JS-页面截图下载为pdf
关于如何下载为 pdf 在上面的这篇文章中有写,大家可以看下,下载图片代码在最下面
这时我们发现 three 部分是空白的如下:

这就多少有点尴尬了,这时我们习惯性的看下后台报错

是不是发现了惊喜,html2canvas其实已经给我报错了,而且还很贴心的给出了解决方案,我们先上代码:
renderer = new THREE.WebGLRenderer({
antialias: true, // 启用抗锯齿功能
preserveDrawingBuffer: true
});
其实就是给 WebGLRenderer 多传了一个参数,那这个是什么意思呢?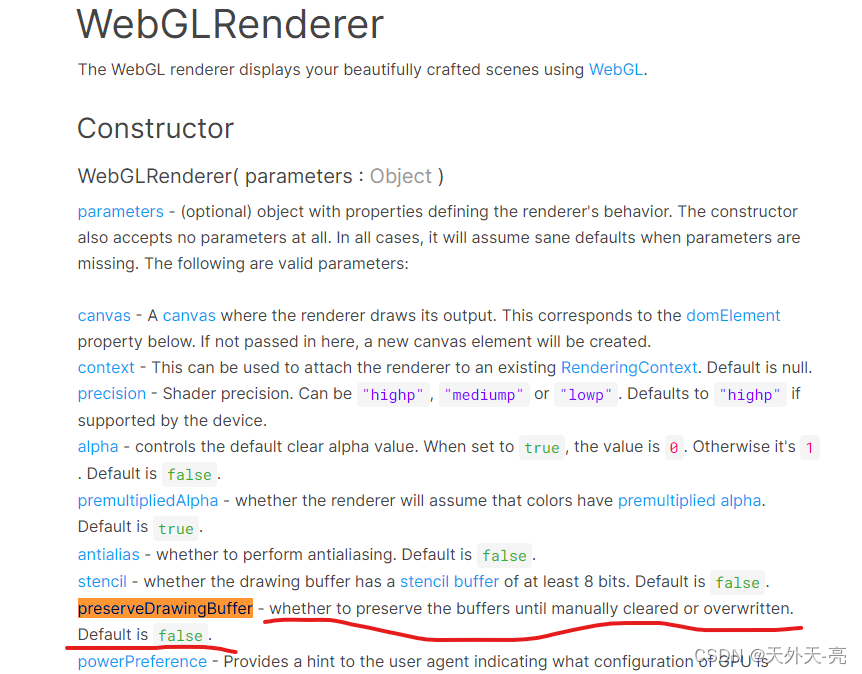
官方解释:是否保留缓冲区直到手动清除或重写。默认值为false。
preserveDrawingBuffer 是一个WebGL渲染器选项,用于确定是否在多个渲染循环中保留drawing buffer。如果设置为true,则drawing buffer在多个渲染循环中会被保持,这可以提高性能,但可能会占用更多的内存。
请注意,这个选项在WebGL渲染器的默认行为中并不常用,因为通常WebGL会在每次渲染后自动清除drawing buffer。设置preserveDrawingBuffer为true可能会导致性能问题或内存问题,特别是如果你在渲染循环中不断请求帧缓存的像素数据。
下载为图片:
const downloadPDF = () => {
const element: any = document.querySelector('.app');
// const { scrollHeight, scrollWidth, offsetHeight, height } = element;
const opts = {
scale: 3, // 缩放比例,提高生成图片清晰度
useCORS: true, // 允许加载跨域的图片
allowTaint: false, // 允许图片跨域,和 useCORS 二者不可共同使用
tainttest: true, // 检测每张图片都已经加载完成
logging: true, // 日志开关,发布的时候记得改成 false
height: element.offsetHeight
};
html2canvas(element, opts).then((canvas) => {
const link = document.createElement('a');
// 通过超链接herf属性,设置要保存到文件中的数据
link.href = canvas.toDataURL("image/png");
link.download = 'aaa.png'; // 下载文件名
link.click(); // js代码触发超链接元素a的鼠标点击事件,开始下载文件到本地
});
};
请大家注意如果 three 中有用到 CSS2DRenderer 或者 CSS3DRenderer,这个也要加
labelRenderer = new CSS2DRenderer({
preserveDrawingBuffer: true
});