为了减少计算复杂度,通过借鉴生物神经网络的一些机制,我们引入了局部连接、权重共享以及汇聚操作来简化神经网络结构。神经网络中可以存储的信息量称为网络容量。一般来讲,利用一组神经元来存储信息的容量和神经元的数量以及网络的复杂度成正比。如果要存储越多的信息,神经元数量就要越多或者网络要越复杂,进而导致神经网络的参数成倍的增加。我们人脑的生物神经网络同样存在着容量问题,人脑中的工作记忆大概只有几秒钟的时间,类似于循环神经网络中的隐状态。人脑在有限的资源下,并不能同时处理这些过载的信息。大脑就是通过两个重要机制:注意力和记忆机制,来解决信息过载问题的。
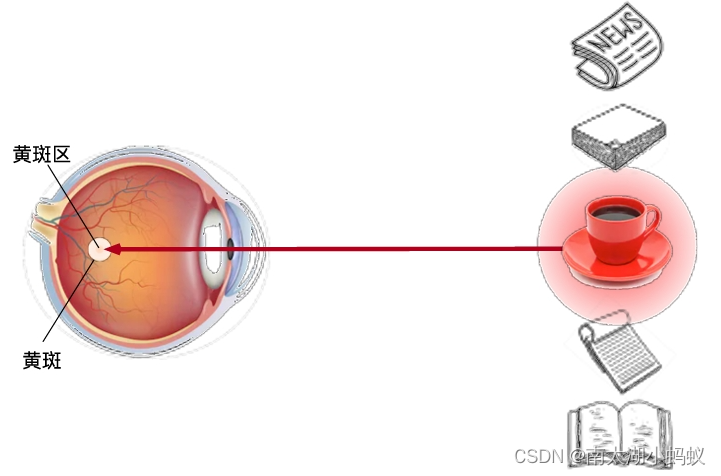
基于显著性注意力
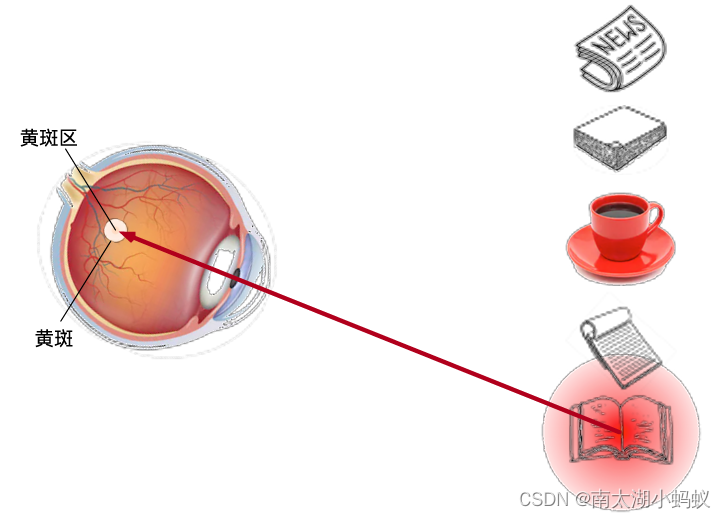
聚焦式注意力
注意力一般分为两种:一种是自上而下的有意识的注意力,称为聚焦式(focus)注意力,如上图,我们如果主观上要去看一本书,那在当下的场景中,可能会直接去搜寻书籍;另一种是自下而上的无意识的注意力,称为基于显著性的注意力,如上图,如果我们没有任何目的,随意的一看,可能最容易吸引我们注意的就是红色的茶杯。
在神经网络中,我们可以把最大池化(max pooling),门控等机制看作是自下而上的基于显著性的注意力机制,因为这些操作并没有主动去搜索信息。而我们这里讨论的注意力机制可以看作是一种自上而下的聚焦式注意力机制。用X=[x1,x2,...,xn]表示n个输入信息,为了节省计算资源,不需要将所有的n个输入信息都输入到神经网络进行计算,只需要从X中选择一些和任务相关的信息输入给神经网络。注意力机制的计算可以分为两步:一是在所有输入信息上计算注意力分布,二是根据注意力分布来计算输入信息的加权平均。
注意力机制其实可以理解为求解相似度。这点网上有一个视频讲解的很好。
假设现在有一个从腰围到体重的映射,我们成腰围为key,体重为value。对应效果如下:
key:51——》value:40
key:56——》value:43
key:58——》value:48
那么,如果现在有一个query=57,value该怎么求?
