文章目录
11.3.8 流形学习方法
11.3.9 什么是finetune
11.3.10 finetune为什么有效
11.3.11 什么是网络自适应
11.3.12 GAN在迁移学习中的应用
参考文献
11.3.8 流形学习方法
什么是流行学习?
流行学习自从2000年在Science上被提出来以后,就成为了机器学习和数据挖掘领域的热门问题。它的基本假设是,现有的数据是从一个高维空间中采样出来的,所以,它具有高维空间中的低维流形结构。流形就是一种几何对象(就是我们能想象能观测到的)。通俗点说就是,我们无法从原始的数据表达形式明显看出数据所具有的结构特征,那我把它想象成是处在一个高维空间,在这个高维空间里它是有个形状的。一个很好的例子就是星座。满天星星怎么描述?我们想象它们在一个更高维的宇宙空间里是有形状的,这就有了各自星座,比如织女座、猎户座。流形学习的经典方法有lsomap、locally linear embedding、laplacian eigenmap等。
流行空间中的距离度量:两点之间什么最短?在二维上是直线(线段),可在三维呢?地球上的两个点的最短距离可不是直线,它是地球展开成二维平面后画的那条直线。那条线在三维的地球上就是一条曲线,这条曲线就表示了两个点之间的最短距离,我们叫它测地线。更通俗一点,两点之间,测地线最短。在流形学习中,我们遇到测量距离的时候更多的时候用的就是这个测地线。在我们要介绍的 GFK 方法中,也是利用了这个测地线距离。比如在下面的图中,从 A 到 C 最短的距离在就是展开后的线段,但是在三维球体上看它却是一条曲线。
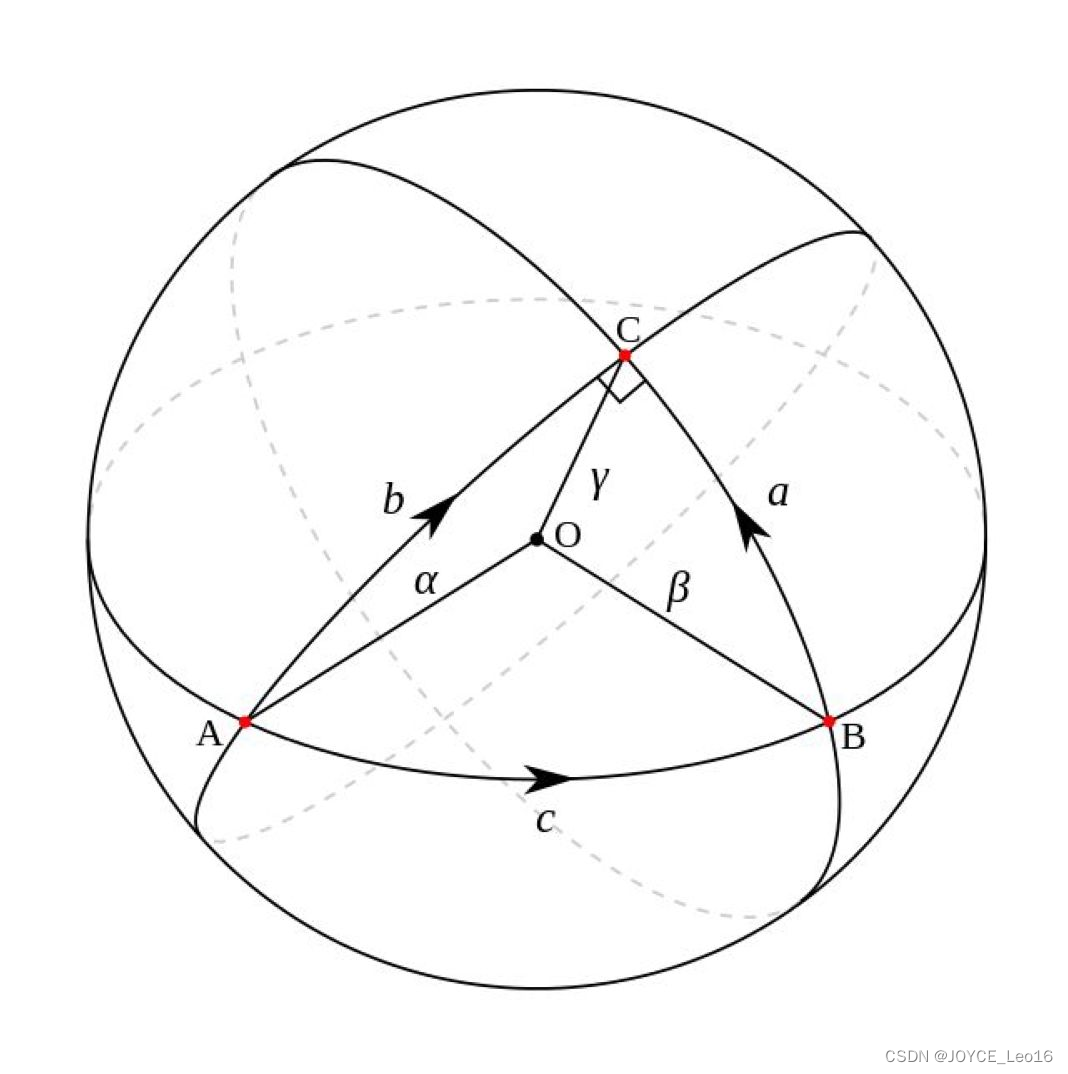
图28 三维空间中两点之间的距离示意图
由于在流形空间中的特征通常都有着很好的几何性质,可以避免特征扭曲,因此我们首先将原始空间下的特征变换到流形空间中。在众多已知的流形中, Grassmann 流形G(d) 可以通过将原始的 d 维子空间 (特征向量)看作它基础的元素,从而可以帮助学习分类 器。在 Grassmann流形中,特征变换和分布适配通常都有着有效的数值形式,因此在迁移学习问题中可以被很高效地表示和求解 [Hamm and Lee,2008]。因此,利用 Grassmann流形空间中来进行迁移学习是可行的。现存有很多方法可以将原始特征变换到流形空间中[Gopalan et al.,2011, Baktashmotlagh et al., 2014]。
在众多的基于流形变换的迁移学习方法中,GFK(Geodesic Flow Kernel)方法[Gong et al.,2012]是最为代表性的一个。GFK是在2011年发表在ICCV上的SGF方法[Gopalan et al.,2011]发展起来的。我们首先介绍SGF方法。
SGF 方法从增量学习中得到启发:人类从一个点想到达另一个点,需要从这个点一步一步走到那一个点。那么,如果我们把源域和目标域都分别看成是高维空间中的两个点,由源域变换到目标域的过程不就完成了迁移学习吗?也就是说, 路是一步一步走出来的。
