1. 编码表
计算机中只有数字(0和1),如果有一个字符串(字符串由字符组成)要存储,在内存中该如何表达这个字符串?
那么所有的字符都必须数字化,也就是一个字符对应一个特定的数字,最终这些数字和字符一一对应,形成了一张表,也就是“编码表”。
目前常见的编码表如下:
- ASCII编码表
- Unicode编码表
- UTF-8编码表(属于Unicode的一种)
1.1 ASCII编码表
ASCII(美国信息交换标准代码)编码表,是最早的字符编码标准,它用7位(后来扩展到8位,也就是一个字节)来表示字符。
最开始主要用来表示拉丁字符,如大小写的英文字母、数字、标点符号和一些控制字符。
但由于它只能表示128个字符,无法涵盖世界上所有语言字符(如汉字),所以后续还延伸出了其他编码表。
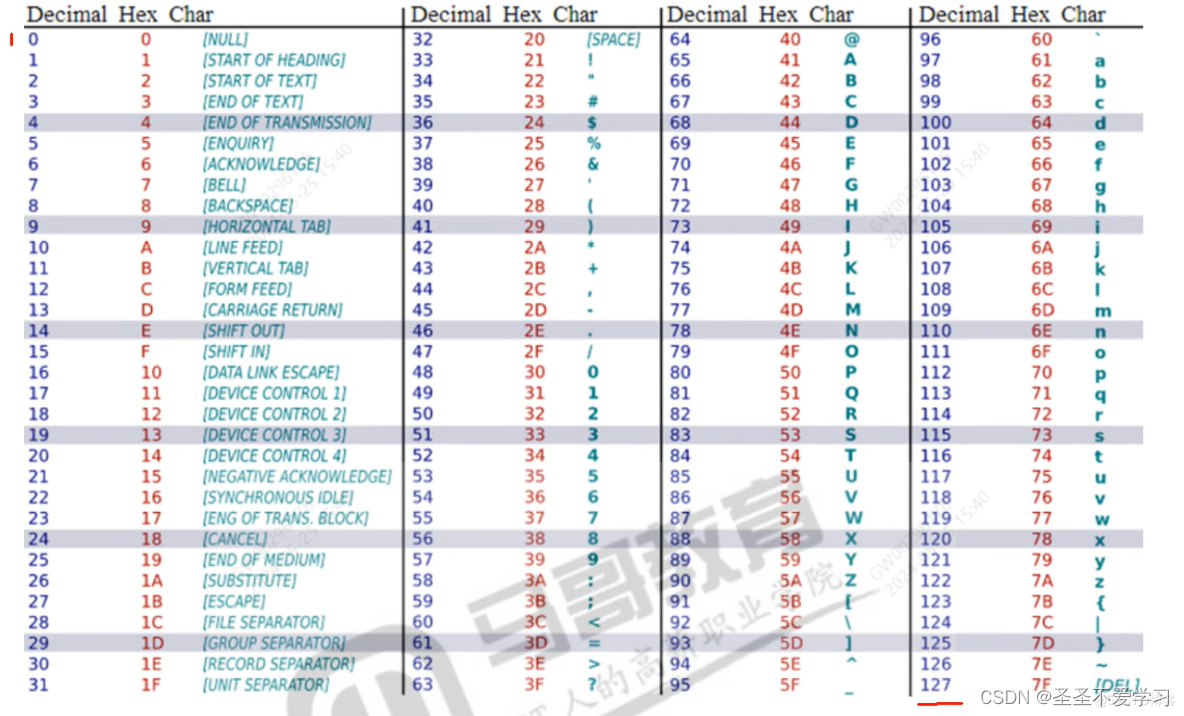
需要熟记的一些特殊字符,注意字符0-9和十进制0-9是有区别的
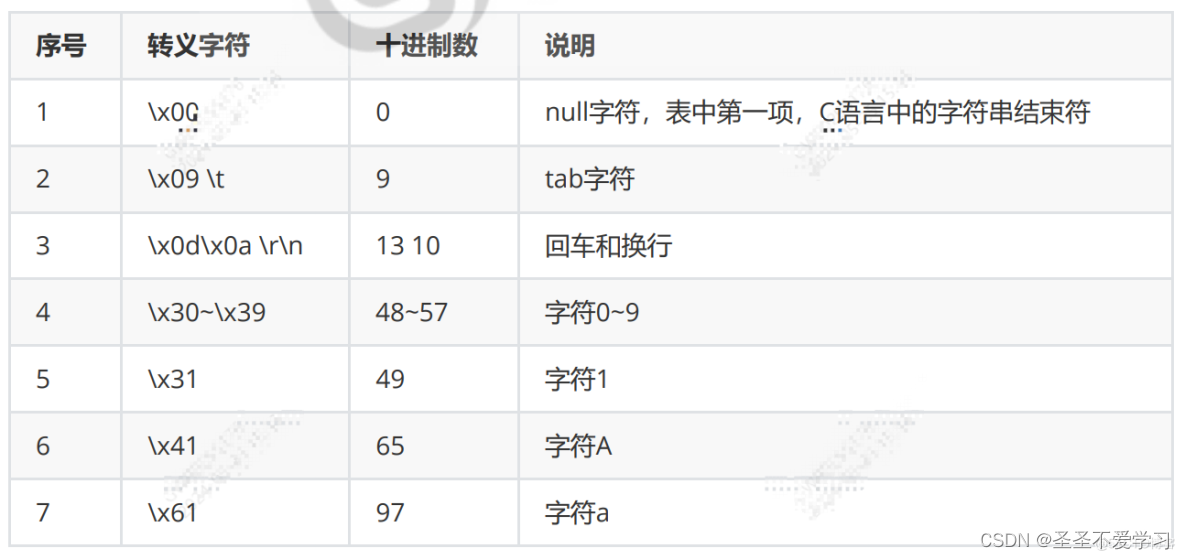
1.2 Unicode编码表
Unicode 是一个旨在解决字符编码混乱问题的国际标准,它为每种语言的每个字符分配了一个唯一的数字码(码点)。
Unicode 包括了ASCII中的所有字符,并扩展了数以万计的其他字符,以支持世界上几乎所有的书写系统。
Unicode 的实现方式有多种,包括UTF-8、UTF-16、UTF-32等,这些实现方式使用不同数量的字节来表示Unicode码点。
1.3 UTF-8编码表
UTF-8是一种可变长度的Unicode字符编码方式,它使用1到4个字节来表示一个字符。
对于ASCII字符,UTF-8的编码方式与ASCII编码表相同,即使用一个字节来表示。
对于其他Unicode字符,UTF-8使用多个字节进行编码,从而能够支持大量的字符,并且兼容ASCII。
UTF-8的优点在于其兼容性(与ASCII兼容)和节约空间(对于大多数常用字符,只需要一个或两个字节)。
2. 字符
本质上来说,计算机中一切都可以表示成一个字节一个字节的,字符串也是多个字节组合而成,就是一个个字节形成的有序序列。
但是对于多字节编码的中文来说,用一个字节描述不了,需要多个字节表示一个字符。
Go在表示一个字符时,如果可以使用ASCII码表,就用一个字节来表达,对应byte类型,byte兼容ASCII码表,别名uint8,占用1个字节。
但是声明变量时,如果不指定数据类型,默认会定义为int32类型,占用4字节。
Go在表示汉字等字符时,要用Unicode码表,对应runte类型,别名int32,占用4个字节。
注意:
单引号括起来的是字符,且一个单引号中只能有一个字符,否则会报错。
双引号括起来的是字符串。
下面代码举例说明:
2.1 字符使用注意事项
注意:字符是不能使用len函数来统计长度的,且一个单引号中只能有一个字符。
len只能用于:字符串、数组、切片、map、channel。
字符默认是rune类型。
package main
import (
"fmt"
)
func main() {
// s := 'ab' 这样是不可以的,一个单引号中只能有一个字符
s := 'a' // 不指定类型,默认为int32(),占用4字节
fmt.Printf("s的类型为:%T", s)
}
==========调试结果==========
s的类型为:int32
如上述代码,最终结果显示’a’为int32,也就是rune类型,为什么呢?
在go中,并不会因为你是一个字符(‘a’)就把你当成byte类型,默认情况下一个字符(‘a’)都是当成了rune类型(int32),占用4字节。
