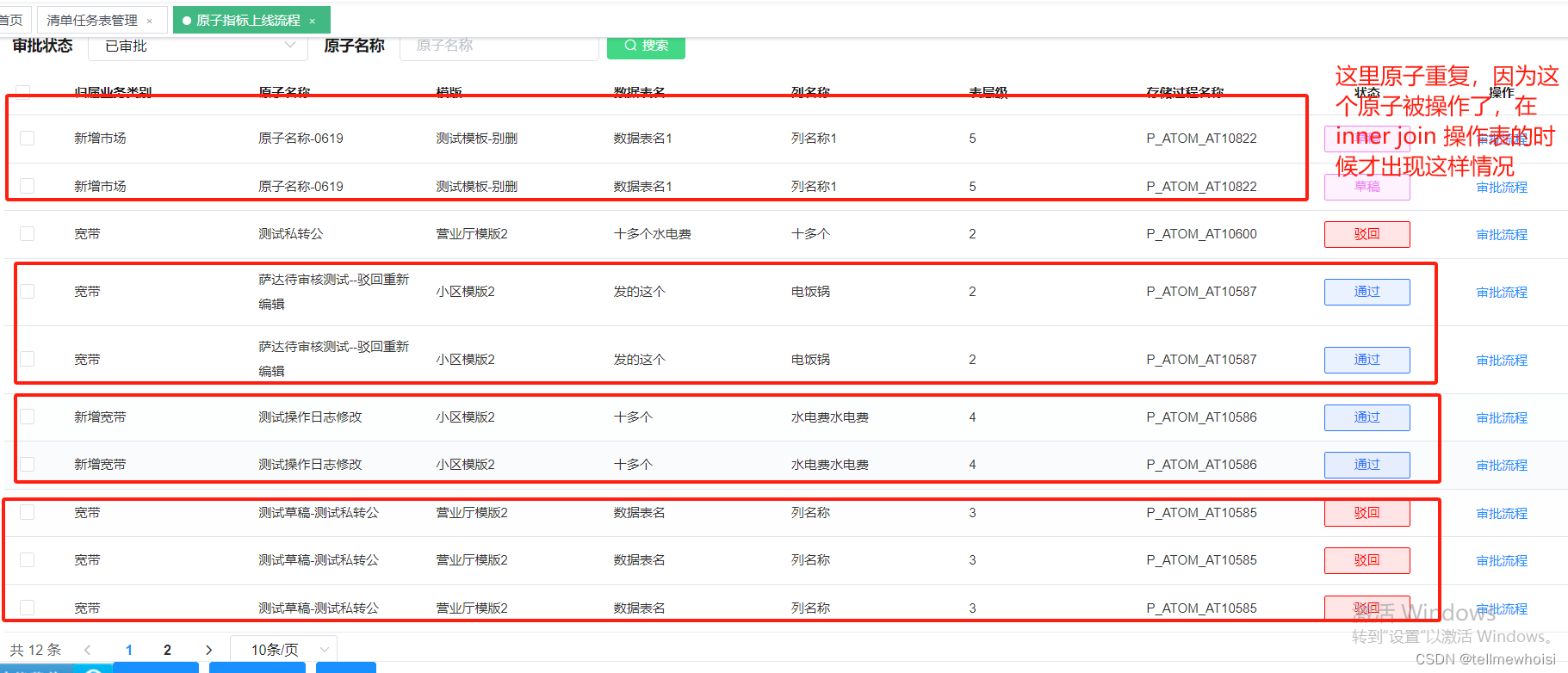
问题1:不使用collection 聚合分页正确
简单列子
T_ATOM_DICT表有
| id | name |
|---|---|
| 1 | 原子1 |
| 2 | 原子2 |
| 3 | 原子3 |
| 4 | 原子4 |
| 5 | 原子5 |
| 6 | 原子6 |
T_ATOM_DICT_AUDIT_ROUTE表审核记录表有
| id | audit |
|---|---|
| 1 | 拒绝 |
| 1 | 通过 |
| 4 | 拒绝 |
我要显示那些原子审核了,我把两个表inner join 就是那些原子审核过了
| id | name | audit |
|---|---|---|
| 1 | 原子1 | 拒绝 |
| 1 | 原子1 | 通过 |
| 4 | 原子4 | 拒绝 |
mapper
IPage<AtomDict> findAllByAuditRouteNoDuplicate(@Param("criteria") AtomDictQueryCriteria criteria, Page<Object> page);
xml基础的查询类型和返回类型
<!-- 分步要用-->
<resultMap id="BaseResultMap" type="com.njry.sjzl.busi.domain.AtomDict">
<result column="ATOM_ID" property="atomId"/>
<result column="ATOM_ID" property="id"/>
<result column="CATEGORY_ID" property="categoryId"/>
<result column="CATEGORY_NAME" property="categoryName"/>
<result column="ATOM_NAME" property="atomName"/>
<result column="TYPE" property="type"/>
<result column="TYPE_NAME" property="typeName" />
<result column="DATA_CYCLE" property="dataCycle"/>
<result column="DATA_CYCLE_NAME" property="dataCycleName"/>
<result column="LIB_TYPE" property="libType"/>
<!-- <result column="AUDIT_RESULT" property="auditResult"/>-->
<!-- <result column="AUDIT_REMARK" property="auditRemark"/>-->
<result column="LIB_TYPE_NAME" property="libTypeName"/>
<result column="DATA_GENE_MODE" property="dataGeneMode"/>
<result column="DATA_GENE_MODE_NAME" property="dataGeneModeName"/>
<result column="TEMPLATE_ID" property="templateId"/>
<result column="TEMPLATE_NAME" property="templateName"/>
<result column="DATABASE" property="database"/>
<result column="DATABASE_NAME" property="databaseName"/>
<result column="DATABASE_TABLE" property="databaseTable"/>
<result column="COLUMN_NAME" property="columnName"/>
<result column="TABLE_LEVEL" property="tableLevel"/>
<result column="PROC_NAME" property="procName"/>
<result column="IS_HZ" property="isHz"/>
<result column="STATUS" property="status"/>
<result column="ATOM_TABLE" property="atomTable"/>
<result column="MODE_FLAG" property="modeFlag"/>
<result column="CREATE_ID" property="createId"/>