于是 SGF 就做了这个事情。它是怎么做的呢?把源域和目标域分别看成高维空间 (即Grassmann流形)中的两个点,在这两个点的测地线距离上取d个中间点,然后依次连接起来。这样,源域和目标域就构成了一条测地线的路径。我们只需要找到合适的每一步的变换,就能从源域变换到目标域了。图29 是 SGF 方法的示意图。
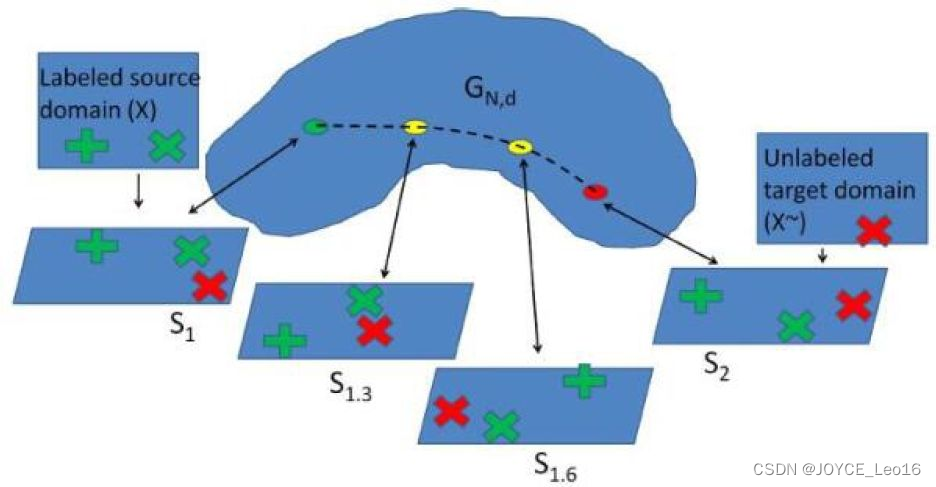
图29 SGF流形迁移学习方法示意图
SGF 方法的主要贡献在于:提出了这种变换的计算及实现了相应的算法。但是它有很明显的缺点:到底需要找几个中间点? SGF也没能给出答案,就是说这个参数d是没法估计的,没有一个好的方法。这个问题在 GFK 中被回答了。
GFK方法首先解决SGF的问题:如何确定中间点的个数d。它通过提出一种核学习的方法,利用路径上的无穷个点的积分,把这个问题解决了。这是第一个贡献。然后,它又解决了第二个问题:当有多个源域的时候,我们如何决定使用哪个源域跟目标域进行迁移? GFK通过提出Rank of Domain度量,度量出跟目标域最近的源域,来解决这个问题。图30 是 GFK 方法的示意图。

图30 GFK流形迁移学习方法示意图
用Ss和St分别表示源域和目标域经过主成分分析(PCA)之后的子空间,则G可以视为所有的d维子空间的集合。每一个d维的原始子空间都可以被看作G上的一个点。因此,在两点之间的测地线{(t) :0 < t <1}可以在两个子空间之间构成一条路径。如果我 们令Ss = ,(0),𝑆𝑡=(1),则寻找一条从(0)到(1)的测地线就等同于将原始的特征变换到一个无穷维度的空间中,最终减小域之间的漂移现象。这种方法可以被看作是一种从(0)到(1)的増量式“行走”方法。
特别地,流形空间中的特征可以被表示为z =(t)Tx。变换后的特征Zi和Zj的内积定义了一个半正定 (positive semidefinite) 的测地线流式核
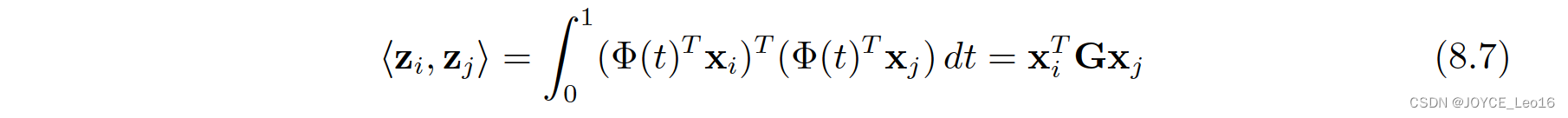
GFK 方法详细的计算过程可以参考原始的文章,我们在这里不再赘述。
11.3.9 什么是finetune
深度网络的finetune也许是最简单的深度网络迁移方法。Finetune,也叫微调、fine-tuning,是深度学习中的一个重要概念。简而言之,finetune就是利用别人已经训练好的网络,针对自己的任务再进行调整。从这个意思上看,我们不难理解finetune是迁移学习的一部分。
为什么需要已经训练好的网络?
在实际的应用中,我们通常不会针对一个新任务,就去从头开始训练一个神经网络。这样的操作显然是非常耗时的。尤其是,我们的训练数据不可能像ImageNet那么大,可以训练出泛化能力足够强的深度神经网络。即使有如此之多的训练数据,我们从头开始训练,其代价也是不可承受的。
那么怎么办呢?迁移学习告诉我们,利用之前已经训练好的模型,将它很好地迁移到自己的任务上即可。
为什么需要 finetune?
因为别人训练好的模型,可能并不是完全适用于我们自己的任务,可能别人的训练数据之间不服从同一个分布;可能别人的网络能做比我们任务更多的事情;可能别人的网络比较复杂,我们的任务比较简单。
举一个例子来说,假如我们想要训练一个猫狗图像二分类的神经网络,那么很有参考价值的就是在 CIFAR-100 上训练好的神经网络。但是 CIFAR-100 有100个类别,我们只需要2个类别。此时,就需要针对我们自己的任务,固定原始网络的相关层,修改网络的输出层以使结果更符合我们的需要。
图36展示了一个简单的finetune过程。从图中我们可以看到,我们采用的预训练好的网络非常复杂,如果直接拿来从头开始训练,则时间成本会非常高昂。我们可以将此网络进行改造,固定前面若干层的参数,只针对我们的任务,微调后面若干层。这样,网络训练速度会极大地加快,而且对提高我们任务的表现也具有很大的促进作用。
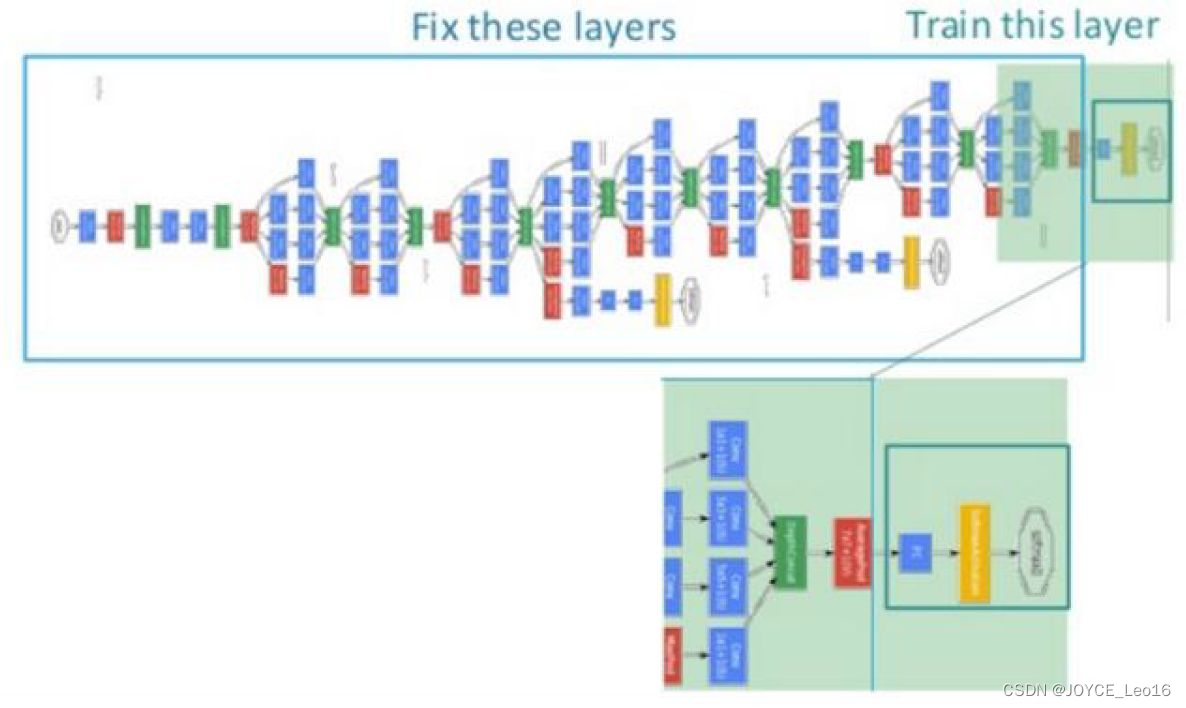
图36 一个简单的finetune示意图
Finetune 的优势
Finetune的优势是显然的,包括:
- 不需要针对新任务从头开始训练网络,节省了时间成本;
- 预训练好的模型通常都是在大数据集上进行的,无形中扩充了我们的训练数据,使得模型更鲁棒、泛化能力更好;
- Finetune 实现简单,使得我们只关注自己的任务即可。
Finetune 的扩展
在实际应用中,通常几乎没有人会针对自己的新任务从头开始训练一个神经网络。Finetune是一个理想的选择。
Finetune 并不只是针对深度神经网络有促进作用,对传统的非深度学习也有很好的效果。例如,finetune对传统的人工提取特征方法就进行了很好的替代。我们可以使用深度网络对原始数据进行训练,依赖网络提取出更丰富更有表现力的特征。然后,将这些特征作为传统的机器学习方法的输入。这样的好处是显然的:既避免了繁复的手工特征提取,也能自动地提取出更有表现力的特征。
比如,图像领域的研究,一直是以 SIFT、SURF 等传统特征为依据的,直到 2014 年,伯克利的研究人员提出了 DeCAF特征提取方法[]Donahue et al.,2014,直接使用深度卷积神经网络进行特征提取。实验结果表明,该特征提取方法对比传统的图像特征,在精度上有着无可匹敌的优势。另外,也有研究人员用卷积神经网络提取的特征作为SVM分类器的输 入[Razavian et al.,2014],显著提升了图像分类的精度。
11.3.10 finetune为什么有效
随着 AlexNet [Krizhevsky et al.,2012] 在 2012 年的 ImageNet大赛上获得冠军,深度学习开始在机器学习的研究和应用领域大放异彩。尽管取得了很好的结果,但是神经网络本身就像一个黑箱子,看得见,摸不着,解释性不好。由于神经网络具有良好的层次结构很自然地就有人开始关注,能否通过这些层次结构来很好地解释网络?于是,有了我们熟知的例子:假设一个网络要识别一只猫,那么一开始它只能检测到一些边边角角的东西,和猫根本没有关系;然后可能会检测到一些线条和圆形;慢慢地,可以检测到有猫的区域;接着是猫腿、猫脸等等。图32 是一个简单的示例。
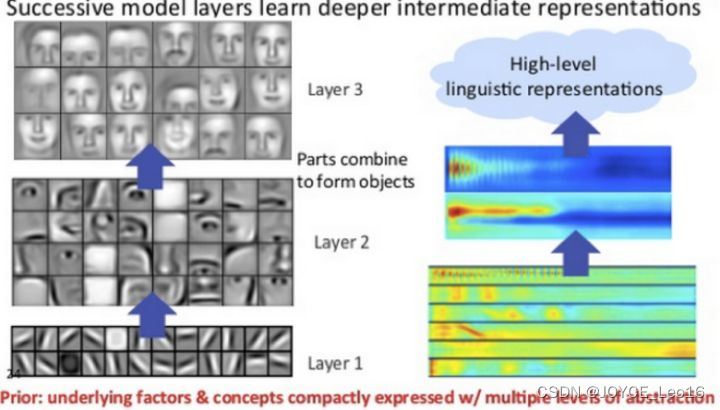
图32 深度神经网络进行特征提取到分类的简单示例
这表达了一个什么事实呢?概括来说就是:前面几层都学习到的是通用的特征(general feature);随着网络层次的加深,后面的网络更偏重于学习任务特定的特征(specific feature)。 这非常好理解,我们也都很好接受。那么问题来了:如何得知哪些层能够学习到 general feature,哪些层能够学习到specific feature。更进一步:如果应用于迁移学习,如何决定该迁移哪些层、固定哪些层?
这个问题对于理解神经网络以及深度迁移学习都有着非常重要的意义。
来自康奈尔大学的 Jason Yosinski 等人[Yosinski et a., 2014]率先进行了深度神经网络可迁移性的研究,将成果发表在2014年机器学习领域顶级会议NIPS上并做了口头汇报。该论文是一篇实验性质的文章(通篇没有一个公式)。其目的就是要探究上面我们提到的几个关键性问题。因此,文章的全部贡献都来自于实验及其结果。(别说为啥做实验也能发文章:都是高考,我只上了个普通一本,我高中同学就上了清华)
在ImageNet的1000类上,作者把1000类分成两份(A和B),每份500个类别。然后,分别对A和B基于Caffe训练了一个AlexNet网络。一个AlexNet网络一共有8层, 除去第8层是类别相关的网络无法迁移以外,作者在 1 到 7这 7层上逐层进行 finetune 实验,探索网络的可迁移性。
为了更好地说明 finetune 的结果,作者提出了有趣的概念: AnB 和 BnB。
迁移A网络的前n层到B (AnB) vs固定B网络的前n层(BnB)
简单说一下什么叫AnB:(所有实验都是针对数据B来说的)将A网络的前n层拿来并将它frozen,剩下的8 - n层随机初始化,然后对B进行分类。
相应地,有BnB:把训练好的B网络的前n层拿来并将它frozen,剩下的8 - n层随机初始化,然后对 B 进行分类。
实验结果
实验结果如下图(图33) 所示:
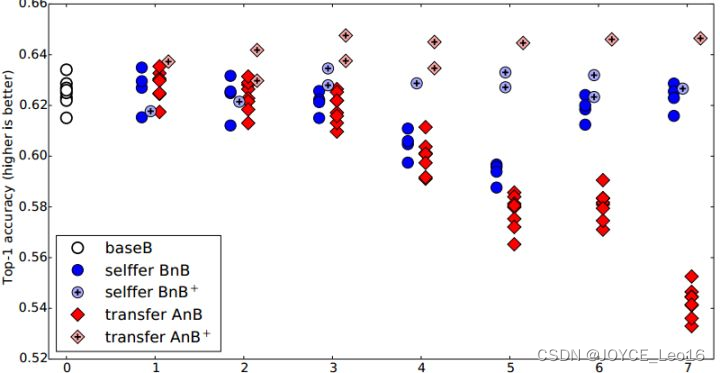
图33 深度网络迁移实验结果1
这个图说明了什么呢?我们先看蓝色的BnB和BnB+(就是BnB加上finetune)。对 BnB而言,原训练好的 B 模型的前 3 层直接拿来就可以用而不会对模型精度有什么损失到了第4 和第5 层,精度略有下降,不过还是可以接受。然而到了第6 第第7层,精度居然奇迹般地回升了!这是为什么?原因如下:对于一开始精度下降的第4 第 5 层来说,确实是到了这一步,feature变得越来越specific,所以下降了。那对于第6第7层为什么精度又不变了?那是因为,整个网络就8层,我们固定了第6第7层,这个网络还能学什么呢?所以很自然地,精度和原来的 B 网络几乎一致!
对 BnB+ 来说,结果基本上都保持不变。说明 finetune 对模型结果有着很好的促进作用!
我们重点关注AnB和AnB+。对AnB来说,直接将A网络的前3层迁移到B,貌似不会有什么影响,再一次说明,网络的前3层学到的几乎都是general feature!往后,到了第4第5层的时候,精度开始下降,我们直接说:一定是feature不general 了!然而,到了第6第7层,精度出现了小小的提升后又下降,这又是为什么?作者在这里提出两点co-adaptation和feature representation。就是说,第4第5层精度下降的时候,主要是由于A和B两个数据集的差异比较大,所以会下降;到了第6第7层,由于网络几乎不迭代了,学习能力太差,此时 feature 学不到,所以精度下降得更厉害。
再看AnB+。加入了 finetune以后,AnB+的表现对于所有的n几乎都非常好,甚至 比baseB (最初的B)还要好一些!这说明:finetune对于深度迁移有着非常好的促进作用!
把上面的结果合并就得到了下面一张图 (图34):
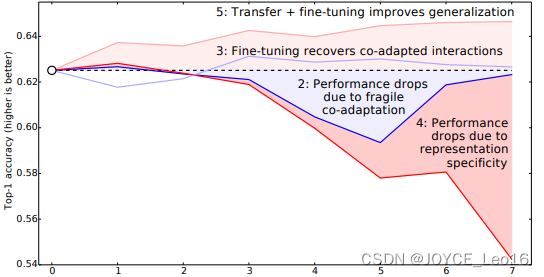
至此, AnB 和 BnB 基本完成。作者又想,是不是我分 A 和 B 数据的时候,里面存在一些比较相似的类使结果好了?比如说A里有猫,B里有狮子,所以结果会好?为了排除这些影响,作者又分了一下数据集,这次使得A和B里几乎没有相似的类别。在这个条件下再做AnB,与原来精度比较(0%为基准)得到了下图(图35):
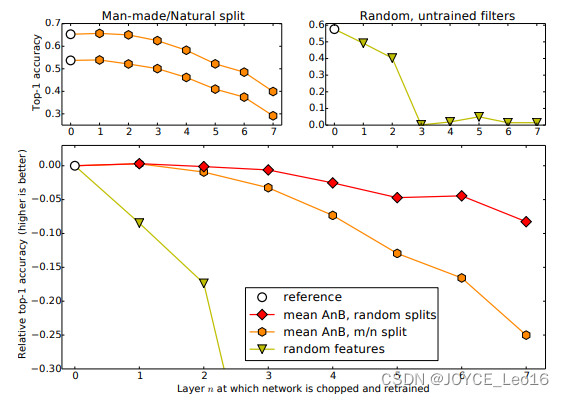
这个图说明了什么呢?简单:随着可迁移层数的增加,模型性能下降。但是,前3层仍然还是可以迁移的!同时,与随机初始化所有权重比较,迁移学习的精度是很高的!总之:
-
深度迁移网络要比随机初始化权重效果好;
-
网络层数的迁移可以加速网络的学习和优化。
11.3.11 什么是网络自适应
基本思路
深度网络的 finetune 可以帮助我们节省训练时间,提高学习精度。但是 finetune 有它的先天不足:它无法处理训练数据和测试数据分布不同的情况。而这一现象在实际应用中比比皆是。因为 finetune 的基本假设也是训练数据和测试数据服从相同的数据分布。这在迁移学习中也是不成立的。因此,我们需要更进一步,针对深度网络开发出更好的方法使之更好地完成迁移学习任务。
以我们之前介绍过的数据分布自适应方法为参考,许多深度学习方法[Tzeng et al.,2014, Long et al.,2015a]都开发出了自适应层(AdaptationLayer)来完成源域和目标域数据的自适应。自适应能够使得源域和目标域的数据分布更加接近,从而使得网络的效果更好。
从上述的分析我们可以得出,深度网络的自适应主要完成两部分的工作:
一是哪些层可以自适应,这决定了网络的学习程度;
二是采用什么样的自适应方法 (度量准则),这决定了网络的泛化能力。
深度网络中最重要的是网络损失的定义。绝大多数深度迁移学习方法都采用了以下的损失定义方式:
![]()
其中,I表示网络的最终损失,lc(Ds,ys)表示网络在有标注的数据(大部分是源域)上的常规分类损失(这与普通的深度网络完全一致),Ia(Ds,Dt)表示网络的自适应损失。最后一部分是传统的深度网络所不具有的、迁移学习所独有的。此部分的表达与我们先前讨论过的源域和目标域的分布差异,在道理上是相同的。式中的A是权衡两部分的权重参数。
上述的分析指导我们设计深度迁移网络的基本准则:决定自适应层,然后在这些层加入自适应度量,最后对网络进行 finetune。
11.3.12 GAN在迁移学习中的应用
生成对抗网络 GAN(Generative Adversarial Nets) [Goodfellow et al.,2014]是目前人工智能领域最炙手可热的概念之一。其也被深度学习领军人物 Yann Lecun 评为近年来最令人欣喜的成就。由此发展而来的对抗网络,也成为了提升网络性能的利器。本小节介绍深度对抗网络用于解决迁移学习问题方面的基本思路以及代表性研究成果。
基本思路
GAN 受到自博弈论中的二人零和博弈 (two-player game) 思想的启发而提出。它一共包括两个部分:一部分为生成网络(Generative Network),此部分负责生成尽可能地以假乱真的样本,这部分被成为生成器(Generator);另一部分为判别网络(Discriminative Network), 此部分负责判断样本是真实的,还是由生成器生成的,这部分被成为判别器(Discriminator) 生成器和判别器的互相博弈,就完成了对抗训练。
GAN 的目标很明确:生成训练样本。这似乎与迁移学习的大目标有些许出入。然而,由于在迁移学习中,天然地存在一个源领域,一个目标领域,因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据 (通常是目标域) 当作是生成的样本。此时,生成器的职能发生变化,不再生成新样本,而是扮演了特征提取的功能:不断学习领域数据的特征使得判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器 (Feature Extractor)。
通常用 Gf 来表示特征提取器,用 Gd 来表示判别器。正是基于这样的领域对抗的思想,深度对抗网络可以被很好地运用于迁移学习问题中。与深度网络自适应迁移方法类似,深度对抗网络的损失也由两部分构成:网络训练的损失lc*和领域判别损失Id:
![]()
DANN
Yaroslav Ganin 等人 [Ganin et al.,2016]首先在神经网络的训练中加入了对抗机制,作者将他们的网络称之为DANN(Domain-Adversarial Neural Network)。在此研宄中,网络的学习目标是:生成的特征尽可能帮助区分两个领域的特征,同时使得判别器无法对两个领域的差异进行判别。该方法的领域对抗损失函数表示为:
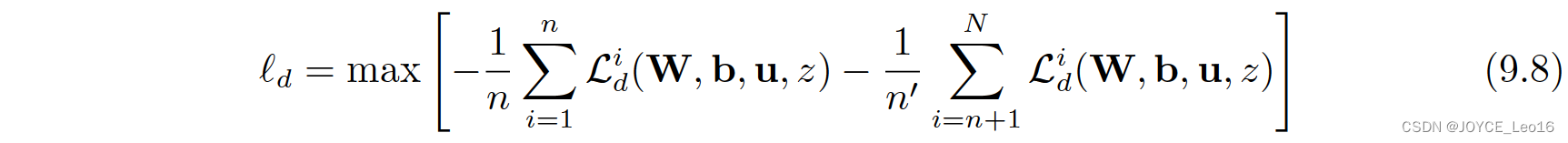
Id = max 其中的 Ld 表示为:
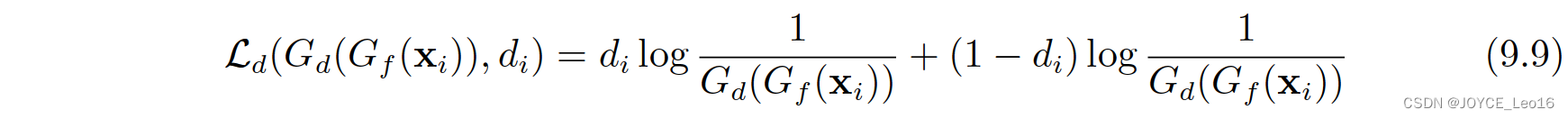
参考文献
王晋东,迁移学习简明手册
[Baktashmotlagh et al., 2013] Baktashmotlagh, M., Harandi, M. T., Lovell, B. C.,and Salz- mann, M. (2013). Unsupervised domain adaptation by domain invariant projection. In ICCV, pages 769-776.
[Baktashmotlagh et al., 2014] Baktashmotlagh, M., Harandi, M. T., Lovell, B. C., and Salz- mann, M. (2014). Domain adaptation on the statistical manifold. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition*,pages 2481-2488.
[Ben-David et al., 2010] Ben-David, S., Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., and Vaughan, J. W. (2010). A theory of learning from different domains. Machine learning, 79(1-2):151-175.
[Ben-David et al., 2007] Ben-David, S., Blitzer, J., Crammer, K., and Pereira, F. (2007). Analysis of representations for domain adaptation. In NIPS, pages 137-144.
[Blitzer et al., 2008] Blitzer, J., Crammer, K., Kulesza, A., Pereira, F., and Wortman, J. (2008). Learning bounds for domain adaptation. In Advances in neural information processing systems, pages 129-136.
[Blitzer et al., 2006] Blitzer, J., McDonald, R., and Pereira, F. (2006). Domain adaptation with structural correspondence learning. In Proceedings of the 2006 conference on empirical methods in natural language processing, pages 120-128. Association for Computational Linguistics.
[Borgwardt et al., 2006] Borgwardt, K. M., Gretton, A., Rasch, M. J., Kriegel, H.-P., Scholkopf, B., and Smola, A. J. (2006). Integrating structured biological data by kernel maximum mean discrepancy. Bioinformatics, 22(14):e49-e57.
[Bousmalis et al., 2016] Bousmalis, K., Trigeorgis, G., Silberman, N., Krishnan, D., and Erhan, D. (2016). Domain separation networks. In Advances in Neural Information Processing Systems, pages 343-351.
[Cai et al., 2011] Cai, D., He, X., Han, J., and Huang, T. S. (2011). Graph regularized nonnegative matrix factorization for data representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 33(8):1548-1560.
