【Pandas驯化-06】一文搞懂Dataframe中的索引stack、unstack问题
本次修炼方法请往下查看

🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地!
🎇 相关内容文档获取 微信公众号
🎇 相关内容视频讲解 B站
🎓 博主简介:AI算法驯化师,混迹多个大厂搜索、推荐、广告、数据分析、数据挖掘岗位 个人申请专利40+,熟练掌握机器、深度学习等各类应用算法原理和项目实战经验。
🔧 技术专长: 在机器学习、搜索、广告、推荐、CV、NLP、多模态、数据分析等算法相关领域有丰富的项目实战经验。已累计为求职、科研、学习等需求提供近千次有偿|无偿定制化服务,助力多位小伙伴在学习、求职、工作上少走弯路、提高效率,近一年好评率100% 。
📝 博客风采: 积极分享关于机器学习、深度学习、数据分析、NLP、PyTorch、Python、Linux、工作、项目总结相关的实用内容。
🌵文章目录🌵
- 🎯 1. 基本介绍
- 💡 2. 使用方法
- 2.1 stack函数使用
- 2.2 unstack函数使用
- 🔍 3. 高阶用法
- 3.1 特征工程中的trick
- 3.1 fillna函数进行数据填充
- 🔍 4. 注意事项
- 🔧 5. 总结
下滑查看解决方法
🎯 1. 基本介绍
在Pandas中,DataFrame 是一种非常灵活的数据结构,它允许我们以表格的形式存储和操作数据。stack 和 unstack 是两个用于操作多级索引(multi-index,也称为层次化索引)的函数,它们可以帮助我们重塑数据的形状,以适应不同的分析需求。
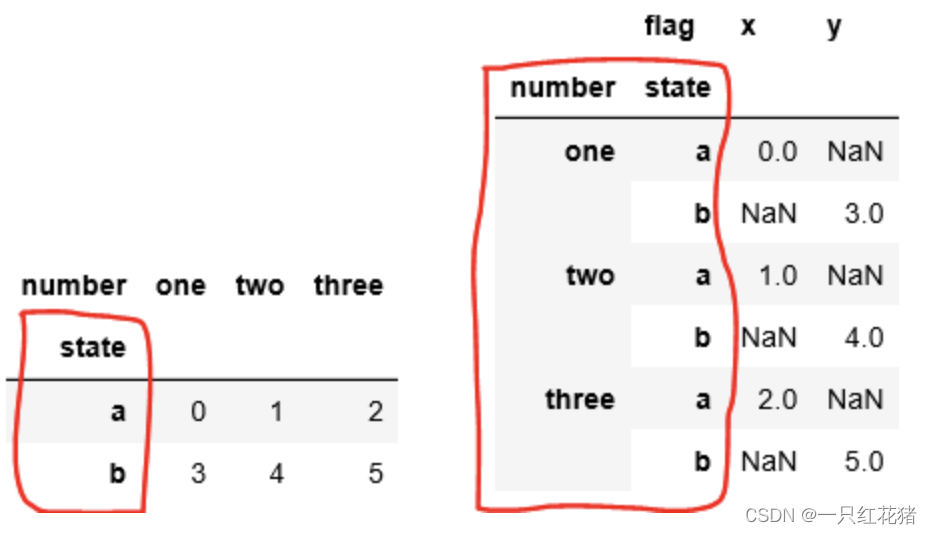
在介绍上述的两个函数之前,先得对pandas数据格式得索引有一定得了解会比较容易发挥这两个函数得强大功能,个人感觉可以将其理解为数据的一种Hashmap,如下图片中左边的红色框中为一层索引 key-value的不同之处,右边的为两层索引,需如要果注使意用的是行索列引转可换以函重数复不,设这置个索和引字典的中话的,会使用默认的索引(0,1,2…)这样也发挥不出开列转行函数的作用,大家如果用过pandas里面的神奇函数pivot, 可以去看看里面的核心代码就是这两个函数的转换
💡 2. 使用方法
2.1 stack函数使用
为了要大家更加方便的看到改函数的作用,首先,我们创建一个具有多级索引的 DataFrame。具体如下所示:
import pandas as pd
# 创建多级索引
index = pd.MultiIndex.from_product([['A', 'B'], ['X', 'Y', 'Z']], names=['Letter', 'Category'])
# 创建 DataFrame
df = pd.DataFrame({'Data': range(6)}, index=index)
# 显示 DataFrame
print(df)
Letter Category
A X 0
Y 1
Z 2
B X 3
Y 4
Z 5
Name: Data, dtype: int32
对上述的多级索引数据,stack 方法用于将索引的一个级别转换为列。具体操作如下:
# 使用 stack 将 'Category' 级别转换为列
stacked_df = df.stack('Category')
# 显示 stack 后的 DataFrame
print(stacked_df)
Category X Y Z
Letter
A 0 1 2
B 3 4 5
2.2 unstack函数使用
unstack 方法与 stack 相反,它将一个级别的列转换回索引。
