Meta 在今年 4 月开源了 Llama 3 大型语言模型,这是 Meta,也是整个行业迄今为止功能最强大的开源 LLM。
那么 Meta 是如何训练 Llama 3 大型语言模型的,又在训练过程中遇到了什么问题,提出了什么新的解决方案呢?近日,Meta 在官网放出了一篇名为「How Meta trains large language models at scale」的文章,详细介绍了其中的重点和难点,让我们一起来看看,Llama 3 到底是如何炼成的。
 图源:Meta
图源:Meta
Meta 此前曾为 Facebook 和 Instagram 的推荐系统训练过各种 AI 模型,虽然这些模型会摄取大量信息以做出准确的推荐,但这些模型规模仍然较小,需要的 GPU 数量相对较少,而不像 Llama 系列等需要大量数据和 GPU 的大规模语言模型。
 图源:Meta
图源:Meta
随着生成式 AI(GenAI)的出现,Meta 发现他们日常的工作任务还是那些,但工作量却出现了陡然增大。大规模的 GenAI 意味着他们需要重新思考软件、硬件和网络基础设施,才能更好地将他们结合在一起。
大规模模型训练的挑战

图源:Meta
为了训练大规模语言模型,Meta 日常作业中 GPU 的数量出现大幅增长,但这同样也让硬件出现故障的可能性一同增加了。此外,所有这些 GPU 仍然需要在同一高速网络上进行通信才能实现最佳的性能。为此 Meta 需要克服四个挑战:
-
- 硬件可靠性:确保硬件可靠性非常重要,Meta 需要尽量减少硬件故障中断训练任务的可能性。这涉及严格的测试和质量控制措施,以及检测和解决问题的自动化流程。
- 快速故障恢复:尽管 Meta 尽了最大努力,但硬件故障仍然会时不时发生。当故障发生时,Meta 制定了能够快速恢复的流程,这涉及减少重新调度开销和快速重新初始化。
- 高效保存训练状态:在发生故障时,Meta 已经能够实现从中断的地方继续进行训练的一套方法。其中涉及需要定期检查训练状态,并高效地存储和检索训练数据。
- GPU 之间的连接最优化:大规模模型训练涉及在 GPU 之间同步传输大量数据。GPU 子集之间的数据交换缓慢会累积并拖慢整个任务。解决这个问题需要一个强大且高速的网络基础设施以及高效的数据传输协议和算法。
在基础设施堆栈中进行创新
由于大规模生成式 AI(GenAI)的需求日益增长,为了将训练效果最大化,Meta 还需要改进其基础设施堆栈中的每一层。
训练软件
Meta 允许研究人员使用 PyTorch 和其他新的开源开发工具,让技术能够快速从研究进入到生产环境中。这包括开发用于高效大规模训练的新算法和技术,并将新的软件工具和框架集成到 Meta 的基础设施中。
调度
高效的调度有助于确保资源得到最佳利用,Meta 开发了一套极其复杂的算法,可以根据不同任务的需求分配资源,并进行动态调度以适应不断变化的工作负载。
硬件
训练大型语言模型需要高性能硬件来处理其中的计算需求。除了大小和规模之外,许多硬件配置和属性需要为生成式人工智能进行最佳优化。鉴于硬件开发时间通常较长,Meta 不得不自行改造现有硬件,为此他们探索了包括功率、HBM 容量和速度以及 I/O 在内的各种维度。
Meta 还通过修改使用 NVIDIA H100 GPU 开发的 Grand Teton 平台,将 GPU 的 TDP 增加到 700W,并将 GPU 移至 HBM3。
所有这些与硬件相关的更改都很具有挑战性,因为 Meta 必须在现有资源限制内找到一个解决方案,改变的自由度非常小,并且要满足紧迫的时间表。
数据中心部署
一旦 Meta 选择好了对应的 GPU 和系统,将它们放置在数据中心以优化资源使用(电力、冷却、网络等)时,他们还需要权衡其他类型的工作负载。数据中心的电力和冷却基础设施不能快速(或轻松)更改,他们必须找到一种最佳布局,使数据中心内的计算能力最大化。这需要将支持服务移出数据中心,并尽可能多地放置 GPU 机架,以最大化电力和网络能力,从而实现最高的计算密度和最大的网络集群。
可靠性
为了在发生硬件故障时最大限度地减少停机时间,Meta 需要提前规划如何检测和修复问题。故障数量会随着集群规模的扩大而增加,在运行跨集群的作业时,应保留充足的备用容量,以便尽快重新启动作业。此外,还引入了更先进的故障检测,通过提前预防来减少停机时间。
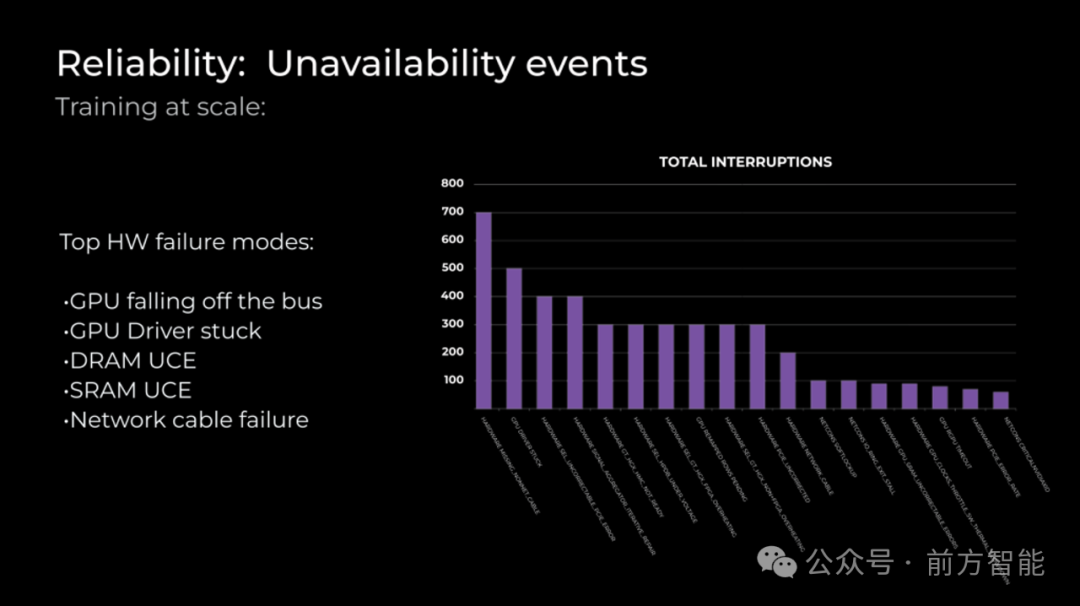
图源:Meta
Meta 观察到的三个最常见的故障是:
-
- GPU 掉线:在这种情况下,主机无法在 PCIe 上检测到 GPU。导致这种故障的原因有很多,但这种故障模式在早期更常见,随着服务器的老化会逐渐减少。
- DRAM 和 SRAM UCE:不可纠正的错误在内存中很常见,我们监控并识别重复出错的内存,跟踪阈值,并在错误率超过供应商阈值时启动 RMA。
- HW 网络电缆:无法连接上服务器的情况,这种问题通常会出现在服务器刚开始使用不久的时候。
网络
大规模模型训练涉及在 GPU 之间快速传输大量数据。这需要强大的高速网络基础设施以及高效的数据传输协议和算法。
