文章目录
- 1.硬件配置选择
- 1.场景说明
- 2.服务器台数选择
- 3.磁盘选择
- 4.内存选择
- 1) 堆内存配置
- 2)页缓存配置
- 5. cpu选择
- 6.网络选择
- 2.生产者
- 3.kafka broker
- 4. 服役新节点,退役旧节点
- 1)创建一个要均衡的主题。
- 2) 生成一个负载均衡的计划
- leader分布不均匀解决办法
- 生产环境需要关闭的属性
1.硬件配置选择
1.场景说明
100万日活,每人每天100条日志,每天总共的日志条数是100万100条=1亿条。
1亿/24小时/60分/60秒=1150条/每秒钟。每条日志大小:0.5k-2k(取1k)。
1150条/每秒钟 1k≈1m/s。
高峰期每秒钟:1150条*20倍=23000条。每秒多少数据量:20MB/s。
2.服务器台数选择
服务器台数=2 (生产者峰值生产速率副本/ 100)+ 1
= 2 *(20m/s * 2/100)+ 1
= 3台建议3台服务器。
3.磁盘选择
kafka底层主要是顺序写,固态硬盘和机械硬盘的顺序写速度差不多。建议选择普通的机械硬盘。
每天总数据量:1亿条* 1k≈100g
100g副本2保存时间3天/ 0.7≈1T建议三台服务器硬盘总大小,大于等于1T。
4.内存选择
kafka 内存组成:堆内存+页缓存
1) 堆内存配置
kafka 堆内存建议每个节点:10g~15g
修改kafka-server-start.sh
默认配置
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G"
fi
建议修改为:
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then
export KAFKA_HEAP_OPTS="-Xmx10G-Xms10G"
fi
2)页缓存配置
页缓存:页缓存是Linux系统服务器的内存。我们只需要保证1个segment(1g)中25%的数据在内存中就好。
每个节点页缓存大小=(分区数1g 25%)/节点数。例如10个分区,页缓存大小=(101g25%)/3≈1g
建议服务器内存大于等于11G (堆内存10g+页缓存1g)
5. cpu选择
num.io.threads=8负责写磁盘的线程数,整个参数值要占总核数的50%。
num.replica.fetchers=1副本拉取线程数,这个参数占总核数的50%的1/3。
num.network.threads=3数据传输线程数,这个参数占总核数的50%的2/3。
建议32个cpu core。
6.网络选择
网络带宽=峰值吞吐量≈20MB/s选择千兆网卡即可。100Mbps单位是bit;10M/s单位是byte;1byte=8bit,100Mbps/8=12.5M/s。一般百兆的网卡(100Mbps)、千兆的网卡(1000Mbps)、万兆的网卡(10000Mbps)。
2.生产者
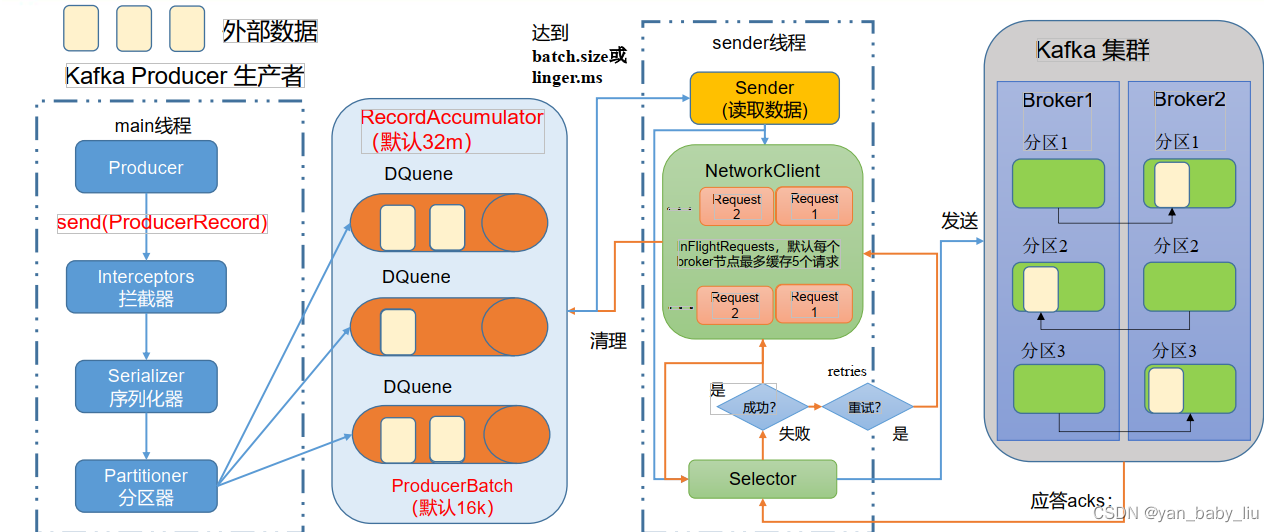
batch.size:只有数据积累到batch.size之后,sender才会发送数据。默认16k•linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。
•0:生产者发送过来的数据,不需要等数据落盘应答。
•1:生产者发送过来的数据,Leader收到数据后应答。
•-1(all):生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答。-1和all等价。
| 参数名称 | 描述 |
|---|---|
| bootstrap.servers | 生产者连接集群所需的broker地址清单。例如hadoop102:9092,hadoop103:9092,hadoop104:9092,可以设置1个或者多个,中间用逗号隔开。注意这里并非需要所有的broker地址,因为生产者从给定的broker里查找到其他broker信息。 |
| key.serializer和value.serializer | 指定发送消息的key和value的序列化类型。一定要写全类名。 |
| buffer.memory | RecordAccumulator缓冲区总大小,默认32m。 |
| batch.size | 缓冲区一批数据最大值,默认16k。适当增加该值,可以提高吞吐量,但是如果该值设置太大,会导致数据传输延迟增加。 |
| linger.ms | 如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。生产环境建议该值大小为5-100ms之间。 |
| acks | 0:生产者发送过来的数据,不需要等数据落盘应答。1:生产者发送过来的数据,Leader收到数据后应答。-1(all):生产者发送过来的数据,Leader+和isr队列里面的所有节点收齐数据后应答。默认值是-1,-1和all是等价的。 |
| max.in.flight.requests.per.connection | 允许最多没有返回ack的次数,默认为5,开启幂等性要保证该值是1-5的数字。 |
| retries | 当消息发送出现错误的时候,系统会重发消息。retries表示重试次数。默认是int最大值,2147483647。如果设置了重试,还想保证消息的有序性,需要设置MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION=1否则在重试此失败消息的时候,其他的消息可能发送成功了。 |
| retry.backoff.ms | 两次重试之间的时间间隔,默认是100ms。 |
| enable.idempotence | 是否开启幂等性,默认true,开启幂等性。 |
| compression.type | 生产者发送的所有数据的压缩方式。默认是none,也就是不压缩。支持压缩类型:none、gzip、snappy、lz4和zstd。 |
3.kafka broker
| 参数名称 | 描述 |
|---|---|
| replica.lag.time.max.ms | ISR中,如果Follower长时间未向Leader发送通信请求或同步数据,则该Follower将被踢出ISR。该时间阈值,默认30s。 |
| auto.leader.rebalance.enable | 默认是true。自动LeaderPartition平衡。建议关闭。 |
| leader.imbalance.per.broker.percentage | 默认是10%。每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。 |
| leader.imbalance.check.interval.seconds | 默认值300秒。检查leader负载是否平衡的间隔时间。 |
| log.segment.bytes | Kafka中log日志是分成一块块存储的,此配置是指log日志划分成块的大小,默认值1G。 |
| log.index.interval.bytes | 默认4kb,kafka里面每当写入了4kb大小的日志(.log),然后就往index文件里面记录一个索引。 |
| log.retention.hours | Kafka中数据保存的时间,默认7天。 |
| log.retention.minutes | Kafka中数据保存的时间,分钟级别,默认关闭。 |
| log.retention.ms | Kafka中数据保存的时间,毫秒级别,默认关闭。 |
| log.retention.check.interval.ms | 检查数据是否保存超时的间隔,默认是5分钟。 |
| log.retention.bytes | 默认等于-1,表示无穷大。超过设置的所有日志总大小,删除最早的segment。 |
| log.cleanup.policy | 默认是delete,表示所有数据启用删除策略;如果设置值为compact,表示所有数据启用压缩策略。 |
| num.io.threads | 默认是8。负责写磁盘的线程数。整个参数值要占总核数的50%。 |
| num.replica.fetchers | 默认是1。副本拉取线程数,这个参数占总核数的50%的1/3 |
| num.network.threads | 默认是3。数据传输线程数,这个参数占总核数的50%的2/3。 |
| log.flush.interval.messages | 强制页缓存刷写到磁盘的条数,默认是long的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。 |
| log.flush.interval.ms | 每隔多久,刷数据到磁盘,默认是null。一般不建议修改,交给系统自己管理。 |
4. 服役新节点,退役旧节点
创建three主题,4个分区,2个副本
[root@node2 kafka_2.12-3.0.0]# bin/kafka-topics.sh --bootstrap-server node1:9092 --create --topic three --partitions 4 --replication-factor 2
Created topic three.
