ai目录:sheng的学习笔记-AI目录-CSDN博客
目录
集成学习
什么是集成学习
集成学习一般结构:
示意图
弱学习器
经典算法
Boosting
什么是boosting
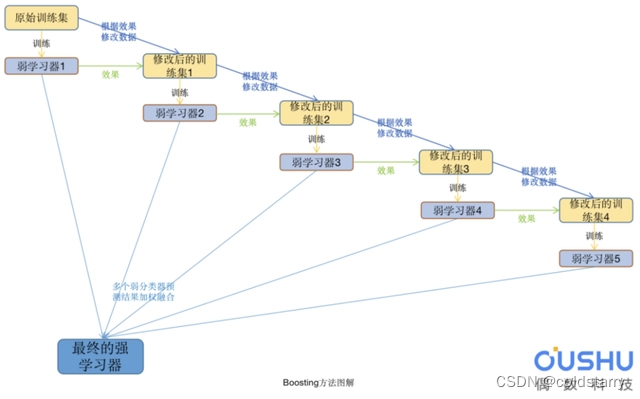
方法图
AdaBoost 算法
AdaBoost示意图
流程解析:
错误分类率error
权重
编辑
Adaboost 集成
算法
西瓜书的算法
其他资料补充算法
算法解释
编辑编辑
Bagging
算法
随机森林
bagging,boosting,随机森林的比较
bagging和boosting比较
bagging和随机森林比较
组合策略
平均法
投票法
学习法
多样性增强
数据样本扰动
输入属性扰动
输出表示扰动
算法参数扰动
参考文章
集成学习
什么是集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,有时也被称为多分类器系统(multi-classifier system)、基于委员会的学习(committee-based learning)等
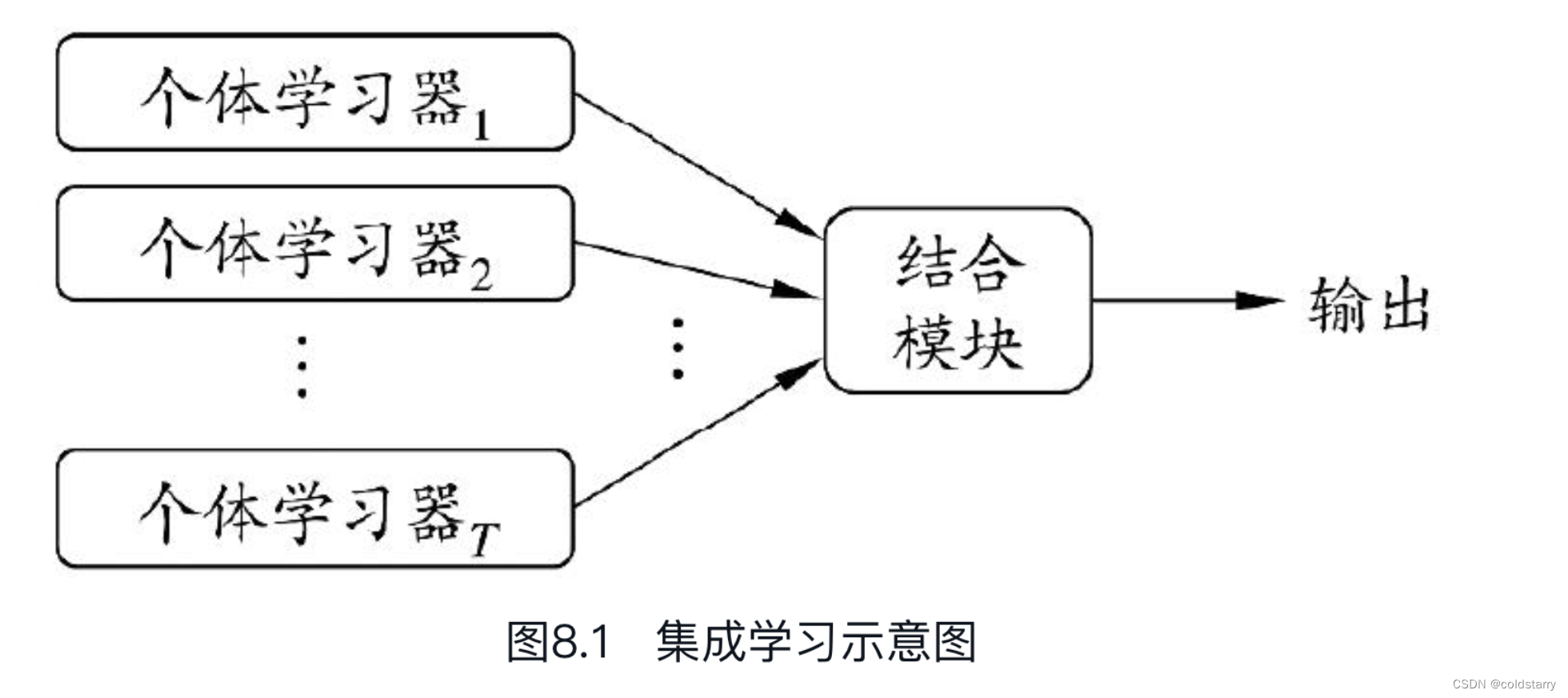
集成学习一般结构:
先产生一组“个体学习器”(individual learner),再用某种策略将它们结合起来。个体学习器通常由一个现有的学习算法从训练数据产生,例如C4.5决策树算法、BP神经网络算法等,此时集成中只包含同种类型的个体学习器,例如“决策树集成”中全是决策树,“神经网络集成”中全是神经网络,这样的集成是“同质”的(homogeneous)。同质集成中的个体学习器亦称“基学习器”(base learner),相应的学习算法称为“基学习算法”(base learning algorithm)。集成也可包含不同类型的个体学习器,例如同时包含决策树和神经网络,这样的集成是“异质”的(heterogenous)。异质集成中的个体学习器由不同的学习算法生成,这时就不再有基学习算法;相应的,个体学习器一般不称为基学习器,常称为“组件学习器”(component learner)或直接称为个体学习器
示意图
弱学习器
弱学习器常指泛化性能略优于随机猜测的学习器;例如在二分类问题上精度略高于50%的分类器。
集成学习通过将多个学习器进行结合,常可获得比单一学习器显著优越的泛化性能。这对“弱学习器”(weak learner)尤为明显,因此集成学习的很多理论研究都是针对弱学习器进行的,而基学习器有时也被直接称为弱学习器。但需注意的是,虽然从理论上来说使用弱学习器集成足以获得好的性能,但在实践中出于种种考虑,例如希望使用较少的个体学习器,或是重用关于常见学习器的一些经验等,人们往往会使用比较强的学习器。
要获得好的集成,个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”(diversity),即学习器间具有差异。
