🎩 欢迎来到技术探索的奇幻世界👨💻
📜 个人主页:@一伦明悦-CSDN博客
✍🏻 作者简介: C++软件开发、Python机器学习爱好者
🗣️ 互动与支持:💬评论 👍🏻点赞 📂收藏 👀关注+
如果文章有所帮助,欢迎留下您宝贵的评论,
点赞加收藏支持我,点击关注,一起进步!
前言
AdaBoost分类树模型、梯度提升分类树模型、Bagging分类树模型以及随机森林分类模型是常见且有效的机器学习算法。以下是它们的详细介绍:
AdaBoost分类树模型:
- 基本原理:AdaBoost(Adaptive Boosting)是一种集成学习方法,通过串行训练一系列弱分类器(通常是决策树),每个分类器都试图修正前一个分类器的错误,从而提升整体性能。
- 工作流程:首先给每个样本赋予相等的权重,训练第一个分类器并根据分类结果调整样本权重,使得错误分类的样本在下一个分类器训练中获得更高的权重。迭代过程中,每个分类器的权重由其准确性决定。
- 优点:对于复杂问题表现良好,能够处理高维度数据和大量样本。
- 缺点:对噪声和异常值敏感,可能导致过拟合。
梯度提升分类树模型:
- 基本原理:梯度提升(Gradient Boosting)也是一种集成学习技术,但它是通过构建多个决策树(弱学习器)的集合来提升模型性能。每个新树的构建都是为了减少前一棵树在训练集上的残差(预测错误)。
- 工作流程:从第一个简单模型(通常是决策树)开始,每个后续模型都专注于修正前面所有模型的预测误差。
- 优点:效果较好且健壮,不易受到噪声干扰。
- 缺点:相较于AdaBoost,更容易过拟合,训练时间较长。
Bagging分类树模型:
- 基本原理:Bagging(Bootstrap Aggregating)通过构建多个相互独立的分类器(决策树),并在平均预测结果以减少方差和提升泛化能力。
- 工作流程:通过随机选择样本(有放回抽样)和特征进行训练,每个分类器权重相等且相互独立。
- 优点:降低了过拟合风险,适合高方差的模型。
- 缺点:可能增加模型解释性的难度,不利于模型结果的可解释性。
随机森林分类模型:
- 基本原理:随机森林是一种集成学习技术,构建多个决策树并将它们集成为一个强大的模型。每个决策树都是在不同的随机样本和随机特征集上训练。
- 工作流程:通过投票或取平均值来提高预测准确率,每个树都在随机样本子集上训练。
- 优点:高度并行化处理,适用于高维度数据和大型数据集,对异常值和噪声具有较好的鲁棒性。
- 缺点:对于高度相关的特征可能表现不佳,需要较多内存和计算资源。
正文
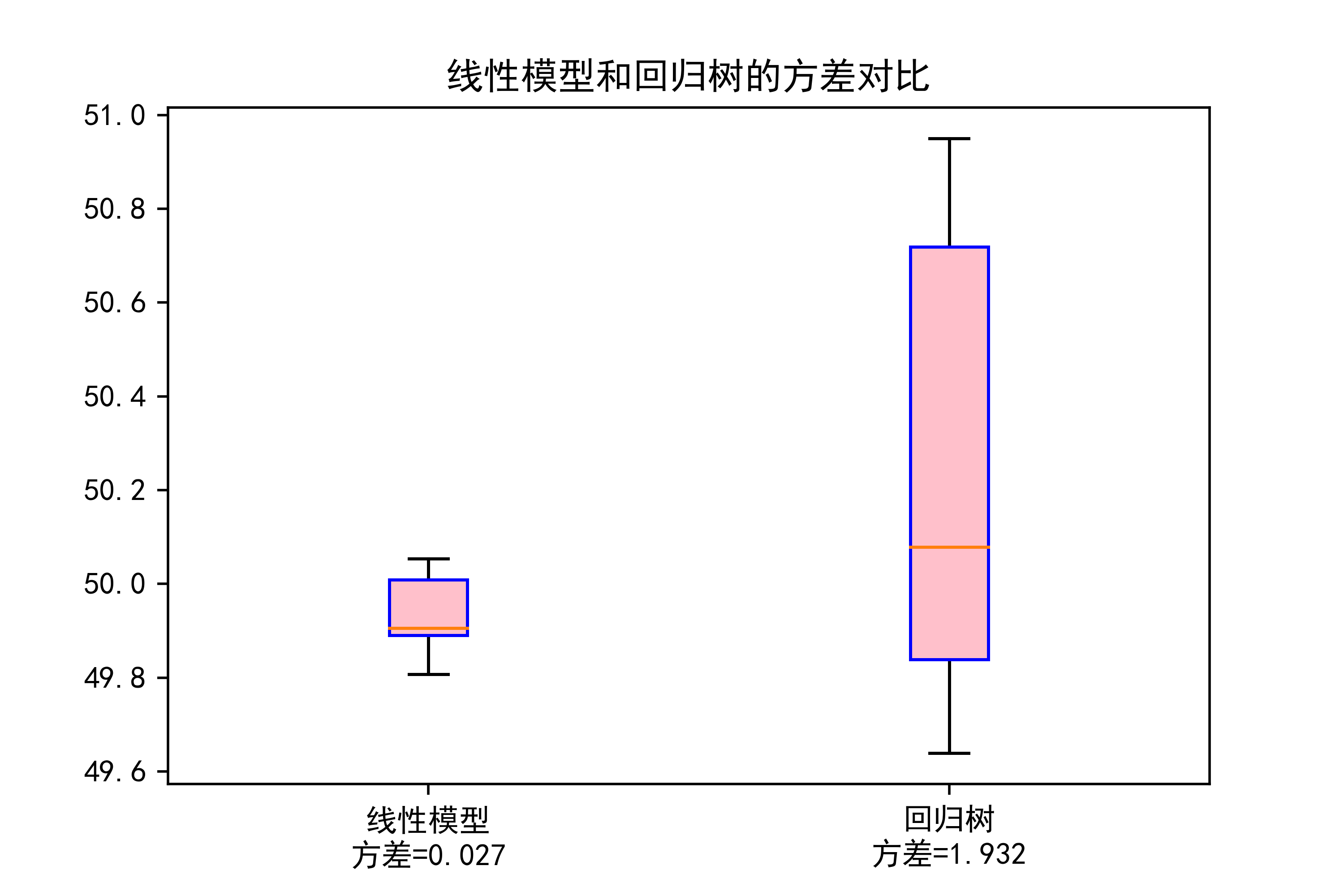
01-线性模型和回归树的方差对比
这段代码主要是对线性模型和回归树模型的方差进行比较,并通过箱线图展示。下面是对代码的详细解释和代码作用:
导入模块:导入所需的Python库和模块,包括numpy、pandas、warnings(用于警告处理)、matplotlib.pyplot(用于绘图)、sklearn中的相关模块(用于机器学习)、xgboost(用于梯度提升)、以及读取数据的excel文件。
数据预处理:读取数据,并进行一系列数据清洗操作,包括将0替换为NaN(缺失值),删除包含NaN的行,筛选满足条件的数据,并将特征(‘SO2’和’CO’)赋值给X,目标变量(‘PM2.5’)赋值给Y。
模型选择:定义了两个模型,一个是决策树回归模型(modelDTC),另一个是线性回归模型(modelLR),并设置了模型参数(决策树最大深度为3,随机种子为123)。
交叉验证:使用KFold进行10折交叉验证,将数据集分为训练集和测试集,循环训练模型并预测。
箱线图绘制:利用matplotlib.pyplot绘制箱线图,比较了线性模型和回归树模型的方差情况。在箱线图中,红色圆点代表中位数,红色线段表示上下四分位数,箱体内的蓝色盒子表示数据分布的中间50%区域,盒子外的蓝色线段表示数据的范围,其中数据点是异常值(如果有的话)。
保存图像:通过plt.savefig将绘制的箱线图保存为PNG格式的图片文件。
这段代码的主要作用是比较线性模型和回归树模型在预测PM2.5浓度时的方差情况,并以可视化的方式展示结果,有助于分析模型的性能和稳定性。
#本章需导入的模块
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error
import xgboost as xgb
data=pd.read_excel('北京市空气质量数据.xlsx')
data=data.replace(0,np.NaN)
data=data.dropna()
data=data.loc[(data['PM2.5']<=200) & (data['SO2']<=20)]
X=data[['SO2','CO']]
Y=data['PM2.5']
X0=np.array(X.mean()).reshape(1,-1)
modelDTC = tree.DecisionTreeRegressor(max_depth=3,random_state=123)
modelLR=LM.LinearRegression()
model1,model2=[],[]
kf = KFold(n_splits=10,shuffle=True,random_state=123)
