- Apache Druid:是是一个集时间序列数据库、数据仓库和全文检索系统特点于一体的分析性数据平台,旨在对大型数据集进行快速的查询分析("OLAP"查询)。Druid最常被当做数据库来用以支持实时摄取、高性能查询和高稳定运行的应用场景,同时,Druid也通常被用来助力分析型应用的图形化界面,或者当做需要快速聚合的高并发后端API,Druid最适合应用于面向事件类型的数据。
- 特性
- 实时数据摄取:Druid能够实时地处理和索引数据,使其几乎可以立即查询。
- 高性能查询:Druid优化了查询性能,特别是对于聚合查询和数据切片,这在传统的关系型数据库中可能需要很长时间。
- 灵活的数据模型:Druid支持灵活的数据模型,允许用户定义数据的维度和度量,以适应不同的分析需求。
- 水平扩展:Druid设计为分布式系统,可以水平扩展以处理PB级别的数据。
- 高可用性:Druid的架构支持高可用性,通过复制数据和查询负载均衡来实现。
- 丰富的集成:Druid可以与多种数据源和数据管道工具集成,如Apache Kafka、Apache Hadoop等。
- 主要查询方式及参数说明
- Druid原生查询
- Druid SQL查询
- 主要参数
- queryType: 指定查询的类型,对于时间序列查询,这个值通常是 "timeseries"。
- dataSource: 指定查询的数据源名称,即要从哪个数据表或数据集进行查询。
- intervals: 定义查询的时间范围,可以是一个或多个时间区间。格式通常是 ISO 8601 格式,例如 "2019-01-01T00:00:00Z/2019-01-02T00:00:00Z"。
- granularity: 指定查询的粒度,可以是 "all"(表示整个数据集)、"hour"、"day"、"week"、"month"、"year" 或自定义的粒度。
- filter: 定义查询的过滤条件,可以是各种类型的过滤器,如选择器(selector)、布尔(boolean)等。
- aggregations: 定义聚合操作,用于对数据进行汇总计算。可以包含多个聚合,每个聚合都有自己的字段名、类型和名称。
- postAggregations: 定义在聚合之后执行的二次计算,用于对聚合结果进行进一步的处理。
- dimensions: 指定要返回的维度列,可以是维度的数组。
- metrics: 指定聚合操作的输出名称,通常与聚合操作中的 name 字段对应。
- orderBy: 指定结果的排序方式,可以是按照时间或特定维度排序。
- limitSpec: 定义结果集中返回的行数限制。
- context: 提供查询的上下文信息,可以包含各种设置,如超时时间、查询优先级等。
- having: 指定过滤聚合结果的条件,通常在聚合之后应用。
- intervalsOverride: 覆盖查询中定义的时间区间。
- descending: 指定是否按降序返回结果。
- 案例:
- {
- "queryType":"topN",
- "dataSource":"taxi_message",
- "dimension":"local",
- "threshold":2,
- "metric":"age",
- "granularity":"month",
- "aggregations":[
- {
- "type":"longMin",
- "name":"age",
- "fieldName":"age"
- }
- ],
- "filter":{"type":"selector","dimension":"sex","value":"女"},
- "intervals":["2021-06-07/2022-06-07"]
- }
- Druid 最开始的时候是不支持 SQL 查询的,原生查询是通过查询 Broker 提供的 http server 来实现的
- Druid API 接口及其作用
- 原生查询方式
- /druid/v2/pretty:JSON格式请求,返回JSON结果集
- SQL 查询接口:
- /druid/v2/sql:执行 SQL 查询,返回查询结果。
- 数据摄取(Ingestion)接口:
- /druid/indexer/v1/task: 提交数据摄取任务,用于将数据加载到 Druid 中。
- 数据源(DataSource)管理接口:
- /druid/coordinator/v1/datasources: 获取所有数据源的列表。
- /druid/coordinator/v1/datasources/{dataSource}: 获取指定数据源的详细信息。
- 任务管理接口:
- /druid/indexer/v1/task: 提交数据摄取任务。