那如何让go把一个字符(‘a’)当成byte类型来处理呢?
如下代码:
package main
import (
"fmt"
)
func main() {
// s := 'a' //这样定义字符,go默认会当成rune(int32)类型处理
var s byte = 'a'
fmt.Printf("s的类型为:%T", s)
}
==========调试结果==========
s的类型为:uint8
定义变量的时候指定类型为byte(uint8)就可以了。
2.2 字符串使用注意事项、
注意:在go中,len取字符串长度时,只取字符对应的字节数。而其他语言中使用len,则是取字符数。
并且,字符串中定义的是汉字时,使用的是utf-8编码表,一个汉字占用3个字节长度。
package main
import (
"fmt"
)
func main() {
s1 := "abc" // 字符串中,大小写字母依然使用acsii码表(utf8兼容ascii)
s2 := "测试" // 汉字占用3字节,使用utf-8编码表。
fmt.Printf("s1的类型:%T s1的长度:%[2]d\ns2的类型:%[3]T s2的长度:%[4]d", s1, len(s1), s2, len(s2))
}
==========调试结果==========
s1的类型:string s1的长度:3
s2的类型:string s2的长度:6
2.3 字符串与字符序列(字符串)转换
如s1 := "abc这个字符串,我们还可以把它当成一个“有序字节序列”来看,因为字符串也是线性数据结构。
类似切片,因为字符串也有header,并且也有底层字节数组这个概念,但是用起来为了不增加学习难度,设计者把它的使用方式和其他语言统一了。
字符串在Go中是不可变的字节序列。对于ASCII字符,每个字符通常占用一个字节。但是,对于UTF-8编码的字符串,非ASCII字符(如中文字符)可能占用多个字节。
2.3.1 ASCII字符串转字节切片
字节切片是字节的序列。当你将一个ASCII编码的字符串转换为字节切片时,你得到的是字符串中每个字节的原始表示。对于中文字符,这意味着每个字符将被转换为多个字节。
注意这种强制类型转换操作,只能用在字符串上,字符是不可以的,因为字符只有一个元素,不算是字符序列。
package main
import (
"fmt"
)
func main() {
s1 := "abc" // 字符串中,大小写字母依然使用acsii码表(utf8兼容ascii)
// 注意这里[]byte(s1),表示强制类型转换。如果是[]byte{},就是声明切片。
t1 := []byte(s1) // 强制类型转换,把字符转成字节切片
fmt.Println(t1)
fmt.Printf("t1的元素:%v|t1的长度:%d|t1的容量:%d", t1, len(t1), cap(t1))
}
==========调试结果==========
[97 98 99] // 97 98 99,对应的就是ascii码表中abc的十进制数值
t1的元素:[97 98 99]|t1的长度:3|t1的容量:8
2.3.2 ASCII字符串转rune(int32)切片
package main
import (
"fmt"
)
func main() {
s1 := "abc"
t2 := []rune(s1)
fmt.Println(t2, len(t2), cap(t2))
}
==========调试结果==========
[97 98 99] 3 4
请问t1 := []byte(s1)和t2 := []rune(s1)有什么区别?
