我们先进行一个整体轮廓的了解,随后在深入理解细节。
在动态库加载之前还要说一下程序的加载,因为理解了程序的加载对动态库会有更深的理解。
轮廓:
首先,不管是程序还是动态库刚开始都是在磁盘中的,想要执行对应的可执行程序或者编译都需要一个指定的路径才可以找到。他就像我们现实生活中的地址,当然这些对我们程序地址空间的影响不大,主要是因为路径太重要了,进行一下强调。
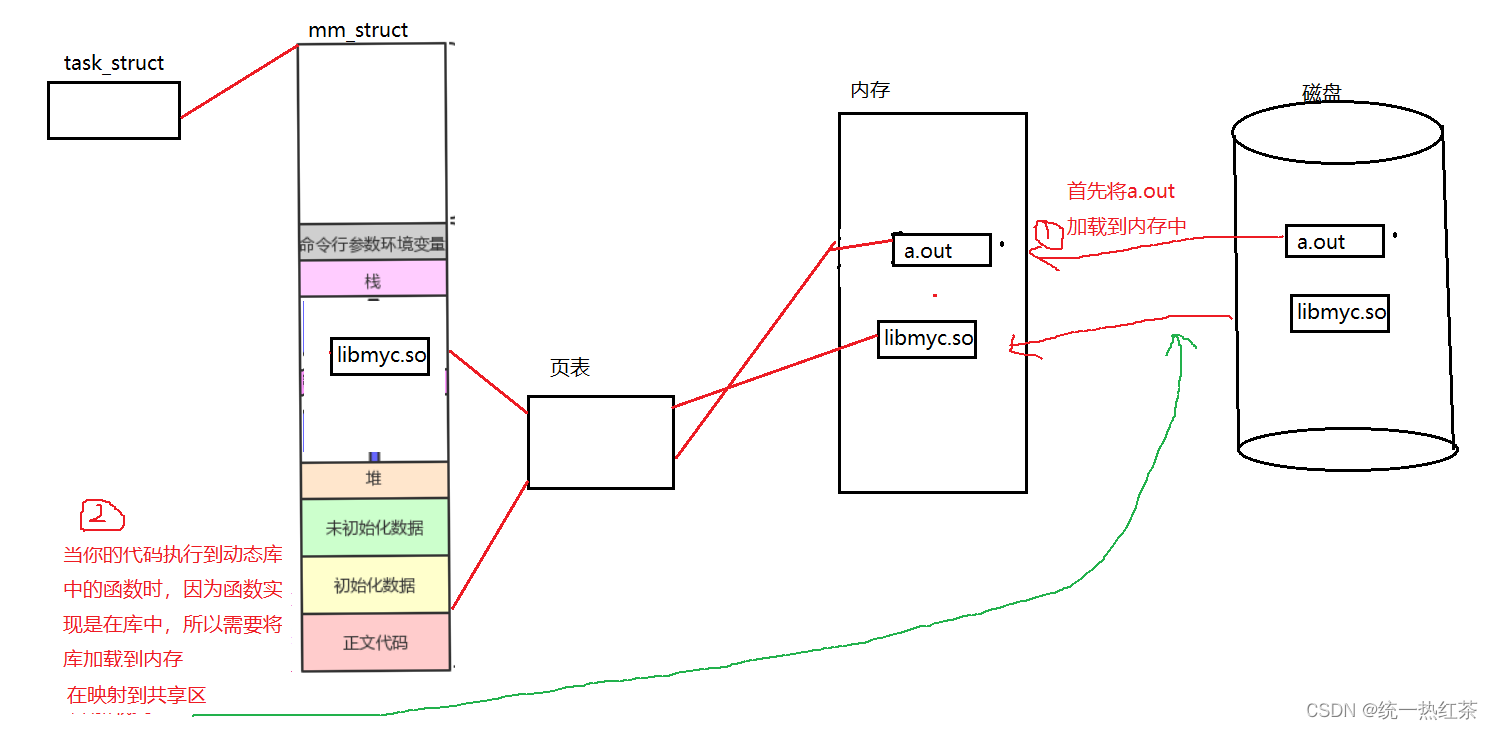
从图中可以比较清晰的看到动态库加载的简略行为,随后在执行到库函数的地方时跳转到共享区,执行完在跳转回来即可。
可是这个库只会被一个进程使用吗?
