前言
(1)如果有嵌入式企业需要招聘湖南区域日常实习生,任何区域的暑假Linux驱动实习岗位,可C站直接私聊,或者邮件:zhangyixu02@gmail.com,此消息至2025年1月1日前均有效
(2)之前我发表过一篇关于如何利用keil工具解决程序卡死问题的博客。但是依旧有朋友遇到hardfault问题还是不能够灵活解决。其实hardfault问题和我之前说的程序卡死的排查流程基本是一样的。就只有细微的不同点。但是为了做保姆级教程,因此再写一篇博客赘述一下。
问题复现
(1)首先看一下网友的问题:
<1>他说程序运行不到1分钟就进入hardFault。这个代码量很少,所以能够很快定位到问题,但是如果程序大了,如何定位问题。
<2>他说可以尝试通过查看R0–R15寄存器是否可以找出问题。
(2)首先回答第一个问题,对于程序的问题定位,肯定是一个复杂而又漫长的过程,经常能够遇到一些玄学问题因此我们要学会掌握技巧,下面的方法就是技巧之一。其次是第二个问题,这明显就是没搞明白寄存器的作用分别是干嘛的,完全是胡乱看寄存器。
(3)问题如下:

排查流程
栈回溯分析
(1)既然知道了问题是什么了,那么就开始排查,根据前面的介绍,我们可以通过