查看下分区和副本情况
[root@node2 kafka_2.12-3.0.0]# bin/kafka-topics.sh --bootstrap-server node1:9092 --describe --topic three
Topic: three TopicId: 7GQ8d0fRRK2xULnj3pbhjg PartitionCount: 4 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: three Partition: 0 Leader: 2 Replicas: 2,1 Isr: 2,1
Topic: three Partition: 1 Leader: 1 Replicas: 1,0 Isr: 1,0
Topic: three Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2
Topic: three Partition: 3 Leader: 2 Replicas: 2,0 Isr: 2,0
现在我们想把three主题的所有副本存储在0 和1 节点上
vim increase-replication-factor.json
{
"version":1,
"partitions":[
{
"topic":"three","partition":0,"replicas":[0,1]
},
{
"topic":"three","partition":1,"replicas":[0,1]
},
{
"topic":"three","partition":2,"replicas":[0,1]
},
{
"topic":"three","partition":3,"replicas":[0,1]
}
]
}
[root@node2 kafka_2.12-3.0.0]# bin/kafka-reassign-partitions.sh --bootstrap-server node1:9092 --reassignment-json-file increase-replication-factor.json --execute
Current partition replica assignment
{"version":1,"partitions":[{"topic":"three","partition":0,"replicas":[2,1],"log_dirs":["any","any"]},{"topic":"three","partition":1,"replicas":[1,0],"log_dirs":["any","any"]},{"topic":"three","partition":2,"replicas":[0,2],"log_dirs":["any","any"]},{"topic":"three","partition":3,"replicas":[2,0],"log_dirs":["any","any"]}]}
Save this to use as the --reassignment-json-file option during rollback
Successfully started partition reassignments for three-0,three-1,three-2,three-3
[root@node2 kafka_2.12-3.0.0]#
验证副本存储计划
bin/kafka-reassign-partitions.sh --bootstrap-server node1:9092 --reassignment-json-file increase-replication-factor.json --verify
查下该topic 信息
[root@node2 kafka_2.12-3.0.0]# bin/kafka-topics.sh --bootstrap-server node1:9092 --topic three --describe
Topic: three TopicId: 7GQ8d0fRRK2xULnj3pbhjg PartitionCount: 4 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: three Partition: 0 Leader: 0 Replicas: 0,1 Isr: 1,0
Topic: three Partition: 1 Leader: 1 Replicas: 0,1 Isr: 1,0
Topic: three Partition: 2 Leader: 0 Replicas: 0,1 Isr: 0,1
Topic: three Partition: 3 Leader: 0 Replicas: 0,1 Isr: 0,1
1)创建一个要均衡的主题。
vimtopics-to-move.json
{
"topics":[
{"topic":"first"}
],
"version":1
}
2) 生成一个负载均衡的计划
[root@node2 kafka_2.12-3.0.0]# bin/kafka-reassign-partitions.sh --bootstrap-server node1:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
Current partition replica assignment
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[1,0,2],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[0,2,1],"log_dirs":["any","any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[1,2,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[2,0,1],"log_dirs":["any","any","any"]}]}
[root@node2 kafka_2.12-3.0.0]#
执行副本存储计划
vim increase-replication-factor-first.json
{“version”:1,“partitions”:[{“topic”:“first”,“partition”:0,“replicas”:[1,0,2],“log_dirs”:[“any”,“any”,“any”]},{“topic”:“first”,“partition”:1,“replicas”:[2,1,0],“log_dirs”:[“any”,“any”,“any”]},{“topic”:“first”,“partition”:2,“replicas”:[0,2,1],“log_dirs”:[“any”,“any”,“any”]}]}
[root@node2 kafka_2.12-3.0.0]# bin/kafka-reassign-partitions.sh --bootstrap-server node1:9092 --reassignment-json-file increase-replication-factor-first.json --execute
验证副本存储计划
[root@node2 kafka_2.12-3.0.0]# bin/kafka-reassign-partitions.sh --bootstrap-server node1:9092 --reassignment-json-file increase-replication-factor-first.json --verify
Status of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.
