国内如何高速下载hugginging face模型
背景
如今开源大模型很多,相较于线上的调用接口,本地部署更有吸引力。这就免不了需要去Huggingface上下载模型,但因为国内管制要求,huggingface 并不能直接访问,或者下载速度很慢。这两天折腾出两条曲线方案。
现状
原先可用的镜像方式基本已经不可用。
- 对于一些主流的模型可以通过aliendao 进行加速。缺点是模型不多
- 如果你有梯子,那么可以直接下载。但几个G,甚至几十个G的模型,光是流量还是肉疼的。
曲线救国
为此采取一种曲线救国的方式(前提是你可以访问外网,主要为了节约流量):
前期准备:申请百度网盘开发者
- colab or play-with-dcoker ,话不多说,直接看代码。
- 上传百度网盘,然后国内下载。(上传速度很快)

共享机制
本着我为人人,人人为我的精神。如果你愿意分享 你的百度网盘地址,可提交 issue 在这个页面共享模型
https://github.com/kevin-meng/HuggingfaceDownloadShare/issues/1
方法一 (colab-推荐)
[colab 页面]
https://colab.research.google.com/drive/1S7E3mMsVhJlhuvtMFUalOSXl0e0YOSbt?usp=sharing
完整程序有点长放在文末。(其中解决 colab 的 符号链接(symlink)/软连接文件处理函数还是蛮有用的)
https://github.com/kevin-meng/HuggingfaceDownloadShare

方法二 (play-with-dcoker)
方法二相对麻烦些,需要在 play-with-dcoker 启动一个节点,并构建镜像,之后会得到一个 gradio 的页面。然后可以在对应窗口中填入相应的 模型id 即可。
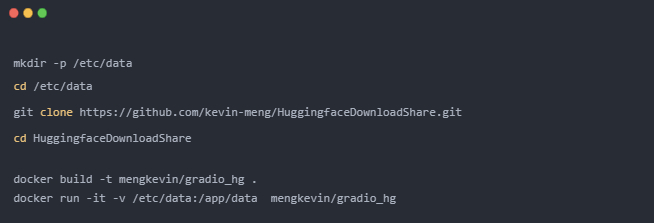
colab 完整程序
import os
import shutil
from huggingface_hub import snapshot_download
from bypy import ByPy
def copy_data(source_directory,target_directory):
# 遍历源目录中的所有文件和目录
for entry in os.listdir(source_directory):
entry_path = os.path.join(source_directory, entry)
# 检查是否为符号链接
if os.path.islink(entry_path):
# 获取符号链接的目标路径
target_path = os.readlink(entry_path)
# 构建目标路径的绝对路径
target_absolute_path = os.path.join(source_directory, target_path)
# 获取目标路径的文件名或目录名
target_basename = os.path.basename(target_absolute_path)
# 构建目标文件或目录的路径
target_entry_path = os.path.join(target_directory, entry)
# 复制目标文件或目录到目标目录
if os.path.isdir(target_absolute_path):
shutil.copytree(target_absolute_path, target_entry_path)
else:
shutil.copy2(target_absolute_path, target_entry_path)
else:
# 如果不是符号链接,直接复制到目标目录
shutil.copy2(entry_path, os.path.join(target_directory, entry))
def download(repo_id):
source_directory = snapshot_download(repo_id=repo_id,cache_dir="/app/data/",force_download =True)
print("文件路径:",source_directory)
path_name = repo_id.replace("/","---")
target_directory = f"{os.getcwd()}/download/{path_name}"
# 移动文件
os.system(f"mkdir -p {target_directory}")
os.system(f"mkdir -p {os.getcwd()}/tar/{path_name}/")
copy_data(source_directory,target_directory)
print("复制路径:",target_directory)
return target_directory
def upload_by_file(source_path):
bp = ByPy()
dest_path = source_path.split("/")[-1] # 文件名
out = bp.upload(
source_path,
dest_path )
return out
def upload_by_path(source_path,compress=True):
bp = ByPy()
# 创建目录
dest_path = source_path.split("/")[-1]
# 压缩
if compress:
print("分卷压缩....")
tar_path =f"{os.getcwd()}/tar/{dest_path}"
os.system(f"zip -s 4000M {tar_path}/{dest_path}.zip {source_path}/*")
source_path = tar_path
print("上传百度云....")
bp.mkdir(dest_path)
# 同步目录
out = bp.syncup(
source_path,
dest_path
)
return out
if __name__ == "__main__":
## 设置 repo_id
repo_id = "THUDM/chatglm2-6b-int4"
out_path = download(repo_id)
# 上传文件夹
# 如果单个文件大小小于 4G 则无需压缩
bp = ByPy()
print(bp.list())
upload_by_path(out_path,compress=True)
!rm -rf /content/download/*
!rm -rf /content/tar/*
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。