- /druid/indexer/v1/supervisor: 管理数据摄取的监督器(Supervisor)任务。
- 查询历史(Query History)接口:
- /druid/query/history: 获取查询历史记录。
- 集群协调(Coordinator)接口:
- /druid/coordinator/v1/cluster: 获取集群状态信息。
- /druid/coordinator/v1/leader: 获取当前集群的领导者节点。
- 数据节点(Data Node)接口:
- /druid/dataNode/v1: 获取数据节点的状态信息。
- 历史节点(Historical Node)接口:
- /druid/historical/v1: 获取历史节点的状态信息。
- 实时节点(Realtime Node)接口:
- /druid/v2/datasources/{dataSource}/intervals: 获取实时数据源的活跃时间区间。
- 配置管理接口:
- /druid/indexer/v1/worker: 获取工作节点的配置信息。
- 监控和状态接口:
- /druid/broker/v1: 获取 Broker 节点的状态信息。
- /druid/overlord/v1: 获取 Overlord 节点的状态信息。
- 元数据存储接口:
- /druid/metadata/v1: 与元数据存储交互,例如获取或更新表的元数据。
- 任务状态接口:
- /druid/indexer/v1/task/{taskId}: 获取特定任务的状态和结果。
- 原生查询方式
- 开发人员须知的概念
- 数据源:
- 段的生命周期管理包括创建、发布和可用性检查。新创建的段首先由MiddleManager生成并标记为未提交(uncommitted),此时数据已经可以被查询。随着时间的推移,段会被提交并发布到深度存储,变为不可变(immutable),并由Historical进程进行管理。Coordinator负责监控新的段,并指导Historical加载这些段以提供服务
- 数据源中的数据被组织成多个段(Segment),每个段代表一个时间区间的数据。例如,如果数据源按天分区,那么每个chunk将代表一天的数据。每个段内部,数据被优化存储,包括列式存储、使用位图索引进行索引等,这些都是为了加快查询速度而设计的。
- 数据源在Druid中的作用类似于传统数据库中的表。每个数据源包含特定时间段的数据,并且可以按事件分区,也可以根据需要按其他属性进一步分区。这种分区机制使得Druid能够有效地管理和查询大量数据。
- 索引:
- Druid支持多种索引类型,包括全文搜索索引、嵌套索引和主键索引。这些索引类型可以单独使用或组合使用,以满足不同的查询需求。
- 索引在Druid中是可选的,但如果正确使用,可以显著提高查询性能。例如,主键索引可以加速表扫描,而全文搜索索引则支持高效的文本搜索。
- 索引的创建和管理是通过Druid提供的工具和API进行的,开发人员需要熟悉这些工具来优化他们的数据查询。
- 查询语言:
- Druid的原生查询语言提供了一种高效且灵活的方式来处理复杂的分析查询。这种语言支持各种操作,如时间序列分析、聚合和过滤。
- 学习Druid的查询语言对于充分利用其分析能力至关重要。虽然起初可能是挑战性的,但掌握它可以极大地增强数据处理的能力。
- 数据摄取:
- Druid设计用于处理实时数据摄取,这意味着它能够快速接收并处理流数据。这对于需要快速响应数据变化的应用来说非常重要。
- 数据摄取的过程可以通过Druid的管理界面或API进行配置,开发人员需要了解这些选项以确保数据的正确和高效流入。
- 安全性:
- Druid支持基于角色的访问控制,这允许管理员为不同的用户和应用程序分配不同的权限级别。
- 开发人员需要了解如何配置这些权限,以确保数据的安全性和合规性。
- 数据源:
- 参考链接
- 快速开始 · ApacheDruid中文技术文档
- 对比
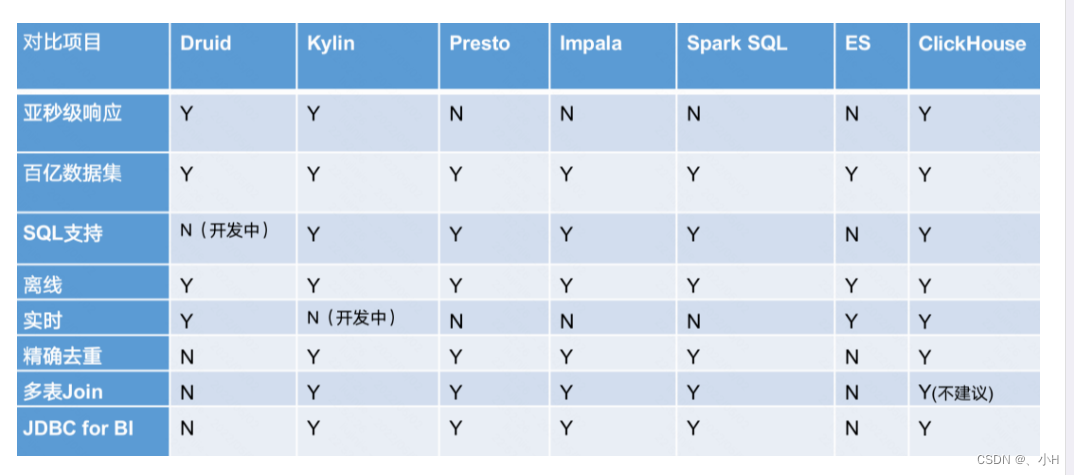
Apache Druid-时序数据库
news2026/2/15 2:55:56
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1837350.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
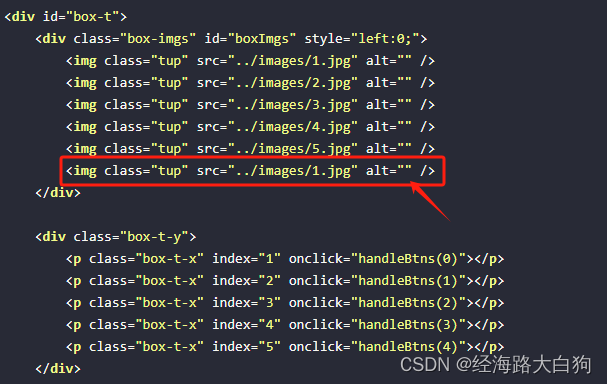
手把手带你实现一个简单的轮播图
轮播图现有成熟的插件非常多,但做为一名学习中的想要成为前端开发的小伙伴们来说,自己动手实现一个轮播图,还是很锻炼的,实现完成后,也是很有成就感的。下面,我们来实现一个简单的轮播图吧。 目录
1 HTML …