Clearing broker-level throttles on brokers 0,1,2
Clearing topic-level throttles on topic first
leader分布不均匀解决办法
减少分区(会报错),增加分区
[2023-01-29 16:55:40,828] ERROR org.apache.kafka.common.errors.InvalidPartitionsException: Topic currently has 3 partitions, which is higher than the requested 2.
(kafka.admin.TopicCommand$)
[root@node2 kafka_2.12-3.0.0]# bin/kafka-topics.sh --bootstrap-server node1:9092 --alter --topic first --partitions 4
[root@node2 kafka_2.12-3.0.0]# bin/kafka-topics.sh --bootstrap-server node1:9092 --topic first --describe
Topic: first TopicId: IcU6kbglSSWOkruuSmgryg PartitionCount: 4 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 2 Replicas: 1,0,2 Isr: 2,1,0---
Topic: first Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,0,1
Topic: first Partition: 2 Leader: 2 Replicas: 0,2,1 Isr: 2,0,1
Topic: first Partition: 3 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0
发现leader都是2,将node1,node2,node3上的kafka停止后,重启
如果leader集中的部分机器上,那么该机器的请求压力,吞吐压力就很大,而其他机器的请求量很少,分布不均匀,容易导致数据堆积
vim test.json
{
“partitions”:[
{
“partition”:0,
“topic”:“first”
},
{
“partition”:1,
“topic”:“first”
},
{
“partition”:2,
“topic”:“first”
}
]
}
[root@node2 kafka_2.12-3.0.0]# bin/kafka-leader-election.sh --path-to-json-file test.json --bootstrap-server node1:9092 --election-type PREFERRED
[root@node2 kafka_2.12-3.0.0]# bin/kafka-topics.sh --bootstrap-server node1:9092 --topic first --describe
Topic: first TopicId: IcU6kbglSSWOkruuSmgryg PartitionCount: 4 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: first Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,1,0
Topic: first Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 2,1,0
Topic: first Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 2,1,0
Topic: first Partition: 3 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
直接kafka-leader-election.sh可以把所有topic的所有分区都执行一遍重新平衡,如果集群中需要重平衡的副本较多,则会对客户端带来一定的影响,所以一般生产环境中在使用的时候,会加参数path-to-json-file来指定一个json文件,以对部分分区进行leader重平衡。
例如我们只对topic video_features的分区12、13进行优先副本选举,需要编写一个json文件test1.json:
{
“partitions”:[
{
“partition”:12,
“topic”:“video_features”
},
{
“partition”:13,
“topic”:“video_features”
}
]
}
参考文档:https://blog.csdn.net/worldchinalee/article/details/108213917
kafka集群重启后,leader容易分布不均匀,这个如何一劳永逸的解决呢?不能每次重启以后,重重新分布leader吧?????
生产环境需要关闭的属性
auto.leader.rebalance.enable:ture/false------是否允许定期进行 Leader 选举
若开启,默认300s即5分钟扫描一次,每次若发现每个broker之间的leader对比 比率超过10%,则重新发起选举。
不建议开启
虽然在一定条件下,才会触发leader选举,但是如果把auto.leader.rebaleance.enable设置为true,可能一段时间后leaderA就被强行换成Leader B了

leader更换代价很高的,原本向A发送的请求的所有客户端都要切换到向B发送请求,而且这种更换leader本质上没有任何性能收益,
但是如果关闭,leader一旦宕机,就没有leader了
unclean.leader.election.enable,版本不一样默认值也不一样,建议设置为false

注:虽然设置为false会可能导致该partition不可用,但是设置为ture会有丢数据的风险。