Prometheus告警Alertmanager部署
资源监控一般离不开预警,因为我们不可能每时每刻都盯着某个资源监控看,而且在实际的工作中当中我们搭建的解决方案涉及到的服务器是多台甚至数十台,所以更加不现实,因此资源告警是一个必不可少的一个模块。
Alertmanager告警原理
首先我们了解下alertmanager的基本的报警原理
Prometheus Server(监控规则-告警)–push->AlertManager(Router-Receiver)–notify->Email/企业微信…
通过Prometheus Server中配置的监控规则采集数据,当采集的数据经过一定的计算符合配置的告警规则时,就将把告警对应的内容信息推送给alertmanager模块,alertmanager模块根据配置规则将报警推送给邮件或者企业微信内容,具体可以参考官方文档:https://prometheus.io/docs/alerting/latest/configuration/
Alertmanager告警部署
alertmanager主要进行报警
1.首先我们进入Prometheus的官方网站的下载页面:https://prometheus.io/download/获取对应的版本。我们会看到如下界面。
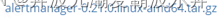
然后这里我们选择altermanager-0.21.0.linux-amd64.tar.gz的版本进行点击进入下载,我们可以获取相应的安装包。
2.将下载下来的文件包通过xshell上传到跟我们prometheus同一台服务器上(也可以不同服务器),把程序包放到一个目录下面:
[root@localhost Stability]# pwd
/ftp/Stability
[root@localhost Stability]# ls |grep al
alertmanager-0.21.0.linux-amd64.tar.gz
3.通过以下命令对altermanager进行安装。
首先进行解压:
[root@localhost Stability]# tar -zxvf alertmanager-0.21.0.linux-amd64.tar.gz
alertmanager-0.21.0.linux-amd64/
alertmanager-0.21.0.linux-amd64/alertmanager
alertmanager-0.21.0.linux-amd64/amtool
alertmanager-0.21.0.linux-amd64/NOTICE
alertmanager-0.21.0.linux-amd64/LICENSE
alertmanager-0.21.0.linux-amd64/alertmanager.yml
解压完成以后对文件进行重命名:
[root@localhost Stability]# mv alertmanager-0.21.0.linux-amd64 alertmanager
因为很多公司服务器所在的环境都属于公司内网中,服务器无法获取外网地址。如果在有外网的情况下是可以简化步骤1、步骤2中的步骤。只需要在在步骤1中获取下载的地址,然后进入CentOS操作系统下,使用如下命令即可获取安装包。
wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
4.设置node_export后台启动,命令如下。
# 首先我们需要确定操作系统版本,CentOS7及以上可以成服务的模式
root@localhost:/usr/local/monitor/node_exporter# cat /etc/redhat-release
CentOS release 6.9 (Final)
# 然后我们需要在prometheus.yml文件中添加如下信息
[root@localhost prometheus]# vi prometheus.yml
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets: ['10.31.128.110:7093']
rule_files:
- /ftp/Stability/prometheus/rules/*.rules
# 接下来我们就要在对应的规则文件路径下进行规则配置,假设我们配置一个服务器Down的报警,操作如下
[root@localhost rules]# pwd
/ftp/Stability/prometheus/rules
[root@localhost rules]# vi service_down.rules
groups:
- name: ServiceStatus #规则组名称
rules:
- alert: ServiceStatusAlert #单个规则的名称
expr: up == 0 #匹配规则, up==0
for: 10s #持续时间
labels: #标签
project: ServiceDownAlert #自定义lables
annotations: #告警正文
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
# 然后我们再配置alertmanager的告警规则
[root@localhost alertmanager]# vi alertmanager.yml
我们可以看到原先的配置文件如下:
global:
resolve_timeout: 5m
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'web.hook'
receivers:
- name: 'web.hook'
webhook_configs:
- url: 'http://127.0.0.1:5001/'
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
然后我们进行改造成如下配置信息
#全局配置,比如配置发件人
global:
resolve_timeout: 5m #处理超时时间,默认为5min
smtp_smarthost: 'mail.XXXXX.com:25' # 邮箱smtp服务器代理
smtp_from: 'XXXX@XXXX.com' # 发送邮箱名称
smtp_auth_username: 'XXXX@XXXX.com' # 邮箱名称
smtp_auth_password: 'XXXXXXX' # 邮箱密码或授权码