<result column="CREATE_DATE" property="createDate"/>
<result column="REC_ID" property="recId"/>
<result column="REC_DATE" property="recDate"/>
<result column="SH_ID" property="shId"/>
<result column="SH_DATE" property="shDate"/>
<result column="SH_REMARK" property="shRemark"/>
<result column="DEL_ID" property="delId"/>
<result column="DEL_DATE" property="delDate"/>
<result column="START_DATE" property="startDate"/>
<result column="END_DATE" property="endDate"/>
<result column="UNIT" property="unit"/>
<result column="DIMEN_FLAG" property="dimenFlag"/>
</resultMap>
<resultMap id="BaseResultMapBoss" type="com.njry.sjzl.busi.domain.AtomDict">
<result column="ATOM_ID" property="atomId"/>
<result column="ATOM_ID" property="id"/>
<result column="CATEGORY_ID" property="categoryId"/>
<result column="CATEGORY_NAME" property="categoryName"/>
<result column="ATOM_NAME" property="atomName"/>
<result column="TYPE" property="type"/>
<result column="TYPE_NAME" property="typeName" />
<result column="DATA_CYCLE" property="dataCycle"/>
<result column="DATA_CYCLE_NAME" property="dataCycleName"/>
<result column="LIB_TYPE" property="libType"/>
<result column="LIB_TYPE_NAME" property="libTypeName"/>
<result column="DATA_GENE_MODE" property="dataGeneMode"/>
<result column="DATA_GENE_MODE_NAME" property="dataGeneModeName"/>
<result column="TEMPLATE_ID" property="templateId"/>
<result column="TEMPLATE_NAME" property="templateName"/>
<result column="DATABASE" property="database"/>
<result column="DATABASE_NAME" property="databaseName"/>
<result column="DATABASE_TABLE" property="databaseTable"/>
<result column="COLUMN_NAME" property="columnName"/>
<result column="TABLE_LEVEL" property="tableLevel"/>
<result column="PROC_NAME" property="procName"/>
<result column="IS_HZ" property="isHz"/>
<result column="STATUS" property="status"/>
<result column="ATOM_TABLE" property="atomTable"/>
<result column="MODE_FLAG" property="modeFlag"/>
<result column="CREATE_ID" property="createId"/>
<result column="CREATE_DATE" property="createDate"/>
<result column="REC_ID" property="recId"/>
<result column="REC_DATE" property="recDate"/>
<result column="SH_ID" property="shId"/>
<result column="SH_DATE" property="shDate"/>
<result column="SH_REMARK" property="shRemark"/>
<result column="DEL_ID" property="delId"/>
<result column="DEL_DATE" property="delDate"/>
<result column="START_DATE" property="startDate"/>
<result column="END_DATE" property="endDate"/>
<result column="UNIT" property="unit"/>
<result column="DIMEN_FLAG" property="dimenFlag"/>
</resultMap>
<!-- <collection property="batchList" resultMap="BatchListResultMap"/>-->
<!-- 审核表数据还得关联用户表显示用户名-->
<resultMap id="BatchListResultMap" type="com.njry.sjzl.busi.domain.AtomDictAuditRoute">
<result column="ROUTE_ID" property="routeId"/>
<result column="ROUTE_ID" property="id"/>
<result column="ATOM_IDREPEAT" property="atomId"/>
<result column="AUDIT_RESULT" property="auditResult"/>
<result column="AUDIT_REMARK" property="auditRemark"/>
<result column="AUDIT_ID" property="auditId"/>
<result column="AUDIT_NAME" property="auditName"/>
<result column="AUDIT_DATE" property="auditDate"/>
</resultMap>
<sql id="BathList_Column_List">
auditroute.ROUTE_ID as ROUTE_ID, auditroute.ATOM_ID as ATOM_IDREPEAT, tuser.NAME AS AUDIT_NAME,
auditroute.AUDIT_RESULT as AUDIT_RESULT, auditroute.AUDIT_REMARK as AUDIT_REMARK,auditroute.AUDIT_ID as AUDIT_ID,auditroute.AUDIT_DATE as AUDIT_DATE
</sql>
<sql id="Base_Column_List">
tad.ATOM_ID, tad.CATEGORY_ID, tad.ATOM_NAME, tad.TYPE, tad.DATA_CYCLE, tad.LIB_TYPE, tad.DATA_GENE_MODE, tad.TEMPLATE_ID, tad.DATABASE_TABLE, tad."DATABASE",tad.COLUMN_NAME, tad.TABLE_LEVEL, tad.PROC_NAME, tad.IS_HZ, tad.STATUS, tad.ATOM_TABLE, tad.MODE_FLAG, tad.CREATE_ID,tad.CREATE_DATE, tad.REC_ID, tad.REC_DATE, tad.SH_ID, tad.SH_DATE, tad.SH_REMARK, tad.DEL_ID, tad.DEL_DATE, tad.START_DATE, tad.END_DATE, tad.UNIT, tad.DIMEN_FLAG
</sql>
<!-- 数据字典回显名字-->
<sql id="Dict_Detail_Column_List">
dtable.label AS DATABASE_NAME,
dtable1.label AS DATA_GENE_MODE_NAME,
dtable2.label AS LIB_TYPE_NAME,
dtable3.label AS DATA_CYCLE_NAME,
dtable4.label AS TYPE_NAME