我们看到一个动态库可能会被多个进程同时使用
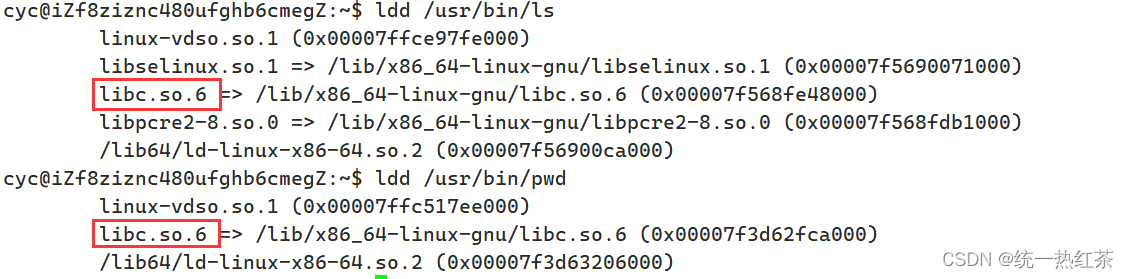
所以当我们由另外的进程时,不需要重新加载动态库了,只要用现成的,直接使用页表映射即可。因为他能被多个库同时使用,所以也叫共享库!
程序的加载:
说在前边,程序的加载需要说一大堆预备的知识,最后才能进行串起来。
我们谈这个之前先想一个问题:我们编译好的程序的二进制代码中会有“地址”吗?
我们验证一下:
对此文件进行一下objdump -S code(反汇编)
可以看到其中就已经存在一种类似地址的东西了。
同时我们进行size可以看到这个可执行程序已经分好了各种区域,类似我们mm_struct中的地址空间划分。

那我们在程序中定义的变量名也理所当然的变为了地址。
至此我们知道了可执行程序中存在地址与空间划分了
linux中生成的可执行程序格式叫做ELF。
这个二进制可执行程序有自己固定的格式,elf可执行程序的头部有着自己的属性。
另外我们的文件经过编译后,有很多的汇编语句,我们已经见到过了,这是什么地址呢?是如何进行编址?
先回答第二个问题
我们在编址时一般有两种:其一是相对编址;其二是绝对编址。
相对编址时,使用起始地址加上对应的偏移量
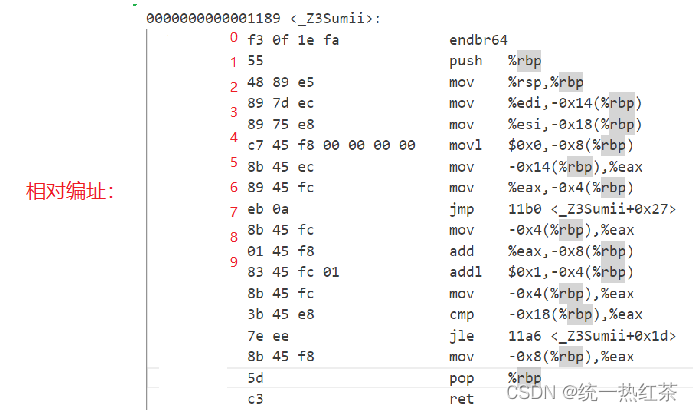
绝对编址:
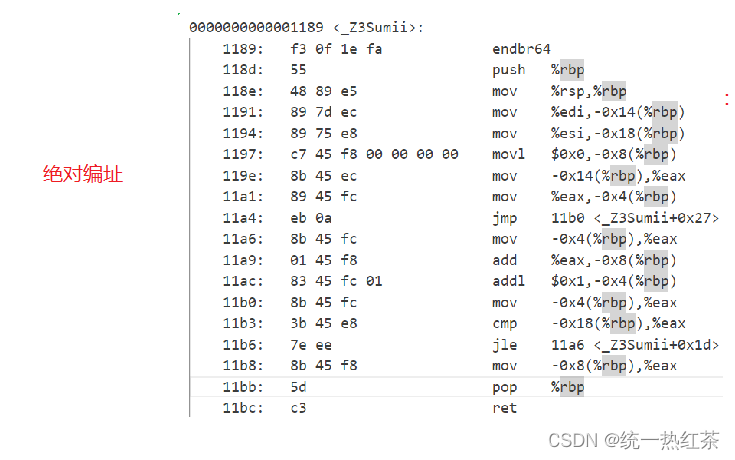
绝对编址就是我们本身的方式,也叫做平坦模式,所以整体是线性增长的。
同时我们也可以认为这其实就是虚拟地址!