基学习器的误差相互独立。在现实任务中,个体学习器是为解决同一个问题训练出来的,它们显然不可能相互独立!事实上,个体学习器的“准确性”和“多样性”本身就存在冲突。一般的,准确性很高之后,要增加多样性就需牺牲准确性。事实上,如何产生并结合“好而不同”的个体学习器,恰是集成学习研究的核心
根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器间存在强依赖关系、必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表是Boosting,后者的代表是Bagging和“随机森林”(Random Forest)
经典算法
Boosting
什么是boosting
Boosting是一族可将弱学习器提升为强学习器的算法。
在分类问题中,它通过改变训练样本的权重学习多个分类器,并将这些分类器们进行线性组合来提高分类的能力。
通过从训练数据构建模型,然后创建第二个模型来尝试纠正第一个模型中的错误来完成的。添加模型直到完美预测训练集或添加最大数量的模型。提升学习的每一步产生弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型的生成都是依据损失函数的梯度方式,就称为梯度提升
Boosting指的是通过结合粗略和适度不准确的经验法则来产生非常准确的预测规则的一般问题。
提升学习技术的意义:如果一个问题存在弱预测模型,那么可以通过提升技术的方法得到一个强预测模型
Boosting族算法最著名的代表是AdaBoost
常见 算法:
-
AdaBoost
-
Gradient Boosting(GBDT)
-
XGboost
方法图
AdaBoost 算法
AdaBoost的核心就是求当前分类器的权重和更新样本的误差。它可以用于提高任何机器学习算法的性能。最好与弱学习器一起使用。
这意味着难以分类的样本会收到越来越大的权重,直到算法识别出正确分类这些样本的模型。
与AdaBoost一起使用的最合适也是最常见的算法是具有一层的决策树。因为这些树很短,并且只包含一个用于分类的决策,所以它们通常被称为决策树桩。
AdaBoost示意图
训练数据集中的每个实例都被加权。初始权重设置为:Weight(Xi) = 1/N
其中Xi是第i个训练实例,N是训练实例的总数。(训练实例:即用于训练模型的样本数据)
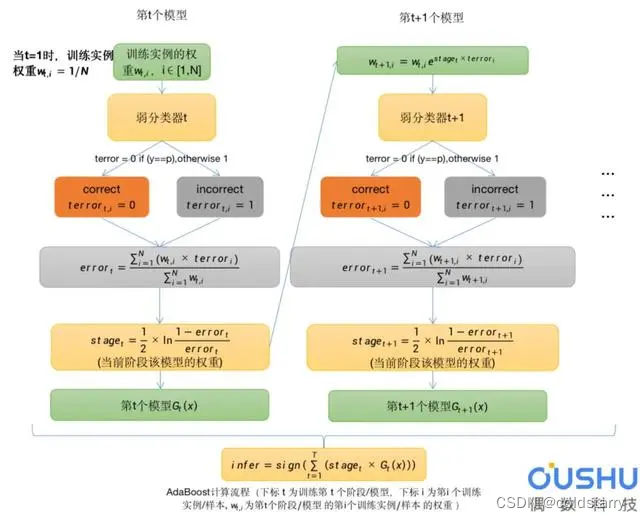
流程解析:
错误分类率error
每个实例都有自己独立的权重w,通常我们会对w进行归一化,使得w之和sum(w)=1。
使用加权之后的样本作为训练数据,以弱分类器(决策树桩)进行训练。仅支持二元(两类)分类问题,因此每个决策树桩对一个输入变量做出一个决策,并为第一类或第二类输出+1或-1值。
为训练后的模型计算错误分类率。传统的计算方式如下:
其中error是误分类率,correct是模型正确预测的训练实例数,N是训练实例总数。例如,如果模型正确预测了100个训练实例中的68个,则错误率或误分类率为(100-68)/100或0.32 。
将以上方式修改为加权训练实例:

这是误分类率的加权和,w是训练实例i的权重,terror是训练实例i的预测误差,terror为1时是误分类,为0时是正确分类,sum是对N个实例的求和
例如,如果我们有三个训练实例,权重分别为0.01、0.5和0.2.预测值为-1、-1和-1,实例中的真实输出变量为-1、1和-1,则terror为0、1和0。误分类率将计算为:
error = (0.01*0 + 0.5*1 + 0.2*0)/(0.01+0.5+0.2) = 0.704
权重
为经过训练的模型计算阶段权值,该值为模型做出的任何预测提供权重。训练模型的阶段值计算如下:
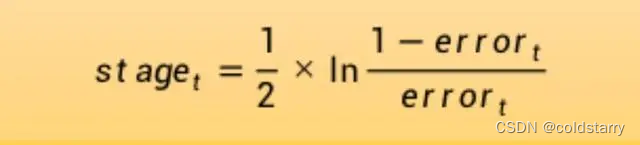
其中stage是用于对模型的预测进行加权的阶段值,即当前阶段模型的权重,ln()是自然对数,error是模型的误分类率。阶段权重stage的作用是,更准确的模型对最终预测的权重贡献更大
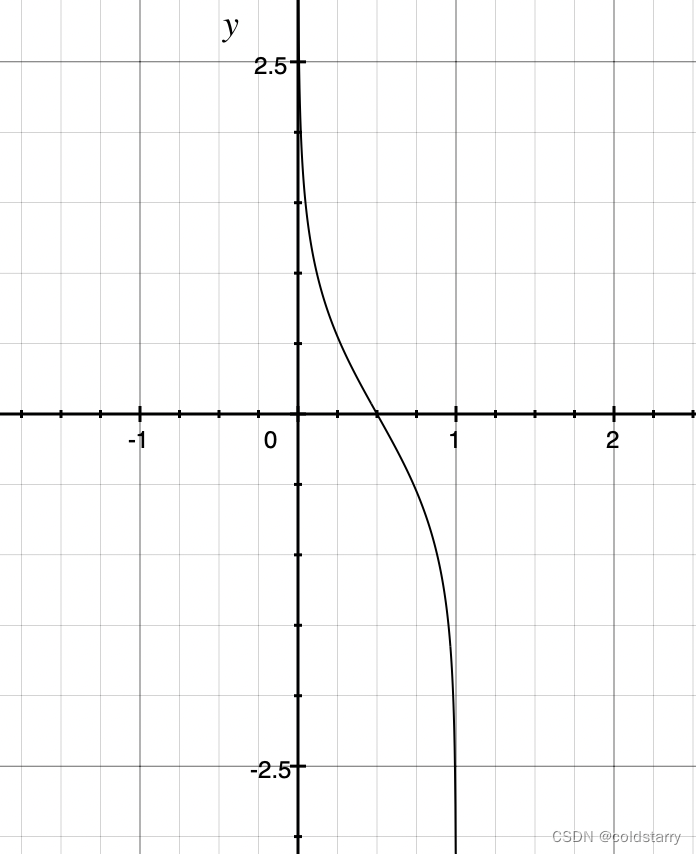
stage的图像如下:横轴是error,纵轴是stage,小于0.5值为正,大于0.5值为负

