写文章只是为了学习总结或者工作内容备忘,不保证及时性和准确性,看到的权当个参考哈!
1. 执行Broadcast大表时,等待超时异常(awaitResult)
现象:org.apache.spark.SparkException: Exception thrown in awaitResult:
java.util.concurrent.TimeoutException: Futures timed out after [300seconds]


原因分析:当数据需要broacast到executor上时,由于数据量较大 、broacast超时导致。
解决方案:
设置spark.sql.autoBroadcastJoinThreshold=-1 不broadcast小表,直接走shuffle。(弊端:时间花费长,影响较大)
2.Task任务在写文件时,发生管道中断关闭异常ClosedByInterruptException
现象:Uncaught exception while reverting writes to file /data03/yarn/……………
java.nio.channels.ClosedByInterruptException

解决方案:查看该Task任务是否是推测执行任务,如果是属于正常现象,不影响任务。
3.DiskBlockManager 在创建本地目录失败
现象:Failed to create local dir in /data10/yarn/………….

原因分析:这个错误一般是磁盘满了或者要么是磁盘坏了。联系大数据平台运维人员。
4.SparkSQL访问HIVE表时,找不到数据库或者元数据信息
现象:org.apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'XXXX' not found;
解决方案:Step 1:查看hive的配置文件是否正确。
Step 2:在Step 1 基础上,查看是否存在该数据库。
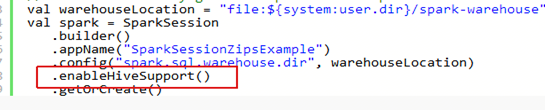
Step 3:查看SparkSession 创建方法是否启用了Hive支持。正确的创建SparkSession 如下图:
5.使用wholeTextFiles读取文件时,报非法参数异常
现象:Java.lang.IllegalArgumentException:……………..wholeTextFiles…..CharBuffer.allocation…….

原因分析:wholeTextFile不支持一次性读入大于1G的大文件,因为是将整个文件内容变成一个Text对象,而Text对象是有长度限制。
解决方案:将单个大文件分割成多个小文件读取。
6.数据倾斜
现象:为啥我有几个Task任务卡住不动已经很久了?现象如下图:

点到当前的stage Tab 中 ,效果图如下:

原因分析:典型的数据倾斜现象,所有的task都已经完成了,而正在运行的task任务超过了所有完成task时间中位数的1.5倍以上,发生了数据倾斜现象。
解决方案:1.如果是Spark sql 访问hive 表,由于上游的某个hive文件过大导致,需要避免上游的表落地时某个文件特别大。可以在sql后面添加distribute by rand() ; 并且适
当增大spark.sql.shuffle.partitions参数值。2.需要从代码和业务逻辑上去处理数据倾斜
问题。参考:https://www.cnblogs.com/hd-zg/p/6089220.html
7.TaskResultGetter在拉取block块的时候,Executor丢失,导致连接失败错误
现象:org.apache.spark.shuffle.FetchFailedException:Failed to connection………….
或者出现Executor Lost 现象。