for train_index, test_index in kf.split(X):
Ntrain=len(train_index)
XKtrain=X.iloc[train_index]
YKtrain=Y.iloc[train_index]
modelLR.fit(XKtrain,YKtrain)
modelDTC.fit(XKtrain,YKtrain)
model1.append(float(modelLR.predict(X0)))
model2.append(float(modelDTC.predict(X0)))
plt.boxplot(x=model1,sym='rd',patch_artist=True,boxprops={'color':'blue','facecolor':'pink'},
labels ={"线性模型\n方差=%.3f"%np.var(model1)},showfliers=False)
plt.boxplot(x=model2,sym='rd',positions=[2],patch_artist=True,boxprops={'color':'blue','facecolor':'pink'},
labels ={"回归树\n方差=%.3f"%np.var(model2)},showfliers=False)
plt.title("线性模型和回归树的方差对比")
plt.savefig("../4.png", dpi=500)运行结果如下图所示
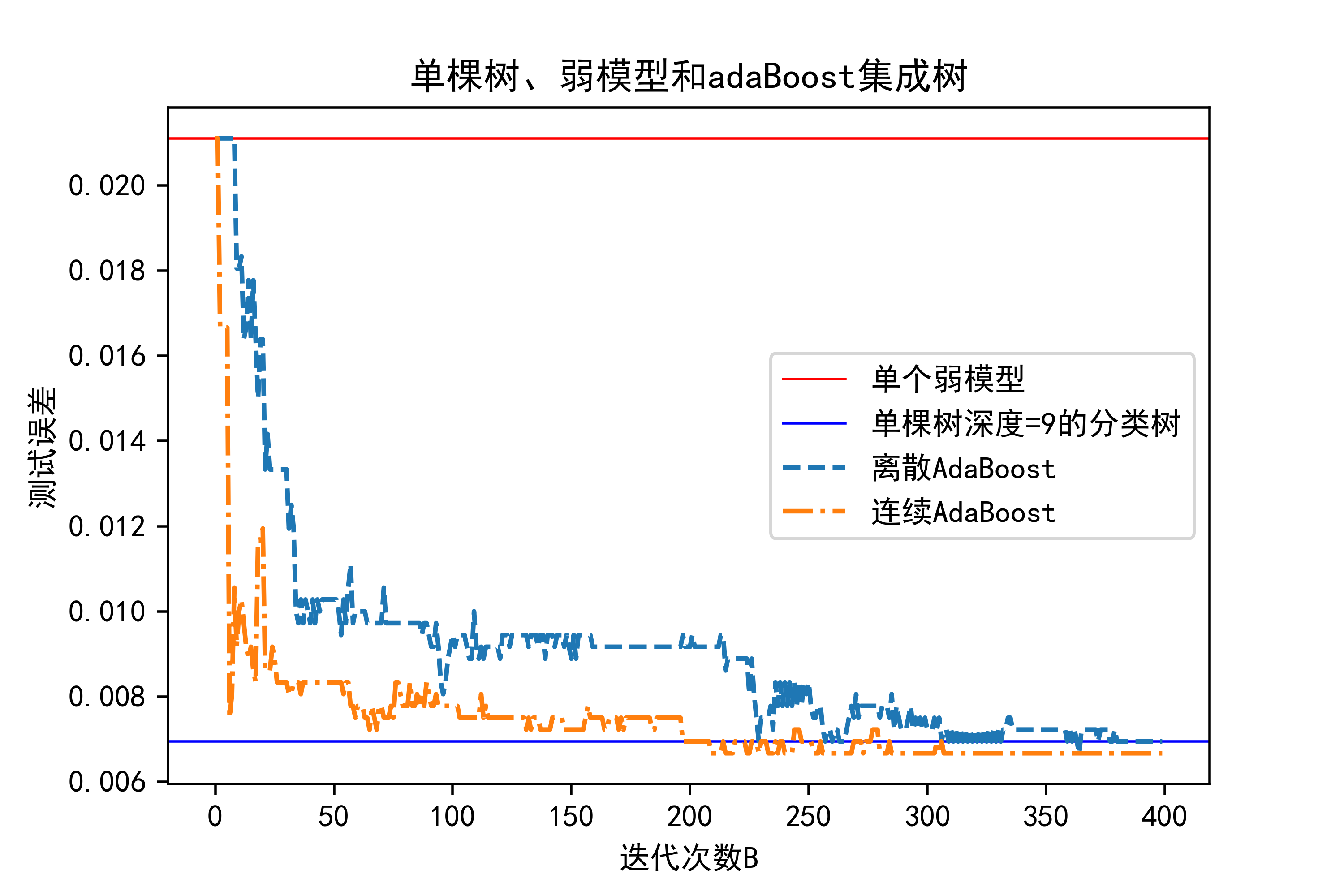
02-对比单棵决策树、弱模型以及提升策略的预测效果
这段代码主要是用于比较单棵决策树、单个弱分类模型以及使用AdaBoost集成的分类器在测试集上的误差表现,并通过可视化结果展示比较。
导入模块:首先导入需要使用的Python库和模块,包括numpy、pandas、warnings(用于警告处理)、matplotlib.pyplot(用于绘图)、sklearn中的相关模块(用于机器学习)、xgboost(用于梯度提升)。
生成数据集:使用
make_classification生成一个虚拟的分类数据集,包括12000个样本和10个特征,其中具有信息性的特征有2个,设置了随机种子和类别间的簇数。数据集划分:使用
train_test_split将数据集划分为训练集和测试集,其中训练集占70%。定义单棵决策树模型:创建了两个不同深度的决策树分类器(
dt_stump和dt),并计算它们在测试集上的分类误差。AdaBoost集成模型:
- 离散AdaBoost:使用
