介绍
据报道,仓鼠、狼、黑猩猩和蝙蝠等智能动物可以学习环境地图,并选择适当的行动路径。
因此,机器人自我定位和绘制环境地图以实现智能行为被认为是非常重要的。
另一方面,如果通过机器学习(如神经网络)来解决一项任务,使其朝着某个目标前进,则无需任何明确的映射机制就能成功实现目标。
这一机制尚未被人们所了解,而了解这一机制具有重要的学术意义和现实意义。
因此,本文将研究映射机制是否是一种新出现的现象。
本文的新颖之处在于,它关注的是在非常严格的盲目条件下,人工智能是否可以通过简单的奖励来自然学习地图(地图出现),并提出了多种有效的实验来阐明这一点。本文的研究结果包括
- 出色的行动规划能力:在新环境中出色地实现目标(成功率约为 95%)。
- 使用长期记忆:在一次发作中记忆约 1 000 步过去的经历
- 智能行为的表现:学习捷径。
- 环境地图和碰撞检测神经元的表达:人工智能学习到的内部表征暗示了环境地图和碰撞检测神经元。
- 选择性、任务依赖性地图:忘记探索性迂回路线
论文地址:https://arxiv.org/abs/2301.13261
卓越的行动规划能力
我们使用一座真实房屋的三维复制品来评估人工智能行动规划任务的性能。一个直径 0.2 米、高 1.5 米的圆柱体被视为人工智能的物理实体,并被模拟在仿真房屋内移动。
解决问题
每一集,人工智能的环境都是随机初始化的。目标点为(xg、yg、zg);人工智能可以执行四个动作:向前移动 0.25 米、左转 10°、右转 10°,并宣布已达到目标。设定最多允许 2000 个动作。
图 1 是人工智能行动环境的一个示例。图 1 中的蓝色立方体是起点,红色立方体是目标点。为了检验人工智能的泛化能力而非记忆力,我们对人工智能在从未见过的环境中达到目标的能力进行了评估。
人工智能会得到与目标的相对位置(Δx、Δy、Δz)和目标的相对方向(Δθ)。这可以说是给了鼹鼠一个全球定位系统和指南针。虽然鼹鼠是一种盲目的动物,但据说它能够通过整合自己走过的路径和捕捉地球磁场来确定自己的位置,这与给它一个全球定位系统和指南针类似。

图 1.行动计划任务。
在这种情况下,设定了两个评估指标来评估行动规划能力。一个是 “成功”,如果人工智能能宣布在距离目标 0.2 米以内到达目标,即为成功。另一个是 “最短路径长度(SPL)”。这一指标表明,通往成功的路径越短,行动的效率就越高。
人工智能算法
人工智能行为是根据长短期记忆(LSTM)模型确定的。在这里,目标位置(xg, yg, zg)、与目标的相对位置(Δx,Δy, Δz)、目标方向 Δθ和与目标的接近指数 min(||(xg,yg,zg)-(Δx,Δy, Δz)||,0.5)被作为 LSTM 的输入。每种行为都被映射到 32 维,并与前一种行为的 32 维嵌入连接起来,形成 160 维的 LSTM 输入;LSTM 的输出被馈送到全耦合层,该层输出行为空间分布和价值函数的估计值。该 LSTM 的模型参数通过强化学习 PPO(近端策略优化)进行优化。此时的奖励就是朝着目标前进。
评估结果
与之相比,受昆虫启发的行动规划算法 “虫虫”(Bug)是一种沿着目标方向基本直线前进的算法,当它碰到墙壁时,就会沿着墙壁前进。
当沿着墙壁前进时,可以选择向左或向右前进,此时,总是向右的 "总是向右的虫子 "和总是向左的 "总是向左的虫子 "都会被评估。此外,作为一种理想的虫虫算法,虫虫会根据情况选择向左或向右前进,以尽量缩短与目标的距离,这种情况被评估为 Clarivoyant 虫虫算法(虫虫不可能学会走哪条路,但我们正在研究如果可能的话的性能)。
图 2 举例说明了 “永远向右的虫子”(黑底白字)、“永远向左的虫子”(橙色)、“好奇的虫子”(浅蓝色)和人工智能(特工,蓝色)的行动路径比较。

图 2.不同方法下的不同行为路径。
从这个例子可以看出,虽然出现条纹的路径是千里眼虫的路径,但千里眼虫到达目标的效率非常高,因为这些路径与 "虫虫向右 "和 "虫虫向左 "的路径重叠。在 "只向左 "或 “只向右”( )的情况下,有些路径在到达目标时会出现绕远路的情况。另一方面,拟议的人工智能(Agent)显示,它能够选择相对平滑的路线。
表 1 显示了与人工智能(视觉)相比的性能,后者拥有深度传感器,可被视为具有视觉。

表 1.与视力正常的人工智能的比较(视力正常)
与视力正常的人工智能(视力正常)相比,拟议的盲人人工智能(盲人)虽然不如千里眼虫,但到达目标的成功率(成功)更高,到达目标的路径长度(SPL)更短。
使用长期记忆
我们研究了人工智能如何利用内存。具体来说,我们研究了记忆长度与性能指标之间的关系,以确定它是在利用短期记忆(关于碰撞是否发生在最近一步的信息)还是长期记忆(关于碰撞是否发生在几百步之前的信息)。
图 3 显示了内存长度与性能指标之间的关系,通过对 LSTM 进行精心设计,使其无法利用之前步骤的信息,对性能指标进行了评估。
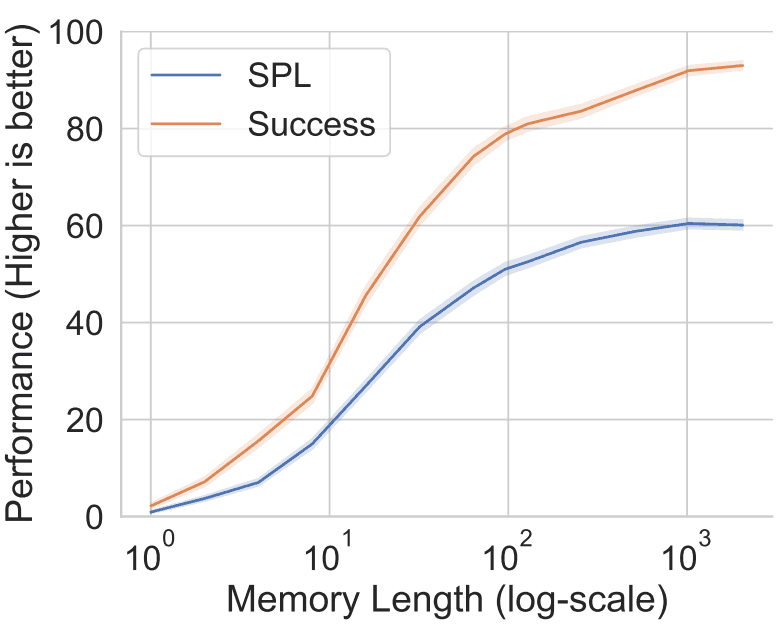
图 3:内存长度与性能指标之间的关系。
两个评估指标 SPL 和 Success 的性能在内存长度达到约 1000 步时才达到饱和。这说明,所提出的人工智能可以通过利用长期内存来提高性能。
智能行为的体现
为了研究人工智能能记住哪些信息,我们进行了一次探测实验。在这个实验中,人工智能被要求规划从图 4 中绿色球体所代表的起点到红色球体所代表的目标点的行动,然后从起点再次瞄准目标点,同时继承已达到目标的人工智能的记忆。

图 4:探针实验。
结果显示,人工智能走的第一条路径是蓝色路径所指示的路径,但当它再次尝试从起点到达目标时,它走的是紫色路径。这说明它可以走捷径。虽然人工智能应该是盲目的,但它却像盲人一样选择了一条路径。
环境地图和碰撞检测神经元的表达。
如果人工智能能根据其学习到的神经元对障碍物的存在与否进行分类,那么它就能得到一张环境地图(相当于地图,因为没有障碍物的路线就是可通行的路线,而这里的地图显示的是可通行的路线)。根据障碍物的存在预测并从人工智能记忆中提取的环境地图如图 5 所示。
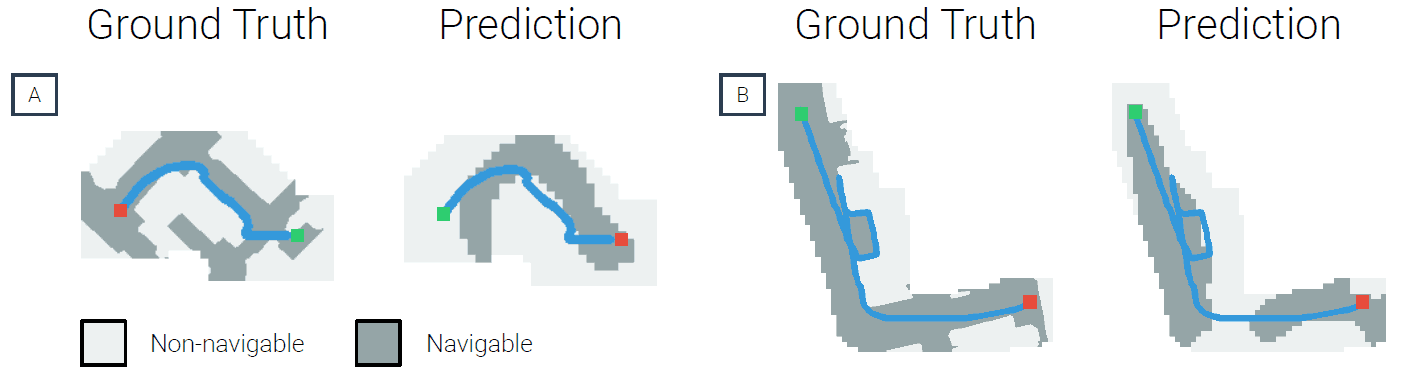
图 5:正确和预测的障碍物存在/不存在情况
图 5 显示了 A 和 B 两个示例,其中正确答案(地面实况)和预测结果(预测)基本相似。
接下来,我们研究了碰撞在人工智能内部表示(LSTM 神经元)中的结构:使用人工智能训练过的神经元作为特征,我们重新训练了一个稀疏线性分类器来分类碰撞是否存在,并提取了 10 个对碰撞分类影响较大的神经元。然后,我们使用 t-SNE 将其低维化到二维特征空间,并对行为进行聚类,结果如图 6 所示。