keil的debug工具中的Call Stack进行栈回溯。分析程序卡死之前被哪些函数调用,然后逐步分析这些函数可能的问题。
(2)但是,不幸的是,我们会发现Call Stack中只有一个HardFault_Handler。那么明显说明Call Stack工具现在是用不了的。

CM3和CM4异常返回值
(1)之前那篇博客,是介绍的普通的程序卡死如何进行排查,然后栈回溯调试。而这里有些许的不同,在于是
hardfault错误,因此只有这个地方会不同。
(2)前文我介绍了,程序卡死一般是看R14(LR)寄存器,因为这个寄存器存放返回值信息,通俗来说就是C语言的return根据这个寄存器进行函数返回。
注:下图摘抄自CM3权威指南3.1寄存器组章节。

(3)那么现在我们看一下
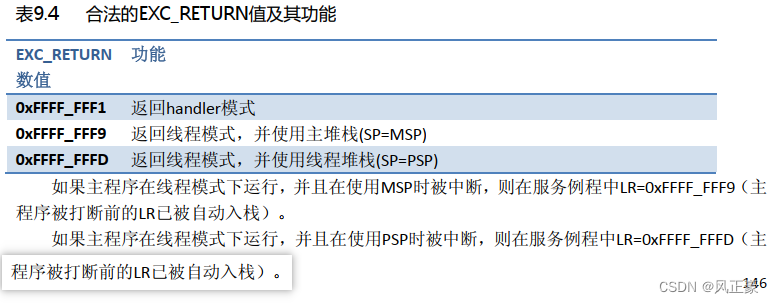
R14(LR)寄存器值是什么。我们会发现里面居然是0xFFFFFFFD!很明显,我函数返回不可能是返回到一个0xFFFFFFFD,因为程序一般都是存储在0x08开头的位置。那么这个时候我们就需要来了解一下CM3和CM4的异常返回值的知识了。

(4)我们在看上面的寄存器介绍的时候,有没有发现一个问题,