smtp_require_tls: false
# 定义路由树信息,这个路由可以接收到所有的告警,还可以继续配置路由,比如project: zhidaoAPP(prometheus 告警规则中自定义的lable)发给谁,project: baoxian的发给谁
route:
group_by: ['alertname'] # 报警分组依据
group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知
group_interval: 10s # 在发送新警报前的等待时间
repeat_interval: 10s # 发送重复警报的周期 对于email配置中,此项不可以设置过低,否则将会由于邮件发送太多频繁,被smtp服务器拒绝
receiver: 'email' # 发送警报的接收者的名称,以下receivers name的名称
# 定义警报接收者信息
receivers:
- name: 'email' # 路由中对应的receiver名称
email_configs: # 邮箱配置
- to: 'XX@XXX.com' # 接收警报的email配置
#html: '{{ template "test.html" . }}' # 设定邮箱的内容模板注意:我们改过prometheus.yml文件,所以需要重载
5.设置alertmanager后台启动,命令如下。
# 进入后台启动服务目录
[root@localhost Stability]# cd /usr/lib/systemd/system
# 拷贝一份现有的service服务脚本
[root@localhost system]# cp prometheus.service alertmanager.service
# 使用vim命令对文件记性编辑
[root@localhost system]# vim alertmanager.service
# 修改成以下内容后进行保存退出
[Unit]
Description=AlertManager
Documentation=https://prometheus.io/
After=network.target
[Service]
ExecStart=/ftp/Stability/alertmanager/alertmanager --config.file=/ftp/Stability/alertmanager/alertmanager.yml --storage.path=/ftp/Stability/alertmanager/data
Restart=on-failure
[Install]
WantedBy=multi-user.target
# 保存退出后我们进行重新加载配置
[root@localhost system]# systemctl daemon-reload
# 然后启动alertmanager服务
[root@localhost system]# systemctl start alertmanager
# 查看进程是否在线
[root@localhost alertmanager]# systemctl status alertmanager
● alertmanager.service - AlertManager
Loaded: loaded (/usr/lib/systemd/system/alertmanager.service; disabled; vendor preset: disabled)
Active: active (running) since Wed 2021-03-24 10:31:49 CST; 1s ago
6.启动完成以后,我们就可以用如下地址进行访问9093地址

这样我们一个报警就已经设置好了。
Alertmanager告警触发实例
因为我们目前的测试环境网段是无法进行邮件发送的,主要是跟网络隔离,所以这里使用windows环境的Alertmanager相关报进行邮件模拟发送。主要在prometheus上面简历了两个告警规则。
[root@localhost rules]# ls
cpu_high.rules service_down.rules
规则1:当服务器10.31.131.20的CPU使用率超过0即报警
[root@localhost rules]# cat cpu_high.rules
groups:
- name: ServiceStatus #规则组名称
rules:
- alert: ServiceStatusAlert #单个规则的名称
expr: sum(count(node_cpu_seconds_total{instance="10.31.131.20:7100", mode='system'}) by (cpu,instance)) by(instance) > 0 #匹配规则
for: 10s #持续时间
labels: #标签
project: ServiceDownAlert #自定义lables
annotations: #告警正文
summary: "Instance {{ $labels.instance }} cpu higer"
description: "{{ $labels.instance }} of job {{ $labels.job }} cpu is very higer."
规则2:当相应的服务在线,即报警
[root@localhost rules]# cat service_down.rules
groups:
- name: ServiceStatus #规则组名称
rules:
- alert: ServiceStatusAlert #单个规则的名称
expr: up == 1 #匹配规则, up==0
for: 10s #持续时间
labels: #标签
project: ServiceDownAlert #自定义lables
annotations: #告警正文
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
当触发报警以后,我们可以登录http://10.31.128.110:9090/classic/alerts的界面看到告警产生:

Inactive:告警仅仅生效,未发生任何事宜。
Pending:已触发阈值,但为满足告警持续时间
Firing:已触发阈值且满足告警持续时间。报警发送给接受者
接收的报警邮件如下: