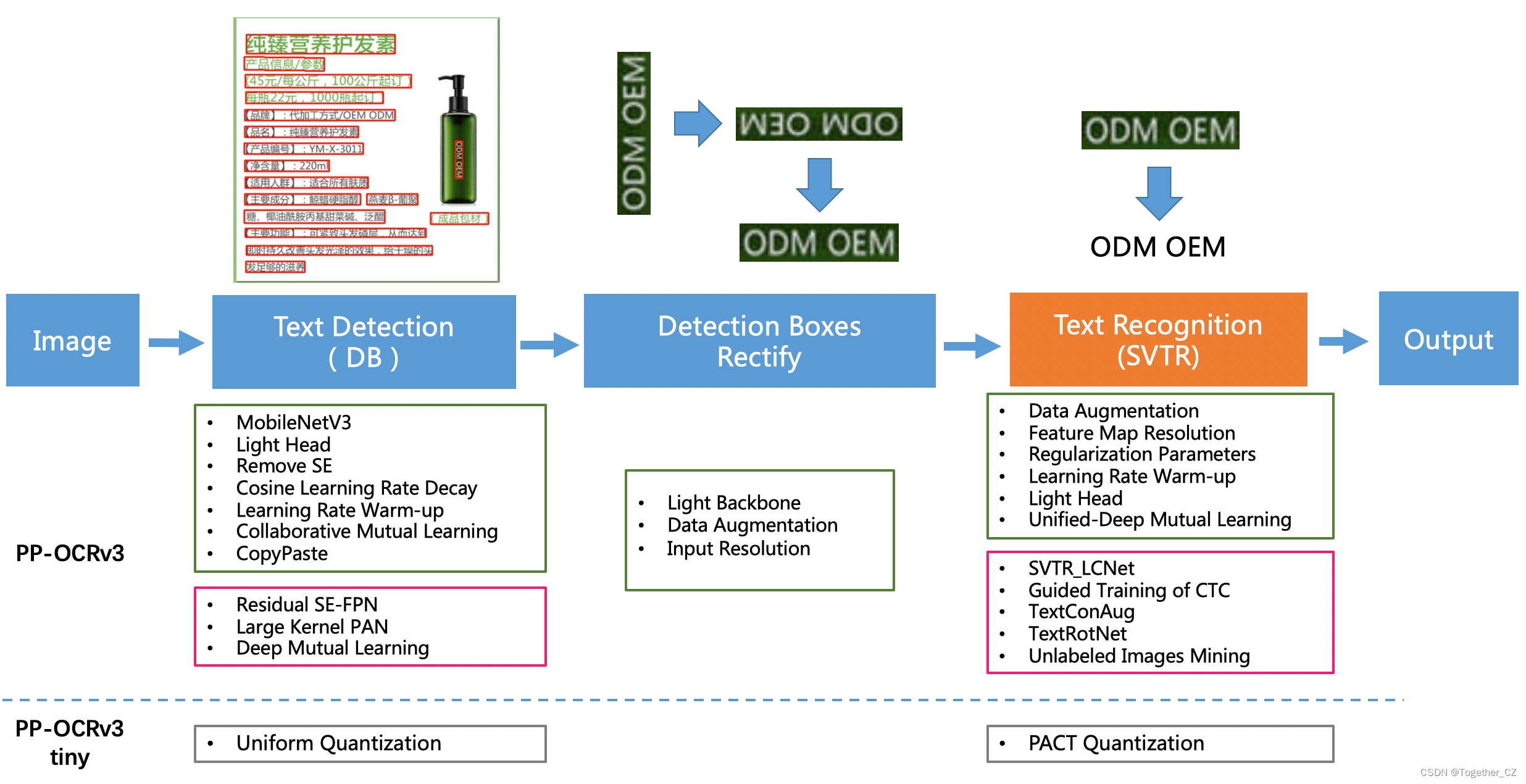
- DML:教师模型互学习策略;
- RSE-FPN:残差注意力机制的FPN结构;
-
识别模块:
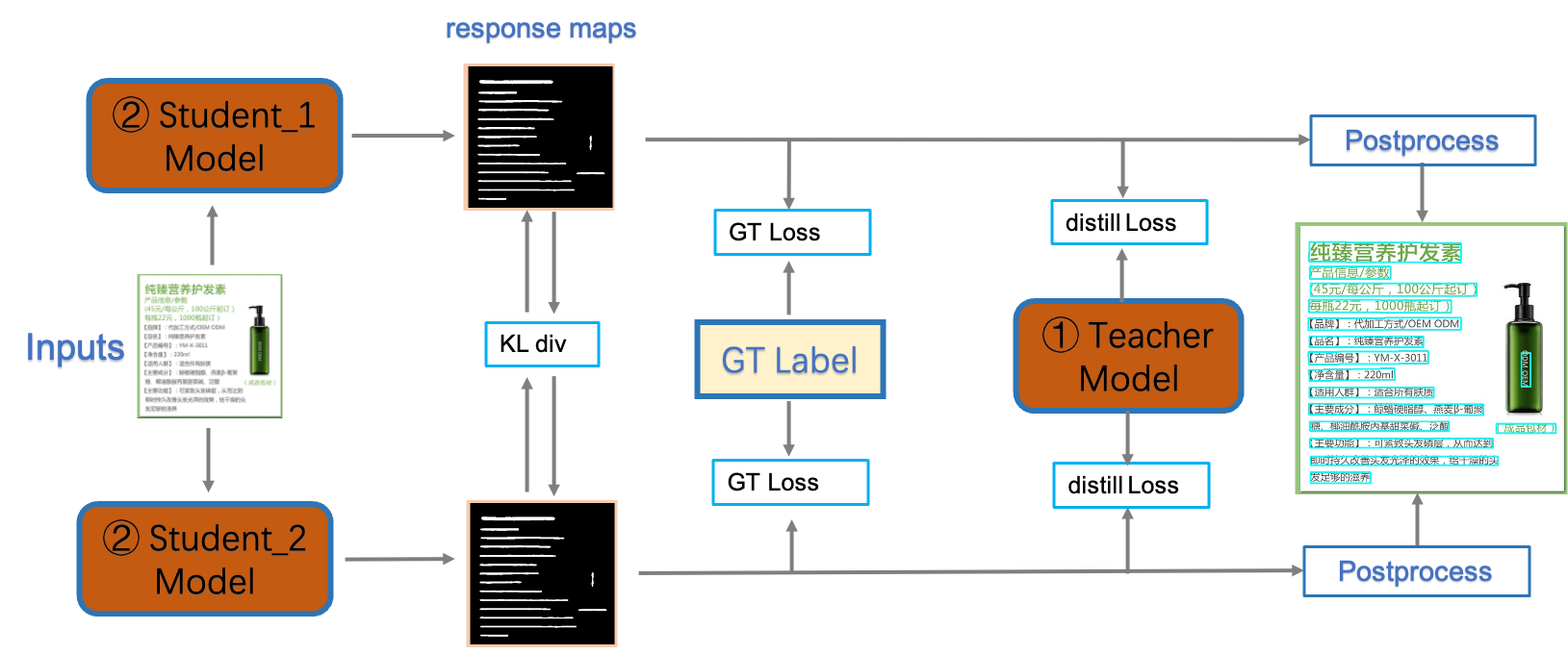
- SVTR_LCNet:轻量级文本识别网络;
- GTC:Attention指导CTC训练策略;
- TextConAug:挖掘文字上下文信息的数据增广策略;
- TextRotNet:自监督的预训练模型;
- UDML:联合互学习策略;
- UIM:无标注数据挖掘方案。
从效果上看,速度可比情况下,多种场景精度均有大幅提升:
- 中文场景,相对于PP-OCRv2中文模型提升超5%;
- 英文数字场景,相比于PP-OCRv2英文模型提升11%;
- 多语言场景,优化80+语种识别效果,平均准确率提升超5%。
【检测端优化】
【识别端优化】
这里我们只是简单的了解了官方团队的开发历程,没有深入去分析学习原理,主要是想要能够应用开发自己的文本检测识别系统。
PaddlePaddle环境我本地并没有安装,所以没有办法使用原生的模型权重来进行推理计算,所以我这里想的是将其转化为onnx格式然后再借助于ort进行推理。
首先下载所需要的模型权重:
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar
cd ./inference && tar xf ch_PP-OCRv3_det_infer.tar && cd ..
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar
cd ./inference && tar xf ch_PP-OCRv3_rec_infer.tar && cd ..
wget -nc -P ./inference https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar
cd ./inference && tar xf ch_ppocr_mobile_v2.0_cls_infer.tar && cd ..之后使用 Paddle2ONNX 将Paddle静态图模型转换为ONNX模型格式:
paddle2onnx --model_dir ./inference/ch_PP-OCRv3_det_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./inference/det_onnx/model.onnx \
--opset_version 11 \
--enable_onnx_checker True
paddle2onnx --model_dir ./inference/ch_PP-OCRv3_rec_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./inference/rec_onnx/model.onnx \
--opset_version 11 \
--enable_onnx_checker True
paddle2onnx --model_dir ./inference/ch_ppocr_mobile_v2.0_cls_infer \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file ./inference/cls_onnx/model.onnx \
--opset_version 11 \
--enable_onnx_checker True处理完成如下:

官方的项目和文档可以说是很详细了,建议自行好好看看,我们参照官方的实例来构建对应的核心计算流程:
orgImg = cv2.imread(image_path)
box_list = detect_model.detect(orgImg)
print("box_list: ", box_list)
print("total_box_list_num: ", len(box_list))
one_text = ''
texts_list=[]
for one_ploygon in box_list:
print("one_ploygon: ", one_ploygon.tolist())
one_ploygon = detect_model.order_points_clockwise(one_ploygon)
textimg = detect_model.get_rotate_crop_image(orgImg, one_ploygon.astype(np.float32))
angle = angle_model.predict(textimg)
if angle=='180':
textimg = cv2.rotate(textimg, 1)
one_text = rec_model.predict_text(textimg)
one_ploygon = one_ploygon.astype(int)
cv2.polylines(orgImg, [one_ploygon], True, (0, 0, 255), thickness=2)
for i in range(4):
cv2.circle(orgImg, tuple(one_ploygon[i, :]), 3, (0, 255, 0), thickness=-1)
print("one_text: ", one_text)
texts_list.append([one_text, one_ploygon])
cv2.imwrite('result.jpg', orgImg)
return orgImg, texts_list结果实例如下:

为了更加便捷使用,我们基于前面系列博文中开发构建的可视化系统界面应用开发了对应的界面系统,实例如下:


初步的学习实践就到这里,后面有时间再来详细看下官方的项目吧,感兴趣的话也都可以自行尝试下!