R13怎么有两个寄存器,一个MSP,一个是PSP?因为MSP用于内核和异常处理,而PSP用于进程的堆栈。这使得Cortex-M3处理器可以轻松实现多任务操作系统。
(5)上述这些,如果想详细了解的个人建议直接看这篇博客,介绍的非常的好:RTOS系列文章(6):Cortex-M3/4之SP,MSP,PSP,Thread模式、Handler模式、内核态、用户态
(6)但是,这部分知识跟我们问题定位关系不大。我们只需要了解,如果R14(LR)如果是0xFFFFFFFD,那么就看PSP寄存器。如果R14(LR)是0xFFFFFFF9,那么就看MSP寄存器。
注:下图摘抄自CM3权威指南9.6异常返回值章节。
手动栈回溯
(1)很好,既然我们有上述知识了之后。因为
R14(LR),我们就知道现在要看PSP寄存器的值了,之后内存信息知道堆栈数据,然后手动栈回溯了解HardFault_Handler之前是卡死在哪里。
(2)现在我们看PSP寄存器,知道堆栈寄存器存储的是0x00000020。那么就打开Memory工具,查看当前芯片内部的存储信息。
这里需要注意,PSP的堆栈寄存器,不是PC或者LR寄存器,因此是看的Memory工具而不是Disassembly工具。
