摘要解读
我们提出了一种能够以全双工方式运行的生成性对话系统,实现了无缝互动。该系统基于一个精心调整的大型语言模型(LLM),使其能够感知模块、运动功能模块以及一个具有两种状态(称为神经有限状态机,neural FSM)的简单有限状态机的概念。
感知模块和运动功能模块协同工作,使系统能够同时与用户进行说话和聆听。LLM生成文本标记以响应查询,并通过向神经FSM发出控制标记自主决定何时开始回应、等待或打断用户。LLM的所有这些任务都是在对话的实时序列化视图上进行下一个标记的预测。
在模拟现实生活互动的自动质量评估中,与基于LLM的半双工对话系统相比,所提出的系统将平均对话响应延迟减少了三倍以上,同时在超过50%的评估互动中在500毫秒内作出响应。运行仅8亿参数的LLM,我们的系统在语音对话中断精度方面比最好的商用LLM高出8%。
作者:
Peng Wang, Songshuo Lu, Yaohua Tang, Sijie Yan, Yuanjun Xiong, Wei Xia
机构:
MThreads AI
摘要分析:
本论文介绍了一种能够实现全双工操作的生成性对话系统,允许无缝互动。该系统基于大型语言模型(LLM),并与感知模块、运动功能模块以及一个简单的有限状态机(称为神经FSM)结合。感知和运动功能模块协同工作,使系统能够同时与用户进行说话和聆听。LLM生成文本标记以响应查询,并通过发出控制标记给神经FSM来自主决定何时开始回应、等待或打断用户。这些任务通过在实时对话的序列化视图上进行下一个标记的预测来完成。在模拟现实生活互动的自动质量评估中,该系统在对话响应延迟方面比基于LLM的半双工对话系统减少了三倍以上,并在超过50%的评估互动中在500毫秒内作出响应。运行8亿参数的LLM,该系统的中断精度比最佳商用LLM高出8%。

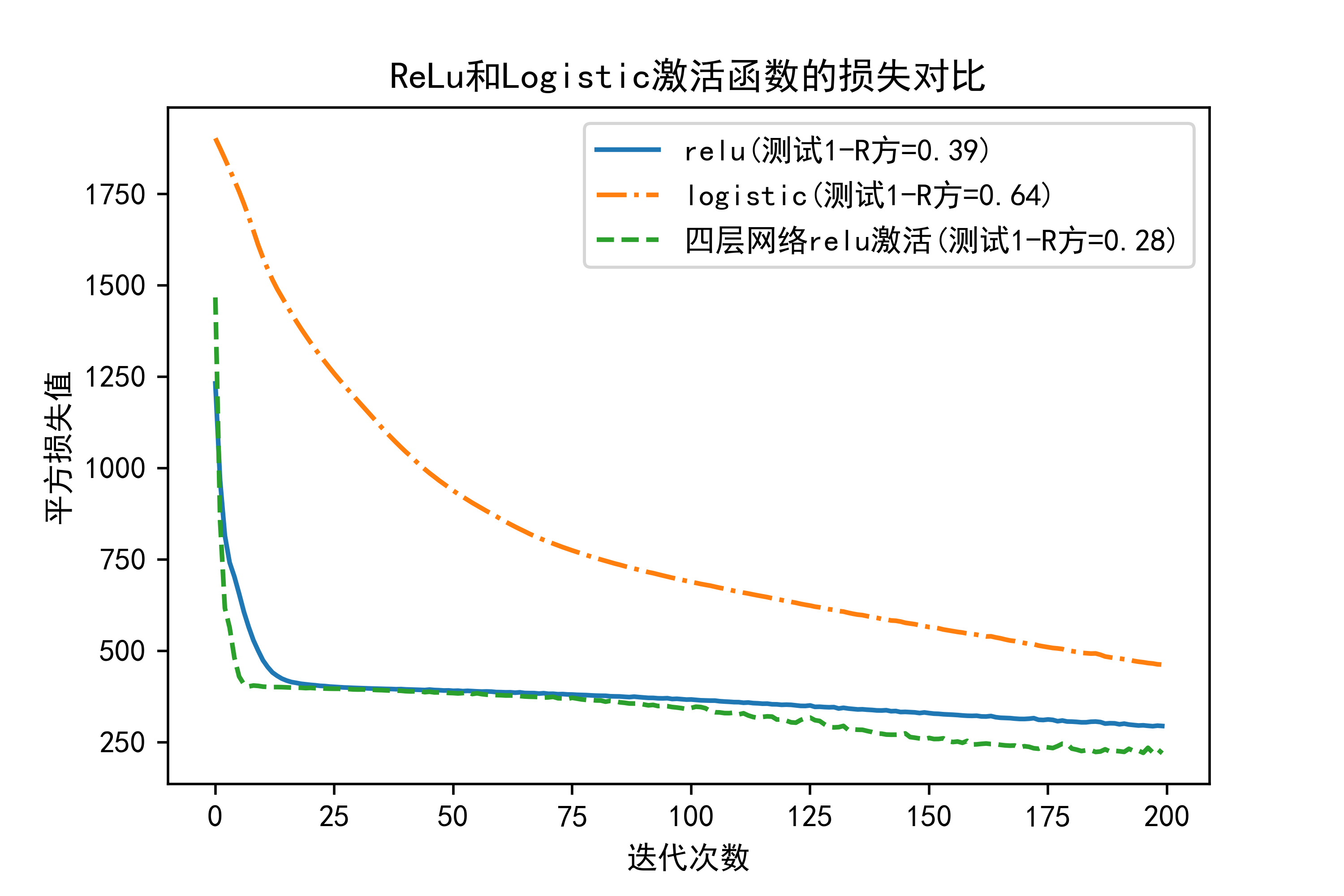
图1:左侧。支持基于大语言模型(LLM)的全双工对话模型的代理设计概述。该代理配备了一个LLM、一个感知模块和一个运动功能模块。后者连续且同时操作以收集LLM的输入并生成基于语音的LLM输出。右侧。LLM操作一个具有SPEAK(说话)和LISTEN(聆听)状态的两态神经有限状态机(FSM)。在每个时间步,LLM要么1)接收一个外部输入词元,要么2)生成一个用于语音的文本词元,要么3)生成一个控制词元以在神经FSM中信号状态转换。这个简单的工作流程无需任何外部调节模块即可实现全双工对话。