所以我们的汇编程序中就已经存在虚拟地址了。
此时我们还需要设计一个东西叫做加载器:
我们会先把加载器的库加载到内存中,执行库中的方法将可执行程序拷贝到内存,加载器对可执行程序的头部进行解释。可以得到main函数的地址。
所以 ELF + 加载器 = 各个区域中的起始位置与结束位置 + main函数地址。
现在我们基本就将预备知识铺垫的差不多了。
可以进入主线了。
我们常说进程 = 内核数据结构+代码和数据。
那么当我们执行一个程序时是先创建内核数据结构还是先将文件加载到内存中呢?
我们这样想:当你被学校录取后,你是开学到了学校才是这个学校的学生还是当志愿填报结束你得到了被录取的信息才是呢?
答案是显然的,当你收到了录取通知就已经是学校的学生了。
那我们进程也是先有内核数据结构在加载程序。
那我们就要开始创建内核数据结构了。
我们的mm_struct是一个对象,其中有成员变量,变量的初始值是什么?
我们的可执行程序中就已经提供了对应的分配好了各个地址,就可以去填充了。
所以虚拟地址空间这个概念不是OS独有的,是由OS+编译器+加载器一起构成的。
我们不会提到一个没有用的事物,对于main函数的地址我们该怎么用呢?
我们的CPU中有一个PC指针,他保存的是当前执行指令的下一条虚拟地址。
在最开始的时候就是main的地址。这是很关键的一环。
所以我们要开始加载程序到内存咯。
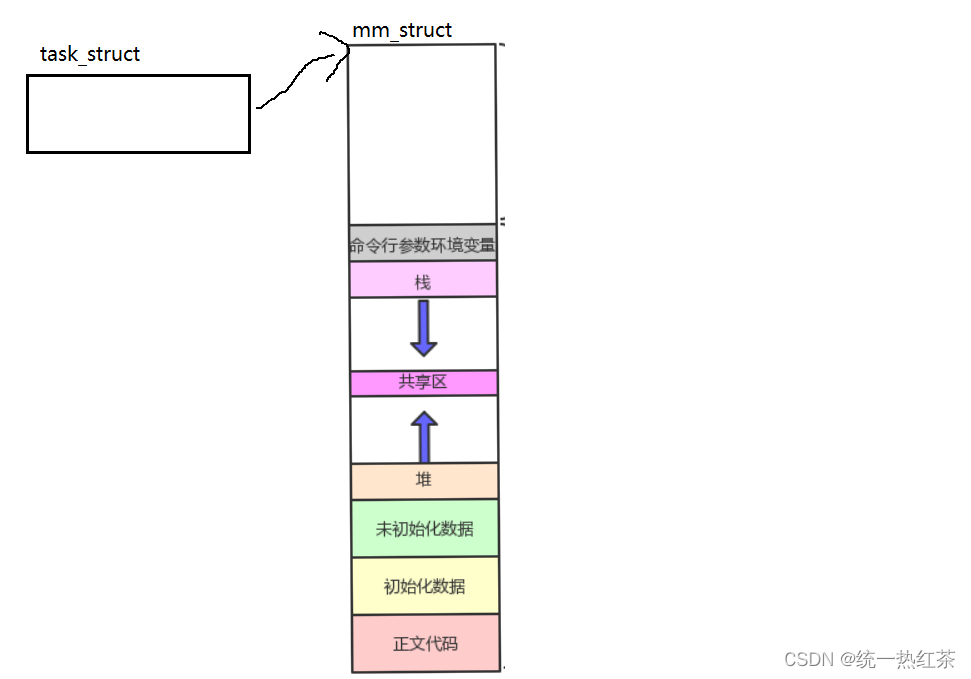
尽管我们的程序中有自己的虚拟地址,但是加载到物理内存中仍然会有属于自己的物理地址。
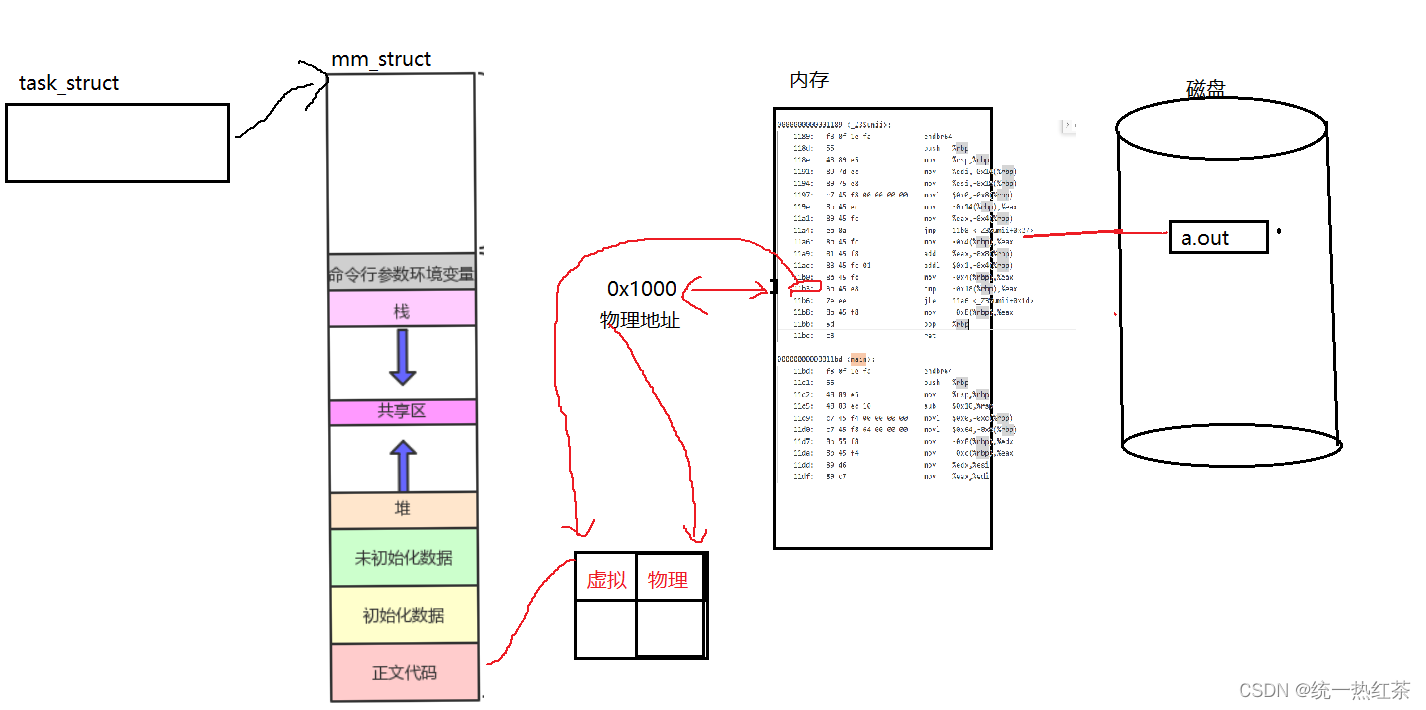
那我们现在就需要将mm_struct与内存进行连接起来,那就是页表!
我们现在开始运行!
根据PC指针的值去页表中映射对应的物理地址,拿到指令去执行,循环往复就执行起来啦!
