构建多模态大模型时有很多有效的trick,如采用交叉注意力机制融合图像信息到语言模型中,或直接将图像隐藏状态序列与文本嵌入序列结合输入至语言模型。
但是这些trick为什么有效,其计算效率如何,往往解释得很粗略或者或者缺乏充分的实验验证。
Hugging Face团队最近进行了广泛的实验以验证在构建多模态大模型时哪些trick是真正有效的,得出了一系列极具参考价值的结论,甚至推翻了以往文献中普遍使用的观点。
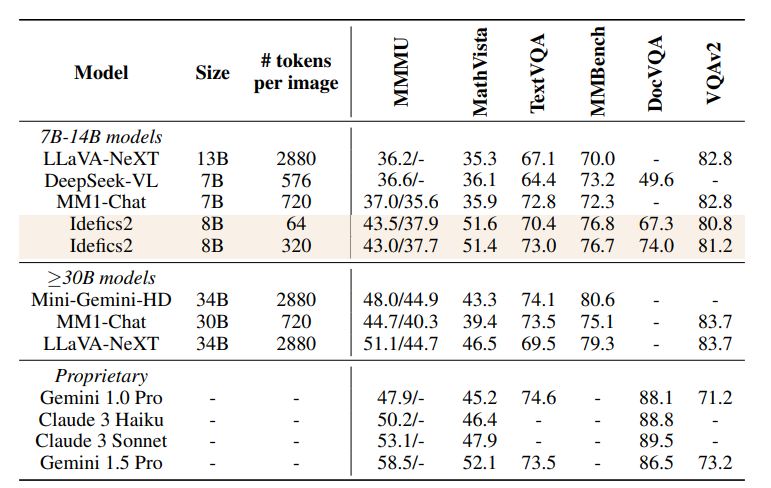
基于这些验证过的有效trick,团队开源了一个8B参数的视觉大模型——Idefics2,它在同等大小模型中是最能打的,其性能在某些基准测试中甚至超越了比它大4倍的模型,足以与闭源模型Gemini 1.5 Pro相媲美。
除此之外,还对Idefics2做了专门的对话训练,在与用户交互时也表现得相当出色。
比如分析表中数据并进行正确的计算: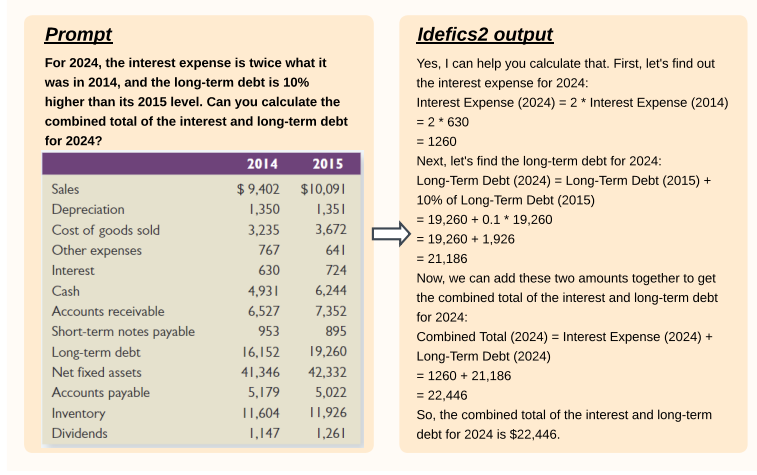
在简历中找到所需的信息,并将其组织为JSON格式:

解读表情包也像模像样:
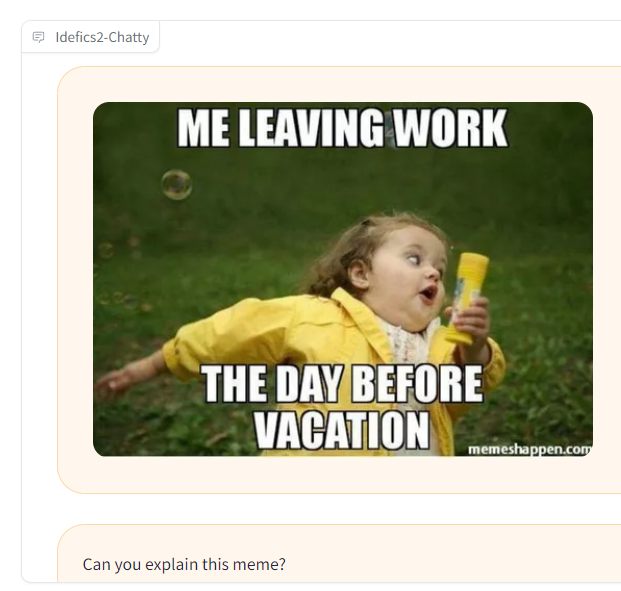
这个表情包描绘了一个穿着黄色雨衣的年轻女孩,她似乎正在穿过一片草地。她手里拿着一个黄色的东西,可能是一个玩具或一件设备。这张照片的背景是一片绿色的田野,远处有树木。表情包上的文字是“我在假期前一天下班”。这表明女孩在假期开始前兴奋地提前下班,象征着她在田野里快乐地奔跑。女孩充满活力的姿势和结合“工作”,为那些可能也期待假期的观众创造了一个轻松愉快和相关的场景。
团队也开放了源码和试玩地址,感兴趣的朋友可以试试效果~
试玩地址:
https://huggingface.co/spaces/HuggingFaceM4/idefics2_playground
论文标题:
What matters when building vision-language models?
论文链接:
https://arxiv.org/pdf/2405.02246
多模态大模型的基础结构
首先我们先简单了解一下多模态大模型由哪几部分组成。
一般来说,整个多模态大模型的训练可以被分为多模态理解与多模态生成两个步骤,如下图所示。多模态理解包含多模态编码器,输入投影与大模型主干三个部分,而多模态生成则包含输出投影与多模态生成器两个部分,通常而言,在训练过程中,多模态的编码器、生成器与大模型的参数一般都固定不变,不用于训练,主要优化的重点将落在输入投影与输出投影之中。
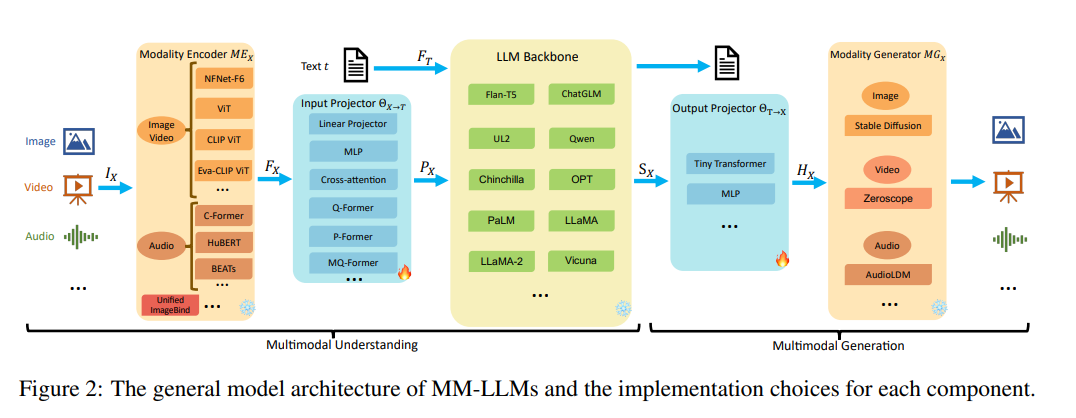 ▲图源《MM-LLMs: Recent Advances in MultiModal Large Language Models》
▲图源《MM-LLMs: Recent Advances in MultiModal Large Language Models》
本文主要聚焦于多模态理解能力,因此着重关注多模态编码器与输入投影部分。
多模态大模型构建中常用的trick真的有效吗?
模态编码器对性能的影响
多模态大模型使用预训练的模态编码器提取视觉输入的特征,使用语言模型主干提取文本输入特征。那么选择不同的视觉和文本模型对最终的性能有何影响呢?
作者固定了预训练模块的大小、用于多模态预训练的数据以及训练更新次数。在交叉注意力架构下,在视觉-语言基准测试中,随着模型升级,其性能大幅提升。
如下表1所示,将语言模型LLaMA-1-7B替换为Mistral-7B的性能提升了5.1个百分点。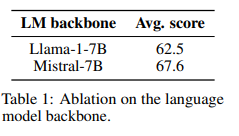
此外,将视觉编码器从CLIP-ViT-H切换到SigLIP-SO400M在基准测试中提升了3.3个百分点,如下表2所示:
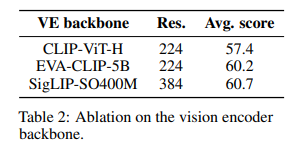
结论:对于固定参数,语言模型主干质量对最终VLM性能的影响大于视觉模型主干。
完全自回归架构与交叉注意架构相比哪个更优?