# 使用 unstack 将列转换回索引
unstacked_df = stacked_df.unstack('Category')
# 显示 unstack 后的 DataFrame
print(unstacked_df)
Category X Y Z
Letter
A 0 1 2
B 3 4 5
🔍 3. 高阶用法
3.1 特征工程中的trick
当有两层行索引的时候,如果想要去掉设置的索引改为默认的直接重设即可:
# 设置多层索引 result.unstack(level=0)
#将第2层索引翻转为列,-1为第一层索引
# 这个翻转函数在进行特征工程的时候经常会用到:
1. 当有两层行索引的时候,如果想要去掉设置的索引改为默认的直接重设即可:
df.reset_index()
2. 当有两层列索引的时候,往往进行特征提取的时候,需要将多张表进行meger或者concat,这个时候表的columns都是单层的,
这个时候可以使用ravel骚函数或者将其转为元组类型的list,将多层的表转换为单层的表:
pair_cols= df.columns.ravel()
df.columns = [str(i) + '_' str(j) for i, j in pair_cols]
3.1 fillna函数进行数据填充
数据分析真实场景中,缺失值的存在是不可明显存在的,对很多的算法不支持缺失数据的出现,因此,经常需要对缺失的数据进行填充,具体的填充方法为:
import pandas as pd
import numpy as np
# 创建示例数据
data = {'A': [1, np.nan, 3, 4],
'B': [5, 6, np.nan, 8]}
df = pd.DataFrame(data)
# 填充缺失值为指定值
filled_df = df.fillna(value=0)
print(filled_df)
# 使用列的统计值填充缺失值
mean_filled_df = df.fillna(value=df.mean())
print(mean_filled_df)
# 使用前一个有效值填充缺失值
ffill_filled_df = df.fillna(method='ffill')
print(ffill_filled_df)
A B
0 1.0 5.0
1 0.0 6.0
2 3.0 0.0
3 4.0 8.0
A B
0 1.0 5.0
1 2.7 6.0
2 3.0 6.3
3 4.0 8.0
A B
0 1.0 5.0
1 1.0 6.0
2 3.0 6.0
3 4.0 8.0
🔍 4. 注意事项
对上述的各个函数在使用的过程中需要注意的一些事项,不然可能会出现error,具体主要为:
- 使用 stack 时,如果原始 DataFrame 有多个列,stack 后将只保留一个列,其他列的数据将丢失。
- unstack 可以用于恢复 stack 操作之前的状态,但要注意,如果 stack 后的数据经过了修改或筛选,unstack 可能无法完全恢复原始结构。
- 当使用 stack 或 unstack 时,如果指定的级别不存在,会引发 KeyError。
🔧 5. 总结
stack 和 unstack 是 Pandas 中处理多级索引的强大工具,它们可以帮助我们以不同的方式查看和分析数据。通过 stack,我们可以将索引的一个级别转换为列,而 unstack 则可以将列转换回索引。这些操作在处理具有复杂层次结构的数据时非常有用。本文通过实际的代码示例和输出结果,展示了如何使用这两个函数来处理具有多级索引的 DataFrame,希望能够帮助读者更好地理解这些概念。