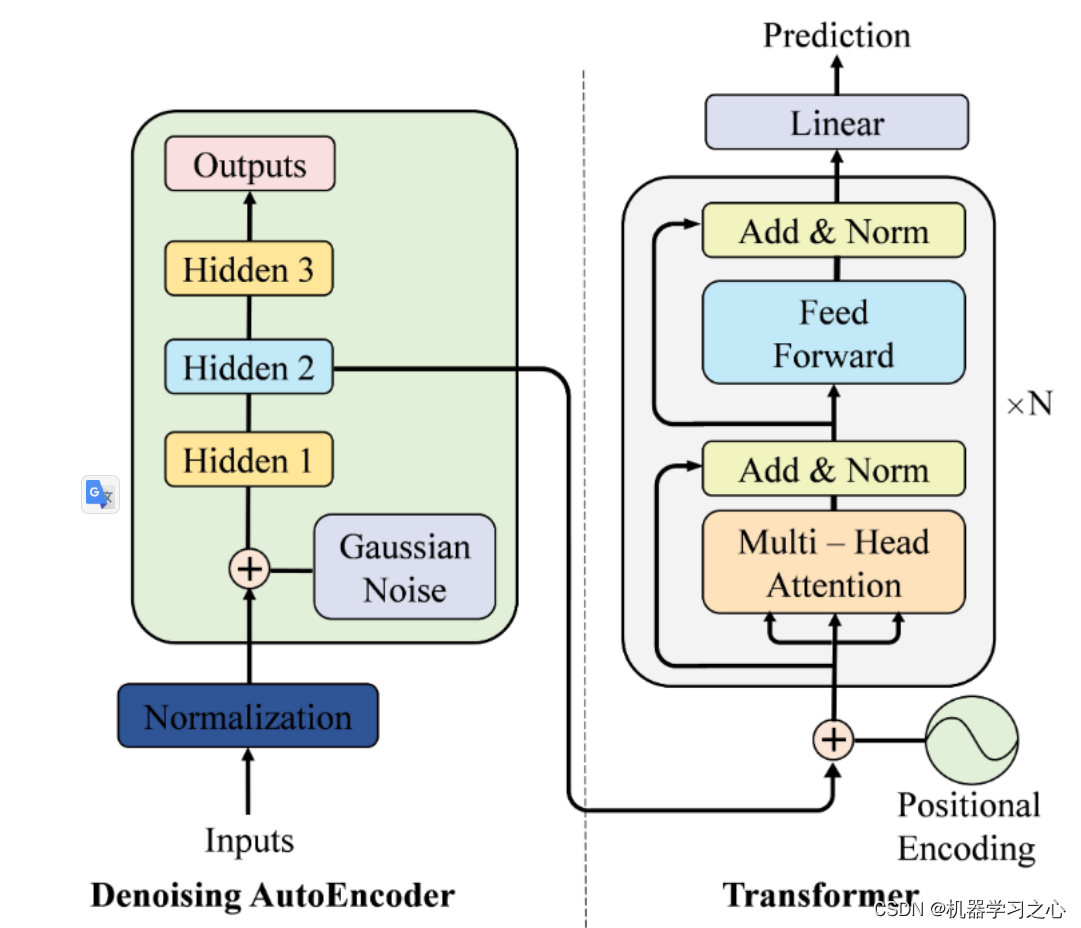
数据准备
首先,我们需要收集一些与欧洲杯比赛相关的历史数据。这些数据可能包括球队的历史战绩、球员的能力评分、比赛场地信息、历史交锋记录等。这些数据可以从公开来源获取,并进行适当的预处理和清洗。
特征提取
接下来,我们需要从收集的数据中提取出有意义的特征,这些特征将作为机器学习模型的输入。特征的选择应该基于它们与比赛结果之间的潜在关系。例如,我们可以选择以下特征:
- 球队历史胜率
- 球员平均能力评分
- 主客场因素
- 最近几场比赛的表现
- 历史交锋记录
构建模型
一旦我们有了特征数据,就可以选择一个合适的机器学习算法来构建预测模型。对于分类问题(如预测比赛胜者),常用的算法包括逻辑回归、决策树、随机森林等。这里,我们以逻辑回归为例。
我们可以使用Python的scikit-learn库来构建和训练模型。首先,我们需要将数据集分为训练集和测试集。然后,我们使用训练集来训练模型,并使用测试集来评估模型的性能。
训练模型
在训练模型时,我们需要选择合适的参数,并通过交叉验证等方法来优化模型性能。这通常涉及到调整模型的超参数,如正则化强度、学习率等。
预测与评估
一旦模型训练完成,我们就可以使用它来预测新的比赛结果。我们可以将新的比赛数据输入到模型中,得到预测的胜者。
为了评估模型的性能,我们可以使用准确率、召回率、F1分数等指标。然而,由于体育赛事结果的复杂性和不确定性,这些指标可能无法完全反映模型的预测能力。
实现过程简单流程
首先,你需要安装必要的库,比如pandas用于数据处理,scikit-learn用于机器学习算法。你可以使用pip来安装:
pip install pandas scikit-learn
