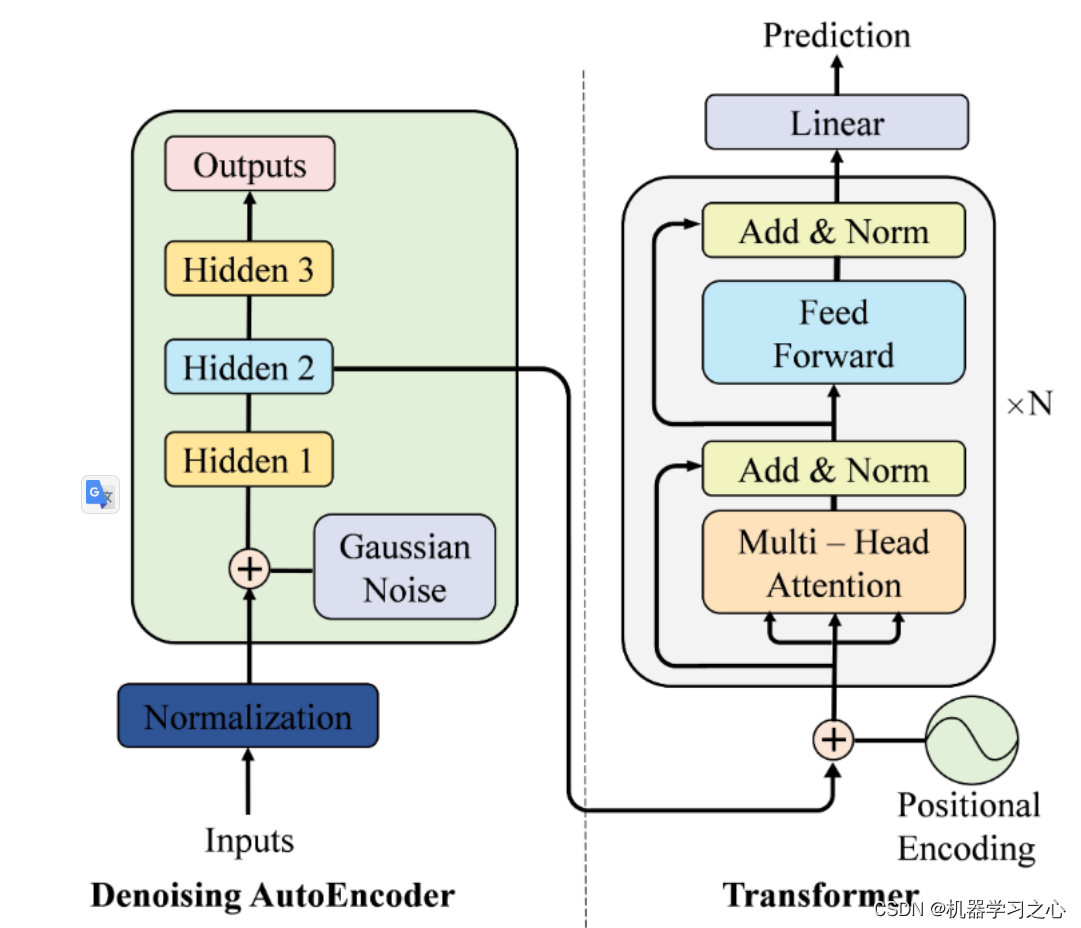
LLMs(大型语言模型)能够记忆并重复它们的训练数据,这可能会带来隐私和版权风险。为了减轻记忆现象,论文作者引入了一种名为"goldfish loss"的微妙修改,在训练过程中,随机抽样的一部分标记被排除在损失计算之外。这些被舍弃的标记不会被模型记忆,从而防止模型完整复制训练集中的一整个标记序列。

论文行了广泛的实验,训练了十亿规模的 Llama-2 模型,包括预训练模型和从头开始训练的模型,并展示出在几乎不影响下游基准测试的情况下,可显著减少记忆现象。
goldfish loss
llm通常使用因果语言建模(CLM)目标进行训练,该目标表示令牌的平均对数概率,以所有先前的令牌为条件。对于包含L个训练标记的序列x = {xi},可以写成:
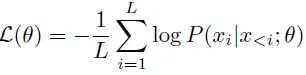
当模型以高置信度正确预测序列{xi}时,该目标最小化,从而使由下一个标记预测训练的模型易于记忆。而goldfish loss仅在令牌的一个子集上计算,因此阻止了模型学习整个令牌序列。选取goldfish mask G∈{0,1}L,定义损失为
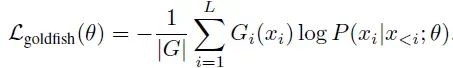
当某些段落在不同文档中多次出现时,我们应该每次掩盖相同的标记,因为不一致的掩盖最终会泄露整个段落。
作者首先在序列中每隔 k 个标记丢弃一个标记,称之为静态掩码。这种静态掩码的方式在上面说的重复段落的情况下失败了,因为掩码对齐于预训练序列长度,而不是文本内容。
所以作者提出了新的局部哈希掩码来解决这个问题。对于确定哈希上下文宽度的正整数 h,如果应用于前 h 个标记的哈希函数 f : |V|^h → R 的输出小于 1/k,则掩盖标记 xi。
i) 处理重复段落的稳健性处理与哈希
当某些段落在不同文档中多次出现时,我们应该每次掩盖相同的标记,因为不一致的掩盖最终会泄露整个段落。
静态掩码基线在这里失败,因为掩码对齐于预训练序列长度,而不是文本内容。
作者们提出了新的局部哈希掩码来解决这个问题。对于确定哈希上下文宽度的正整数 h,如果应用于前 h 个标记的哈希函数 f : |V|^h → R 的输出小于 1/k,则掩盖标记 xi。通过这种策略,掩码在每个位置上仅依赖于前 h 个标记。每当相同的 h 个标记序列出现时,第 (h + 1) 个标记都会以相同的方式被掩盖。
验证记忆保留
因为进行了掩码的遮蔽,所以还需要验证LLM是否会丢掉记忆
作者首先将训练集中的每个测试序列切成长度为n个token的前缀和后缀。以前缀为条件,它们渐进式地生成温度为零的文本。使用两个指标将生成的后缀与真实后缀进行比较:
RougeL score: [Lin, 2004],它量化了最长公共(非连续)子序列的长度。得分为1.0表示记忆力很好。
精确匹配率:衡量与真实文本相比,正确预测的标记的百分比。
作者在仅包含 100 篇英文维基百科文章的数据集上,对 LLaMA-2–7B 模型进行了 100 个周期的训练。
上图为哈利·波特的结果显示,标准训练导致了对 84/100 篇文章的逐字记忆,而使用goldfish loss模型(k = 4)则没有记忆任何一篇文章。
RougeL 指标表明,使用goldfish loss损失训练的模型重复的非连续 n-gram 子序列长度大约是从未见过数据的模型的两倍。
针对于训练数据的重复:
作者预先训练了一个包含 1.1B 个参数和 32k 词汇量的语言模型。构建了来自两个来源数据集:RedPajama 2 的一个子集;混合了来自维基百科语料库的 2000 个目标序列,每个序列长度为 1024 到 2048 个标记。
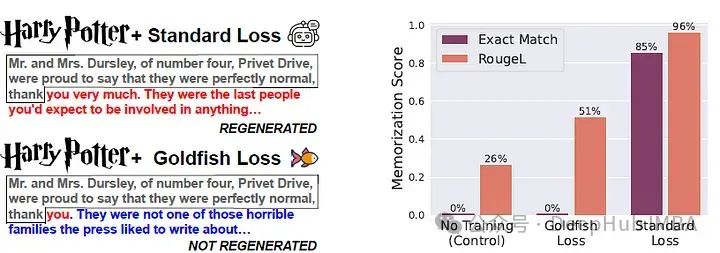
下图绘制了训练后目标文档的 RougeL 记忆化分数分布。
当k = 3和k = 4时,RougeL值的分布与未在目标文档上训练的模型的分布大多重叠。对于较低的k值,可提取的记忆化接近于控制模型,并且标准损失中观察到的精确重复现象得到了有效缓解。