在行业中有两个符合这些要求的领先选择:RoCE 和 InfiniBand 结构。这两种选择都各有利弊。一方面,Meta 在过去四年中构建了 RoCE 集群,但这些集群中最大的仅支持 4K GPU,因此他们需要显著更大的 RoCE 集群。但另一方面,Meta 构建了多达 16K GPU 的 InfiniBand 研究集群。然而,这些集群并未紧密集成到他们的生产环境中,也不是为最新一代的 GPU 和网络构建的。这使得选择构建哪种结构变得困难。
综合考虑之后,Meta 决定构建两个 24k 集群,一个使用 RoCE,另一个使用 InfiniBand。Meta 优化了 RoCE 集群以缩短构建时间,并优化了 InfiniBand 集群以实现全双工带宽,而且 Llama 3 就是使用 InfiniBand 和 RoCE 集群完成训练的。尽管这些集群之间的底层网络技术存在差异,但能够调整它们以为这些大型 GenAI 工作负载提供等效的性能。

图源:Meta
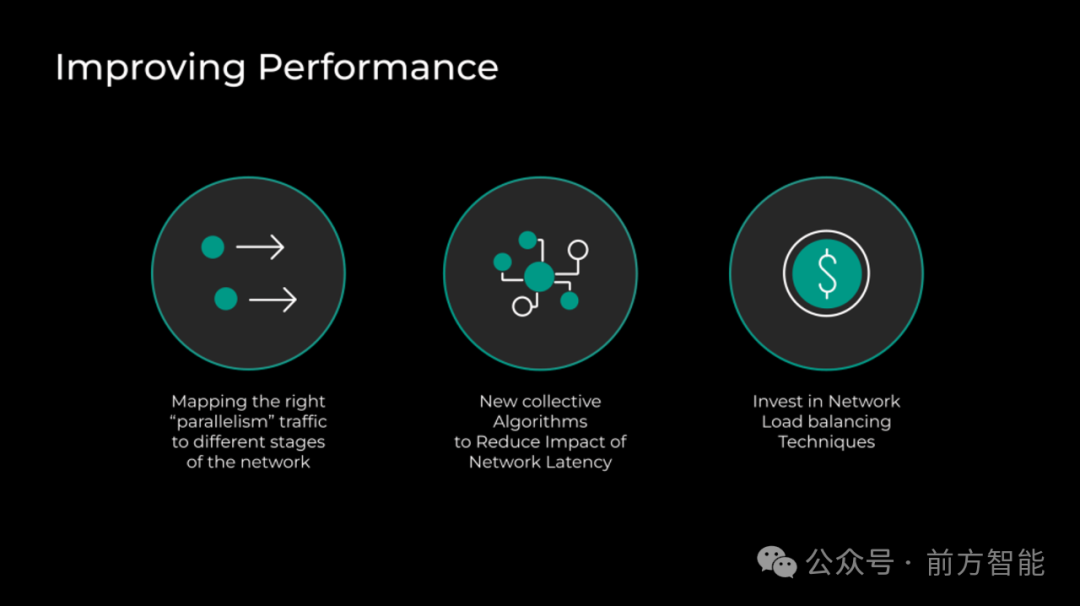
Meta 优化了整体堆栈的三个方面,使 GenAI 模型在两个集群上的网络通信性能更好:
-
- 将由不同模型、数据和管线并行性产生的通信模式分配到网络拓扑的不同层,以便有效利用网络能力。
- 实现了具有网络拓扑感知的集体通信模式,使其对延迟的敏感度降低。通过使用递归加倍或减半等自定义算法来更改集体通信的默认实现,而不是使用传统的环形算法。
- GenAI 作业会产生额外的 fat flows(胖流),使得很难在所有可能的网络路径上分配流量。这要求 Meta 进一步投资于网络负载均衡和路由,以实现流量在网络资源上的最佳分配。
图源:Meta
存储
这一环节,Meta 提供的信息相对较少,仅表示他们需要高效的数据存储解决方案来存储用于模型训练的大量数据,其中涉及投资于大容量和高速存储技术,并为特定的工作负载开发新的数据存储解决方案。
展望未来
Meta 表示:
在接下来的几年里,我们将使用成千上万的 GPU,处理更大规模的数据,并应对更长的距离和延迟。我们将采用新的硬件技术 —— 包括更新的 GPU 架构 —— 并改进我们的基础设施。这些挑战将推动我们以无法完全预测的方式进行创新和适应。但有一件事是确定的:这只是这段旅程的开始。随着我们继续在不断发展的 AI 领域中前行,我们将继续致力于突破可能性的界限。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。