第一步:准备数据
5种鸟类数据:self.class_indict = ["苹果派", "猪小排", "果仁蜜饼", "生牛肉薄片", "鞑靼牛肉"]
,总共有5000张图片,每个文件夹单独放一种数据

第二步:搭建模型
本文选择一个Swin-Transformer网络,其原理介绍如下:
Swin-Transformer是2021年微软研究院发表在ICCV上的一篇文章,并且已经获得ICCV 2021 best paper的荣誉称号。虽然Vision Transformer (ViT)在图像分类方面的结果令人鼓舞,但是由于其低分辨率特性映射和复杂度随图像大小的二次增长,其结构不适合作为密集视觉任务或高分辨率输入图像的通过骨干网路。为了最佳的精度和速度的权衡,提出了Swin-Transformer结构。
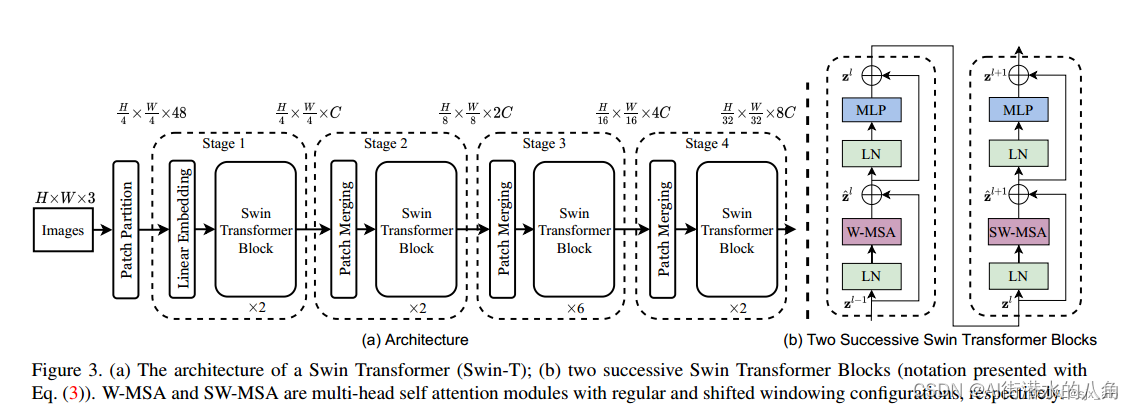
Swin-Transformer的基础流程。
- 输入一张图片 [ H ∗ W ∗ 3 ] [H*W*3] [H∗W∗3]
- 图片经过
Patch Partition层进行图片分割 - 分割后的数据经过
Linear Embedding层进行特征映射 - 将特征映射后的数据输入具有改进的自关注计算的
Transformer块(Swin Transformer块),并与Linear Embedding一起被称为第1阶段。 - 与阶段1不同,阶段2-4在输入模型前需要进行
Patch Merging进行下采样,产生分层表示。 - 最终将经过阶段4的数据经过输出模块(包括一个
LayerNorm层、一个AdaptiveAvgPool1d层和一个全连接层)进行分类。
Swin-Transformer结构
简单看下原论文中给出的关于Swin Transformer(Swin-T)网络的架构图。其中,图(a)表示Swin Transformer的网络结构流程,图(b)表示两阶段的Swin Transformer Block结构。注意:在Swin Transformer中,每个阶段的Swin Transformer Block结构都是2的倍数,因为里面使用的都是两阶段的Swin Transformer Block结构,如下图所示:
第三步:训练代码
1)损失函数为:交叉熵损失函数
2)训练代码:
import os
import argparse
import torch
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from my_dataset import MyDataSet
from model import swin_tiny_patch4_window7_224 as create_model
from utils import read_split_data, train_one_epoch, evaluate
def main(args):
device = torch.device(args.device if torch.cuda.is_available() else "cpu")
if os.path.exists("./weights") is False:
os.makedirs("./weights")
tb_writer = SummaryWriter()
train_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path)
img_size = 224
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(int(img_size * 1.143)),
transforms.CenterCrop(img_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 实例化训练数据集
train_dataset = MyDataSet(images_path=train_images_path,
images_class=train_images_label,
transform=data_transform["train"])
# 实例化验证数据集
val_dataset = MyDataSet(images_path=val_images_path,
images_class=val_images_label,
transform=data_transform["val"])
batch_size = args.batch_size
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
pin_memory=True,
num_workers=nw,
collate_fn=train_dataset.collate_fn)
val_loader = torch.utils.data.DataLoader(val_dataset,
batch_size=batch_size,
shuffle=False,
pin_memory=True,
num_workers=nw,
collate_fn=val_dataset.collate_fn)
model = create_model(num_classes=args.num_classes).to(device)