ensemble.AdaBoostClassifier构建基于dt_stump的AdaBoost分类器,设置了400个估计器(基分类器),使用SAMME算法。- 连续AdaBoost:同样基于
dt_stump构建AdaBoost分类器,但使用了SAMME.R算法。误差计算:
- 对离散AdaBoost和连续AdaBoost模型分别使用
staged_predict方法来逐步预测测试集,然后计算每次迭代的分类误差(zero_one_loss),并将结果存储在ada_discrete_err和ada_real_err数组中。绘制图形:
- 创建一个新的图形(
fig),添加子图(axes)。- 使用
axhline绘制水平线,表示单个弱分类模型(dt_stump_err)和深度为9的单棵树模型(dt_err)的分类误差。- 使用
plot绘制离散AdaBoost和连续AdaBoost的分类误差随迭代次数变化的曲线。- 设置图的标题、x轴和y轴标签,添加图例用于说明每条曲线的含义。
保存和显示图像:
- 使用
plt.savefig将绘制的图形保存为PNG格式的图片文件,保存路径为"…/4.png",设置分辨率为500dpi。- 使用
plt.show()显示绘制的图形在屏幕上。这段代码的主要作用是通过实验和可视化分析,比较不同模型在分类任务中的表现,特别是单棵树、单个弱分类模型与使用AdaBoost集成的模型之间的性能差异。
#本章需导入的模块
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
X,Y=make_classification(n_samples=12000,n_features=10,n_redundant=0,n_informative=2,random_state=123,n_clusters_per_class=1)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
dt_stump = tree.DecisionTreeClassifier(max_depth=1, min_samples_leaf=1)
dt_stump.fit(X_train, Y_train)
dt_stump_err = 1.0 - dt_stump.score(X_test, Y_test)
dt = tree.DecisionTreeClassifier(max_depth=9, min_samples_leaf=1)
dt.fit(X_train, Y_train)
dt_err = 1.0 - dt.score(X_test, Y_test)
B=400
ada_discrete = ensemble.AdaBoostClassifier(base_estimator=dt_stump,n_estimators=B,algorithm="SAMME")
ada_discrete.fit(X_train, Y_train)
ada_real = ensemble.AdaBoostClassifier(base_estimator=dt_stump,n_estimators=B,algorithm="SAMME.R")
ada_real.fit(X_train, Y_train)
ada_discrete_err = np.zeros((B,))
for i,Y_pred in enumerate(ada_discrete.staged_predict(X_test)):
ada_discrete_err[i] = zero_one_loss(Y_pred, Y_test)
ada_real_err = np.zeros((B,))
for i, Y_pred in enumerate(ada_real.staged_predict(X_test)):
ada_real_err[i] = zero_one_loss(Y_pred, Y_test)
fig = plt.figure()
axes = fig.add_subplot(111)
axes.axhline(y=dt_stump_err,c='red',linewidth=0.8,label='单个弱模型')
axes.axhline(y=dt_err,c='blue',linewidth=0.8,label='单棵树深度=9的分类树')
axes.plot(np.arange(B), ada_discrete_err,linestyle='--',label='离散AdaBoost')
axes.plot(np.arange(B), ada_real_err,linestyle='-.',label='连续AdaBoost')
axes.set_xlabel('迭代次数B')
axes.set_ylabel('测试误差')
axes.set_title('单棵树、弱模型和adaBoost集成树')
axes.legend()
#leg = axes.legend(loc='upper right', fancybox=True)
#leg.get_frame().set_alpha(0.7)
plt.savefig("../4.png", dpi=500)
plt.show()运行结果如下图所示
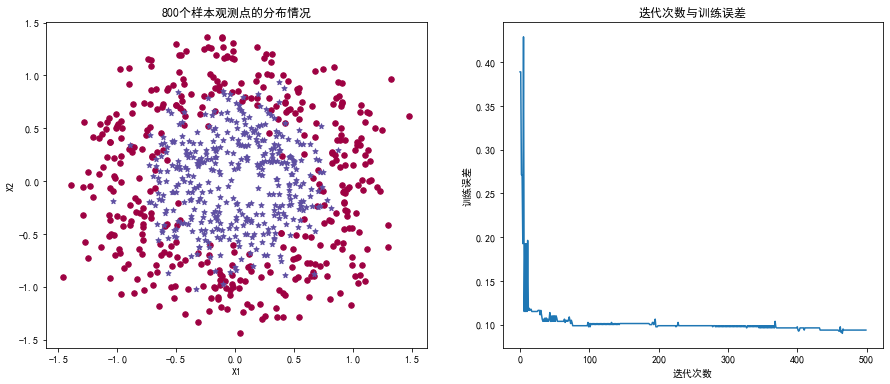