图 6:人工智能对碰撞的内部表示聚类
颜色表示碰撞或未碰撞,绿色表示未碰撞,红色表示碰撞。箭头表示前一个动作,前进表示前进,右转表示右转,左转表示左转。聚类的结果是 “前进-无碰撞”、"前进-碰撞 "和 “转弯-无碰撞”(2 个聚类)。数字和相应图像代表场景。
向前-向前-碰撞神经元群和向前-向前-无碰撞神经元群的产生表明,检测向前运动是否发生碰撞的神经元已经得到表达。
选择性、任务依赖性地图
人工智能的记忆力有限,这表明它会记住重要信息而遗忘不必要的信息;为了研究人工智能记住了哪些信息,我们调查了人工智能能否从其记忆中预测过去的位置。 具体来说,我们训练了一个网络,让它根据当前 LSTM 的输出预测过去的位置,并检查预测误差。预测误差越大,说明位置记忆越好。
图 7显示了对过去位置的预测误差(误差越小,对过去位置的记忆效果越好)。

图 7.对过去位置的预测误差因路线而异(误差越小,对过去位置的记忆效果越好)。
横轴为过去的步数,纵轴为预测误差。线的颜色表示过去位置的分类(哪种路径)。绿色(出口)是指包含在循环路径(循环出口)最后 10%步数中的位置,橙色(偏离)是指包含在循环路径(人们将其归类为绕一圈后返回原位的路径)中的位置。蓝色(Non-Excursion)为非循环路径中的位置。
基本上,预测误差会随着时间的推移而增大,但预测误差ogisa因路径而异。包含在循环路径中的地点的预测误差较大,而包含在非循环路径中的地点的预测误差较小。
循环路径可以被视为迂回路径,因为它们可以被视为迂回路径,但很明显,人工智能会忘记这些路径,而很好地记住那些不会忘记的路径。
另一方面,属于循环的一部分但退出循环的路径预测误差较小,这可以解释为记忆路径是避免再次进入同一循环的地标。
结论
本文介绍的论文表明,当一个盲人人工智能接近目标时会得到奖励,并被要求完成一项任务,该任务要求盲人人工智能从头到尾规划一条路线并采取行动,盲人人工智能学会了绘制环境地图。
他们能很好地利用自己的长期记忆,如果能到达目标就能选择捷径,只记住和忘记迂回路线的地标,能发现碰撞,学会沿着墙壁移动,表现出惊人的到达目标的能力,而不会让他们觉得自己是盲人。
虽然这不是一篇提出新算法的论文,但它设计了认知科学家和人工智能研究人员都感兴趣的问题,巧妙地进行了实验来回答这个问题,并对实验进行了清晰的描述,这些都被认为是优秀论文。
这篇论文在结构上很独特,有一系列有趣的标题,就像一篇通俗文章,这在一般论文中是没有的。附录中具体介绍了详细的实验装置,在明确描述技术细节的同时,突出了问题的答案。
国际人工智能大会(ICLR)是顶级人工智能大会之一,它先入为主地认为,通过数学理论和新颖高效的技术进行理解将受到高度重视,但看到通过本文介绍的论文等方法对行为学习的科学理解受到高度重视,我们可能会在未来看到更多对人类和动物的科学理解。基于人工智能的研究可能会促进这方面的发展。









![【YOLOv10改进[注意力]】使用注意力MLCA改进C2f + 含全部代码和详细修改方式 + 手撕结构图](https://img-blog.csdnimg.cn/direct/72fdccaa605c4bb88d16bd92bde4bee4.png)