</sql>
真正xml如下:关联很多表回显,T_ATOM_TEMPLATE模板表,T_ATOM_BUSI_CATEGORY业务分类,五个字典表,和(原子审核表,原子审核表要关联用户表差审核用户名)
<select id="findAllByAuditRouteNoDuplicate" resultMap="BaseResultMapBoss">
select tatempalte.TEMPLATE_NAME,tabc.CATEGORY_NAME AS CATEGORY_NAME,
<include refid="Base_Column_List"/>,
<include refid="Dict_Detail_Column_List"/>,
<include refid="BathList_Column_List"/>
from T_ATOM_DICT tad
left join T_ATOM_TEMPLATE tatempalte on tatempalte.TEMPLATE_ID = tad.TEMPLATE_ID
left join T_ATOM_BUSI_CATEGORY tabc on tad.CATEGORY_ID = tabc.category_id
left join (select dd.label,dd.value from t_dict d left join t_dict_detail dd on dd.dict_id = d.dict_id
where d.name = 'asset_archive_name') dtable
on tad.DATABASE = dtable.value
left join (select dd1.label,dd1.value from t_dict d1 left join t_dict_detail dd1 on dd1.dict_id = d1.dict_id
where d1.name = 't_atmo_dict_generation_mechanism') dtable1
on tad.DATA_GENE_MODE = dtable1.value
left join (select dd2.label,dd2.value from t_dict d2 left join t_dict_detail dd2 on dd2.dict_id = d2.dict_id
where d2.name = 't_atmo_dict_atomic_library_type') dtable2
on tad.LIB_TYPE = dtable2.value
left join (select dd3.label,dd3.value from t_dict d3 left join t_dict_detail dd3 on dd3.dict_id = d3.dict_id
where d3.name = 't_atmo_dict_data_cycle') dtable3
on tad.DATA_CYCLE = dtable3.value
left join (select dd4.label,dd4.value from t_dict d4 left join t_dict_detail dd4 on dd4.dict_id = d4.dict_id
where d4.name = 't_atmo_dict_data_type') dtable4
on tad.TYPE = dtable4.value
inner join (select ATOM_ID,AUDIT_RESULT,AUDIT_REMARK,ROUTE_ID,AUDIT_ID,AUDIT_DATE
from T_ATOM_DICT_AUDIT_ROUTE) auditroute on auditroute.ATOM_ID =tad.ATOM_ID
left join t_user tuser on tuser.oper_id = auditroute.AUDIT_ID
<where>
<if test="criteria.atomId != null">
and tad.ATOM_ID = #{criteria.atomId}
</if>
<if test="criteria.atomName != null">
and tad.ATOM_NAME like concat('%'||#{criteria.atomName},'%')
</if>
</where>
order by tad.CREATE_DATE desc, auditroute.AUDIT_DATE asc
</select>
问题2:使用collection 聚合出现分页问题
xml基础的查询类型和返回类型 里面把注释的
方法返回类型 id = “BaseResultMapBoss” 里
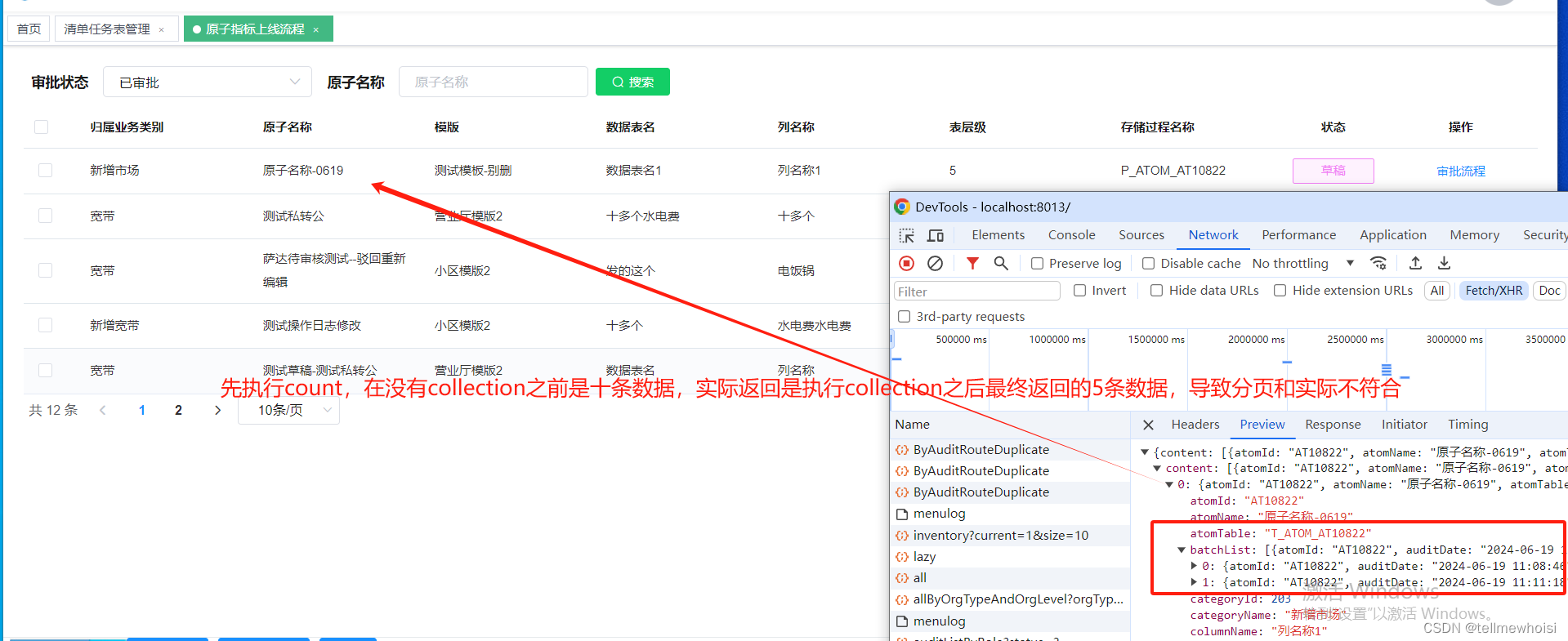
解决办法1(我最蠢的解决办法,把sql分解)
不知道怎么自定义分页解决这种(不会),
我只能把这一个sql语句分开
在impl层
@Override
public PageResult<AtomDict> queryAllByAuditRouteDuplicate(AtomDictQueryCriteria criteria, Page<Object> page){
// 去重 inner join(原来一个sql就该搞定的)
// IPage<AtomDict> all = atomDictMapper.findAllByAuditRouteNoDuplicate(criteria, page);
// 去重 inner join(分步1)
IPage<AtomDict> all = atomDictMapper.findAllByAuditRouteNoDuplicateSubstep(criteria, page);
List<AtomDict> records = all.getRecords();
// 根据每条数据类的busiSort递归向下查找归属业务分类(回显)
// 每条数据类还要找自己的审批过程(分步2)
if(records.size() > 0 ){
for (int i = 0; i < records.size(); i++) {
AtomDict atomDict = records.get(i);
if(atomDict != null){
Set<String> taskSetResult = new LinkedHashSet<>();
Long categoryId = atomDict.getCategoryId();
// 这里拿到第一步去重的审核原子再去查审核记录,放在返回前端的BatchList 里面
List<AtomDictAuditRoute> atomDictAuditRoutes = atomDictMapper.selectBath(atomDict.getAtomId());
atomDict.setBatchList(atomDictAuditRoutes);
if(categoryId != null){
List<String> subCategory = atomBusiCategoryMapper.findSubCategory(categoryId);
String currentCategoryName = atomBusiCategoryMapper.findCategoryNameByCateforyId(categoryId);
taskSetResult.addAll(subCategory);
taskSetResult.add(currentCategoryName);
String temp = "";
for(String item : taskSetResult){
temp += ","+item;
}
String result = temp.substring(1);
atomDict.setCategoryName(result);
}
}
}
}
return PageUtil.toPage(all);
}
mapper
IPage<AtomDict> findAllByAuditRouteNoDuplicateSubstep(@Param("criteria") AtomDictQueryCriteria criteria, Page<Object> page);
List<AtomDictAuditRoute> selectBath(@Param("atomId") String atomId);
xml
<!-- 关联审核表确定原子已经审核,因为原子审核触发,在原子表没有字段判断是否审核字段修改,才导致要关联审核记录表判断(关键还得去重):和原来区别就是不collection并且去重-->
<select id="findAllByAuditRouteNoDuplicateSubstep" resultMap="BaseResultMap">
select stupid.* from (
select row_number() over(partition by tad.ATOM_ID order by tad.CREATE_DATE desc) rn,tatempalte.TEMPLATE_NAME,tabc.CATEGORY_NAME AS CATEGORY_NAME,
<include refid="Base_Column_List"/>,
<include refid="Dict_Detail_Column_List"/>
from T_ATOM_DICT tad
left join T_ATOM_TEMPLATE tatempalte on tatempalte.TEMPLATE_ID = tad.TEMPLATE_ID
left join T_ATOM_BUSI_CATEGORY tabc on tad.CATEGORY_ID = tabc.category_id
left join (select dd.label,dd.value from t_dict d left join t_dict_detail dd on dd.dict_id = d.dict_id
where d.name = 'asset_archive_name') dtable
on tad.DATABASE = dtable.value
left join (select dd1.label,dd1.value from t_dict d1 left join t_dict_detail dd1 on dd1.dict_id = d1.dict_id
where d1.name = 't_atmo_dict_generation_mechanism') dtable1
on tad.DATA_GENE_MODE = dtable1.value
left join (select dd2.label,dd2.value from t_dict d2 left join t_dict_detail dd2 on dd2.dict_id = d2.dict_id
where d2.name = 't_atmo_dict_atomic_library_type') dtable2
on tad.LIB_TYPE = dtable2.value
left join (select dd3.label,dd3.value from t_dict d3 left join t_dict_detail dd3 on dd3.dict_id = d3.dict_id
where d3.name = 't_atmo_dict_data_cycle') dtable3
on tad.DATA_CYCLE = dtable3.value
left join (select dd4.label,dd4.value from t_dict d4 left join t_dict_detail dd4 on dd4.dict_id = d4.dict_id
where d4.name = 't_atmo_dict_data_type') dtable4
on tad.TYPE = dtable4.value
inner join (select ATOM_ID,AUDIT_RESULT,AUDIT_REMARK,ROUTE_ID,AUDIT_ID,AUDIT_DATE
from T_ATOM_DICT_AUDIT_ROUTE) auditroute on auditroute.ATOM_ID =tad.ATOM_ID
left join t_user tuser on tuser.oper_id = auditroute.AUDIT_ID
<where>
<if test="criteria.atomId != null">
and tad.ATOM_ID = #{criteria.atomId}
</if>
<if test="criteria.atomName != null">
and tad.ATOM_NAME like concat('%'||#{criteria.atomName},'%')
</if>
</where>
) stupid
where stupid.rn = 1
</select>
<select id="selectBath" resultMap="BatchListResultMap">
select <include refid="BathList_Column_List"/>
from (select ATOM_ID,AUDIT_RESULT,AUDIT_REMARK,ROUTE_ID,AUDIT_ID,AUDIT_DATE
from T_ATOM_DICT_AUDIT_ROUTE) auditroute
left join t_user tuser on tuser.oper_id = auditroute.AUDIT_ID
where auditroute.ATOM_ID = #{atomId}
</select>
解决方法2(设计表时候应该加一个冗余字段)
我仔细想了一下,都是因为T_ATOM_DICT这个原子表缺少一个是否审核字段,(只要触发审核,就修改这个原子是否审核的状态)如果加这个字段就可以直接用collection收集这个原子的审批记录
解决方法3就是我不会的那种,求路过大神指教