其中w是特定训练实例的权重,e是数值常数,stage是弱分类器的误分类率,terror是弱分类器预测输出变量的错误训练实例,评估为: terror = 0 if (y==p), otherwise 1
e的x方的图像如下

其中y是训练实例的输出变量,p是弱学习器的预测结果。
如果训练实例被正确分类,则权重不发生改变,如果被错误分类,则增大权重
Adaboost 集成
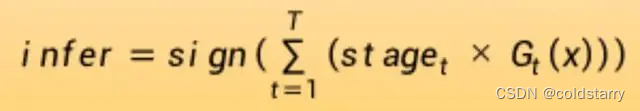

算法
西瓜书的算法
西瓜书的算法,解释的比较隐晦,大概看看


其他资料补充算法


算法解释
其中exp就是e的指数,图像上面有对于w的计算,如果正确分类样本,变量取-a,值会很少,如果错误分类样本,变量取a,exp(a)值会大


从偏差-方差分解的角度看,Boosting主要关注降低偏差,因此Boosting能基于泛化性能相当弱的学习器构建出很强的集成。我们以决策树桩为基学习器,在表4.5的西瓜数据集3.0α上运行AdaBoost算法,不同规模(size)的集成及其基学习器所对应的分类边界如图8.4所示

Bagging
欲得到泛化性能强的集成,集成中的个体学习器应尽可能相互独立;虽然“独立”在现实任务中无法做到,但可以设法使基学习器尽可能具有较大的差异。给定一个训练数据集,一种可能的做法是对训练样本进行采样,产生出若干个不同的子集,再从每个数据子集中训练出一个基学习器。这样,由于训练数据不同,我们获得的基学习器可望具有比较大的差异。然而,为获得好的集成,我们同时还希望个体学习器不能太差。如果采样出的每个子集都完全不同,则每个基学习器只用到了一小部分训练数据,甚至不足以进行有效学习,这显然无法确保产生出比较好的基学习器

算法

随机森林
随机森林(Random Forest,简称RF)是Bagging的一个扩展变体。
RF在以决策树为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。
具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。
这里的参数k控制了随机性的引入程度:若令k=d,则基决策树的构建与传统决策树相同;若令k=1,则是随机选择一个属性用于划分;一般情况下,推荐值k=log2d。
随机森林的收敛性与Bagging相似。随机森林的起始性能往往相对较差,特别是在集成中只包含一个基学习器时。
因为通过引入属性扰动,随机森林中个体学习器的性能往往有所降低。然而,随着个体学习器数目的增加,随机森林通常会收敛到更低的泛化误差。值得一提的是,随机森林的训练效率常优于Bagging,因为在个体决策树的构建过程中,Bagging使用的是“确定型”决策树,在选择划分属性时要对结点的所有属性进行考察,而随机森林使用的“随机型”决策树则只需考察一个属性子集。
bagging,boosting,随机森林的比较
bagging和boosting比较

bagging和随机森林比较

组合策略
学习器结合可能会从三个方面带来好处
- 从统计的方面来看,由于学习任务的假设空间往往很大,可能有多个假设在训练集上达到同等性能,此时若使用单学习器可能因误选而导致泛化性能不佳,结合多个学习器则会减小这一风险;
- 从计算的方面来看,学习算法往往会陷入局部极小,有的局部极小点所对应的泛化性能可能很糟糕,而通过多次运行之后进行结合,可降低陷入糟糕局部极小点的风险;
- 从表示的方面来看,某些学习任务的真实假设可能不在当前学习算法所考虑的假设空间中,此时若使用单学习器则肯定无效,而通过结合多个学习器,由于相应的假设空间有所扩大,有可能学得更好的近似
平均法