这就是程序加载的过程。
我们只要分为两个阶段看就会好一点
- 内核数据结构的创建
- 程序的加载
还有额外的预备知识~
动态库的加载:
我们的动态库编译好之后和可执行程序基本是一样的,也有自己的地址。
,只不过没有main的地址罢了。
先来画一个图。
假设我们的代码中有一个调用库中的代码Add。
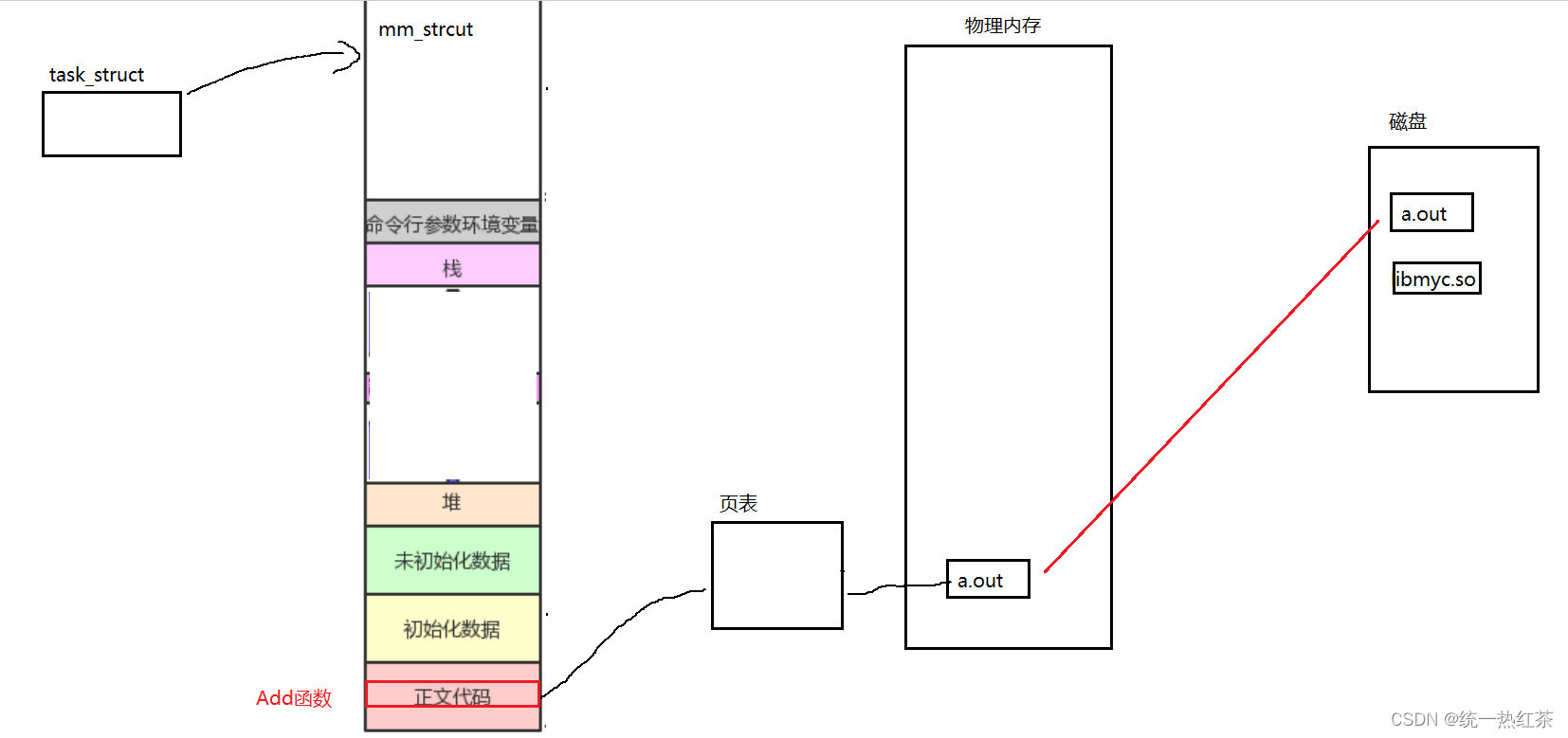
当我们执行到Add时,此时我们的动态库还没加载,那么当然就需要将动态库也加载到内存,同时映射到虚拟地址空间。
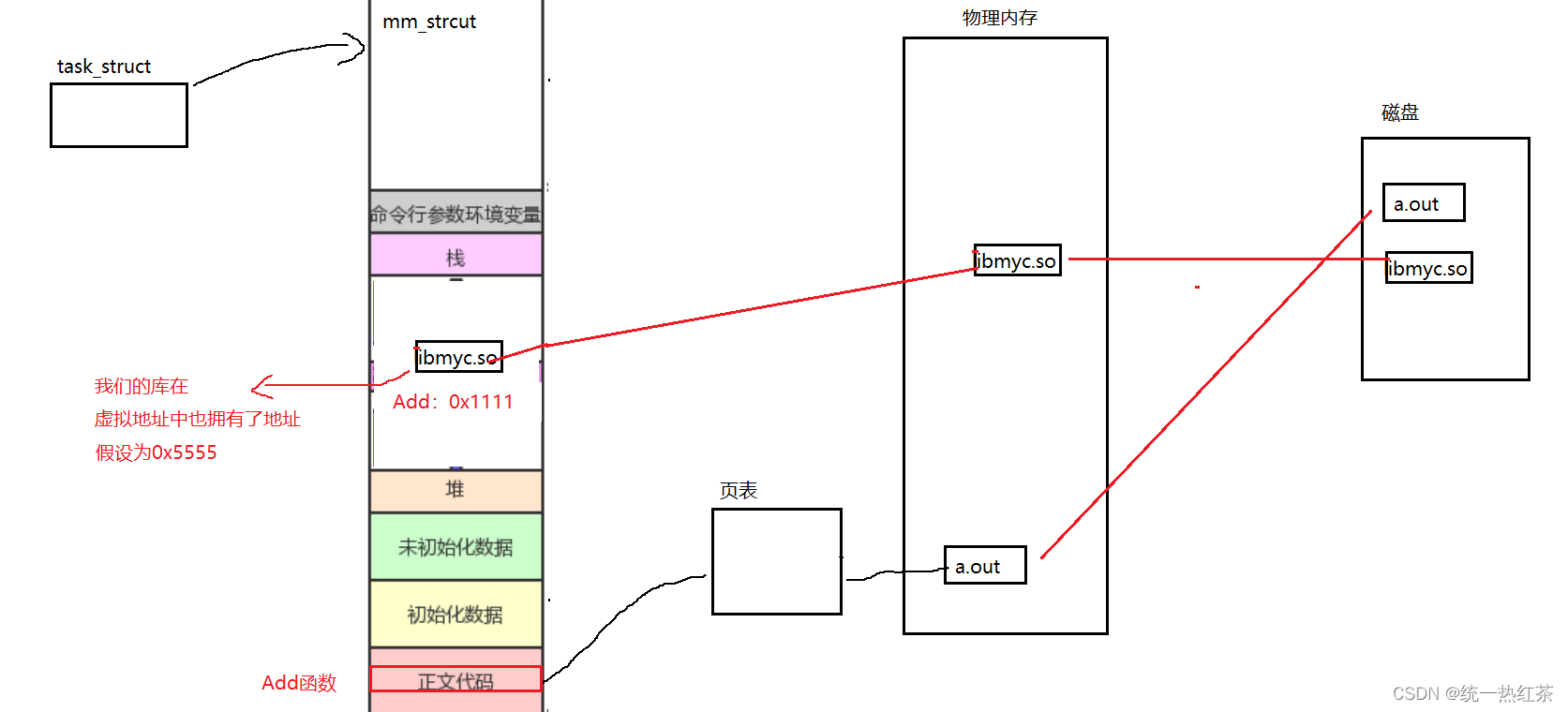
这里有一个细节,我们程序加载到内存映射到地址空间时,只有一个虚拟地址,直接就是二进制程序提供的。可是此时我们的虚拟地址有两份,一个是库中我们要调的函数的地址,一个是mm_struct中动态库的地址。
实际上库中的函数地址就是库函数地址为0的偏移量,当想要访问到库函数时,我们就需要知道他的地址,他的地址就是两者的相加:0x5555+0x1111=0x6666。
所以有了地址我们就可以动态库的函数了,也就是跳转到共享区,执行完毕再跳回来。
所以这个地址被映射到虚拟地址空间的那个位置重要吗?
并不重要,所以制作动态库时需要-fPIC,叫做与地址无关码!
可是我们加动态库时怎么知道有没有被加载?
同时动态库还要存在多份。
所以就需要管理:所以就要有对应的描述结构体与组织他的数据结构(比如链表)。
当我们加载时先遍历一遍观察是否已经加载,有的话直接映射,没有的话就加载…
到此完毕~