一个最自然的想法就是,57是56和58的平均数,所以对应的value也应该是43和48的平均数,f(q)=(v2+v3)/2,这里因为57距离56和58非常近,我们会非常“注意”它们,所以我们分给56和58的注意力权重为0.5,相当于我们假设这里面存在一个映射,也就是函数f(q),假设用α(q,ki)来表示q与对应ki的注意力权重,那么value的预测值展开来就是f(q)=α(q,k1)v1 + α(q,k2)v2 + α(q,k3)v3,这里我们认为α(q,k1)=0,因为距离较远,所以我们没有考虑,而α(q,k2)和α(q,k3)都为0.5,这就得到了我的结果。
不过这种算法没有考虑到其它数据可能带来的影响,实际的情况可能远比求平均数复杂。所以,更一般的,我们应该来计算注意力权重α(q,ki),关键是怎么计算。一般来说,我们会设置一个注意力打分函数,然后对注意力打分函数的结果来进行softmax操作,得到注意力权重,用公式表示就是:
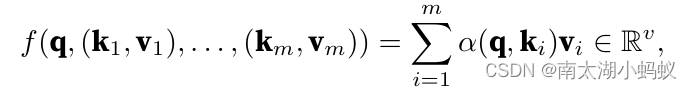
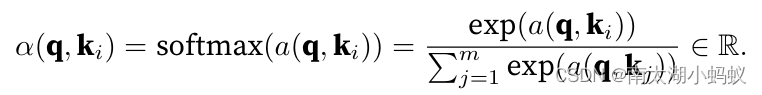
这里面的a(q,ki)就是注意力打分函数,一般有加性模型、点积模型、缩放点击模型和双线性模型,他们的公式如下:
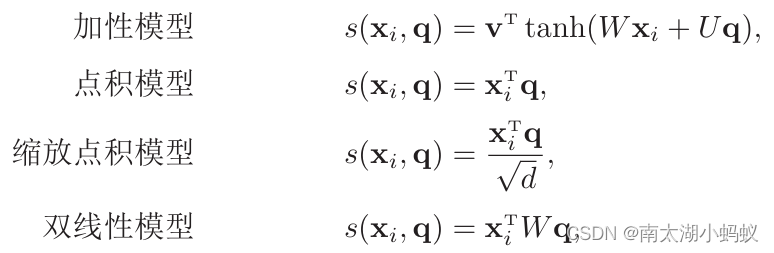
实际应用中,我们一般选择缩放点击模型来作为打分函数。其中W,U,v为可学习的参数,d为输入信息的维度。注意力分布αi可以解释为在给定任务相关的查询q时,第i个信息受关注的程度。
如果q,k,v是多维的也是一样的,我们可以用矩阵来表示,并以Q,K,V来命名查询和键值对,采用缩放点积模型,公式如下:
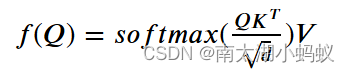
当Q,K,V是同一个矩阵时,这就是自注意力机制了,Q=K=V=X,写成公式就是:
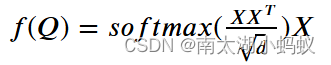
这里面有三个可以训练的参数矩阵WQ,WK,WV,写成公式就是:
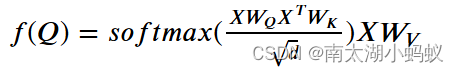
这就是自注意力机制的公式。
李沐的《动手学深度学习》中有个例子比较好的说明了注意力机制作用,就是Nadaraya-Waston回归,下面我们也来实现一下:
给定成对的输入输出数据集{(x1,y1),...,(xn,yn)},学习一个函数f来预测任意新输入x的输出y_hat = f(x)
假设真实函数是:
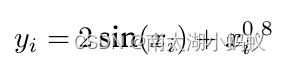
我们给数据加一个随机扰动,生成训练数据:
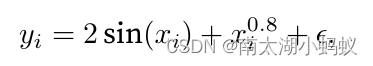
n_train = 50 # 训练样本数
x_train, _ = torch.sort(torch.rand(n_train)*5) # 排序后的训练样本,生成50个[0,1)的数据再乘以5,等于生成50个[0,5)之间的数据
# 定义一个真实函数
def f(x):
return 2*torch.sin(x)+x**0.8
y_train = f(x_train) + torch.normal(0.0,0.5,(n_train,)) # 训练样本的输出,加上了一个扰动
x_test = torch.arange(0,5,0.1) # 测试样本
y_truth = f(x_test) # 测试样本的真实输出定义一个画图函数:
def plot_kernel_reg(y_hat):
plt.plot(x_test, y_truth)
plt.plot(x_test, y_hat)
plt.xlabel('x')
plt.ylabel('y')
plt.legend(['Truth', 'Pred'])
plt.plot(x_train, y_train, 'o', alpha=0.5)
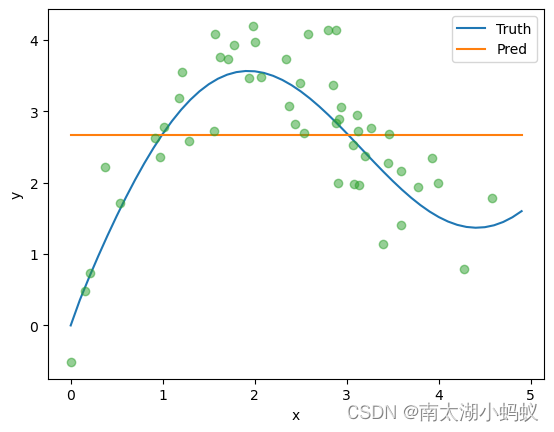
plt.show()1.直接取训练数据的平均值来预测:
y_hat = torch.repeat_interleave(y_train.mean(), n_test)
plot_kernel_reg(y_hat)
plt.show()结果肯定是不理想的,就是一条直线。
2.非参数注意力:
非参数注意力其实就是不需要训练的注意力计算,直接训练数据和测试数据直接的差距来计算注意力。
#每⼀⾏都包含着相同的测试输⼊(例如:同样的查询)
x_repeat =x_test.repeat_interleave(n_train).reshape((-1,n_train))
print(x_repeat)
print(x_repeat.shape)
# 输出
tensor([[0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],
[0.1000, 0.1000, 0.1000, ..., 0.1000, 0.1000, 0.1000],
[0.2000, 0.2000, 0.2000, ..., 0.2000, 0.2000, 0.2000],
...,
[4.7000, 4.7000, 4.7000, ..., 4.7000, 4.7000, 4.7000],
[4.8000, 4.8000, 4.8000, ..., 4.8000, 4.8000, 4.8000],
[4.9000, 4.9000, 4.9000, ..., 4.9000, 4.9000, 4.9000]])
torch.Size([50, 50])x_repeat就是把x_test复制了50份,从一个50个数据的1维数组变成了50X50的矩阵。把x_repeat看成是query,x_train看成是key,y_train看出是value,计算注意力权重,根据注意力权重来计算输出。
#x_train包含着键。attention_weights的形状:(n_test,n_train),
#每⼀⾏都包含着要在给定的每个查询的值(y_train)之间分配的注意⼒权重
attention_weights = nn.functional.softmax(-(x_repeat-x_train)**2 / 2, dim=1)
#y_hat的每个元素都是值的加权平均值,其中的权重是注意力权重
y_hat = torch.matmul(attention_weights, y_train)
plot_kernel_reg(y_hat)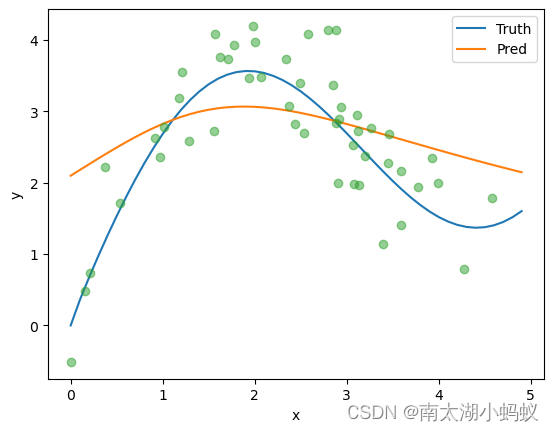
3.带参数的注意力机制
这就是正常的注意力机制了。
# X_tile的形状:(n_train,n_train),每⼀⾏都包含着相同的训练输⼊
x_tile = x_train.repeat((n_train,1))
# Y_tile的形状:(n_train,n_train),每⼀⾏都包含着相同的训练输出
y_tile = y_train.repeat((n_train,1))
# keys的形状:('n_train','n_train'-1)
keys = x_tile[(1-torch.eye(n_train)).type(torch.bool)].reshape((n_train,-1))
# values的形状:('n_train','n_train'-1)
values = y_tile[(1-torch.eye(n_train)).type(torch.bool)].reshape((n_train,-1))这里有个小技巧,用来生成keys和values。
print((1-torch.eye(n_train)).type(torch.bool).shape) # 50X50的矩阵,包含True和False,每一行有49个True和1个False
x_tile[(1-torch.eye(n_train)).type(torch.bool)].shape # 用这个值作为索引后,就得到50行49列的数据,因为每一行都有一个值是False
# 输出:
torch.Size([50, 50])