产生分歧的位置:
作者的直觉是,当损失放弃了标记时,模型不会记住这些标记,这会导致模型与基本事实偏离,或者说模型不会产生出与训练数据一模一样的输出
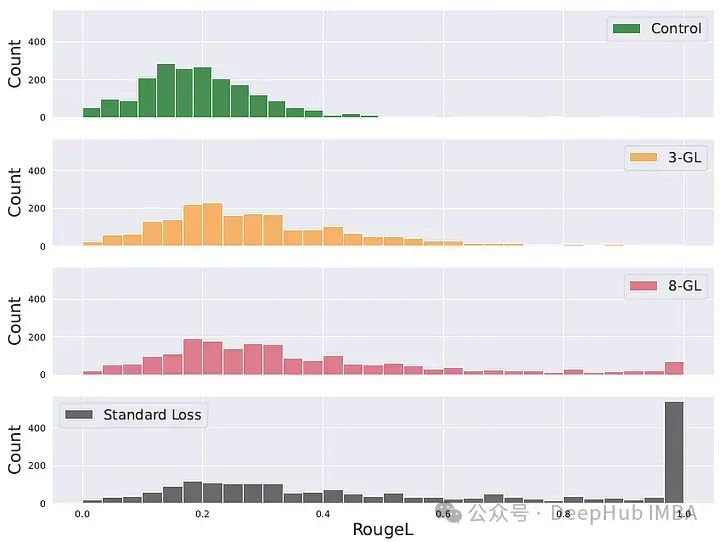
下图显示了 k = 4 的模型在每个序列位置上放弃标记的数量和与事实偏离的标记数量。
下表显示了在放弃标记处发生分歧的可能性。
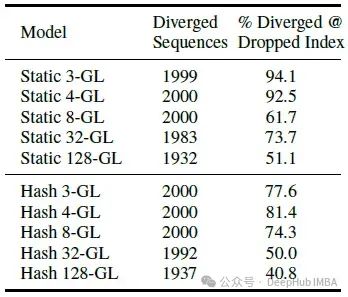
可以看到大多数序列在第一个放弃的标记之后很快就会发生分歧,即使这些序列已经连续训练了 50 次,并且分歧位置几乎与被掩盖的位置完全重合。
对于静态掩码,观察到最大的对应率为 94.1%,随着损失中 k 的增加,这种对应关系逐渐减弱。而基于哈希的方法遵循类似的趋势,但由于此方法按照概率 1/k 丢弃任何标记,大多数分歧发生在第 k 个标记之前。
对模型性能的影响
对评估基准性能的影响
预训练的模型在整体表现上与使用标准因果语言建模(CLM)目标在相同数据上训练的模型表现类似。
下图显示,标准损失模型以及任何goldfish 模型的整体表现之间似乎没有系统性差异
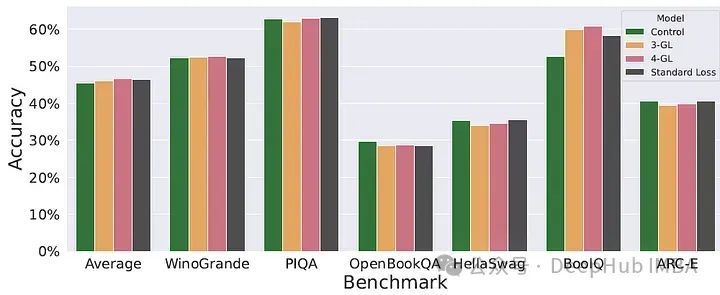
由于goldfish 模型在某种程度上训练过的标记数量较少,可能会想到它们的原始标记预测能力会落后于看过更多数据的标准模型。
为了量化这种影响,作者跟踪模型在训练过程中的验证损失以及每个模型语义连贯性的能力进行对比
损失曲线
下图显示了在 RedpajamaV2 数据的 1200 万个标记上,模型的验证损失曲线,其中一个是使用标准损失训练的模型,另外两个是使用 4-GL 训练的模型。
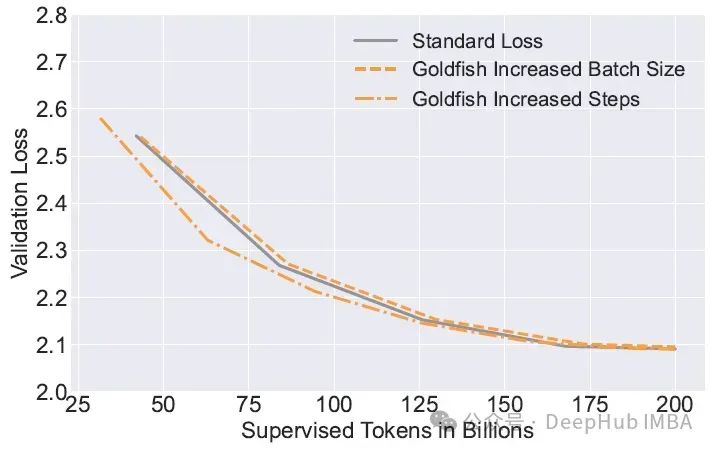
所有模型收敛到几乎相同的验证损失值。随着批量大小的增加,损失遵循相同的验证曲线
Mauve分数:
Mauve分数是一个用来评估生成文本质量的指标,通过衡量生成文本与真实文本之间的多样性和自然性相似性来进行评估。
下图显示了使用模型在Slimpajama数据集样本上的Mauve分数。
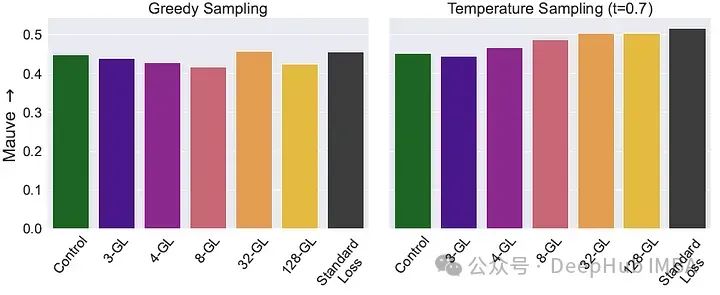
对于贪婪解码,与使用因果语言建模(CLM)质量几乎没有明显下降。
当使用温度为0.7的多项式采样生成时,随着 k 增加和模型看到更多标记,分数略微有上升的趋势。
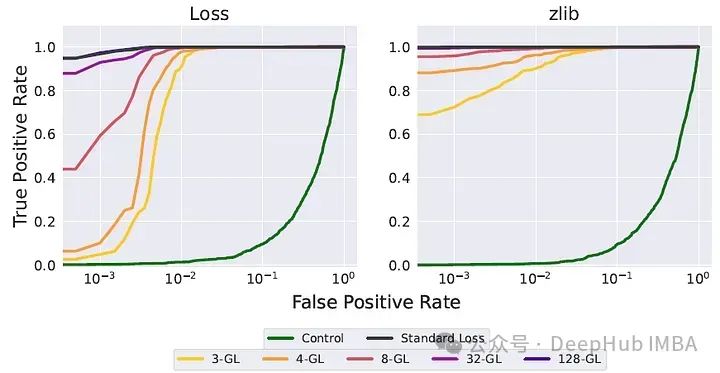
另外攻击者可能会尝试通过搜索序列的多种可能解码来提取数据,而最直接的实施方式是使用Beam Search。下图展示了使用30个束进行激进Beam Search的结果。

当k = 3时,goldfish loss仍然可以抵抗这种攻击,但当k值较大时,Beam Search抽样实现的可提取性增加。
总结
goldfish loss由于其简单性、可扩展性以及对模型性能影响相对较小,可以成为工业环境中的有用工具。不仅可以让模型不重复产生训练数据,这样可以规避训练数据泄露的风险,也可以让模型产生更多样的结果,丰富模型的输出。
但是更大的模型会记住更多的训练数据,因此研究goldfish loss对数十亿或数百亿参数规模模型带来的益处如何扩展,是一个有趣的开放问题。
最后金鱼的记忆只有7秒,虽然7秒记忆已经被研究证实是错的了,但是这个名字起的挺好,比哪些凑字的名字强多了,比如:谷歌的那个Lion (EvoLved SIgn MOmeNtum).
https://avoid.overfit.cn/post/d24d133b5c9e4b109f990783a1661c16


![【决战欧洲杯巅峰】AI模型预测[走地数据]初步准备工作](https://img-blog.csdnimg.cn/direct/1bafa5ef0d6d4c93ab878c4fae7ff6d6.gif#pic_center)