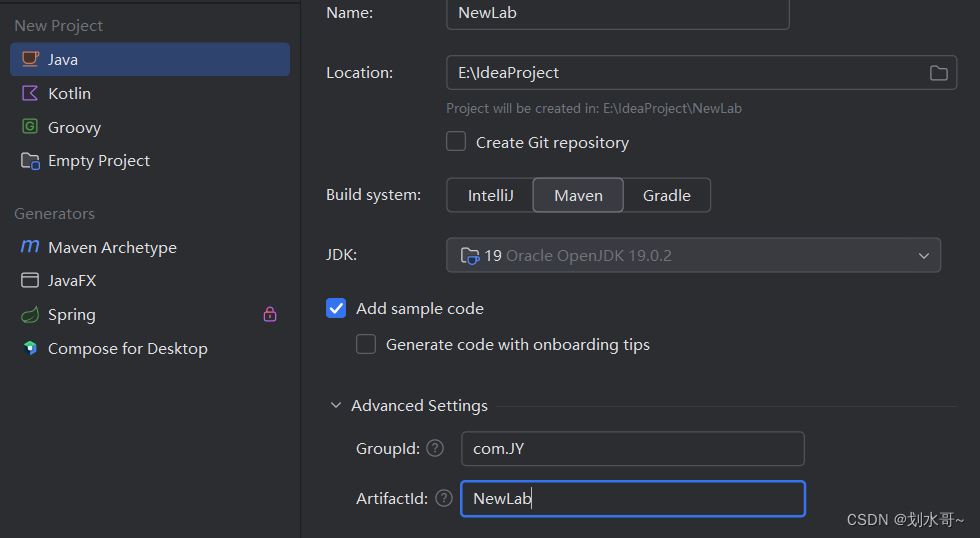
LangChain 框架搭建
安装 langchain
pip install langchain -i https://mirrors.aliyun.com/pypi/simple/
安装 langchain-openai
pip install langchain-openai -i https://mirrors.aliyun.com/pypi/simple/
ChatOpenAI 配置环境变量
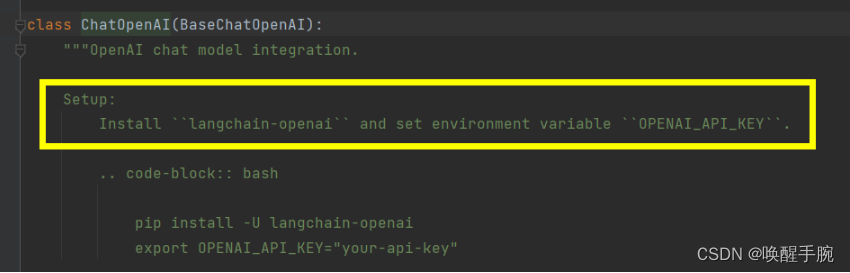
环境变量
OPENAI_API_KEY=OpenAI API 密钥
OPENAI_BASE_URL=OpenAI API 基础 URL
OPENAI_API_KEY
这是你的 OpenAI API 密钥。当你注册 OpenAI 并创建一个新的 API 密钥时,你会得到一个唯一的密钥字符串。这个密钥用于在你的应用程序和 OpenAI API 之间进行身份验证。当你调用 OpenAI API 的任何端点时,你都需要在请求中包含这个 API 密钥。这通常是通过在请求头中添加一个 Authorization 字段来完成的,其值为 Bearer [你的API密钥]。
OPENAI_BASE_URL
这是 OpenAI API 基础 URL。对于大多数用户来说,这个值通常是固定的,并指向 OpenAI 的官方 API 服务器。但是,有些用户可能会出于各种原因(如使用自定义的 API 网关或代理)而需要更改这个值。

Model I / O 说明

本地知识库原理

ChatOpenAI invoke
ChatOpenAI 的 invoke 方法是用于触发与 ChatOpenAI 模型进行交互的函数。此方法的具体实现和参数可能会根据你所使用的库或框架而有所不同,但一般来说,其目标是向模型发送一个输入(如消息或文本),并接收模型的响应。
from langchain_openai import ChatOpenAI
import dotenv
dotenv.load_dotenv(".env")
llm = ChatOpenAI()
result = llm.invoke("hello")
print(result.content)
"""
result = llm.invoke("hello")
print(result)
content='Hello! How can I assist you today?' response_metadata={'token_usage': {'completion_tokens': 9, 'prompt_tokens': 8, 'total_tokens': 17}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-fe5d5321-dd8b-4585-9eba-4fb71a39937e-0' usage_metadata={'input_tokens': 8, 'output_tokens': 9, 'total_tokens': 17}
"""
ChatPromptTemplate
LangChain 中的 ChatPromptTemplate 是用于在聊天领域构建特定提示模板的工具。它允许开发者在聊天环境中以结构化的方式创建提示,从而指导模型生成连贯且相关的输出。
创建使用
ChatPromptTemplate可以通过几种方式创建,包括使用列表和更具体的MessagePromptTemplates(如AIMessagePromptTemplate和HumanMessagePromptTemplate)。创建时,开发者可以指定角色(如AI或人类)和内容,从而定义对话的上下文和流程。
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
import dotenv
dotenv.load_dotenv(".env")
llm = ChatOpenAI()
prompt = ChatPromptTemplate.from_messages([
("system", "你是边缘骇客机器人"),
("user", "{input}")
])
chain = prompt | llm
result = chain.invoke({"input": "你是谁?"})
print(result)
"""
content='我是边缘骇客机器人,专注于为您提供计算机和网络安全方面的帮助和建议。您有什么问题可以问我。' response_metadata={'token_usage': {'completion_tokens': 49, 'prompt_tokens': 29, 'total_tokens': 78}, 'model_name': 'gpt-3.5-turbo', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-c9439b2d-e5c8-488b-9c72-384a2c4405db-0' usage_metadata={'input_tokens': 29, 'output_tokens': 49, 'total_tokens': 78}
"""
总结来说,LangChain的ChatPromptTemplate是一个强大的工具,用于在聊天场景中构建和管理提示。通过提供结构化和灵活的方式来创建聊天提示,它可以帮助开发者创建更加自然和连贯的对话体验。
TextLoader 文档加载
langchain_community 和 langchain 区别