占用内存空间大小不同,byte只占用1字节内存空间,而rune占用4字节,
或者说元素之间的偏移量不同。
如下代码:
package main
import (
"fmt"
)
func main() {
s1 := "abc"
t1 := []byte(s1)
t2 := []rune(s1)
fmt.Printf("t1首个元素内存地址:%d|t1第二个元素内存地址:%d\nt2首个元素内存地址:%d|t2第二个元素内存地址:%d", &t1[0], &t1[1], &t2[0], &t2[1])
}
==========调试结果==========
t1首个元素内存地址:824633819272|t1第二个元素内存地址:824633819273
t2首个元素内存地址:824633819296|t2第二个元素内存地址:824633819300
根据输出结果可以看到:
t1的首个元素和第二个元素相差1字节(偏移1字节)。
t2的首个元素和第二个元素相差4字节(偏移4字节)。
2.3.3 中文字符串转字节切片
字节切片是字节的序列。当你将一个UTF-8编码的字符串转换为字节切片时,你得到的是字符串中每个字节的原始表示(内存中的字节级表示)。
对于中文字符,这意味着每个字符将被转换为多个字节。
package main
import (
"fmt"
)
func main() {
s2 := "测试"
t3 := []byte(s2)
fmt.Println(t3, len(t3), cap(t3))
}
==========调试结果==========
[230 181 139 232 175 149] 6 8
通过结果可以看到:
其实把中文字符串强制转换成字节切片,和使用len(s2)效果相同,因为无论如何,字符串默认都是使用utf-8编码表的,一个元素始终都要占用3个字节长度,所以结果是6个unicode码表值,对应“测试”这俩汉字。
2.3.4 中文字符串转换成rune切片
首先rune切片是int32值的序列,用于表示Unicode码点,注意这里的Unicode和uft-8不要混为一谈。
当你将一个UTF-8编码的字符串转换为rune切片时,Go语言会遍历字符串中每个字符的字节,并根据UTF-8编码规则将它们解码为对应的Unicode码点。每个Unicode码点(无论它在UTF-8编码中占用一个、两个、三个还是四个字节)都会被转换为一个单独的rune值。
对于中文字符来说,由于它们在UTF-8编码中通常占用三个字节,当你将这些字符转换为rune切片时,每个中文字符都会被转换为一个rune值。这个rune值就是该中文字符的Unicode码点,
package main
import (
"fmt"
)
func main() {
s2 := "测试"
t4 := []rune(s2)
fmt.Println(t4, len(t4), cap(t4))
}
==========调试结果==========
[27979 35797] 2 2
通过返回结果也证实了上面的理论,中文字符串转换为rune切片后,每个元素都会被转换成对应的rune值(Unicode码点)。
并且可以直接拿着这个Unicode码点强制转换成string类型(byte也行)。
……省略部分代码
fmt.Println(string(27979)) //把单一的int转换成string
fmt.Println(string([]rune{27979}))//把rune序列转换成utf-8的string序列
fmt.Println(string([]byte{97, 98, 99}))//把rune序列转换成utf-8的string序列
fmt.Println(string([]byte{0x61, '\x62', 0x63}))
==========调试结果==========
测
测
abc
abc
3 . 字符串
特点:
字面常量,只读,不可变(指当前内存空间中)
线性数据结构,可以索引
值类型
utf-8编码
3.1 长度
使用内建函数len,返回字符串占用的字节数。时间复杂度为O(1),字符串是字面常量,定义时已经知道长度,记录下来即可。
之所以字符串的时间复杂度为O(1),是因为在它也有header,里面除了底层数组指针,再就是字符串长度了,所以len就相当于直接读取header中定义好的长度,速度很快。
但字符串的长度是不可变的。
3.2 索引
支持索引,索引范围[0, len(s)-1],但不支持负索引,使用索引只能获取对应字符的字节数。
时间复杂度O(1),使用索引计算该字符相对开头的偏移量即可。
对于顺序表来说,使用索引效率查找效率是最高的。
s[i] 获取索引i处的Ascii编码或UTF-8编码的一个字节。
3.2.1 示例一
package main
import "fmt"
func main() {
s1 := "abc"
// s2 := "测试"
fmt.Println(s1[0], s1[1], s1[2])
}
==========调试结果==========
97 98 99
为什么输出了97 98 99而不是"abc"?
首先这里可以使用索引,说明该对象是个字节序列,字节序列就是[]byte,在字节序列[]byte中按索引一个一个取,拿到的就是对应字符的ascii码。
如果要直接显示对应的字符,可以使用强制类型转换或者遍历。
3.2.2 示例二
package main
import "fmt"
func main() {
// s1 := "abc"
s2 := "测试"
fmt.Println(s2[0], s2[1])
fmt.Println(len(s2))
}
==========调试结果==========
230 181
6
这里依然是当字节序列来处理的。
由于"测试"是中文,使用utf-8编码,一个字符长度为3一共6。
所以使用索引取的话,也只能拿到对应位置上的utf-8编码,3个编码才能表示一个中文字符。
3.3 遍历
3.3.1 方式一:使用索引遍历
该方式就相当于直接对字符串进行字节遍历了,返回的都是字符对应的ascii码和unicode码。
package main
import "fmt"
func main() {
s1 := "abc"
s2 := "测试"
s3 := s1 + s2
for i := 0; i < len(s3); i++ {
fmt.Println(i, s3[i])
}
}
==========调试结果==========
0 97
1 98
2 99
3 230
4 181
5 139
6 232
7 175
8 149
3.3.2 方式二:使用for range
package main
import "fmt"
func main() {
s1 := "abc"
s2 := "测试"
s3 := s1 + s2
for i, v := range s3 {
fmt.Println(i, v, string(v), s3[i])
}
}
==========调试结果==========
0 97 a 97
1 98 b 98
2 99 c 99
3 27979 测 230
6 35797 试 232
for range这种写法,会把中文字符转换成rune类型,每个中文字符都会被转成一个rune值。
这里还要注意一下s3[i],这种相当于是在操作字节序列了,一次只能遍历一个字节,但是中文字符都是3字节的,所以使用索引不能完全取出来对应的中文字符,最后显示就会乱码。
4. strings库
strings提供了很多字符串操作函数,使用方便。
注意:字符串是字面常量,不可修改,很多操作都是返回新的字符串。
4.1 字符串拼接
除了使用+,还能使用Sprintf、Join和Builder。
- Sprintf: 格式化拼接
- Join: 使用间隔符拼接字符串切片
- Builder: 推荐的字符串拼接方式
4.1.1 Sprintf拼接字符串
特别是复杂的字符串拼接,就非常推荐使用这种方式。
package main
import "fmt"
func main() {
s1 := "abc"
s2 := "测试"
// s3 := s1 + s2
s4 := fmt.Sprintf("%s-----%s", s1, s2)
fmt.Println(s4)
}
==========调试结果==========
abc-----测试
4.1.2 Join拼接字符串
语法格式:strings.Join(字符串切片, “分隔符”)
该方式更适合处理已经存在的字符串切片,如果没有字符切片,更适合使用方式一,不然还要像下面一样写一个字符串切片,很麻烦。
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "abc"
s2 := "测试"
s5 := strings.Join([]string{s1, s2}, "***")
fmt.Println(s5)
}
==========调试结果==========
abc***测试
4.1.3 Builder拼接字符串
4.1.3.1 介绍
strings.Builder 是一个可变的数据结构,它允许你逐步构建一个字符串,而不是一次性生成。它内部维护了一个字节切片([]byte),随着添加操作的进行,这个切片会动态扩展。
在编程中,如果需要频繁地拼接字符串,使用 strings.Builder 可以提高效率。它比使用加号(+)拼接字符串更快,因为它避免了在每次拼接时创建新的字符串切片。
使用 strings.Builder 可以带来以下好处:
- 性能提升: 在循环或大量字符串操作中,它比传统的字符串拼接方法更高效。
- 内存使用优化: 减少因字符串拼接导致的内存分配和复制操作。
4.1.3.2 常用方法
Builder携带的很多方法来操作字符串,如下:
- WriteString(s string) (n int, err error): 将字符串s写入到strints.Builder中。
- WriteByte(c byte) (err error): 将单个字节 c 写入到 strings.Builder 中。
- WriteRune(r rune) (n int, err error): 将单个 Unicode 字符 r 写入到 strings.Builder 中。
- Write(p []byte) (n int, err error): 将字节切片 p 写入到 strings.Builder 中。
- Grow(n int): 增加 strings.Builder 的容量至少到 n 字节。如果 n 小于当前容量,此方法不执行任何操作。
- String() string: 返回 strings.Builder 当前内容的字符串表示。此操作不会影响 strings.Builder 的状态,可以继续使用它来追加更多内容。
- Len() int: 返回 strings.Builder 当前内容的长度。
- Cap() int: 返回 strings.Builder 内部字节切片的容量。
- Reset(): 清空 strings.Builder 的内容,使其可以用于新的字符串构建。
- Runes() []rune: 返回包含 strings.Builder 内容的 Unicode 字符切片。
4.1.3.3 示例
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "abc"
s2 := "测试"
// 声明构建器。必须要用var 自定义标识符 来声明。然后这里的builder就能使用strings.Builder中携带的各种方法
var builder strings.Builder
builder.Write([]byte(s1)) // 将"abc"写入构建器
builder.WriteByte('-') // 将'-'写入构建器
builder.WriteString(s2) // 将 "测试" 写入构建器
s6 := builder.String() // 获取最终构建的字符串,并将其存储在变量 s6 中。
fmt.Println(s6)
}
==========调试结果==========
abc-测试
4.1.4 字符串拼接总结
简单拼接字符串常用+、fmt.Sprintf。如果手里正好有字符串的序列,可以考虑Join。如果反复多次拼接,strings.Builder是推荐的方式,减少资源开销,如果涉及到使用for循环拼接,最好也用builder。
4.2 字符串查询
4.2.1 查询方法
- Index:从左至右搜索,返回子串第一次出现的字节索引位置。未找到,返回-1。如果子串为空,则返回0。
- LastIndex:从右至左搜索,返回子串第一次出现的字节索引位置。未找到,返回-1。
- IndexByte、IndexRune与Index类似;LastIndexByte与LastIndex类似。
- IndexAny:从左至右搜索,找到给定的字符集字符串中任意一个字符就返回索引位置。未找到返回-1。
- Contains方法本质上就是Index方法,只不过返回bool值,方便使用bool值时使用。
- LastIndexAny与IndexAny搜索方向相反。
- Count:从左至右搜索子串,返回子串出现的次数。
4.2.2 Index示例
从左至右搜索,返回子串第一次出现的字节索引位置。未找到,返回-1。如果子串为空,则返回0。
语法:func strings.Index(s string, substr string) int
- s:我们定义的字符串或变量
- substr:字符串的子串,就是s中的一部分。
- string:substr的类型。
- int:返回值的类型。
应用场景:
在运维脚本中,strings.Index 可以用于多种场景,包括但不限于:
- 日志分析:在处理日志文件时,可能需要找到特定的错误信息或警告信息的位置。
- 配置文件解析:在配置文件中查找特定的配置项,并获取其值或位置。
- 命令行参数解析:在脚本中解析命令行参数,找到参数的位置并提取其值。
- 数据验证:检查输入数据中是否包含非法字符或特定的分隔符。
- 文本处理:在文本处理中,可能需要根据特定的分隔符来分割字符串或进行其他操作。
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com"
fmt.Println(strings.Index(s1, ".")) // 第一个子串.的索引为3
fmt.Println(strings.Index(s1, "w")) // 第一个子串w的索引为0
fmt.Println(strings.Index(s1, "好")) // 第一个子串“好”的索引为16
fmt.Println(strings.Index(s1, "t")) // 找不到的内容,就返回-1
// 注意下面的两行代码
fmt.Println(strings.Index(s1, "com你好")) // 这里一定要完全匹配"com你好",才会返回c的索引10。
fmt.Println(strings.Index(s1, "你好com")) // 这种就不行,因为找不到"你好com"。
}
==========调试结果==========
3
0
16
-1
10
-1
4.2.2.1 查找是否存在error关键字
package main
import (
"fmt"
"strings"
)
func main() {
a := "Some error message indicating a problem."
b := strings.Index(a, "error")
if b != -1 {
fmt.Println("查找字符存在!")