输入投影目的是将预训练的视觉模块和语言模块连接起来,对齐视觉输入和文本输入,主流方法有两种:
- 交叉注意力(Cross-attention):通过视觉模块对图像进行编码,并通过交叉注意力块将图像嵌入与文本嵌入注入到语言模型的不同层中。
- 完全自回归架构(fully autoregressive architecture):视觉编码器的输出直接与文本嵌入串联,并将整个序列作为语言模型的输入。视觉序列可以进行压缩,提高计算效率。
为了评估两种架构的优劣,作者冻结了单模态模块,仅训练新初始化的参数(一侧采用交叉注意力,另一侧进行模态投影和池化),并在固定训练数据量下进行了比较。交叉注意力块与语言模型层的高频交替排列能提升视觉-语言性能。遵循此设置,交叉注意力架构拥有额外的13亿个可训练参数(总计20亿),且在推理时计算量增加10%。在此条件下,交叉注意力架构的性能比完全自回归架构提升了7个百分点,如下表第二行和第三行所示。
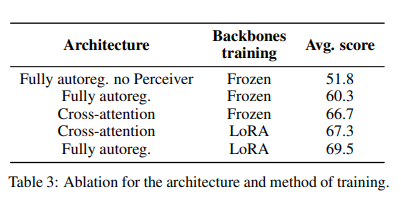
在总参数中,完全自回归架构占比约15%,而交叉注意力架构占比约25%。这种低比例可能限制训练的表达能力。作者解冻了所有参数(包括新初始化和预训练的单模态模块参数)来对比两种架构。为了防止完全自回归架构的训练损失发散,采用了LoRA方法来调整预训练参数,同时对新初始化参数进行完全微调,实验结果如上表最后两行所示。
这种方法显著提升了训练的稳定性:完全自回归架构性能提升12.9个百分点,而交叉注意力架构提升0.6个百分点。因此在可调参数增加的情况下,完全自回归架构更具性价比。
结论1:在单模态预训练模块被冻结时,交叉注意结构性能优于完全自回归结构。然而,一旦解冻并训练单模态网络,尽管交叉注意结构参数更多,但完全自回归架构反而展现出更佳的性能。
结论2:在完全自回归架构下,直接解冻预训练模块可能会导致训练过程的不稳[1]。采用LoRA技术可以在保持训练稳定的同时,有效增加模型的表现力。
图像tokens越多,性能越强??
先前的研究通常将视觉编码器的所有隐藏状态直接传递给模态投影层,并输入到语言模型中,不进行池化操作,这导致每个图像的tokens数量庞大,从而增加了训练成本。[2,3]的研究表明,增加视觉tokens的数量可以提升性能,但作者发现当使用超过64个视觉tokens时,性能并未得到进一步提升。作者推测,在理论上无限训练和数据的假设场景下,tokens越多,性能可能会有所提高,但代价是实际场景中无法接受的。
为了解决这一问题,作者引入了可训练的Transformer池化器(如Perceiver),以减少每个图像隐藏状态的序列长度。这种方法在减少tokens数量的同时,还提高了模型的性能。如下表所示,相比不进行池化的方法,该方法平均提高了8.5分,并将每个图像所需的tokens数量从729减少到了64。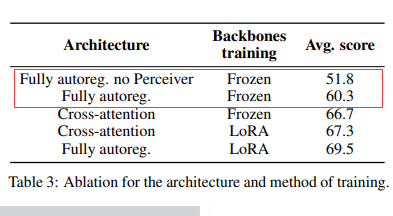
结论:使用可训练的池化器减少了视觉tokens的数量,显著提高了训练和推理的计算效率,同时提高了下游任务的性能。
固定图像宽高比和分辨率对性能是否有影响?
视觉编码器(如SigLIP)通常在固定大小的正方形图像上进行训练。调整图像大小会改变其原始宽高比,这在某些任务(如阅读长文本)中存在问题。此外,仅在单一分辨率上进行训练存在局限性:低分辨率可能忽略关键视觉细节,而高分辨率则降低训练和推理效率。允许模型处理不同分辨率的图像可以让用户根据需要灵活调整计算资源。
视觉编码器(如SigLIP)通常在固定正方形图像上训练,若调整大小会改变宽高比,影响如长文本阅读等任务。另外如果不同分辨率各有优劣:低分辨率忽略细节,高分辨率降低效率。因此允许不同分辨率输入可灵活调整计算资源。
本文尝试了直接将图像分块送入视觉编码器,不调整图像大小或改变其宽高比。在固定大小的低分辨率方形图像上训练时,插入了预训练的位置嵌入,并使用LoRA参数调整视觉编码器。结果如下表: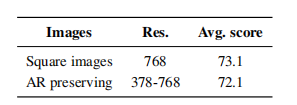
可以看到,固定长宽比的策略(AR preserving)在释放计算灵活性的同时,能保持任务性能。并且无需统一调整为高分辨率,节省GPU内存,允许按需处理图像。
结论:在固定大小的正方形图像上使用预训练的视觉编码器来保持图像的原始宽高比和分辨率,既加速了训练和推理,又减少了内存消耗,且性能不受影响。
切分成子图训练对性能有何影响?
多篇文献表明将图像分割成子图,然后再与原始图像连接可以提高下游任务的性能,但代价是需要编码的图像tokens数量大幅度增加。
作者在指令微调阶段,将每张图像扩展为包含原始图像和四个裁剪图像的列表。这样,模型在推理时既能处理单张图像(64个视觉tokens),也能处理增强的图像集(总共320个视觉tokens),结果如下表: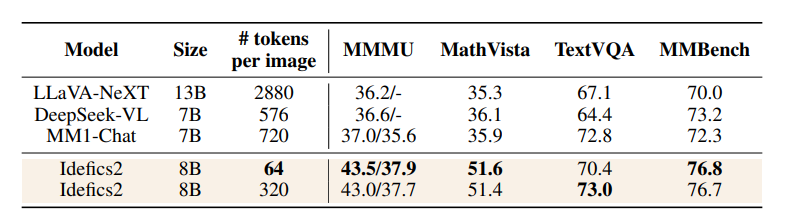
对于TextVQA和DocVQA等基准测试,这种策略尤为有效,因为它们需要高分辨率来提取图像中的文本。即使仅对50%的训练图像进行分割,性能提升也未受影响。
结论:在训练期间将图像分割成子图像,可以在推理期间提高计算效率,提高性能。在涉及读取图像中的文本的任务中,性能的提高尤其明显。
构建Idefics2——一个开放的最先进的视觉语言基础模型
在对影响视觉模型性能的因素进行讨论后,作者训练了一个开放的8B参数的视觉语言模型——Idefics2。下面将展开模型的构建、数据集的选择、训练阶段的过程。
1. 多阶段预训练
我们从SigLIP-SO400M和Mistral-7B-v0.1开始,并在3种类型的数据上预训练Idefics2。
交叉的图像-文本文档
数据源选用OBELICS数据集,并进行了过滤与清洗。这是一个开放的交叉的图像-文本文档数据集,包含3.5亿张图像和1150亿个文本tokens。OBELICS的长文档设计使语言模型在维持性能的同时,能够学习处理任意数量的交叉图像和文本。
图像-文本对
接下来需要利用图像-文本对训练模型,使其学习图像与其相关文本的对应关系。本文使用来自PMD的高质量人工标注的图像-文本对数据以及LAION COCO版本的合成标注数据,LAION COCO中的图像由基于COCO训练的模型进行标注,噪声较少。并使用一个高召回率的NSFW分类器进行过滤。
PDF文档
为了克服VLM在提取图像和文档中文本时的不足,作者训练了Idefics2模型,使用OCR-IDL的1900万份行业文档、PDFA6的1800万页数据,并加入了Rendered Text来增强对字体多样、颜色丰富文本的识别。结果如下表,这样的设置显著提升了模型阅读文档、提取图像的能力。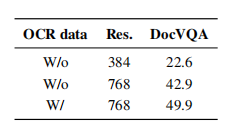
训练过程
为提高计算效率,分两个阶段进行预训练。第一阶段,图像最大分辨率设为384像素,使得可以使用平均大小为2048的批次大小(涵盖17000张图像和2500万个文本tokens)。数据中70%基于OBELICS数据集(序列长度最大为2048),30%为图像-文本对数据集(序列长度最大1536)。
第二阶段,引入PDF文档,将分辨率提升至980像素,保持全局批次大小但减少单机批次大小,使用梯度累积弥补额外内存。样本分配上,OBELICS占45%(序列长最大为2048),图像-文本对占35%(序列长度最大为1536),PDF文档占20%(序列长最大为1024)。同时,随机放大图像以覆盖不同尺寸。
模型评估
本文选择VQAv2 ,TextVQA,OKVQA 和COCO 进行模型评估。如下表: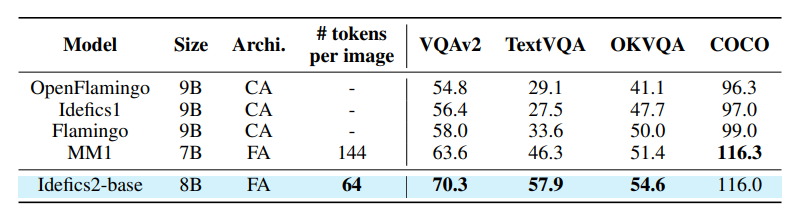
尽管Idefics2每张图片的tokens数量较少,但其高效性使其性能超越了当前最佳的基础视觉语言模型。特别是在理解图像中文本的能力上,Idefics2展现出了显著的优势。下图展示了Idefics2-base识别手写字体的示例。
2. 指令微调
在指令微调阶段,并创建了The Cauldron——一个混合了50个视觉-语言数据集的庞大集合,覆盖广泛任务,如视觉问答、计数、字幕、文本转录、文档理解等。数据集采用共享的问题/答案格式,对于多问题/答案对,构建多回合对话。此外,还添加了纯文本指令数据集,教授模型遵循复杂指令、解决数学和算术问题。
使用一种LoRA变体DoRA对基础模型进行指令调优。在微调时,仅计算Q/A对答案部分的损失,并采取NEFTune对嵌入添加噪声等多种策略降低过拟合风险。然后随机调整图像分辨率以及随机打乱多轮交互将示例输入模型。
评估如下表显示,Idefics2在MMMU、MathVista、TextVQA和MMBench等基准上表现出色,不仅在推理时具有更高的计算效率,在性能上超越了同类大小的视觉语言模型(LLaVA-Next、DeepSeek-VL、MM1-Chat)。
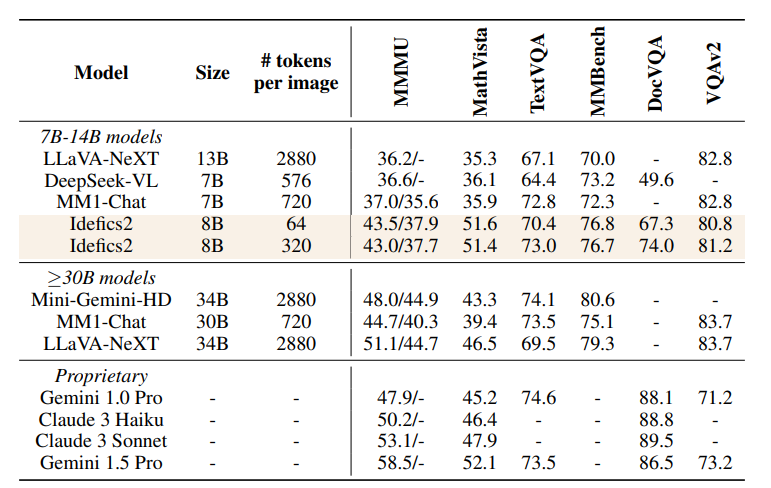
Idefics2与比自己大四倍的最先进的模型性能相当,而且在MathVista和TextVQA等基准上还可与闭源模型Gemini 1.5 Pro相媲美。
3. 对话场景优化
评估基准往往期望非常简短的答案,但人类在与模型交互时更倾向于长篇的生成。而Idefics2在精确遵循预期格式的指令时可能会遇到困难,难以把握生成回复的“长”与“短”。
因此,指令微调后,作者进一步对Idefics2进行对话数据的训练。在LLaVA-Conv和ShareGPT4V上对Idefics2进行了几百步的微调。
用户评价显示,在许多交互中,Idefics2-chatty明显优于仅经过指令微调的版本。下面是一些生成示例:
 ▲描述一个AI生成的图像
▲描述一个AI生成的图像
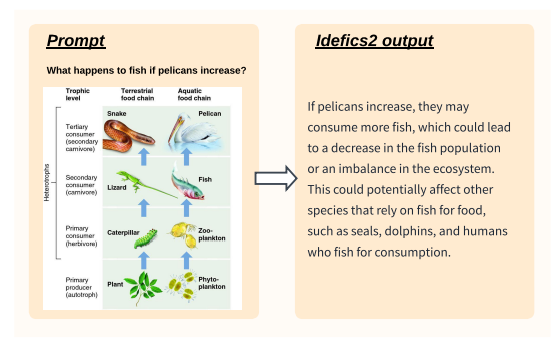 ▲根据科学图表回答问题
▲根据科学图表回答问题
结论
本文通过详尽的实验,深入探讨了构建多模态大模型时文献中常见trick的有效性,并得出了一系列有价值的结论。不仅如此,作者还亲身实践了这些有用的技巧,成功构建了一个性能卓越的8B参数视觉语言模型——Idefics2。在同等规模的模型中,Idefics2展现出了最先进的性能,并具备更高的推理效率,为多模态大模型的研究提供了重要参考。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。







![[Java基本语法] 常量变量与运算符](https://img-blog.csdnimg.cn/direct/5e9e1660a34a4a2386cc4157a6181d54.png)