接下来是Python代码示例:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 假设我们有一个包含特征和目标变量的数据集(这里仅作为示例)
# 特征可能包括历史交锋记录、球队实力评分、球员状态等
data = {
'feature1': [0.1, 0.3, 0.5, 0.7, 0.9], # 示例特征1
'feature2': [0.2, 0.4, 0.6, 0.8, 1.0], # 示例特征2
'winner': ['teamA', 'teamB', 'teamA', 'teamA', 'teamB'] # 示例目标变量,即比赛胜者
}
# 将数据转换为DataFrame格式
df = pd.DataFrame(data)
# 分离特征和目标变量
X = df[['feature1', 'feature2']]
y = df['winner']
# 将目标变量转换为数值型(在实际应用中,你可能需要更复杂的编码方式)
y = pd.factorize(y)[0]
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 使用模型进行预测
y_pred = model.predict(X_test)
# 计算预测准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 预测新的比赛结果(这里我们假设有新的特征数据)
new_data = [[0.4, 0.5]]
predicted_winner = model.predict(new_data)
print(f"Predicted winner for new data: {predicted_winner}")
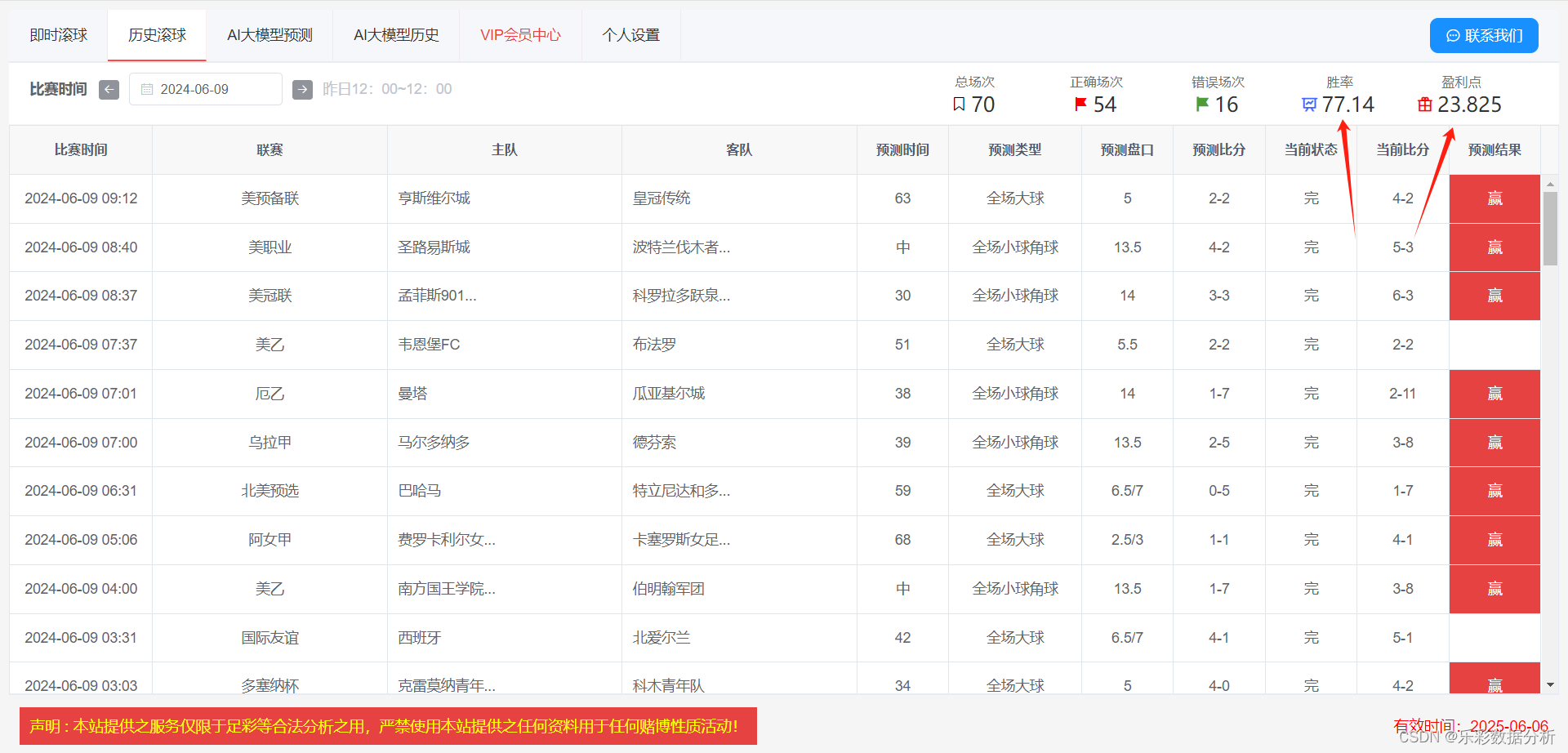
更多预测方法,或者更多交流,请联系作者