原因分析:shuffle read的时候数据的分区数设置的很小,同时shuffle read的量很大,那么
将会导致一个task需要处理的数据非常大。结果导致JVM crash,从而导致取shuffle数据失
败,同时executor也丢失了,看到Failed to connect to host的错误,也就是executor lost的
意思。有时候即使不会导致JVM crash也会造成长时间的GC。
解决方案:
1. 减少shuffle数据:首先考虑使用map side join或是broadcast join来规避shuffle的产生。将不必要的数据在shuffle前进行过滤,比如原始数据有20个字段,只要选取需要的字段进行处理即可,将会减少一定的shuffle数据。
2. 针对于spark sql : 通过spark.sql.shuffle.partitions控制分区数,默认为40,根据shuffle的量以及计算的复杂度提高这个值。
3. 针对RDD操作:通过spark.default.parallelism控制shuffle read与reduce处理的分区数,官方建议为设置成运行任务的executor的2-3倍。
4. 提高executor的内存,通过spark.executor.memory适当提高executor的memory值。
8.Java 堆栈溢出错误
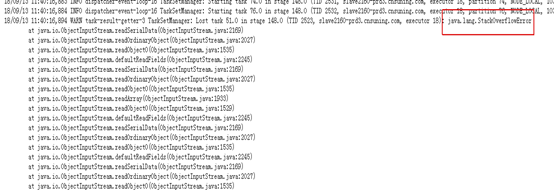
现象:Java.lang.StackOverflowError:
原因分析:
代码中有这样一段逻辑(示意):
Dataset<Row> totalDS; // 总数据集
while (循环条件) {
Dataset<Row> batchDS = // 某种业务计算过程最后得到批次结果数据集;
totalDS = totalDS.union(batchDS); // 把这批次的结果合并到最终总结果中
}
// 最后用 totalDS 再去做计算
因为循环次数比较多,大约200多次,导致最后 totalDS 的 lineage 太长,造成Spark计算时递归过深引发 StackOverflowError。
解决方案:每循环20次就checkpoint保存一下检查点,这样强制截断lineage,结果就运行完了没有出问题。
9.在代码中设置Master为local模式,实际提交模式为yarn-cluster,导致SparkContext初始化失败
现象:ERROR ApplicationMaster: SparkContext did not initialize after waiting for 100000 ms. Please check earlier log output for errors. Failing the application
解决方案:去掉setMaster("local[*]")
10.Executor由于某个正在运行的Task,由于Executor内存使用超出限制,导致Executor的Container被kill,使得Executor退出
现象:ExecutorLostFailure (executor 3 exited caused by one of the running tasks) Reason: Container killed by YARN for exceeding memory limits. 8.1 GB of 8 GB physical memory used
原因分析:不合理的使用大量的cache 和 broadcast操作,导致executor 在运行task任务时资源紧张。
解决方法:尽量避免缓存过多的RDD ,移除RDD缓存操作,增加参数spark.storage.memoryFraction和spark.yarn.executor.memoryOverhead的值。适当增加executor的数量和内存。
11.driver RPC 超时
现象:org.apache.spark.rpc.RpcTimeoutException: Cannot receive any reply in 120 seconds. This timeout is controlled by spark.rpc.askTimeout at org.apache.spark.rpc.RpcTimeout org.apache.spark.rpc.RpcTimeout.org$apache$spark$rpc$RpcTimeout$$createRpcTimeoutException(RpcTimeout.scala:48) at org.apache.spark.rpc.RpcTimeout$$anonfun$addMessageIfTimeout$1.applyOrElse(RpcTimeout.scala:63)
原因分析:导致driver RPC 超时有两个原因:
(1)executor所在的节点宕掉了。
(2)运行在executor中的任务占用较大内存,导致executor长时间GC,心跳线程无法运行,从而引起心跳超时。
引发这个问题可能是发生了数据倾斜,导致stop the world。
解决方案:若存在数据倾斜,首先解决数据倾斜问题。适当增加executor数量和内存。避免长时间的GC。
12.SparkSql使用” $”代替col(),需要导入隐式转换

现象:在scala 命令行模式 可以直接用$"column_name"的方式指定列数据, 为什么sbt 打包的时候不能这么用?还得import column,使用col("column_name")来替代?能用$ 代替 col吗,需要怎么操作?
解决方案:import spark.implicits._(导入)
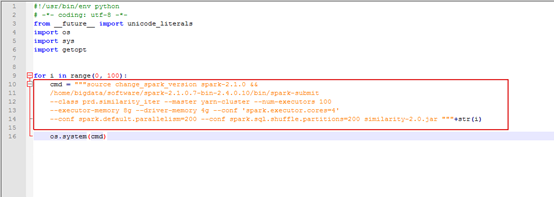
13.Python Spark 在生产线上提交任务,报错:command not find。
解决方案:请参考如下脚本:(注意spark-submit的路径)
14.提高SparkSQL在shuffle之后Task的并发度
现象:明明有很多task,但是在处理量大的时候只分配40个,如何增加Task的数量。