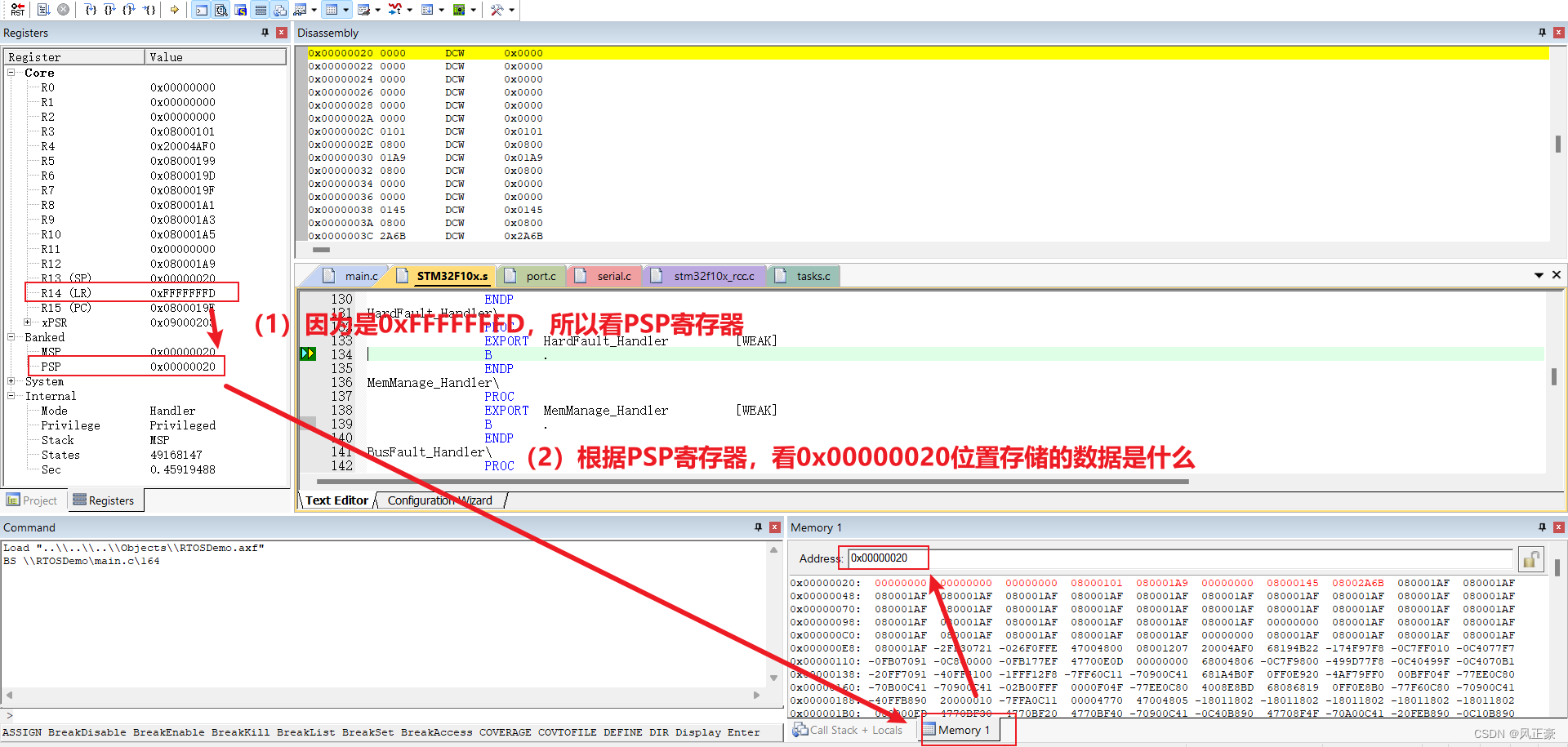
(3)根据堆栈指针寄存器,我们知道了当前堆栈指向位置存储的信息。那么如何根据这些信息进行问题的排查呢?这个时候我们就需要了解一下
CM3/CM4的中断/异常的入栈知识了。CM3/CM4的中断响应时候,硬件是会自动进行入栈的,他的栈存储位置如下。
注:下图摘抄自CM3权威指南9.1.1入栈章节。
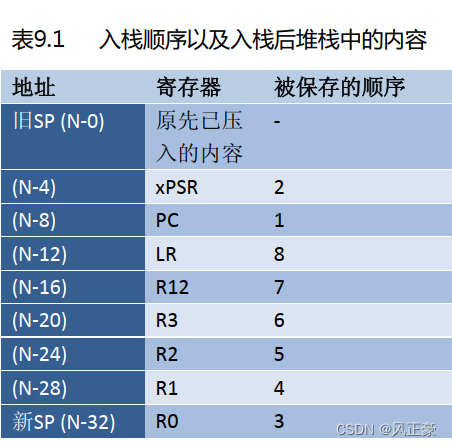
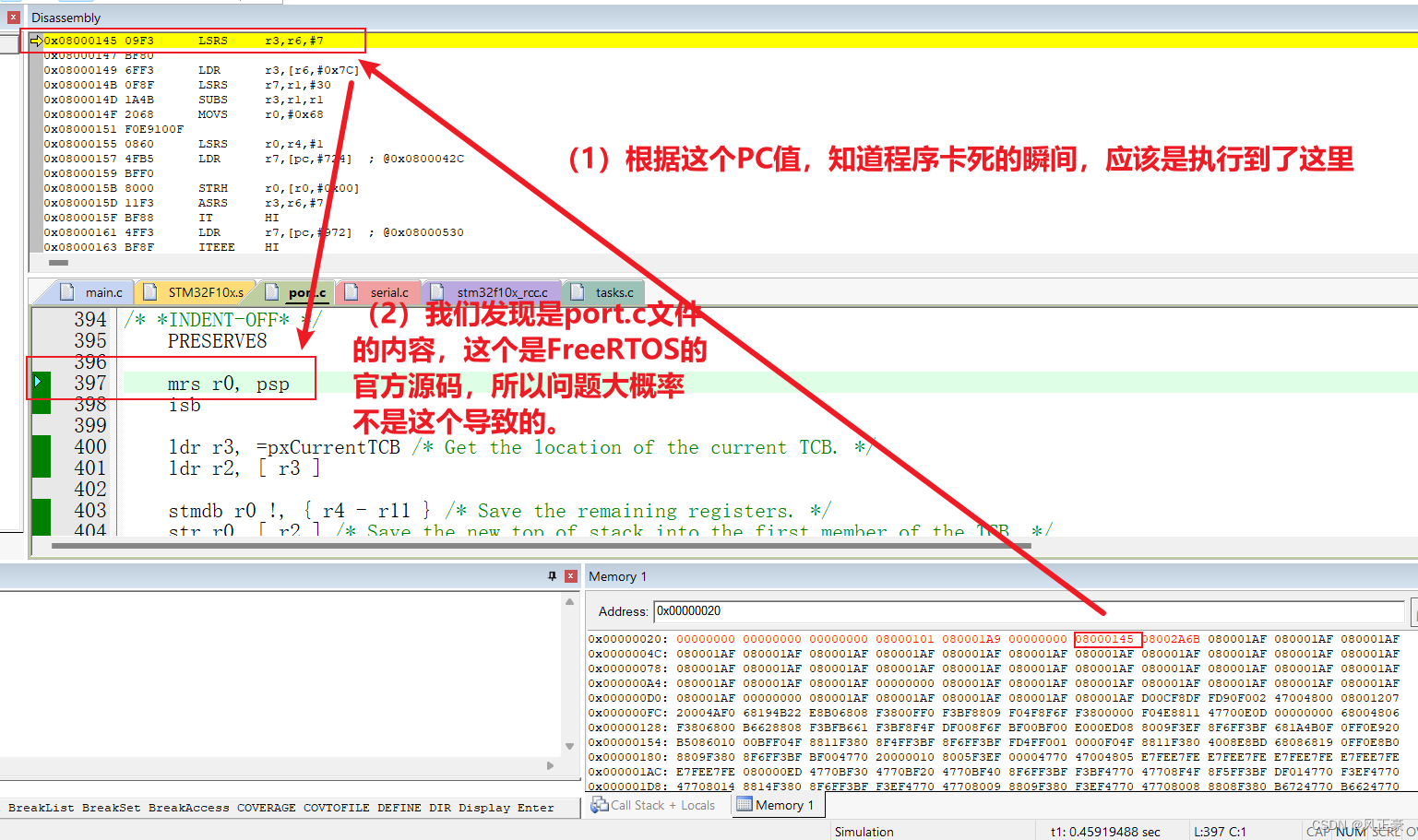
(4)之后我们就可以根据上面这个知识点,进行分析。可以得知,如果程序现在正常运行,那么应该是运行到
0x08000145位置。
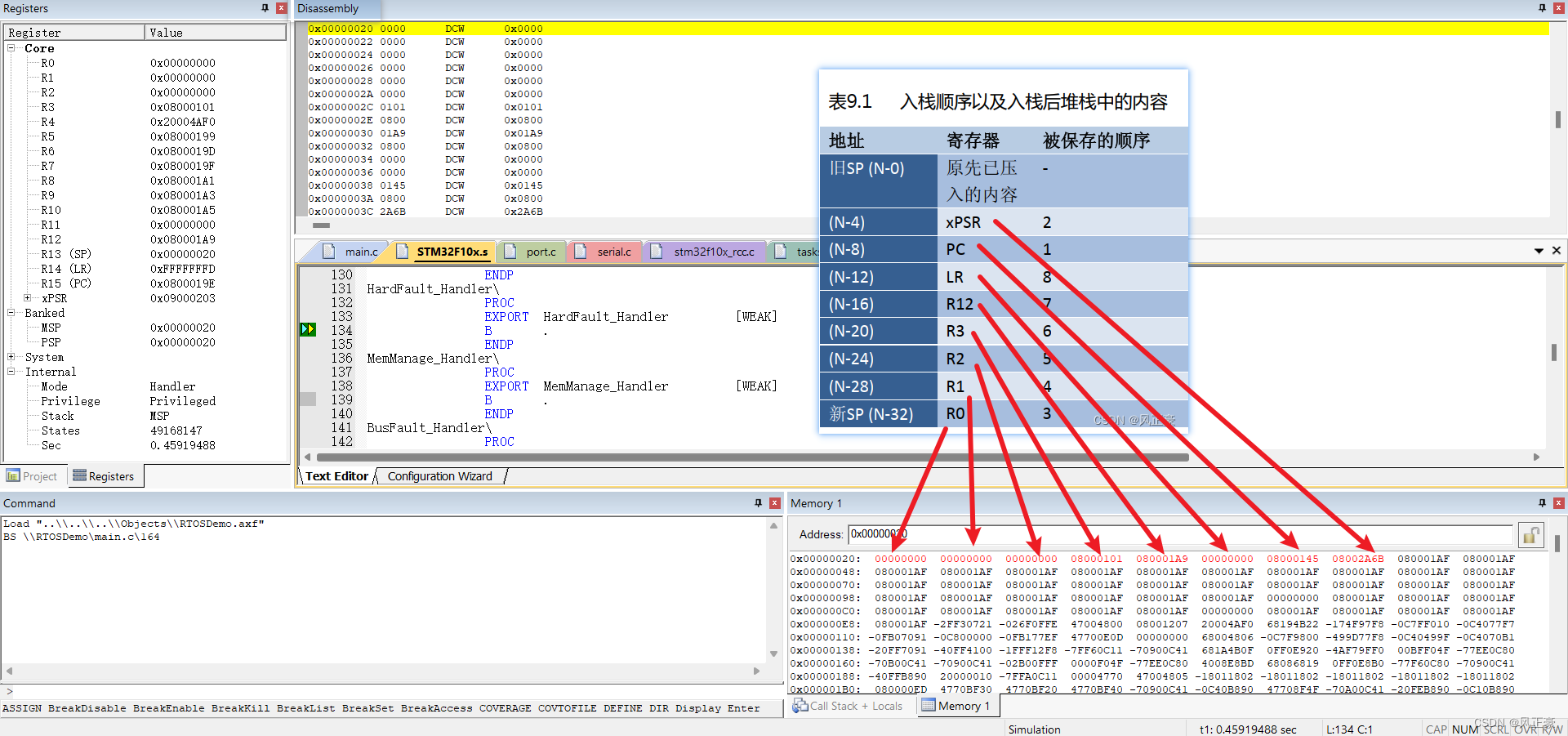
(5)于是我们根据
0x08000145找到程序实际卡死的地方。发现是卡死在port.c文件中,而这个文件又是FreeRTOS的官方源码,出错概率很低。
解决思路
定位可能的原因
(1)有了上述的分析,其实问题就已经解决一大半了。现在我们知道程序是卡死在
