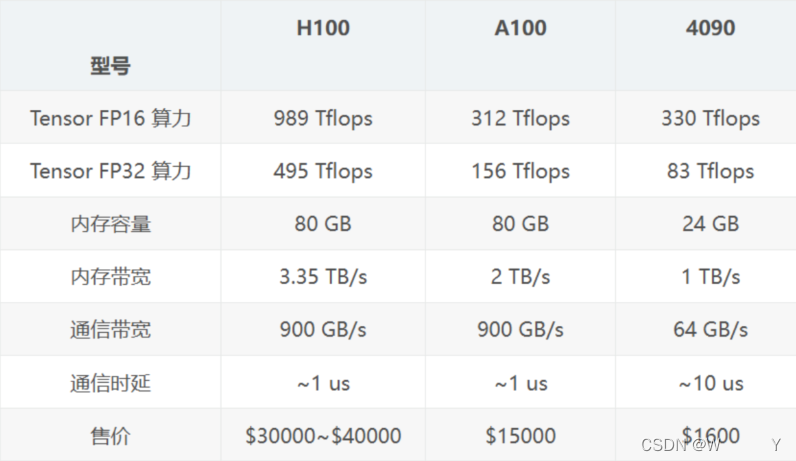
文档切片
文档切片的五个层次
https://medium.com/@anuragmishra_27746/five-levels-of-chunking-strategies-in-rag-notes-from-gregs-video-7b735895694d#b123
Basic RAG 与 Advanced RAG
https://pub.towardsai.net/advanced-rag-techniques-an-illustrated-overview-04d193d8fec6
Basic RAG 的一般流程
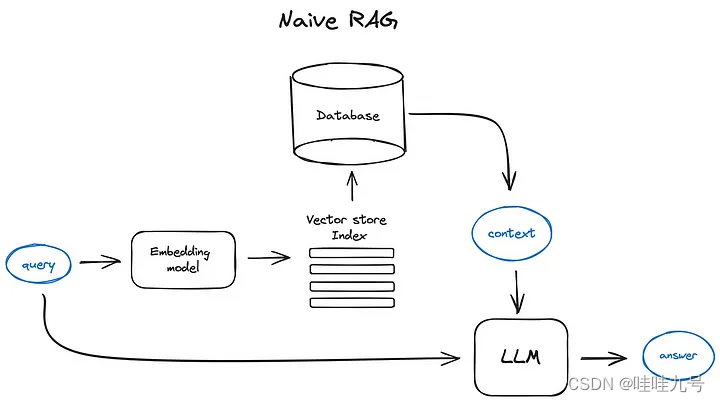
- Vanilla RAG case in brief looks the following way: you split your texts into chunks, then you embed these chunks into vectors with some Transformer Encoder model, you put all those vectors into an index and finally you create a prompt for an LLM that tells the model to answers user’s query given the context we found on the search step.
- In the runtime we vectorise user’s query with the same Encoder model and then execute search of this query vector against the index, find the top-k results, retrieve the corresponding text chunks from our database and feed them into the LLM prompt as context.