DIY一个PE启动盘
原文:https://blog.c12th.cn/archives/18.html
前言 有天,朋友问我有没有带集成软件的U盘启动盘。我也是很久没有弄启动盘了,有次在逛b站时无意中看到还有可以DIY的启动盘,于是就教程就来了… 该两种方法,已在三台实体…
SCADA软件地毯式介绍,你想知道的都在这里.
很多小伙伴对SCADA很陌生,殊不知这个可是智慧工业制造的大脑和中枢神经,很多指令的发出,监控状态的现实都得通过这个系统,本文详解介绍一下什么是SCADA,重大作用,其在工业制造中的位置,以及市面…

停车场控制机系统哪家好?捷顺捷曜分体式车场控制机有哪些功能亮点?
停车场控制机为现代城市提供了许多便利和好处。首先,它能够自动记录车辆进出的时间,便于车主和管理人员进行费用计算。其次,通过车牌识别技术,提高了车辆进出的效率,减少了排队等待时间。此外,控制机还可以…
【Pepper机器人开发与应用】二、Pepper机器人图形化开发:医疗服务机器人程序设计
🏡博客主页: virobotics(仪酷智能):LabVIEW深度学习、人工智能博主 📑上期文章:『【Pepper机器人开发与应用】一、教你如何使用图形化开发软件高效开发pepper机器人(Pepper SDK for LabVIEW)…
MFC开发 解决:VSstudio2019 无法打开afxwin.h 或 安装afxwin.h
在进行MFC开发的学习中,在win10系统下使用vs studio2019进行mfc开发,出现的标题的问题
首先,如果你以及安装过了afxwin.h相关环境
那么按照如下步骤
首先
打开工程的属性
在 高级——MFC的使用——选择在共享DLL中使用MFC
如下 …

【AICFD教程】汽车外气动仿真,小白学CFD的入门案例
【视频教程】 【教程】汽车外气动仿真,小白学CFD的入门案例 【文字教程】
1. 案例背景
1.1 学习目标
本案例针对某汽车仿真模型,在车速为40m/s时进行了汽车外流场的数值模拟。
本案例教程旨在演示AICFD中以下场景与功能的操作:
a. 单域外…

JavaScript和promise——0_1 promise
文章目录 是什么?未来值回调和未来值在回调环境下这么和未来值交互?群居的未来值其他的解决方案 这样写可以实现目标效果。可是,这样写优雅吗? 英雄登场关键词:then关键词:回调 为什么promise不需要start函…