} else {
fmt.Println("查找不字符存在!")
}
}
==========调试结果==========
查找字符存在!
4.2.3 IndexByte示例
strings.IndexByte 这个函数查找字符串中第一个匹配指定字节(byte)的位置。它将字符串视为一个字节序列,不考虑字符的多字节编码。这意味着它查找的是字节而不是字符,这对于ASCII字符是有效的,但对于Unicode字符可能会返回错误的结果。
字符存在返回对应的索引,不存在返回-1。
注意:IndexByte只适用于查找大小(长度)为1字节的字符。
语法:func strings.IndexByte(s string, c byte) int
- s:我们定义的字符串或变量
- c:大小为1字节的字符,注意是字符。
- int:返回值。
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
fmt.Println(strings.IndexByte(s1, 'a'))
fmt.Println(strings.IndexByte(s1, 0x61))
// 下面这个就不可以,因为中文字符占3个字节长度。
//fmt.Println(strings.IndexRune(s1, '你'))
}
==========调试结果==========
5
5
4.2.4 IndexRune示例
strings.IndexRune 是 Go 语言标准库 strings 包中的一个函数,它用于查找字符串中第一次出现的特定 Unicode 码点(即 “rune”)的索引位置。
在 Go 中,一个 rune 可以是一个 Unicode 码点,可以表示一个中文字符、一个 ASCII 字符或其他任何 Unicode 字符。
语法:func strings.IndexRune(s string, r rune) int
- s:定义的字符串或字符串变量
- r:要查找的字符,注意是字符。
- int:返回值。
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
fmt.Println(strings.IndexRune(s1, 'a'))
fmt.Println(strings.IndexRune(s1, 0x61))
fmt.Println(strings.IndexRune(s1, '你'))
}
==========调试结果==========
5
5
13
4.2.5 IndexAny示例
用于查找字符串中任何给定的 Unicode 码点集合(rune)中的一个字符的索引位置。
和index类似,不同的地方在于index匹配多个字符时,必须要完全精确匹配,indexany的话,字符间可以没有顺序。语法:strings.IndexAny(s string, chars string) int
- s: 我们定义的字符串或变量
- chars:指定要搜索的字符合集
- string:表示这个chars是个字符串类型,也就是说字符合集要用双引号。
- int:这个是最终的返回值类型。
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
// 不管字符合集中有多少个字符,都只会返回从左到右最先匹配到的这一个字符的索引。
fmt.Println(strings.IndexAny(s1, "awb."))
}
==========调试结果==========
0
4.2.6 LastIndex示例
从右至左搜索,返回子串第一次出现的字节索引位置。未找到,返回-1。
func strings.LastIndex(s string, substr string) int
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
fmt.Println(strings.Index(s1, "w.b"))
// 虽然是从右往左找,但不影响最终返回的索引结果
fmt.Println(strings.LastIndex(s1, "w.b"))
}
==========调试结果==========
2
2
4.2.7 Contains示例
匹配字符串中有无包含指定的子串,返回的值为bool。
func strings.Contains(s string, substr string) bool
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
fmt.Println(strings.Contains(s1, "你好"))
fmt.Println(strings.Contains(s1, "好你"))
}
==========调试结果==========
true
false
4.2.8 Count示例
Count计算s中substr的非重叠实例的个数。如果substr为空字符串,Count返回1 + s中Unicode码点的个数。
func strings.Count(s string, substr string) int
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
fmt.Println(strings.Count(s1, "w"))
fmt.Println(strings.Count(s1, "ww"))
fmt.Println(strings.Count(s1, "www"))
fmt.Println(strings.Count(s1, "你好"))
fmt.Println(strings.Count(s1, ""))
}
==========调试结果==========
3
1
1
1
16
4.2.8.1 统计IP出现的次数
package main
import (
"fmt"
"strings"
)
func main() {
a := "192.168.1.1 192.168.1.2 192.168.1.3 192.168.1.1"
b := strings.Split(a, " ")
for _, v := range b {
fmt.Println(v, strings.Count(a, v))
}
}
==========调试结果==========
192.168.1.1 2
192.168.1.2 1
192.168.1.3 1
192.168.1.1 2
4.2.9 字符串查询总结
strings库携带的查询方式,时间复杂度都为O(n),查询效率极低,能不用就不用。如果实在要用,查询次数越少越好。
使用总结:
- 如果需要匹配一个完整的子串,使用 Index。
- 如果需要匹配指定的子串,返回的值为bool的,使用Contains。
- 如果需要匹配单字节字符,如 ASCII 字符,使用 IndexByte。
- 如果需要匹配多字节字符,如中文、日文、韩文等 Unicode 字符,使用 IndexRune。
- 如果需要检查字符串中是否包含一组特定字符中的任何一个,使用 IndexAny。
- 如果需要统计特定子串出现的次数,使用Count。
4.3 大小写转换
ToLower:转换为小写
ToUpper:转换为大写
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
fmt.Println(strings.ToUpper(s1))
}
==========调试结果==========
WWW.BAIDU.COM你好
4.4 前后缀匹配
- HasPrefix:是否以子串开头
语法:func strings.HasPrefix(s string, prefix string) bool
该方式执行效率很高,底层基于索引匹配,时间复杂度O(1)。- HasSuffix:是否以子串结尾。
该方式执行效率很高,底层基于索引匹配,时间复杂度O(1)。两种方式返回结果都为bool。
4.4.1 前缀匹配
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
fmt.Println(strings.HasPrefix(s1, "w."))