必须使用非负权重才能确保集成性能优于单一最佳个体学习器,因此在集成学习中一般对学习器的权重施以非负约束。
加权平均法的权重一般是从训练数据中学习而得,现实任务中的训练样本通常不充分或存在噪声,这将使得学出的权重不完全可靠。尤其是对规模比较大的集成来说,要学习的权重比较多,较容易导致过拟合。
因此,实验和应用均显示出,加权平均法未必一定优于简单平均法。一般而言,在个体学习器性能相差较大时宜使用加权平均法,而在个体学习器性能相近时宜使用简单平均法。
投票法
投票法通常用于分类任务中

不同类型预测值不能混用

学习法



多样性增强
欲构建泛化能力强的集成,个体学习器应“好而不同”:个体学习器准确性越高、多样性越大,则集成越好
常见做法主要是对数据样本、输入属性、输出表示、算法参数进行扰动。
数据样本扰动
给定初始数据集,可从中产生出不同的数据子集,再利用不同的数据子集训练出不同的个体学习器。数据样本扰动通常是基于采样法,例如在Bagging中使用自助采样,在AdaBoost中使用序列采样。此类做法简单高效,使用最广。对很多常见的基学习器,例如决策树、神经网络等,训练样本稍加变化就会导致学习器有显著变动,数据样本扰动法对这样的“不稳定基学习器”很有效;然而,有一些基学习器对数据样本的扰动不敏感,例如线性学习器、支持向量机、朴素贝叶斯、k近邻学习器等,这样的基学习器称为稳定基学习器(stable base learner),对此类基学习器进行集成往往需使用输入属性扰动等其他机制
输入属性扰动
子空间一般指从初始的高维属性空间投影产生的低维属性空间,描述低维空间的属性是通过初始属性投影变换而得,未必是初始属性
d′小于初始属性数d。Ft包含d'个随机选取的属性,Dt仅保留Ft中的属性。
训练样本通常由一组属性描述,不同的“子空间”(subspace,即属性子集)提供了观察数据的不同视角。显然,从不同子空间训练出的个体学习器必然有所不同。著名的随机子空间(random subspace)算法]就依赖于输入属性扰动,该算法从初始属性集中抽取出若干个属性子集,再基于每个属性子集训练一个基学习器,算法描述如图8.11所示。对包含大量冗余属性的数据,在子空间中训练个体学习器不仅能产生多样性大的个体,还会因属性数的减少而大幅节省时间开销,同时,由于冗余属性多,减少一些属性后训练出的个体学习器也不至于太差。若数据只包含少量属性,或者冗余属性很少,则不宜使用输入属性扰动法。
输出表示扰动
此类做法的基本思路是对输出表示进行操纵以增强多样性。可对训练样本的类标记稍作变动,如“翻转法”(Flipping Output)随机改变一些训练样本的标记;也可对输出表示进行转化,如“输出调制法”(Output Smearing)将分类输出转化为回归输出后构建个体学习器;还可将原任务拆解为多个可同时求解的子任务,如ECOC法利用纠错输出码将多分类任务拆解为一系列二分类任务来训练基学习器。
算法参数扰动
基学习算法一般都有参数需进行设置,例如神经网络的隐层神经元数、初始连接权值等,通过随机设置不同的参数,往往可产生差别较大的个体学习器。
例如“负相关法”(Negative Correlation)显式地通过正则化项来强制个体神经网络使用不同的参数。对参数较少的算法,可通过将其学习过程中某些环节用其他类似方式代替,从而达到扰动的目的,例如可将决策树使用的属性选择机制替换成其他的属性选择机制。值得指出的是,使用单一学习器时通常需使用交叉验证等方法来确定参数值,这事实上已使用了不同参数训练出多个学习器,只不过最终仅选择其中一个学习器进行使用,而集成学习则相当于把这些学习器都利用起来;由此也可看出,集成学习技术的实际计算开销并不比使用单一学习器大很多
参考文章
机器学习 作者:周志华
https://baijiahao.baidu.com/s?id=1714358199247317942&wfr=spider&for=pc
6.集成学习 - 二、 Boosting - 《AI算法工程师手册》 - 书栈网 · BookStack