在等保2.0框架下,如何进行有效的物联网设备安全培训和意识提升?
在等保2.0框架下,进行有效的物联网设备安全培训和意识提升,可以从以下几个方面入手:
1. 分层次培训内容设计:
• 基础知识普及:涵盖物联网的定义、特点及其面临的安全威胁和攻击手段,让员工理解物联网安全…
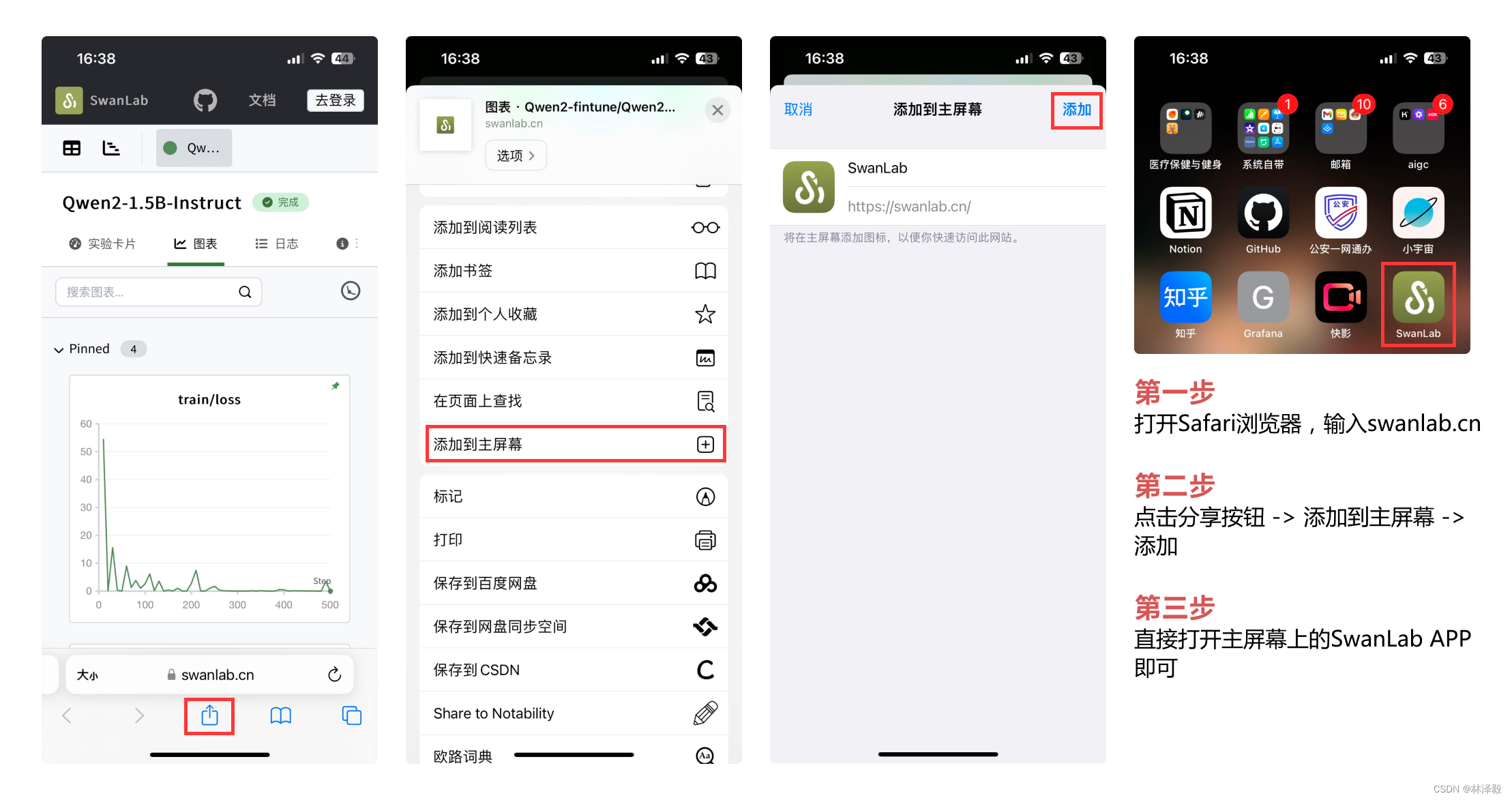
技巧|手机上看SwanLab实验的两种方法
什么是SwanLab?
SwanLab是一个深度学习实验管理与训练可视化工具,由西安电子科技大学创业团队打造,融合了Weights & Biases与Tensorboard的特点,可以记录整个实验的超参数、指标、训练环境、Python版本等,并可视化图表&…
![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] A先生的货运计划(200分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/dedd651ce67e4072b94d4e34d7f1fb36.png)
【2024最新华为OD-C/D卷试题汇总】[支持在线评测] A先生的货运计划(200分) - 三语言AC题解(Python/Java/Cpp)
🍭 大家好这里是清隆学长 ,一枚热爱算法的程序员 ✨ 本系列打算持续跟新华为OD-C/D卷的三语言AC题解 💻 ACM银牌🥈| 多次AK大厂笔试 | 编程一对一辅导 👏 感谢大家的订阅➕ 和 喜欢💗 📎在线评测链接
A先生的货运计划(200分)
🌍 评测功能需要 订阅专栏 后私信…