fmt.Println(strings.HasPrefix(s1, "www"))
}
==========调试结果==========
false
true
4.4.2 后缀匹配
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.com你好"
fmt.Println(strings.HasSuffix(s1, ".com"))
fmt.Println(strings.HasSuffix(s1, "你好"))
}
==========调试结果==========
false
true
4.5 移除
- TrimSpace:去除字符串两端的空白字符。
- TrimPrefix、TrimSuffix:如果开头或结尾匹配,则去除。否则,返回原字符串的副本。
- TrimLeft:字符串开头的字符如果在字符集中,则全部移除,直到碰到第一个不在字符集中的字符为止。
- TrimRight:字符串结尾的字符如果在字符集中,则全部移除,直到碰到第一个不在字符集中的字符为止。
- Trim:字符串两头的字符如果在字符集中,则全部移除,直到左或右都碰到第一个不在字符集中的字符为止。
4.5.1 移除字符串两端的空白字符(TrimSpace)
常用。
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "\v\r\n\ta b\tc\r\nd\n\t"
fmt.Println(s2)
fmt.Println("-----------------")
fmt.Println(strings.TrimSpace(s2))
}
==========调试结果==========
a b c
d
-----------------
a b c
d
4.5.2 移除最左侧匹配的字符(TrimLeft)
package main
import (
"fmt"
"strings"
)
func main() {
// d之所以没有移除,因为间隔了一个c,c不在指定移除的字符集中。
fmt.Println(strings.TrimLeft("abcdefg", "bad"))
fmt.Println(strings.TrimLeft("abcdefg", "bacd"))
}
==========调试结果==========
cdefg
efg
4.5.3 移除最右侧匹配的字符(TrimRight)
和上面的示例原理相同。
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.TrimRight("abcdefg", "bacdg"))
}
==========调试结果==========
abcdef
4.5.4 移除字符集两端匹配的字符(Trim)
可移除的还包含\v\r\n等特殊字符。
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Trim("abcdefg", "bacdg"))
}
==========调试结果==========
ef
4.5.5 前缀移除(TrimPrefix)
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.com"
fmt.Println(strings.TrimPrefix(s2, "www"))
}
==========调试结果==========
.baidu.com
4.5.6 后缀移除(TrimSuffix)
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.com"
fmt.Println(strings.TrimSuffix(s2, "com"))
}
==========调试结果==========
www.baidu.
4.6 分割
- Split: 按照给定的分割子串去分割,返回切割后的字符串切片。
切割字符串是被切掉的,不会出现在结果中。
没有切到,也会返回一个元素的切片,元素就是被切的字符串。
分割字符串为空串,那么返回将被切割字符串按照每个rune字符分解后转成string存入切片返回。- SplitN: 按照给定的子串和次数去切割。
- SplitAfter: 和Split相似,但是不会把指定的子串切掉,而是在子串后面切一个空格出来。
- SplitAfterN: 和SplitN相似,但是不会把指定的子串切掉,而是用空格来分割元素。
- Cut: 从左到右匹配指定的子串,切掉匹配到的第一个子串,然后停止分割,并默认返回3个元素,2个string,1个bool
4.6.1 Split
split切割后的返回值,一定是一个字符串切片。
最常用的也就是Split。
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.du你好"
// 指定切割符为“du”。返回结果为一个字符串类型的切片
fmt.Printf("%T %[1]v\n", strings.Split(s2, "du"))
// 如果指定的切割符在字符串中不存在,则返回字符串原本的元素
fmt.Printf("%T %[1]v\n", strings.Split(s2, "c")) // 指定一个不存在子串“c”
// 指定子串为""时,会在每个字符中间切一刀。
fmt.Println(strings.Split(s2, ""))
}
==========调试结果==========
[]string [www.bai . 你好] // 注意这里切完后,就是3个元素放在切片中的
[]string [www.baidu.du你好] // 没有东西切的,返回的一个元素放到切片中
[w w w . b a i d u . d u 你 好]
4.6.2 SplitN
SplitN(s, sep string, n int) []string
这里的n要分三种情况:
- n < 0:能切多少次,就切多少次,就相当于是Split,返回字符串切片。
- n == 0:不切,并返回没有元素的字符串切片(空切片),长度为0容量为0。
- n > 0:注意,这里的n,指的是返回元素的个数,而不再是切几次。
4.6.2.1 n < 0
能切多少次,就切多少次,就相当于是Split。
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.du你好"
fmt.Println(strings.SplitN(s2, "du", -1))
}
==========调试结果==========
[www.bai . 你好]
4.6.2.2 n == 0
不切,返回没有元素的字符串切片(空切片),长度为0容量为0。
如果是要生成一个空切片,不要用该方式,生成的切片长度和容量都为0,推荐使用make。
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.du你好"
fmt.Println(strings.SplitN(s2, "du", 0))
}
==========调试结果==========
[]
4.6.2.3 n > 0
注意,这里的n,指的是返回元素的个数,而不再是切几次。
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.du你好"
fmt.Println(strings.SplitN(s2, "du", 1))
fmt.Println(strings.SplitN(s2, "du", 2))
fmt.Println(strings.SplitN(s2, "du", 3))
// 这里按照du切割后,最多也只能返回3个元素
fmt.Println(strings.SplitN(s2, "du", 4))
}
==========调试结果==========
[www.baidu.du你好] // 返回1个元素
[www.bai .du你好] // 返回2个元素
[www.bai . 你好] // 返回3个元素
[www.bai . 你好] // 返回3个元素
4.6.3 SplitAfter
和Split相似,但是不会把指定的子串切掉,而是在子串后面切一个空格出来。
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.du你好"
fmt.Println(strings.SplitAfter(s2, "du"))
}
==========调试结果==========
[www.baidu .du 你好]
4.6.4 SplitAfterN
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.du你好"
fmt.Println(strings.SplitAfterN(s2, "du", 1))
fmt.Println(strings.SplitAfterN(s2, "du", 2))