[Cao et al., 2017] Cao, Z., Long, M., Wang, J., and Jordan, M. I. (2017). Partial transfer learning with selective adversarial networks. arXiv preprint arXiv:1707.07901.
[Carlucci et al., 2017] Carlucci, F. M., Porzi, L., Caputo, B., Ricci, E., and Bulo, S. R. (2017). Autodial: Automatic domain alignment layers. In International Conference on* Computer Vision.
[Cook et al., 2013] Cook, D., Feuz, K. D., and Krishnan, N. C. (2013). Transfer learning for activity recognition: A survey. Knowledge and information systems, 36(3):537-556.
[Cortes et al., 2008] Cortes, C., Mohri, M., Riley, M., and Rostamizadeh, A. (2008). Sample selection bias correction theory. In International Conference on Algorithmic Learning Theory, pages 38-53, Budapest, Hungary. Springer.
[Dai et al., 2007] Dai, W., Yang, Q., Xue, G.-R., and Yu, Y. (2007). Boosting for transfer learning. In ICML, pages 193-200. ACM.
[Davis and Domingos, 2009] Davis, J. and Domingos, P. (2009). Deep transfer via second- order markov logic. In Proceedings of the 26th annual international conference on machine learning, pages 217-224. ACM.
[Denget al., 2014] Deng,W.,Zheng,Q.,andWang,Z.(2014).Cross-personactivityrecog-nition using reduced kernel extreme learning machine. Neural Networks, 53:1-7.
[Donahue et al., 2014] Donahue, J., Jia, Y., et al. (2014). Decaf: A deep convolutional activation feature for generic visual recognition. In ICML, pages 647-655.
[Dorri and Ghodsi, 2012] Dorri, F. and Ghodsi, A. (2012). Adapting component analysis. In Data Mining (ICDM), 2012 IEEE 12th International Conference on, pages 846-851. IEEE.
[Duan et al., 2012] Duan, L., Tsang, I. W., and Xu, D. (2012). Domain transfer multiple kernel learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(3):465-479.
[Fernando et al., 2013] Fernando, B., Habrard, A., Sebban, M., and Tuytelaars, T. (2013). Unsupervised visual domain adaptation using subspace alignment. In ICCV*, pages 29602967.
[Fodor, 2002] Fodor, I. K. (2002). A survey of dimension reduction techniques. Center for Applied Scientific Computing, Lawrence Livermore National Laboratory*, 9:1-18.
[Ganin et al., 2016] Ganin, Y., Ustinova, E., Ajakan, H., Germain, P., Larochelle, H., Lavi- olette, F., Marchand, M., and Lempitsky, V. (2016).Domain-adversarial training of neural networks. Journal of Machine Learning Research, 17(59):1-35.
[Gao et al., 2012] Gao, C., Sang, N., and Huang, R. (2012). Online transfer boosting for object tracking. In Pattern Recognition (ICPR), 2012 21st International Conference on, pages 906-909. IEEE.
[Ghifary et al., 2017] Ghifary, M., Balduzzi, D., Kleijn, W. B., and Zhang, M. (2017). Scatter component analysis: A unified framework for domain adaptation and domain generalization. IEEE transactions on pattern analysis and machine intelligence, 39(7):1414-1430.
[Ghifary et al., 2014] Ghifary, M., Kleijn, W. B., and Zhang, M. (2014). Domain adaptive neural networks for object recognition. In PRICAI, pages 898-904.
[Gong et al., 2012] Gong, B., Shi, Y., Sha, F., and Grauman, K. (2012). Geodesic flow kernel for unsupervised domain adaptation. In CVPR, pages 2066-2073.
[Goodfellow et al., 2014] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde- Farley, D., Ozair, S., Courville, A., and Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems, pages 2672-2680.
[Gopalan et al., 2011] Gopalan, R., Li, R., and Chellappa, R. (2011). Domain adaptation for object recognition: An unsupervised approach. In ICCV, pages 999-1006. IEEE.
[Gretton et al., 2012] Gretton, A., Sejdinovic, D., Strathmann, H., Balakrishnan, S., Pontil, M., Fukumizu, K., and Sriperumbudur, B. K. (2012). Optimal kernel choice for large- scale two-sample tests. In Advances in neural information processing systems, pages 1205-1213.
[Gu et al., 2011] Gu, Q., Li, Z., Han, J., et al. (2011). Joint feature selection and subspace learning. In IJCAI Proceedings-International Joint Conference on Artificial Intel ligence, volume 22, page 1294.
[Hamm and Lee, 2008] Hamm, J. and Lee, D. D. (2008). Grassmann discriminant analysis: a unifying view on subspace-based learning. In ICML, pages 376-383. ACM.
[Hou et al., 2015] Hou, C.-A., Yeh, Y.-R., and Wang, Y.-C. F. (2015). An unsupervised domain adaptation approach for cross-domain visual classification. In Advanced Video and Signal Based Surveil lance (AVSS), 2015 12th IEEE International Conference on,pages 1-6. IEEE.
[Hsiao et al., 2016] Hsiao, P.-H., Chang, F.-J., and Lin, Y.-Y. (2016). Learning discriminatively reconstructed source data for object recognition with few examples. IEEETransactions on Image Processing*, 25(8):3518-3532.
[Hu and Yang, 2011] Hu, D. H. and Yang, Q. (2011). Transfer learning for activity recognition via sensor mapping. In IJCAI Proceedings-International Joint Conference on Artificial Intelligence, volume 22, page 1962, Barcelona, Catalonia, Spain. IJCAI.
[Huang et al., 2007] Huang, J., Smola, A. J., Gretton, A., Borgwardt, K. M., Scholkopf, B., et al. (2007). Correcting sample selection bias by unlabeled data. Advances in neural information processing systems, 19:601.
[Jaini et al., 2016] Jaini, P., Chen, Z., Carbajal, P., Law, E., Middleton, L., Regan, K., Schaekermann, M., Trimponias, G., Tung, J., and Poupart, P. (2016). Online bayesian transfer learning for sequential data modeling. In ICLR 2017.
[Kermany et al., 2018] Kermany, D. S., Goldbaum, M., Cai, W., Valentim, C. C., Liang, H., Baxter, S. L., McKeown, A., Yang, G., Wu, X., Yan, F., et al. (2018). Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell, 172(5):1122-1131.
[Khan and Heisterkamp, 2016] Khan, M. N. A. and Heisterkamp, D. R. (2016). Adapting instance weights for unsupervised domain adaptation using quadratic mutual information and subspace learning. In Pattern Recognition (ICPR), 2016 23rd International Conference on, pages 1560-1565, Mexican City. IEEE.
[Krizhevsky et al., 2012] Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems*, pages 1097-1105.
[Li et al., 2012] Li, H., Shi, Y., Liu, Y., Hauptmann, A. G., and Xiong, Z. (2012). Crossdomain video concept detection: A joint discriminative and generative active learning approach. Expert Systems with Applications, 39(15):12220-12228.
[Li et al., 2016] Li, J., Zhao, J., and Lu, K. (2016). Joint feature selection and structure preservation for domain adaptation. In Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, pages 1697-1703. AAAI Press.
[Li et al., 2018] Li, Y., Wang, N., Shi, J., Hou, X., and Liu, J. (2018). Adaptive batch normalization for practical domain adaptation. Pattern Recognition, 80:109-117.
[Liu et al., 2011] Liu, J., Shah, M., Kuipers, B., and Savarese, S. (2011). Cross-view action recognition via view knowledge transfer. In Computer Vision and Pattern Recognition (CVPR), 2011 IEEE Conference on, pages 3209-3216, Colorado Springs, CO, USA. IEEE.
[Liu and Tuzel, 2016] Liu, M.-Y. and Tuzel, O. (2016). Coupled generative adversarial networks. In Advances in neural information processing systems, pages 469-477.
[Liu et al., 2017] Liu, T., Yang, Q., and Tao, D. (2017). Understanding how feature structure transfers in transfer learning. In IJCAI.
[Long et al., 2015a] Long, M., Cao, Y., Wang, J., and Jordan, M. (2015a). Learning transferable features with deep adaptation networks. In ICML, pages 97-105.
[Long et al., 2016] Long, M., Wang, J., Cao, Y., Sun, J., and Philip, S. Y. (2016). Deep learning of transferable representation for scalable domain adaptation. IEEE Transactions on Knowledge and Data Engineering, 28(8):2027-2040.
[Long et al., 2014a] Long, M., Wang, J., Ding, G., Pan, S. J., and Yu, P. S. (2014a). Adaptation regularization: A general framework for transfer learning.*IEEE TKDE, 26(5):1076-1089.
[Long et al., 2014b] Long, M., Wang, J., Ding, G., Sun, J., and Yu, P. S. (2014b). Transfer joint matching for unsupervised domain adaptation. In *CVPR ,pages 1410-1417.
[Long et al., 2013] Long, M., Wang, J., et al. (2013). Transfer feature learning with joint distribution adaptation. In ICCV, pages 2200-2207.
[Long et al., 2017] Long, M., Wang, J., and Jordan, M. I. (2017). Deep transfer learning with joint adaptation networks. In ICML, pages 2208-2217.
[Long et al., 2015b] Long, M., Wang, J., Sun, J., and Philip, S. Y. (2015b). Domain invariant transfer kernel learning. IEEE Transactions on Knowledge and Data Engineering, 27(6):1519-1532.
[Luo et al., 2017] Luo, Z., Zou, Y., Hoffman, J., and Fei-Fei, L. F. (2017). Label efficient learning of transferable representations acrosss domains and tasks. In Advances in Neural Information Processing Systems, pages 164-176.
[Mihalkova et al., 2007] Mihalkova, L., Huynh, T., and Mooney, R. J. (2007). Mapping and revising markov logic networks for transfer learning. In AAAI, volume 7, pages 608-614.
[Mihalkova and Mooney, 2008] Mihalkova, L. and Mooney, R. J. (2008). Transfer learning by mapping with minimal target data. In Proceedings of the AAAI-08 workshop on transfer learning for complex tasks.
[Nater et al., 2011] Nater, F., Tommasi, T., Grabner, H., Van Gool, L., and Caputo, B. (2011). Transferring activities: Updating human behavior analysis. In Computer Vision Workshops (ICCV Workshops), 2011 IEEE International Conference on, pages 17371744, Barcelona, Spain. IEEE.
[Pan et al., 2008a] Pan, S. J., Kwok, J. T., and Yang, Q. (2008a). Transfer learning via dimensionality reduction. In Proceedings of the 23rd AAAI conference on Artificial intelligence, volume 8, pages 677-682.
[Pan et al., 2008b] Pan, S. J., Shen, D., Yang, Q., and Kwok, J. T. (2008b). Transferring localization models across space. In Proceedings of the 23rd AAAI Conference on Artificial Intelligence, pages 1383-1388.
[Pan et al., 2011] Pan, S. J., Tsang, I. W., Kwok, J. T., and Yang, Q. (2011). Domain adaptation via transfer component analysis. IEEE TNN, 22(2):199-210.
[PanandYang, 2010] Pan,S.J.andYang,Q.(2010). A survey on transfer learning. IEEE TKDE*, 22(10):1345-1359.
[Patil and Phursule, 2013] Patil, D. M. and Phursule, R. (2013). Knowledge transfer using cost sensitive online learning classification. International Journal of Science and Research, pages 527-529.
[Razavian et al., 2014] Razavian, A. S., Azizpour, H., Sullivan, J., and Carlsson, S. (2014). Cnn features off-the-shelf: an astounding baseline for recognition. In Computer Vision and Pattern Recognition Workshops (CVPRW), 2014 IEEE Conference on, pages 512519. IEEE.
[Saito et al., 2017] Saito, K., Ushiku, Y., and Harada, T. (2017). Asymmetric tri-training for unsupervised domain adaptation. In International Conference on Machine Learning.
[Sener et al., 2016] Sener, O., Song, H. O., Saxena, A., and Savarese, S. (2016). Learning transferrable representations for unsupervised domain adaptation. In Advances in Neural Information Processing Systems, pages 2110-2118.
[Shen et al., 2018] Shen, J., Qu, Y., Zhang, W., and Yu, Y. (2018). Wasserstein distance guided representation learning for domain adaptation. In AAAI.
[Si et al., 2010] Si, S., Tao, D., and Geng, B. (2010). Bregman divergence-based regularization for transfer subspace learning. IEEE Transactions on Knowledge and Data Engineering, 22(7):929-942.
[Silver et al., 2017] Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., et al. (2017). Mastering the game of go without human knowledge. Nature, 550(7676):354.
[Stewart and Ermon, 2017] Stewart, R. and Ermon, S. (2017). Label-free supervision of neural networks with physics and domain knowledge. In AAAI, pages 2576-2582.
[Sun et al., 2016] Sun, B., Feng, J., and Saenko, K. (2016). Return of frustratingly easy domain adaptation. In AAAI, volume 6, page 8.
[Sun and Saenko, 2015] Sun, B. and Saenko, K. (2015). Subspace distribution alignment for unsupervised domain adaptation. In BMVC, pages 24-1.