- prompt 设计:
def question_answering(context, query): prompt = f""" Give the answer to the user query delimited by triple backticks ```{query}```\ using the information given in context delimited by triple backticks ```{context}```.\ If there is no relevant information in the provided context, try to answer yourself, but tell user that you did not have any relevant context to base your answer on. Be concise and output the answer of size less than 80 tokens. """ response = get_completion(instruction, prompt, model="gpt-3.5-turbo") answer = response.choices[0].message["content"] return answer
Advanced RAG 的一般流程
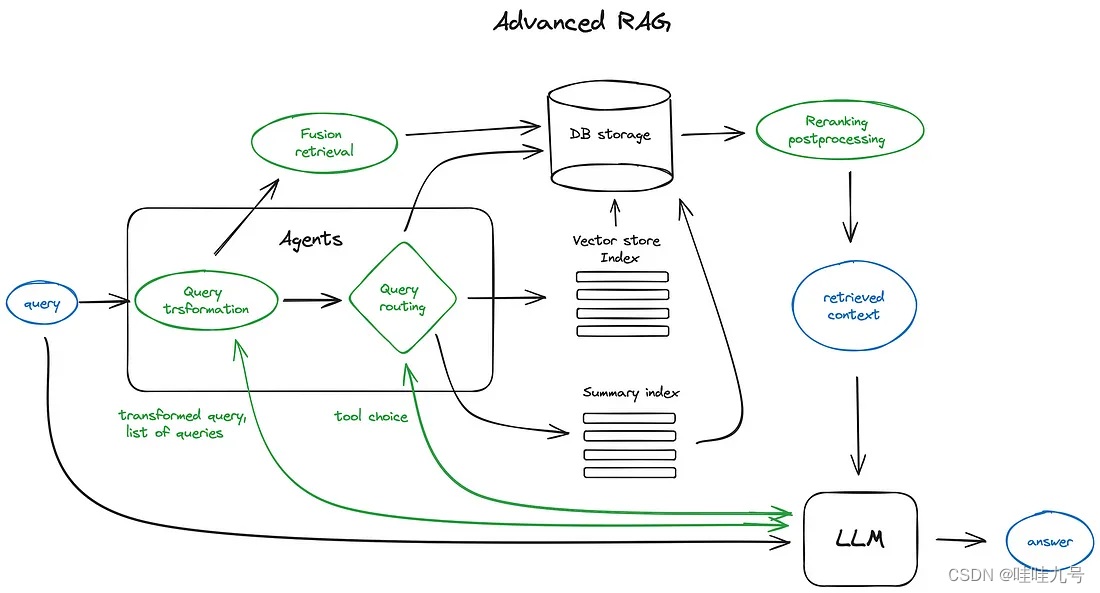
-
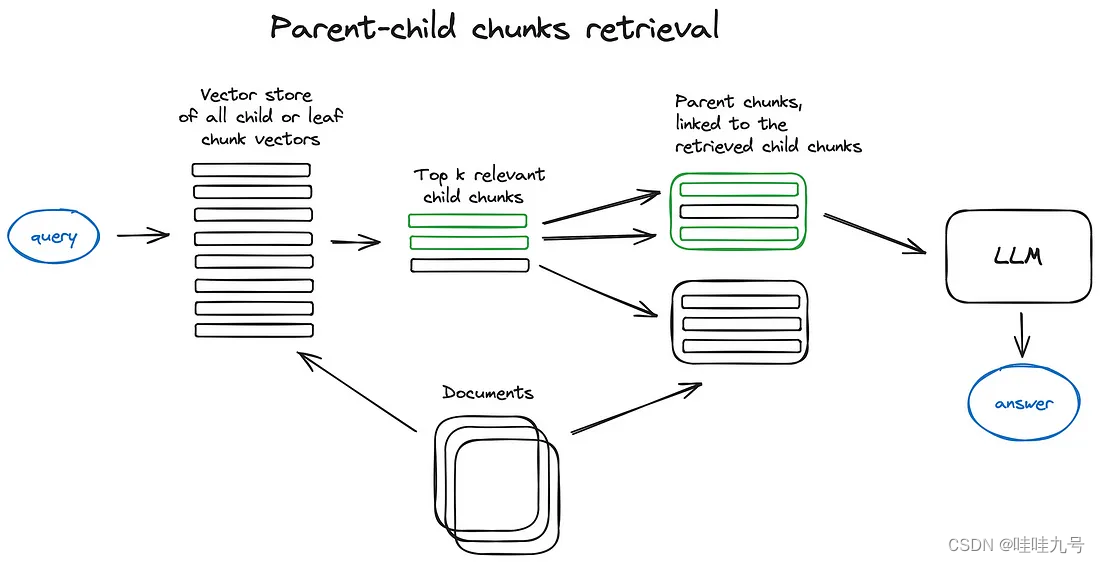
分层索引
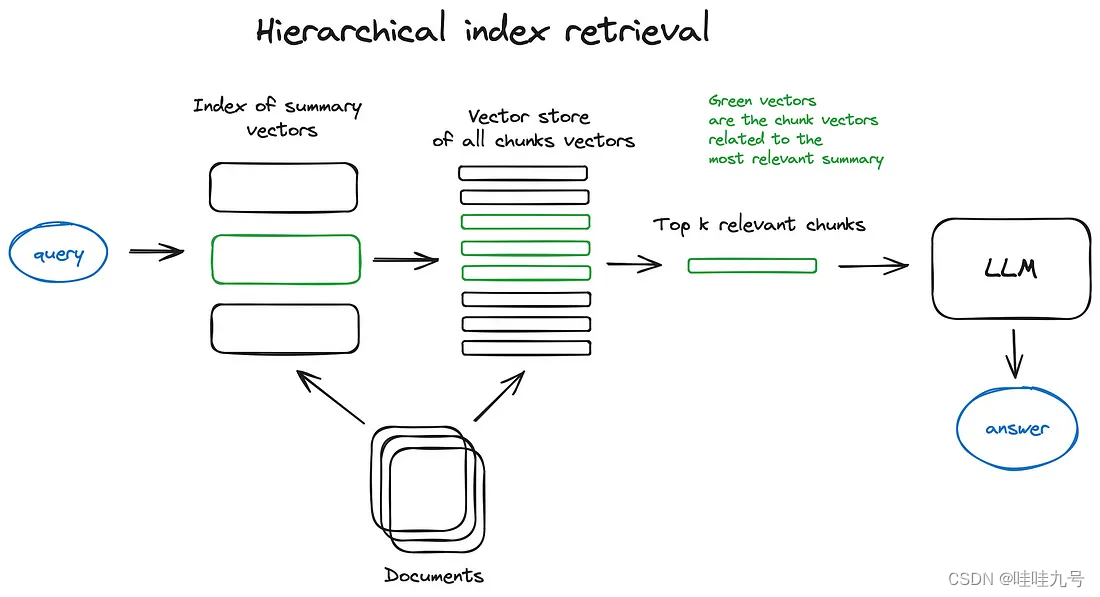
-
上下文窗口扩充