fmt.Println(strings.SplitAfterN(s2, "du", 3))
fmt.Println(strings.SplitAfterN(s2, "du", 4))
}
==========调试结果==========
[www.baidu.du你好]
[www.baidu .du你好]
[www.baidu .du 你好]
[www.baidu .du 你好]
4.6.5 Cut
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.du你好"
fmt.Println(strings.Cut(s2, "du"))
// 切不到的话,第一个string返回原有的字符串,第二个string就是一个空串
fmt.Println(strings.Cut(s2, "c"))
}
==========调试结果==========
www.bai .du你好 true
www.baidu.du你好 false // false前面其实还有一个空串
4.7 替换
Replace(s, old, new string, n int) string
- n int:表示为替换的次数。
- n < 0,等价ReplaceAll,全部替换
- n == 0,或old == new,就返回s(实际是一个全新的副本)
- n > 0,至多替换n次,如果n超过找到old子串的次数x,也就只能替换x次了
- 未找到替换处,就返回s
package main
import (
"fmt"
"strings"
)
func main() {
s2 := "www.baidu.du你好"
// 匹配到的所有子串都会被替换,类似于ReplaceAll
fmt.Println(strings.Replace(s2, "du", ".com", -1))
// 替换0次,依然返回相同内容的字符串,但这个字符串是一个全新的字符串。
fmt.Println(strings.Replace(s2, "du", ".com", 0))
fmt.Println(strings.Replace(s2, "du", ".com", 1))
fmt.Println(strings.Replace(s2, "du", ".com", 2))
}
==========调试结果==========
www.bai.com..com你好
www.baidu.du你好
www.bai.com.du你好
www.bai.com..com你好
4.8 重复
重复一个字符串为指定的次数。
package main
import (
"fmt"
"strings"
)
func main() {
fmt.Println(strings.Repeat("#", 3))
}
==========调试结果==========
###
4.9 Map
strings.Map 函数用于将一个函数应用于字符串的每个字符上,并返回修改后的字符串。注意Map是一对一的映射,不能减少元素个数。
适合对每个字符都修改的场景。
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.du你好"
fmt.Println(strings.Map(func(r rune) rune {
fmt.Println(r, "$$") // 打印每次遍历的rune值。
return r // 返回最后Map拼接的字符串
}, s1)) // 对s1进行rune遍历,可以理解为for range s1,每次只遍历一个rune值,并返回一个字符,遍历完后Map将每次返回的字符拼接成一个全新的字符串。
}
==========调试结果==========
119 $$
119 $$
119 $$
46 $$
98 $$
97 $$
105 $$
100 $$
117 $$
46 $$
100 $$
117 $$
20320 $$
22909 $$
www.baidu.du你好
package main
import (
"fmt"
"strings"
)
func main() {
s1 := "www.baidu.du你好"
fmt.Println(strings.Map(func(r rune) rune {
fmt.Println(r, "$$")
return 46 //通过修改返回值,可以影响Map处理的最终结果
}, s1))
}
==========调试结果==========
119 $$
119 $$
119 $$
46 $$
98 $$
97 $$
105 $$
100 $$
117 $$
46 $$
100 $$
117 $$
20320 $$
22909 $$
.............. // 全部修改为.了
5. 类型转换
5.1 数值类型转换
1.低精度(整数)向高精度(浮点数)转换可以,高精度向低精度转换会损失精度
2.无符号向有符号转换,最高位是符号位
3.byte和int可以互相转换
4.float和int可以相互转换,float转到int会丢失精度
5.bool和int不能相互转换
6.不同长度的int和float之间可以互相转换
5.1.1 有符号转无符号
package main
import (
"fmt"
)
func main() {
var i int8 = -1
fmt.Println(i)
var j uint8 = uint8(i)// 强制类型转换
fmt.Println(j)
}
==========调试结果==========
-1
255
为什么int8的-1转为uint8后,结果变成了255?
首先有符号的最高位为符号位,当我们把一个有符号通过强制类型转换为无符号时,此时原先的最高位就变成了普通的数字,而不再表示符号。
接着说回-1,这里以一个字节为例,-1的int8的表示为0xff,怎么来的呢?这里就不得不说下原码、反码、补码了(正整数的原码、反码、补码都相同,负数不同)。
- 原码:
一字节的-1原码为1000 0001。负数的原码在计算机中是不用的,只是单纯给人看的。- 反码:
符号位不变,其他位全部取反。
如一字节的-1的反码为1111 1110。- 补码
符号位不变,其他全部取反并且最低位+1。
如一字节的-1的补码为1111 1111。
计算机内部使用。最终二进制0b1111 1111对应16进制0xff,对应10进制呢?
主要看我们赋予的数据类型,就像本示例中转成uint8后,就对应10进制的255。
那如果是int8呢?
补码1111 1111(补码做补码为原码),最高位符号位1表示负号依然不变,其他的取反,最低位+1,结果就是1000 0001,对应10进制就是-1。
总结:有符号和无符号的强制类型转换是有风险的,转换前自己必须计算出转换后的结果,否则就会异或-1为啥变成了255。
5.1.2 folat转int
无类型的浮点是不可以直接转成int的,只能转成float32或64。
除非定义时明确指定数据类型为float或者短格式声明,由系统自动推断float类型,但float转为int后,会直接丢弃小数部分。
package main
import (
"fmt"
)
func main() {
// fmt.Println(int(3.14))
fmt.Println(float64(3.14))
}
==========调试结果==========
3.14
package main
import (
"fmt"
)
func main() {
var a = 3.14
fmt.Println(int(a))
}
==========调试结果==========
3
5.1.3 字符结合无类型int
声明变量时,如果不指定字符的数据类型,默认会定义为int32类型,占用4字节。
package main
import (
"fmt"
)
func main() {
b := 'a'
c := b + 1//无类型int是可以和int32运算的,系统会针对无类型int做隐式类型转换
fmt.Printf("%T\n", b)
fmt.Println(b)
fmt.Println(c)
}
==========调试结果==========
int32
97
98
看个错误的
package main
import (
"fmt"
)
func main() {
b := 'a'
c := 1
//这样是不可以的,前面说过,不同数据类型不可以相互运算。
//d := b + c // 此处的b为rune类型,c为自适应int。不能相互运算。
d := int(b) + c // 解决办法就是转换为相同类型就可以了
}
5.2 类型别名和类型定义
package main
import "fmt"
func main() {
var a byte = 'C'
var b uint8 = 49
fmt.Println(a, b, a+b)
}
思考一个问题?a和b能相加吗?