0x08000145位置,于是我们可以在这个位置进行打断点。然后复位程序重新跑,此时Call Stack能够帮助我们进行栈回溯了。
注意:程序需要多按几次全速跑,一直等到进入HardFault_Handler的前一刻停止。因为我们不清楚到底是什么时候卡死在这个断点处的。
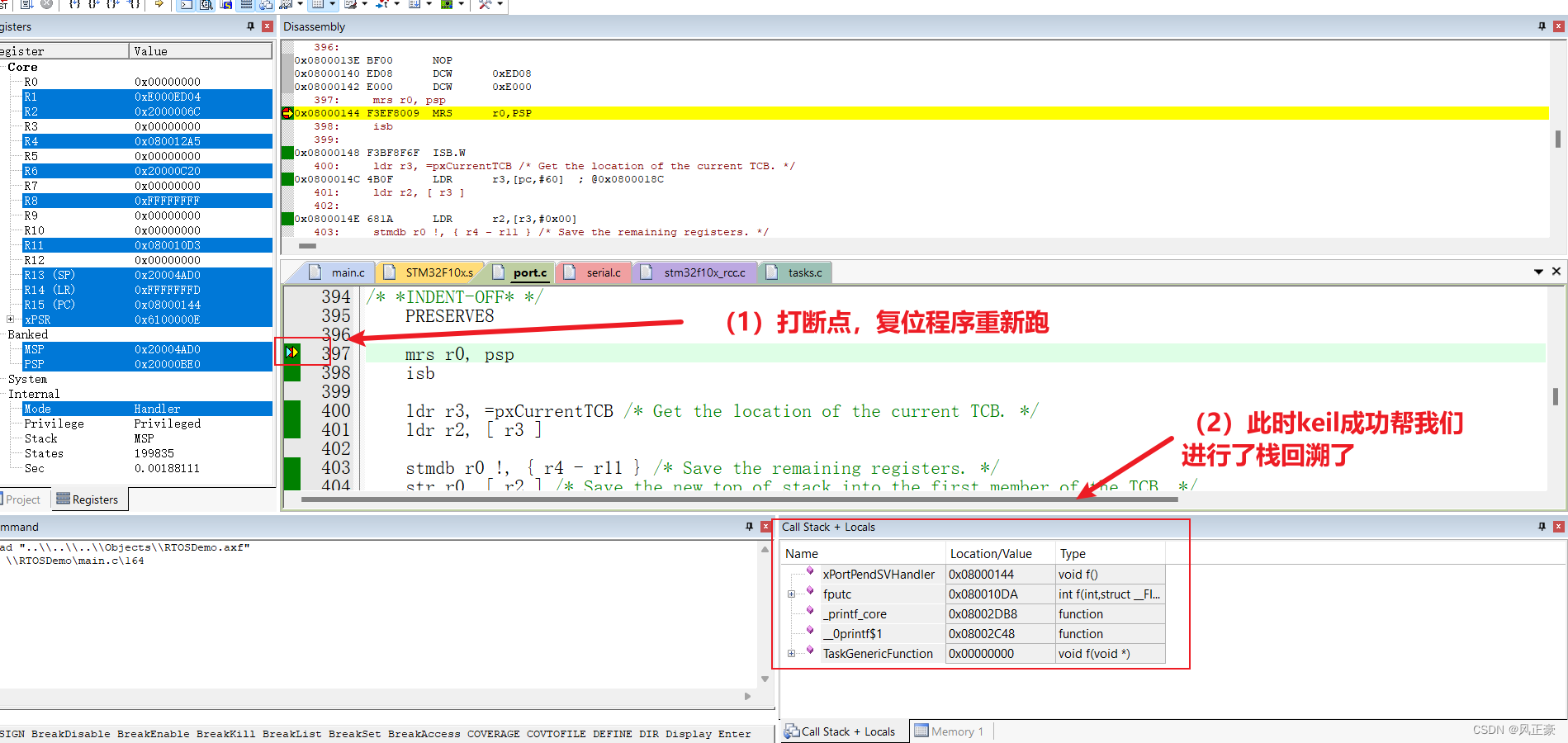
(2)然后我们就开始分析
Call Stack的内容,发现除了TaskGenericFunction()其他的要么是FreeRTOS官方程序,要么是C库程序。于是我们直接看TaskGenericFunction()程序到底发生了什么。跳转过去之后,我们发现这个任务中只有一个printf()打印。我尝试逐步注释printf(),发现可以解决问题,然后就错误的认为这是和printf()线程安全有关导致的bug。但是后面发现,这并不问题的关键。

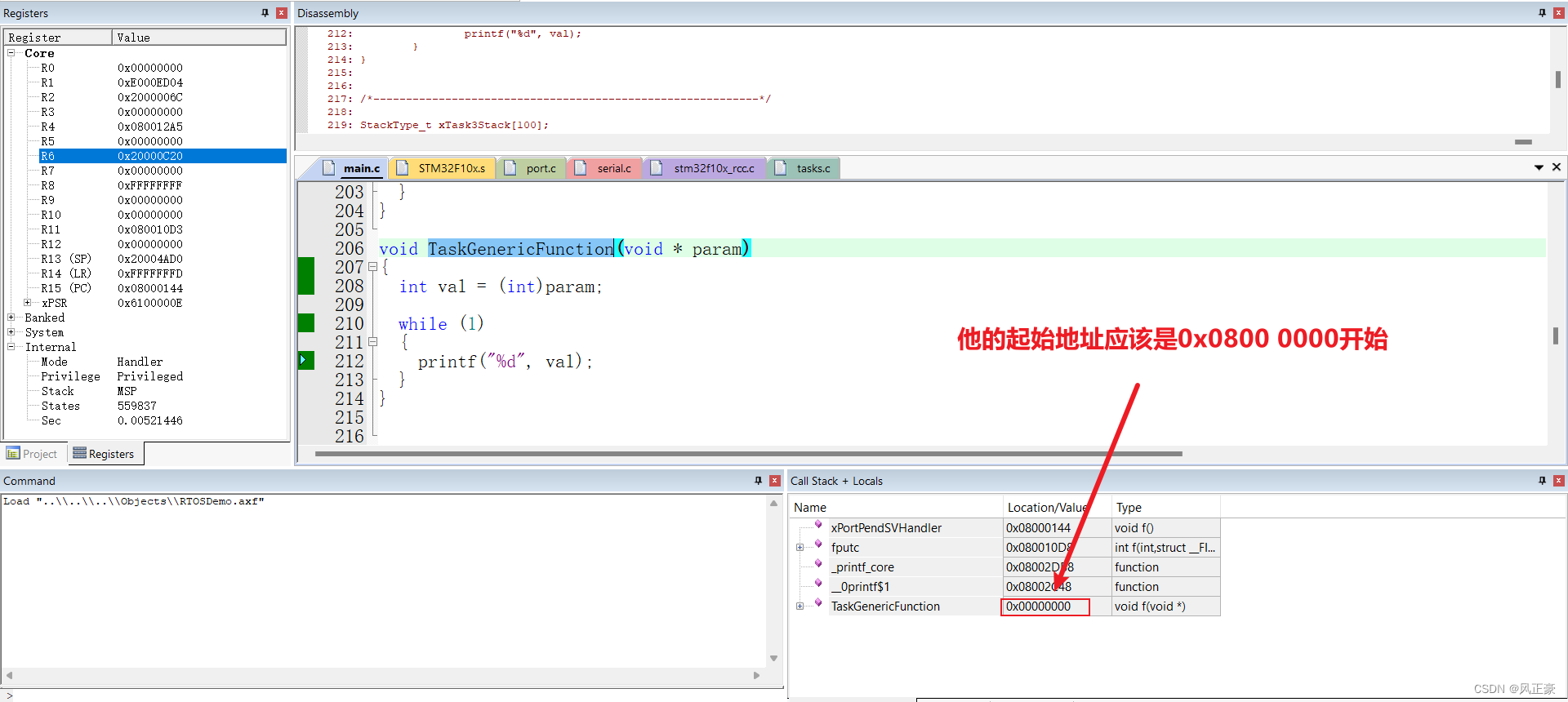
(3)如何发现真正的问题是什么?我们可以看
TaskGenericFunction()函数的Location/Value,会发现这里居然是0x00000000!我们都知道STM32的内存管理起始就是对0X0800 0000开始的Flash部分和0x2000 0000开始的SRAM部分使用管理。因此,这个地方毫无疑问是有问题的。出现这种问题,基本就可以知道是栈溢出的问题了。