引言分析:
在人与人之间的对话中,一方在说话时,另一方在聆听,可以在必要时打断对方。现有的大多数聊天功能的LLM将对话视为一个回合制过程,每个参与者在对方回应之前生成完整的句子,这导致了半双工对话模式。虽然这种模式在构建文本聊天机器人时是合理的,但在实现类似于人类对话体验时,由于响应延迟和难以正确打断对方的问题,半双工对话模式变得不可行。本文旨在解决这一问题,实现全双工对话。
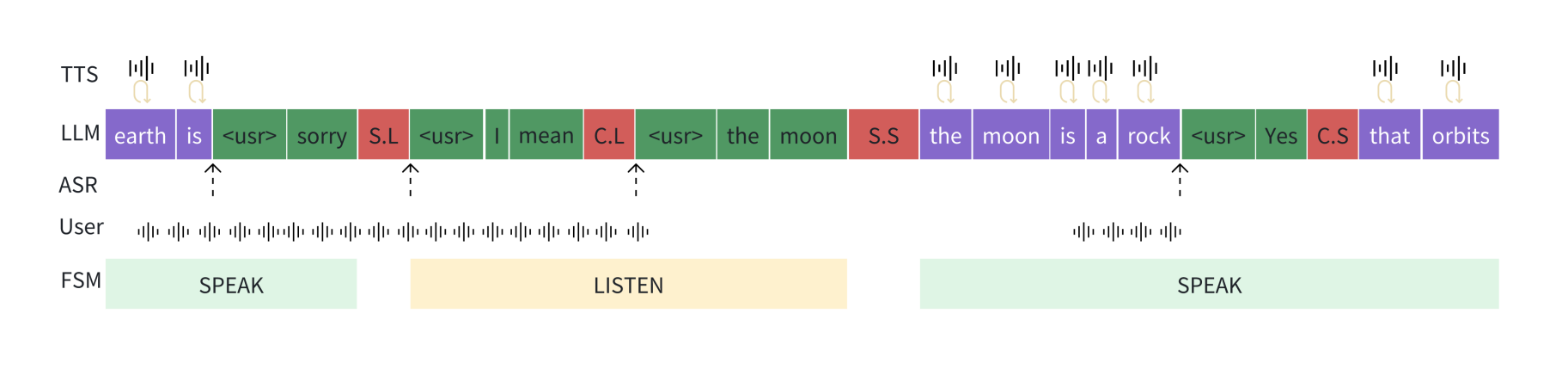
图2:在基于大语言模型(LLM)的全双工对话系统中,LLM操作一个两态有限状态机(FSM),管理对话中的状态转换。
方法分析:
论文提出的系统包括三个模块:感知模块、具有全双工能力的LLM和运动功能模块。感知模块通过自动语音识别模型捕捉用户的语音输入,并将其串流到LLM中。LLM生成的任何文本标记都会立即发送到运动功能模块,并转化为语音输出。LLM通过操作一个有两种状态(“说话”和“聆听”)的神经FSM来管理对话。
贡献与创新:
- 实现双向同时交互:系统允许用户和机器同时交谈,类似于自然人类对话,而不是回合制对话。
- 完全自主性:LLM基于语义上下文自主决定何时暂停、打断或提问。
- 快速响应:系统在对话中以最小的延迟响应用户查询。
方法的长处:
- 降低响应延迟:比现有的半双工系统减少了三倍以上的平均响应延迟。
- 高精度的中断响应:中断精度比最佳商用LLM高出8%。
方法的短处:
- 依赖多模块协同工作:当前系统仍依赖ASR和TTS模块的无缝合作,这可能引入额外的延迟。
实验与评价:
通过设计的自动评估框架,验证系统在响应延迟和对话质量方面的有效性。与最先进的半双工对话系统相比,该系统在减少对话响应延迟和提高中断响应的准确性方面表现出色。
结论:
本文提出了一种基于LLM的全双工对话系统,能够以低延迟进行响应,并根据实时用户输入自主决定何时开始和停止讲话,以及在适当的时机打断用户。未来,随着多模态LLM的出现,感知和运动功能模块将进一步简化,仅需处理音频信号的预处理和语音数据的播放。
论文下载地址
链接:https://pan.quark.cn/s/d356ceec6dd7