langchain_community 和 langchain 在 LangChain 框架中分别担任不同的角色和功能。langchain_community 主要负责第三方集成。它提供了与各种外部服务和库(如数据库、API等)集成的接口和工具,扩展了 LangChain 的功能和应用范围。langchain 作为 LangChain 框架的核心部分,它提供了构建基于大型语言模型(LLM)的应用所需的组件和工具。这包括链(Chains)、代理(Agents)、检索策略等,用于构建复杂的业务流程和智能代理。
langchain_community 当开发者需要将其 LangChain 应用与特定的外部服务(如数据库、API等)集成时,会用到 langchain_community 提供的工具和接口。langchain 在构在这里插入代码片建基于 LLM 的应用时,开发者会使用 langchain 提供的链、代理和检索策略等组件来定义业务流程、处理任务和对话。
安装 langchain_community
pip install langchain_community
读取 document.txt 文档
from langchain_community.document_loaders import TextLoader
loader = TextLoader("document.txt", encoding="UTF-8")
data = loader.load()
print(data)
[Document(page_content='床前明月光,疑是地上霜。', metadata={'source': 'document.txt'})]
常见问题
from langchain.document_loaders import TextLoader
Please install langchain-community to access this module. You can install it using `pip install -U langchain-community`
WebBaseLoader 网络加载

详细源码
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://baike.baidu.com/item/%E9%9B%A8%E9%9C%96%E9%93%83/668352?fr=ge_ala")
data = loader.load()
print(data)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
print(len(splits))
Chroma 数据库
Chroma 数据库是一个高性能的向量数据库,专为处理大规模高维向量数据而设计。它采用高效的索引结构和算法,支持多种相似度度量标准,如欧氏距离和余弦相似度,能够快速且准确地完成向量搜索任务。
Chroma 数据库适用于各种需要处理高维向量数据的场景,如图像识别、自然语言处理、推荐系统等,具有分布式架构、数据压缩、容错恢复等特性,确保系统的稳定性和可扩展性。通过Chroma数据库,用户可以轻松构建高效、准确的向量搜索系统,实现数据的高效利用和价值挖掘。
安装 Chroma 数据库
pip install chromadb
详细源码
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from dotenv import load_dotenv
load_dotenv(".env")
from langchain_openai import OpenAIEmbeddings
loader = WebBaseLoader("https://baike.baidu.com/item/%E9%9B%A8%E9%9C%96%E9%93%83/668352?fr=ge_ala")
data = loader.load()
# from langchain_text_splitters import RecursiveCharacterTextSplitter
# text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
# splits = text_splitter.split_documents(data)
# print(len(splits))
embedding_model = OpenAIEmbeddings()
db = Chroma.from_documents(documents=data, embedding=embedding_model)
print(db)
retriever = db.as_retriever(search_kwargs={'k': 1})
docs = retriever.get_relevant_documents("雨霖铃第一句")
print(docs)
<langchain_community.vectorstores.chroma.Chroma object at 0x0000017A90E4E810>
[Document(page_content='雨霖铃(词牌名)_百度百科······', 'language': 'No language found.', 'source': 'https://baike.baidu.com/item/%E9%9B%A8%E9%9C%96%E9%93%83/668352?fr=ge_ala', 'title': '雨霖铃(词牌名)_百度百科'})]
常见问题
pip install chromadb
ImportError: Could not import chromadb python package. Please install it with `pip install chromadb`.
BaseRetriever.get_relevant_documents
The method `BaseRetriever.get_relevant_documents` was deprecated in langchain-core 0.1.46 and will be removed in 0.3.0. Use invoke instead.
query_result = db.search("雨霖铃第一句", search_type='similarity')
print(query_result)
腾讯云向量数据库
地址:https://buy.cloud.tencent.com/vector
新建安全组

创建向量数据库实例
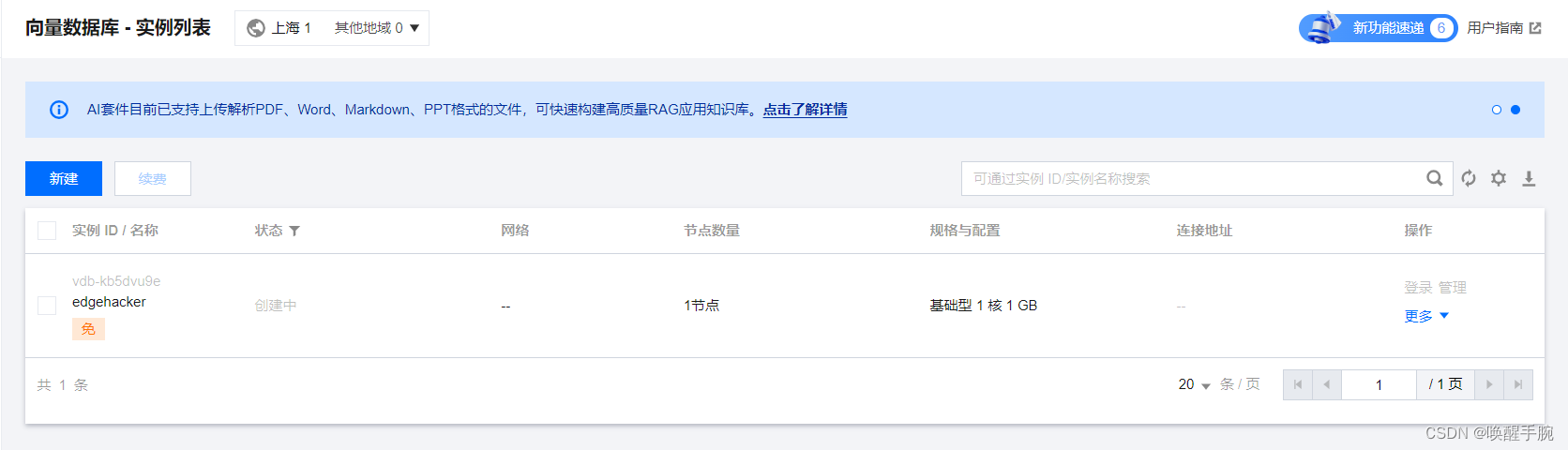
查看密钥

腾讯云 AI 套件
官方文档:https://cloud.tencent.com/document/product/1709/102189
什么是 AI 套件?