if args.weights != "":
assert os.path.exists(args.weights), "weights file: '{}' not exist.".format(args.weights)
weights_dict = torch.load(args.weights, map_location=device)["model"]
# 删除有关分类类别的权重
for k in list(weights_dict.keys()):
if "head" in k:
del weights_dict[k]
print(model.load_state_dict(weights_dict, strict=False))
if args.freeze_layers:
for name, para in model.named_parameters():
# 除head外,其他权重全部冻结
if "head" not in name:
para.requires_grad_(False)
else:
print("training {}".format(name))
pg = [p for p in model.parameters() if p.requires_grad]
optimizer = optim.AdamW(pg, lr=args.lr, weight_decay=5E-2)
for epoch in range(args.epochs):
# train
train_loss, train_acc = train_one_epoch(model=model,
optimizer=optimizer,
data_loader=train_loader,
device=device,
epoch=epoch)
# validate
val_loss, val_acc = evaluate(model=model,
data_loader=val_loader,
device=device,
epoch=epoch)
tags = ["train_loss", "train_acc", "val_loss", "val_acc", "learning_rate"]
tb_writer.add_scalar(tags[0], train_loss, epoch)
tb_writer.add_scalar(tags[1], train_acc, epoch)
tb_writer.add_scalar(tags[2], val_loss, epoch)
tb_writer.add_scalar(tags[3], val_acc, epoch)
tb_writer.add_scalar(tags[4], optimizer.param_groups[0]["lr"], epoch)
torch.save(model.state_dict(), "./weights/model-{}.pth".format(epoch))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--num_classes', type=int, default=5)
parser.add_argument('--epochs', type=int, default=100)
parser.add_argument('--batch-size', type=int, default=4)
parser.add_argument('--lr', type=float, default=0.0001)
# 数据集所在根目录
# https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz
parser.add_argument('--data-path', type=str,
default=r"G:\demo\data\foods")
# 预训练权重路径,如果不想载入就设置为空字符
parser.add_argument('--weights', type=str, default='swin_tiny_patch4_window7_224.pth',
help='initial weights path')
# 是否冻结权重
parser.add_argument('--freeze-layers', type=bool, default=False)
parser.add_argument('--device', default='cuda:0', help='device id (i.e. 0 or 0,1 or cpu)')
opt = parser.parse_args()
main(opt)
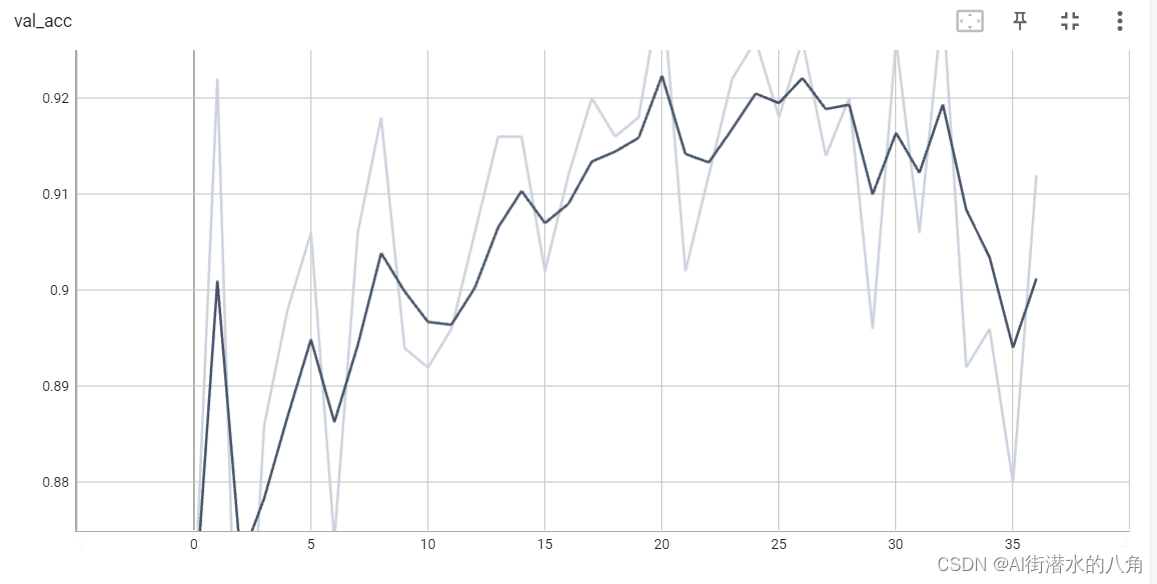
第四步:统计正确率
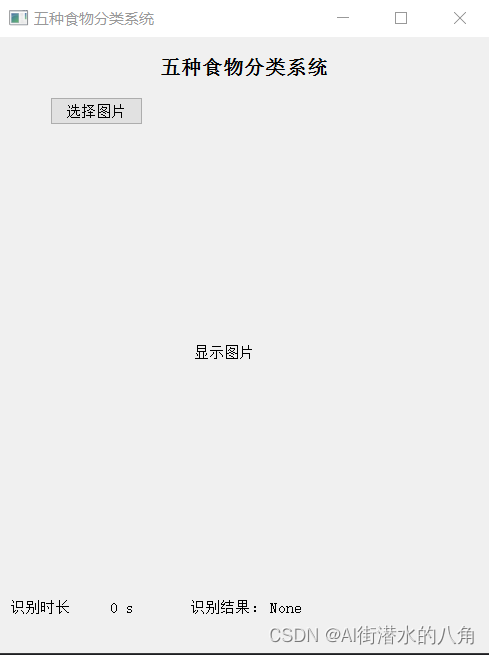
第五步:搭建GUI界面

第六步:整个工程的内容
有训练代码和训练好的模型以及训练过程,提供数据,提供GUI界面代码
代码的下载路径(新窗口打开链接):基于Pytorch框架的深度学习Swin-Transformer神经网络食物分类系统源码

有问题可以私信或者留言,有问必答