答案是肯定的,源码中定义了 type byte = uint8 ,byte是uint8的别名。
补充一点,一字节的C,Go会拿着它对应的acsii码和b相加。再看下面一段代码:
5.2.1 类型定义
package main
import "fmt"
func main() {
type myByte byte // 注意这种是自定义类型,不是定义别名
var a byte = 'C'
var c myByte = 50
// 上面的myByte虽然和byte相同,但实际上GO是把它们当成了不同类型,所以不能相互运算
fmt.Println(a, c, a + c) // 这里a + c就报错了,因为go认为myByte和byte不是同一种数据类型
fmt.Println(a, c, a + byte(c))//强制类型转换后是可以的
}
5.2.2 别名定义
package main
import "fmt"
func main() {
// 定义byte的别名为myByte
type myByte = byte
var a byte = 'C'
var c myByte = 50
fmt.Println(a, c, a+c)
}
==========调试结果==========
67 50 117
5.3 字符串转换
转换过程中应该基于nil做判断,下面只是一个基本的演示,所以没加。
5.3.1 将string转为int
5.3.1.1 strconv.Atoi
func Atoi(s string) (int, error)
- s:要转换的字符串,它应该包含一个可解析的整数,如ascii码。
- int:s转换后的int类型整数
- error:有错误显示错误,没错误显示<nil>
package main
import (
"fmt"
"strconv"
)
func main() {
s1 := "127"
fmt.Println(strconv.Atoi(s1))
// 这里就是一个错误的转换,下面直接报错了
fmt.Println(strconv.Atoi("xxx"))
}
==========调试结果==========
127 <nil>
0 strconv.Atoi: parsing "xxx": invalid syntax
5.3.1.2 strconv.ParseInt
strconv.ParseInt 是 Go 语言标准库中 strconv 包提供的一个函数,用于将字符串转换为整数。
语法:ParseInt(s string, base int, bitSize int) (i int64, err error)
- s:我们需要处理的字符串。
- base:是字符串表示的数字的基数,比如10表示十进制,16表示十六进制。
- bitSize:是结果整数的大小,比如0、4、8、16、32、64位等。注意单位是位(bit),如果配置为0,默系统会默认配置为64。
- i:返回值,也就是转换后的整数,int64类型。
- err:有错误显示错误,无错误显示nil。
package main
import (
"fmt"
"strconv"
)
func main() {
s1 := "127"
// s1转换为10进制,占8位(1个字节)
result, err := strconv.ParseInt(s1, 10, 8)
if err != nil {
fmt.Println("类型转换错误:", err)
return
}
fmt.Printf("转换后的类型:%T|转换后的结果:%[1]v", result)
}
==========调试结果==========
转换后的类型:int64|转换后的结果:127
再看另一个例子
package main
import (
"fmt"
"strconv"
)
func main() {
s1 := "127"
result, err := strconv.ParseInt(s1, 16, 64)//s1转为16进制,占64位
if err != nil {
fmt.Println("类型转换错误:", err)
return
}
fmt.Printf("转换后的类型:%T|转换后的结果:%[1]v", result)
}
==========调试结果==========
转换后的类型:int64|转换后的结果:295
注意看这段代码:strconv.ParseInt(s1, 16, 64),实际上这里是把s1当成了16进制来处理,它占用64位,也就是0x127。
0x127转为10进制就是295。
5.3.2 将string转为float
5.3.2.1 strconv.ParseFloat
strconv.ParseFloat 是 Go 语言标准库中 strconv 包提供的一个函数,用于将字符串转换为浮点数。
语法:func strconv.ParseFloat(s string, bitSize int) (float64, error)
- s:要转换的字符串
- bitSize: 指定了结果浮点数的位数,通常是 32 或 64,分别对应 float32 和 float64。
- float64:函数返回值类型。
- error:有错误显示错误,无错误显示nil
package main
import (
"fmt"
"strconv"
)
func main() {
s2 := "3.14516"
fmt.Println(strconv.ParseFloat(s2, 32))
}
==========调试结果==========
3.145159959793091 <nil>
为啥结果和最初定义的不同?
浮点数字符串转换为浮点数后,它只能无限接近这个数,并不能完全一模一样。
5.3.3 string转为bool
ParseBool(str string) (bool, error)
- str:要转换的字符串,注意,要转的字符串只能是1, t, T, TRUE, true, True, 0, f, F, FALSE, false, False。
- bool:最终结果为bool类型。
- error:成功显示nil,失败显示错误。
package main
import (
"fmt"
"strconv"
"strings"
)
func main() {
t, ok := strconv.ParseBool("1")
if ok != nil {
fmt.Println("转换错误:", ok)
}
fmt.Println(t)
fmt.Println(strings.Repeat("-", 20))
t, ok = strconv.ParseBool("2")
if ok != nil {
fmt.Println("转换错误:", ok)
}
fmt.Println(t)
}
==========调试结果==========
true
--------------------
转换错误: strconv.ParseBool: parsing "2": invalid syntax
false