FreeRTOS的uxTaskGetStackHighWaterMark()函数
(1)既然我们知道了是栈溢出的问题,那么如何知道是那个地方栈溢出了呢?此时就不得不是使用到
FreeRTOS的uxTaskGetStackHighWaterMark()函数了。这个函数可以监控任务使用的栈空间历史使用剩余值的最小值。使用方法如下:这里需要注意,需要在FreeRTOSConfig.h中将INCLUDE_uxTaskGetStackHighWaterMark设置为1,才可以使用这个函数。
/**
* @brief 查看任务使用的栈空间大小
*
* @param xTask 任务句柄
*
* @return 任务堆栈可用的最小值,单位word(4字节)
*/
UBaseType_t uxTaskGetStackHighWaterMark( TaskHandle_t xTask );
/* === 使用方法 === */
void StartCubemxTask(void *argument)
{
/* USER CODE BEGIN StartCubemxTask */
char *CubemxTaskPrintf = (char *)argument;
UBaseType_t Cubemx_Stack;
/* Infinite loop */
for(;;)
{
printf(CubemxTaskPrintf);
Cubemx_Stack = uxTaskGetStackHighWaterMark(keilTaskHandle);
printf("CubemxTask is %ld\r\n",Cubemx_Stack);
}
/* USER CODE END StartCubemxTask */
}
(2)了解了这个函数之后,那么我们尝试在每个任务中加入一个
uxTaskGetStackHighWaterMark()监控栈使用情况,并且都打上断点。

(3)按照如下办法,之后开始查看他们的栈使用情况。

(4)我们一点一点的开始测试,最终发现是能够找到栈空间被榨干的地方了。
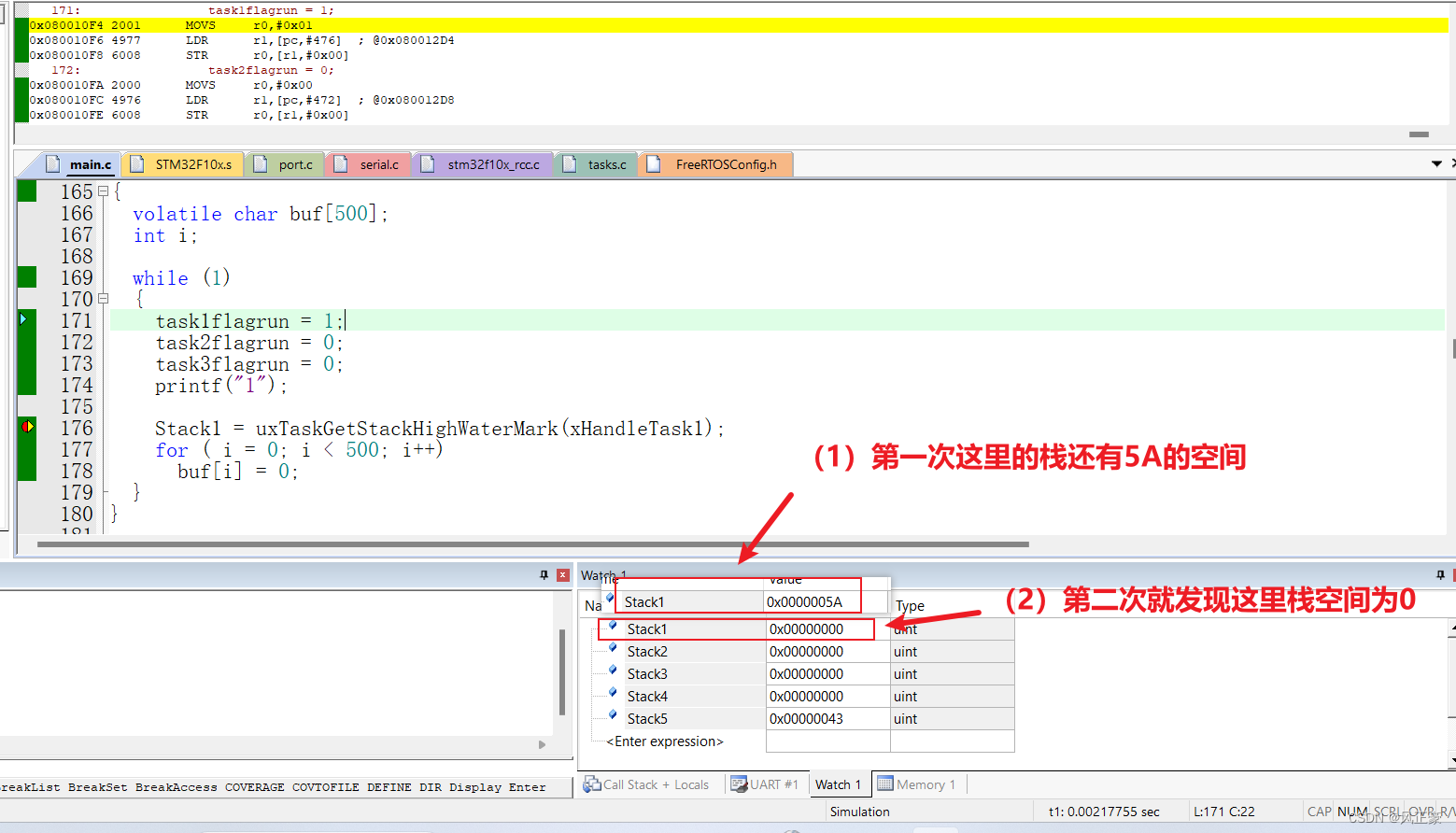
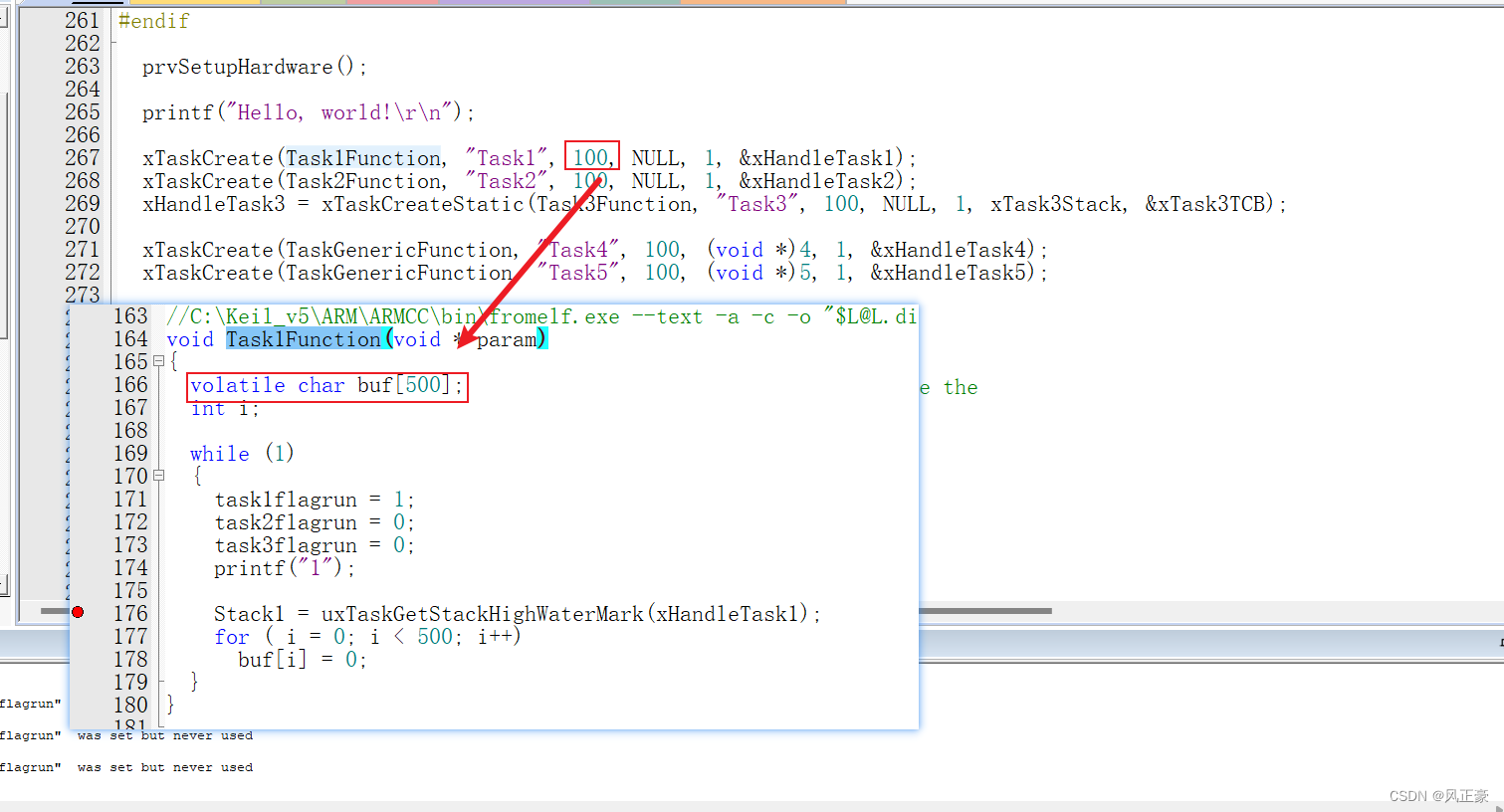