揭秘网络盗版游戏产业链,守护游戏安全 | 天堂1私服非法牟利,涉嫌洗黑钱!
近年来,网络盗版游戏现象日益猖獗,尤其是天堂1私服。这些盗版游戏不仅非法牟利,还存在偷税漏税、诱导消费等违法行为。本文将揭示这一产业链的真相,提醒广大游戏玩家保持警惕,并向相关部门举报,共同维护互联…

安卓软件自动运行插件的开发源代码介绍!
随着移动互联网的快速发展,安卓操作系统凭借其开放性和灵活性,成为了众多开发者们的首选平台,在安卓应用的开发中,为了实现各种复杂的功能,插件化技术逐渐受到青睐。
其中,自动运行插件作为一种能够实现应…

MT8766安卓4G核心板_MTK联发科PCBA方案开发
MT8766是联发科四核4G模块方案,安卓一体板。
采用台积电 12 nm FinFET 制程工艺,4*A53架构,Android 9.0操作系统,搭载2.0GHz 的 Arm NEON 引擎。提供了支持最新 OpenOS 及其要求苛刻的应用程序所需的处理能力,专为具有…

可提供实习证明/实习鉴定报告,企业项目试岗实训开营啦
在数字化转型的浪潮中,大数据和人工智能等前沿技术已成为推动经济发展和科技进步的关键动力。当前,全球各行各业都在积极推进数字化转型,不仅为经济增长注入新活力,也对人才市场结构产生了深刻影响,尤其是对数字化人才…

CCS环形低角度光源用于细微凹凸、损伤、刻印字符的成像——LDR2-LA1系列
机器视觉系统中,光源起着重要作用,不同类型的光源应用也不同,选择合适的光源成像效果非常明显。今天我们一起来看看CCS光源——工业用环形低角度光源LDR2-LA1系列,可对被测物体近距离使用。 LDR2-LA1
特点
1、从被测物体的最近距…

数据可视化实验四:Pyecharts数据可视化
目录
一、使用PyEcharts绘制全国肺炎确诊人数分布图
1.1 柱状图
1.1.2 代码实现
1.1.2 绘制结果
1.2 饼状图
1.2.1 代码实现
1.2.2 绘制结果
1.3 使用over lap实现图形叠加
1.3.1 代码实现
1.3.2 绘制结果
1.4 地图绘制-Map
1.4.1 代码实现
1.4.2 绘制结果
1.5 地…
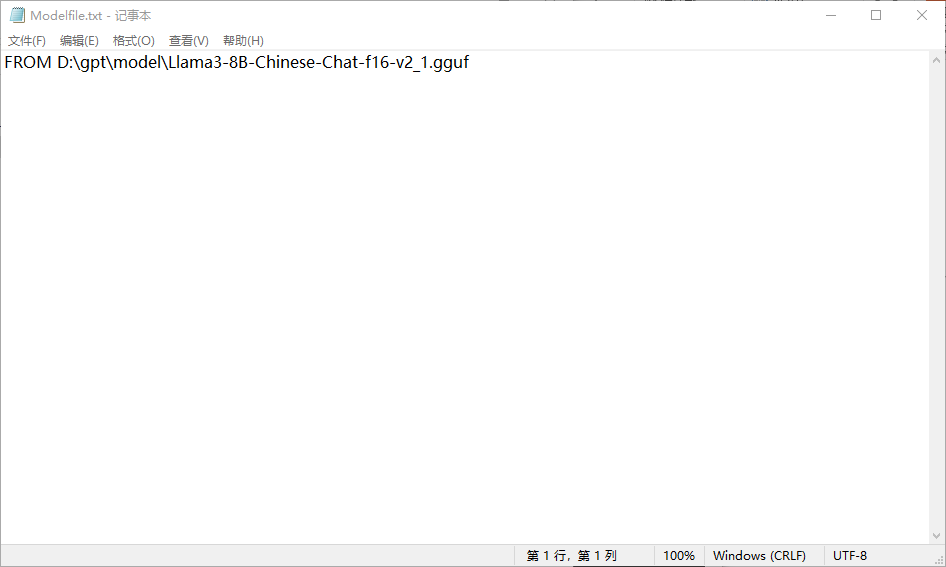
【ai】如何在ollama中随意使用hugging face上的gguf开源模型
【背景】
ollama的pull命令可以直接pull ollama列表中现有的模型,但是ollama可以直接pull的模型大都是英语偏好(llama2有直接可以pull的chinese版本),而hugging face上则有大量多语种训练的模型,如果能直接使用huggin…