解决方案:适当的增加 --conf spark.sql.shuffle.partitions参数的值,注意该参数只有存在shuffle行为下才能生效。
15.由于打包冲突导致的SparkContext启动失败问题
解决方案:将spark相关依赖删掉,然后用maven命令mvn clean package重新打包。
16.在SparkSQL中,sql语句中存在着过长的计算表达式,导致GeneratedIterator超过了规定的字节数
现象:ERROR Thread-8 CodeGenerator: failed to compile: org.codehaus.janino.JaninoRuntimeException: Code of method "agg_doAggregateWithoutKey$(Lorg/apache/spark/sql/catalyst/expressions/GeneratedClass$GeneratedIterator;)V" of class "org.apache.spark.sql.catalyst.expressions.GeneratedClass$GeneratedIterator" grows beyond 64 KB. 用户代码如下图所示:

原因分析:在SQL中拼凑循环累积计算某个表达,导致GeneratedIterator超过了规定的字节数64K。
解决方案:1.优化自身的表达式代码不要过长,可以分开计算。
2.或者设置spark.sql.codegen.wholeStage=false, 不适用codegen策略。
17.Spark在执行Task任务时,发生OOM现象
现象:Java.lang.OutOfMemoryError:Java heap space
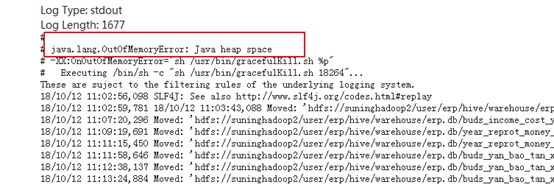
原因分析:如果处理的数据或者加载的数据很大,driver或者executor内存可能不够,出现上面的OOM错误。
解决方案:仔细查看日志,分清是driver端还是executor端OOM。先优化自身的代码,检查思考是否有必要在driver端处理大量的数据,有没有大量的cache或者broadcast操作,如果存在cache或者broadcast操作,去除该操作。适当的调大driver或者executor的内存大小。
19.在SparkSQL中,SQL语句存在大量的嵌套语句,导致Spark无法解析
现象:org.apache.spark.sql.AnalysisException: unresolved operator 'Project
解决方案:检查一下自己的sql是否嵌套太多的子查询语句,导致spark无法解析,所以需要修改sql或者改用其他方式处理;注意该语句可能在hive里面没有错误,但是在spark中会出错。
20.Task返回给driver的数据量超过了1G
现象:Total size of serialized results of 2000 tasks (2048MB) is bigger than spark.maxResultSize(1024.0 MB)
原因分析:ask返回给driver的数据量超过了规定的1G。
解决方案:设置参数spark.driver.maxResultSize=3G,参数的大小根据业务的实际情况而定 。
21.IDE日志中一直显示“ACCEPTED”,任务跑不动
现象:
原因分析:当前IDE系统的yarn队列资源暂时被占满。
解决方案:Spark阻塞在(state :ACCEPTED)状态
22.SparkSQL中小文件数过多导致任务过慢
现象:IDE日志中长时间出现如下内容:可以,如下所示:

原因分析:小文件数较多(与Spark UI中的task数目相同),长时间在重命名小文件所在目录
解决方案:SQL最上方加参数:set spark.sql.adaptive.repartition.enabled=true,并建议将中间临时表、目标表格式切换为DataSource表:Spark DataSource表推广文档







![BC153 [NOIP2010]数字统计](https://img-blog.csdnimg.cn/direct/e25f562e99004708b230f38dd900b46f.png)
![[机器学习算法]线性回归](https://img-blog.csdnimg.cn/direct/28c246f9f7f24f7da2c1fb4ce40a80f3.png)