AI 套件是腾讯云向量数据库(Tencent Cloud VectorDB)提供的一站式文档检索解决方案,包含自动化文档解析、信息补充、向量化、内容检索等能力,并拥有丰富的可配置项,助力显著提升文档检索召回效果。用户仅需上传原始文档,数分钟内即可快速构建专属知识库,大幅提高知识接入效率。
设计思想
AI 套件检索方案提供完整的文档预处理和灵活的内容检索能力。用户只需上传 Markdown 格式的文档文件。腾讯云向量数据库将自动进行文本切分(Split)、信息补充、向量化(Embedding)和索引构建等一系列操作,完成知识库的建立。在进行检索时,会先基于切分后的内容进行相似度计算,并结合词(Words)向量进一步对检索结果进行精排,最终返回排名靠前的 Top K 条数据和其上下文内容。这种综合利用词级别做精排的检索方式,提供了更专业、更精确的内容检索体验。
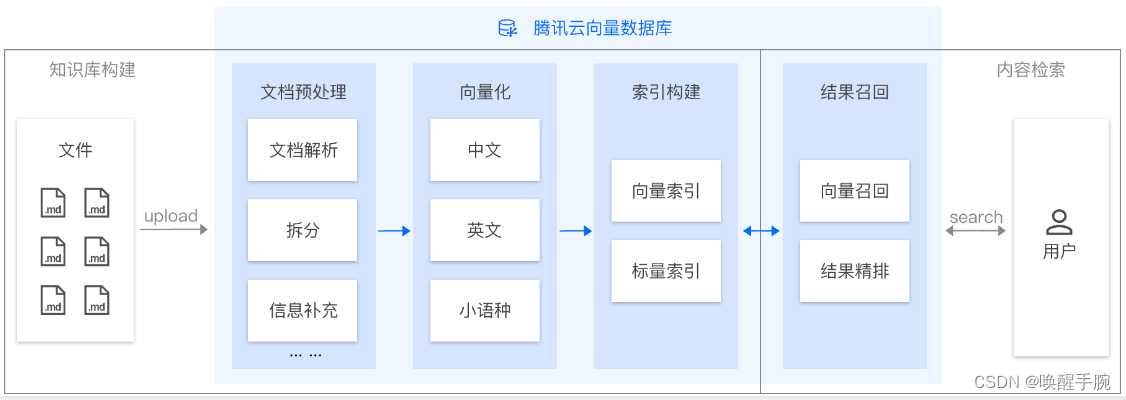
AI 类 Database
AI 类 Database 是专门用于 AI 套件上传和存储文件的向量数据库系统,可用于构建知识库。用户可以直接将文件上传至 AI 类 Database 下的 CollectionView 中,自动构建个性化的知识库。
CollectionView 集合视图
AI 类数据库文档组的集合视图,由多个 DocumentSet 组成,每个 DocumentSet 存储一组数据,对应一个文件数据。多个 DocumentSet 构成一个 CollectionView。
DocumentSet 文档集合
相对 Document 来说 DocumentSet 是 AI 类数据库中存储在 CollectionView 中的非结构化数据,是文件被拆分成多个 Document 的集合。每个DocumentSet 存储一组数据,对应一个文件,是 CollectionView 下存储文件的最小单元。
Metadata 文件元数据
文件元数据 指上传文件时所携带的文件元数据信息,可以包括文件的名称、作者、创建日期、文件类型等信息。所有元数据被自动解析为标量字段,以Key-Value格式存储。用户可根据元数据构建标量字段的 Filter 索引,以检索并管理文件。
Word 词语
词语 是智能文档检索中最小的分割粒度,通常由一个或多个字符组成。在结果召回时,将对召回段落中所有 Words 进行相似性计算,以便于根据词向量进一步对检索结果做精排。
当前支持导入数据库的文件类型包含: Markdown、PDF、Word、PPT
使用 AI 套件上传文件、检索
GitHub 地址:https://github.com/Tencent/vectordatabase-sdk-python
pip install tcvectordb
URL=http://lb-mu3i2g1v-niutm5zpejq7oshw.clb.ap-shanghai.tencentclb.com:10000
KEY=mgeZvc1uQFaKVfnicx0roPaqPkVD3c9Hgy89K2CT
import os
import tcvectordb
import dotenv
dotenv.load_dotenv(".env")
vdbclient = tcvectordb.VectorDBClient(url=os.getenv("URL"), key=os.getenv("KEY"), username="root")
def vdbInit():
db = vdbclient.create_ai_database("test_db")
collView = db.create_collection_view("test_collView")
collView.load_and_split_text(local_file_path="readme.md")
print('upload file sucess')
def knowledgeSearch(query):
db = vdbclient.database('test_db')
collView = db.collection_view('test_collView')
doc_list = collView.search(content=query, limit=3)
knowledge = "根据问题检索到知识内容:\n"
knowledge_id = 1
for item in doc_list:
knowledge += f"知识内容{knowledge_id}:\n{item.data.text}\n"
knowledge_id += 1
return (knowledge)
if __name__ == "__main__":
vdbInit()
query = input("请填写查询内容:")
print(knowledgeSearch(query))
RAG 检索增强生成
技术背景
RAG 概念最初由 Facebook AI Research(FAIR)团队在 2020 年提出,并在论文《Retrieval-Augmented Generation for Knowledge-IntensiveNLPTasks》中进行了详细介绍。
应用场景
RAG 技术可以应用于各种需要利用外部知识来增强模型输出的情况,如知识密集型的自然语言处理任务、问答系统等。