torch.Size([2450])这里torch.eye(n_train)生成的是50X50的单位矩阵,1-torch.eye(n_train)生成的是50X50的矩阵:
tensor([[0., 1., 1., ..., 1., 1., 1.],
[1., 0., 1., ..., 1., 1., 1.],
[1., 1., 0., ..., 1., 1., 1.],
...,
[1., 1., 1., ..., 0., 1., 1.],
[1., 1., 1., ..., 1., 0., 1.],
[1., 1., 1., ..., 1., 1., 0.]])(1-torch.eye(n_train)).type(torch.bool)生成的是50X50的布尔矩阵:
tensor([[False, True, True, ..., True, True, True],
[ True, False, True, ..., True, True, True],
[ True, True, False, ..., True, True, True],
...,
[ True, True, True, ..., False, True, True],
[ True, True, True, ..., True, False, True],
[ True, True, True, ..., True, True, False]])x_tile[(1-torch.eye(n_train)).type(torch.bool)],代表的是根据bool矩阵取出tensor中对应位置元素,如果是False的元素就不取,取出对应位置为True的元素。
所以keys和values的形状就是[50,49]。下面定义Nadaraya-Waston模型:
class NWKernelRegression(nn.Module):
def __init__(self,**kwargs):
super().__init__(**kwargs)
self.w = nn.Parameter(torch.rand((1,), requires_grad=True)) # 初始化权重参数
def forward(self, queries, keys, values):
# queries和attenion_weights的形状为(查询个数,“键值对”个数)
queries = queries.repeat_interleave(keys.shape[1]).reshape((-1, keys.shape[1]))
self.attention_weights = nn.functional.softmax(-((queries-keys)*self.w)**2/2,dim=1)
return torch.bmm(self.attention_weights.unsqueeze(1), values.unsqueeze(-1)).reshape(-1)模型训练:
net = NWKernelRegression()
loss = nn.MSELoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=0.5)
for epoch in range(5):
trainer.zero_grad()
l = loss(net(x_train, keys, values), y_train)
l.sum().backward()
trainer.step()
print(f'epoch {epoch+1}, loss {float(l.sum()):.6f}')
# 输出:
epoch 1, loss 27.291159
epoch 2, loss 6.903591
epoch 3, loss 6.815420
epoch 4, loss 6.729923
epoch 5, loss 6.646971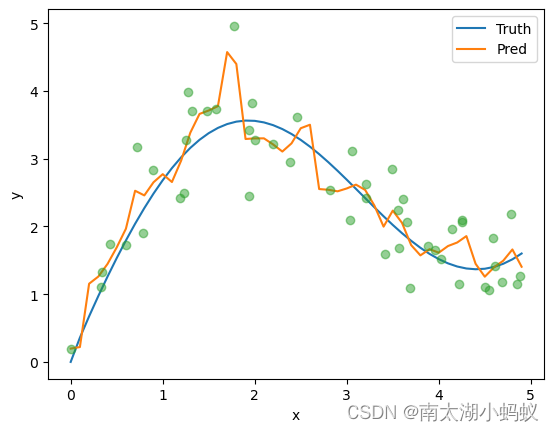
可以看到,预测结果已经越来越接近真实数据了,只是曲线还不是很平滑。其实我还尝试了一下用缩放点积模型来构建模型,但是效果并不好,下一篇来看一下多头注意力和自注意力机制。