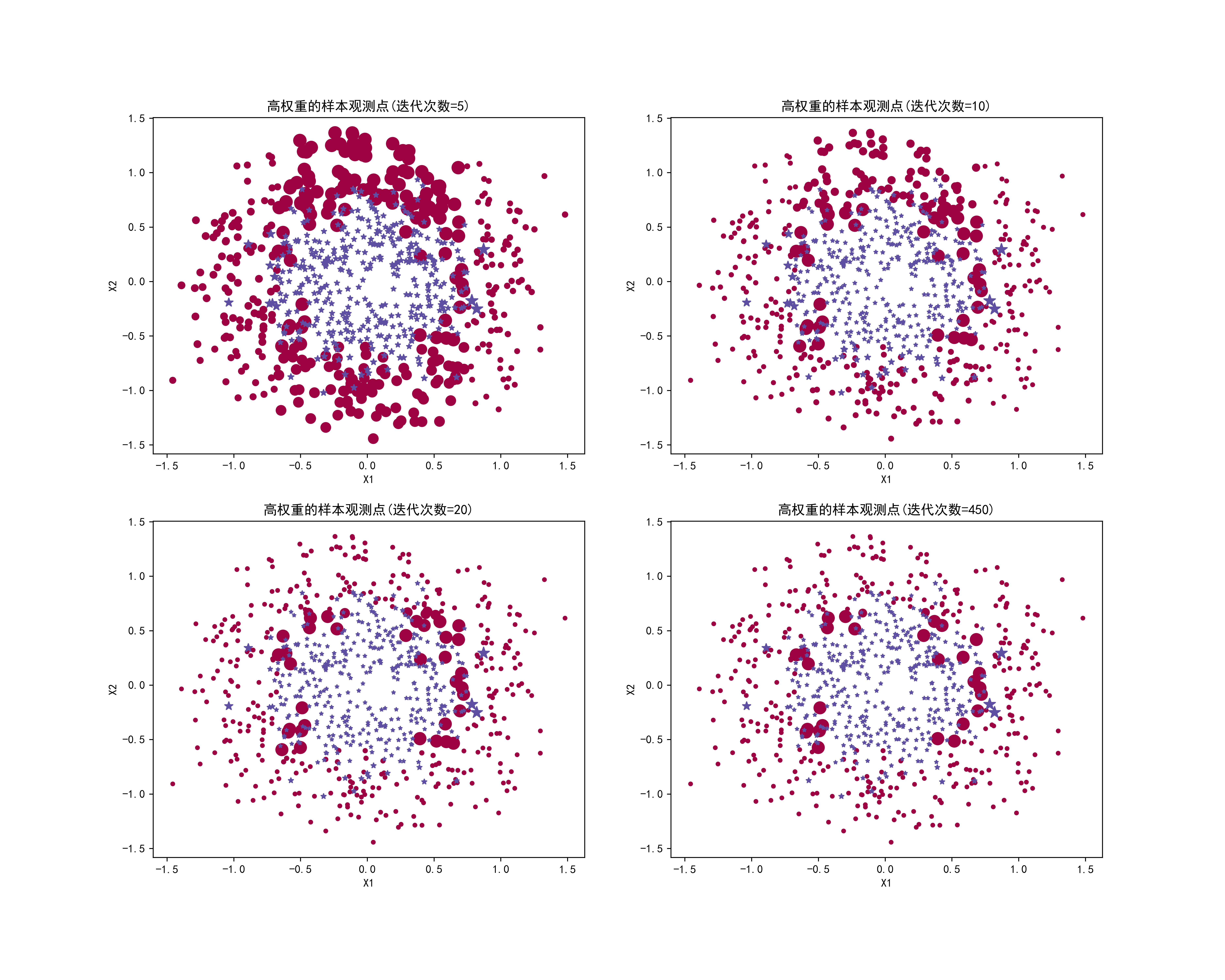
03-基于模拟数据直观观察提升策略下高权重样本观测随迭代次数的变化情况
这段代码是用来实现 AdaBoost 算法在分类问题上的可视化和分析。
模块导入和数据生成:
- 导入所需的库和模块,生成了一个圆环形状的数据集 (
make_circles),用于二分类任务。数据可视化:
- 使用
matplotlib在一个图形中展示了生成的样本数据分布情况,其中不同类别的样本用不同颜色和形状的点表示。AdaBoost 分类器初始化和训练:
- 初始化了一个基础决策树分类器 (
DecisionTreeClassifier) 作为 AdaBoost 的基学习器 (dt_stump)。- 使用
ensemble.AdaBoostClassifier初始化 AdaBoost 分类器,并进行训练 (adaBoost.fit(X, Y))。训练误差的迭代可视化:
- 创建了一个子图展示了随着迭代次数增加,AdaBoost 在训练集上的误差变化 (
adaBoostErr)。样本权重调整:
- 创建了一个大图 (
fig),在多个子图中展示了在不同迭代次数下,权重高的样本点的分布情况。- 对于每个迭代步骤,根据 AdaBoost 的表现调整样本的权重,将权重高的样本以更大的大小和特定的颜色表示,以突出它们对分类器的重要性。
代码作用:
- 生成二维非线性分类数据集。
- 使用 AdaBoost 算法进行训练,并监控训练误差随着迭代次数的变化。
- 可视化不同迭代步骤下样本的分布情况,突出对分类器贡献大的样本。
保存结果:
- 最终将生成的图形保存为
4.png文件,以便进一步分析和展示。这段代码通过可视化展示了 AdaBoost 算法如何通过迭代,调整样本权重并提高分类器性能,适用于理解和教学机器学习中的集成学习方法。
#本章需导入的模块
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
N=800
X,Y=make_circles(n_samples=N,noise=0.2,factor=0.5,random_state=123)
unique_lables=set(Y)
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(15,6))
colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))
markers=['o','*']
for k,col,m in zip(unique_lables,colors,markers):