[Sun and Saenko, 2016] Sun, B. and Saenko, K. (2016). Deep coral: Correlation alignment for deep domain adaptation. In European Conference on Computer Vision, pages 443-450. Springer.
[Tahmoresnezhad and Hashemi, 2016] Tahmoresnezhad, J. and Hashemi, S. (2016). Visual domain adaptation via transfer feature learning. Knowledge and Information Systems, pages 1-21.
[Tan et al., 2015] Tan, B., Song, Y., Zhong, E., and Yang, Q. (2015). Transitive transfer learning. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1155-1164. ACM.
[Tan et al., 2017] Tan, B., Zhang, Y., Pan, S. J., and Yang, Q. (2017). Distant domain transfer learning. In Thirty-First AAAI Conference on Artificial Intelligence.
[Taylor and Stone, 2009] Taylor, M. E. and Stone, P. (2009). Transfer learning for reinforcement learning domains: A survey. Journal of Machine Learning Research, 10(Jul):1633- 1685.
[Tzeng et al., 2015] Tzeng, E., Hoffman, J., Darrell, T., and Saenko, K. (2015). Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, pages 4068-4076, Santiago, Chile. IEEE.
[Tzeng et al., 2017] Tzeng, E., Hoffman, J., Saenko, K., and Darrell, T. (2017). Adversarial discriminative domain adaptation. In CVPR, pages 2962-2971.
[Tzeng et al., 2014] Tzeng, E., Hoffman, J., Zhang, N., et al. (2014). Deep domain confusion: Maximizing for domain invariance. arXiv preprint arXiv:1412.3474.
[Wang et al., 2017] Wang, J., Chen, Y., Hao, S., et al. (2017). Balanced distribution adaptation for transfer learning. In ICDM, pages 1129-1134.
[Wang et al., 2018] Wang, J., Chen, Y., Hu, L., Peng, X., and Yu, P. S. (2018). Stratified transfer learning for cross-domain activity recognition. In 2018 IEEE International Conference on Pervasive Computing and Communications (PerCom).
[Wang et al., 2014] Wang, J., Zhao, P., Hoi, S. C., and Jin, R. (2014). Online feature selection and its applications. IEEE Transactions on Knowledge and Data Engineering, 26(3):698-710.
[Wei et al., 2016a] Wei, P., Ke, Y., and Goh, C. K. (2016a). Deep nonlinearfeature coding for unsupervised domain adaptation. In IJCAI, pages 2189-2195.
[Wei et al., 2017] Wei, Y., Zhang, Y., and Yang, Q. (2017). Learning totransfer. arXiv preprint arXiv:1708.05629*.
[Wei et al., 2016b] Wei, Y., Zhu, Y., Leung, C. W.-k., Song, Y., and Yang, Q. (2016b). Instilling social to physical: Co-regularized heterogeneous transfer learning. In Thirtieth AAAI Conference on Artificial Intelligence*.
[Weiss et al., 2016] Weiss, K., Khoshgoftaar, T. M., and Wang, D. (2016). A survey of transfer learning. Journal of Big Data, 3(1):1-40.
[Wu et al., 2017] Wu, Q., Zhou, X., Yan, Y., Wu, H., and Min, H. (2017). Online transfer learning by leveraging multiple source domains. Knowledge and Information Systems, 52(3):687-707.
[xinhua, 2016] xinhua (2016). http://mp.weixin.qq.com/s?__biz=MjM5ODYzNzAyMQ==& mid=2651933920&idx=1\&sn=ae2866bd12000f1644eae1094497837e.
[Yan et al., 2017] Yan, Y., Wu, Q., Tan, M., Ng, M. K., Min, H., and Tsang, I. W. (2017). Online heterogeneous transfer by hedge ensemble of offline and online decisions. IEEE transactions on neural networks and learning systems.
[Yosinski et al., 2014] Yosinski, J., Clune, J., Bengio, Y., and Lipson, H. (2014). How transferable are features in deep neural networks? In Advances in neural information processing systems, pages 3320-3328.
[Zadrozny, 2004] Zadrozny, B. (2004). Learning and evaluating classifiers under sample selection bias. In Proceedings of the twenty-first international conference on Machine learning, page 114, Alberta, Canada. ACM.
[Zellinger et al., 2017] Zellinger, W., Grubinger, T., Lughofer, E., Natschlager, T., and Saminger-Platz, S. (2017). Central moment discrepancy (cmd) for domain-invariant representation learning. arXiv preprint arXiv:1702.08811.
[Zhang et al., 2017a] Zhang, J., Li, W., and Ogunbona, P. (2017a). Joint geometrical and statistical alignment for visual domain adaptation. In CVPR.
[Zhang et al., 2017b] Zhang, X., Zhuang, Y., Wang, W., and Pedrycz, W. (2017b). Online feature transformation learning for cross-domain object category recognition. IEEE transactions on neural networks and learning systems.
[Zhao and Hoi, 2010] Zhao, P. and Hoi, S. C. (2010). Otl: A framework of online transfer learning. In Proceedings of the 27th international conference on machine learning (ICML- 10), pages 1231-1238.
[Zhao et al., 2010] Zhao, Z., Chen, Y., Liu, J., and Liu, M. (2010). Cross-mobile elm based activity recognition. International Journal of Engineering and Industries, 1(1):30-38.
[Zhao et al., 2011] Zhao, Z., Chen, Y., Liu, J., Shen, Z., and Liu, M. (2011). Cross-people mobile-phone based activity recognition. In Proceedings of the Twenty-Second international joint conference on Artificial Intelligence (IJCAI), volume 11, pages 2545-2550. Citeseer.
[Zheng et al., 2009] Zheng, V. W., Hu, D. H., and Yang, Q. (2009). Cross-domain activity recognition. In Proceedings of the 11th international conference on Ubiquitous computing, pages 61-70. ACM.
[Zheng et al., 2008] Zheng, V. W., Pan, S. J., Yang, Q., and Pan, J. J. (2008). Transferring multi-device localization models using latent multi-task learning. In AAAI, volume 8, pages 1427-1432, Chicago, Illinois, USA. AAAI.
[Zhuang et al., 2015] Zhuang, F., Cheng, X., Luo, P., Pan, S. J., and He, Q. (2015). Supervised representation learning: Transfer learning with deep autoencoders. In IJCAI,pages 4119-4125.
[Zhuo et al., 2017] Zhuo, J., Wang, S., Zhang, W., and Huang, Q. (2017). Deep unsupervised convolutional domain adaptation. In Proceedings of the 2017 ACM on Multimedia Conference, pages 261-269. ACM.