(5)现在我们思考一下为什么这个地方栈空间会被榨干。我们知道,起始是执行了下面这个for循环之后,栈空间就为空了。因此我们再看一下任务分配的时候任务栈空间是多少,能够发现是
100 word,也就是400字节。而这里的buf[]就有500字节了。于是问题就成功发现了,此时我们可以尝试调小buf[]或者是增大任务栈空间。
for ( i = 0; i < 500; i++)
buf[i] = 0;
总结
(1)
ARM的M系列控制器hardfault问题调试步骤,应该基本都是这样的。所以说我们要多练习,程序出故障的可能性很多,栈溢出,逻辑错误,硬件bug都是有可能的。
(2)题外话:说实话,比起调程序bug,猜女孩子的心思才是最难的。硬件有问题,我有万用表,逻辑分析仪,示波器。软件问题,我有编译器,调试器,debug工具,栈回溯。女生发脾气,怎么也不知道到底哪里得罪姑奶奶了,最恶心的是bug不可复现。哭死
参考
(1)RTOS系列文章(6):Cortex-M3/4之SP,MSP,PSP,Thread模式、Handler模式、内核态、用户态
(2)STM32的内存管理相关(内存架构,内存管理,map文件分析)
(3)hardfault问题分析解决及记一次ucosIII环境下的hardfault解决