x_k=X[Y==k]
#plt.plot(x_k[:,0],x_k[:,1],'o',markerfacecolor=col,markeredgecolor="k",markersize=8)
axes[0].scatter(x_k[:,0],x_k[:,1],color=col,s=30,marker=m)
axes[0].set_title('%d个样本观测点的分布情况'%N)
axes[0].set_xlabel('X1')
axes[0].set_ylabel('X2')
dt_stump = tree.DecisionTreeClassifier(max_depth=1, min_samples_leaf=1)
B=500
adaBoost = ensemble.AdaBoostClassifier(base_estimator=dt_stump,n_estimators=B,algorithm="SAMME",random_state=123)
adaBoost.fit(X,Y)
adaBoostErr = np.zeros((B,))
for b,Y_pred in enumerate(adaBoost.staged_predict(X)):
adaBoostErr[b] = zero_one_loss(Y,Y_pred)
axes[1].plot(np.arange(B),adaBoostErr,linestyle='-')
axes[1].set_title('迭代次数与训练误差')
axes[1].set_xlabel('迭代次数')
axes[1].set_ylabel('训练误差')
fig = plt.figure(figsize=(15,12))
data=np.hstack((X.reshape(N,2),Y.reshape(N,1)))
data=pd.DataFrame(data)
data.columns=['X1','X2','Y']
data['Weight']=[1/N]*N
for b,Y_pred in enumerate(adaBoost.staged_predict(X)):
data['Y_pred']=Y_pred
data.loc[data['Y']!=data['Y_pred'],'Weight'] *= (1.0-adaBoost.estimator_errors_[b])/adaBoost.estimator_errors_[b]
if b in [5,10,20,450]:
axes = fig.add_subplot(2,2,[5,10,20,450].index(b)+1)
for k,col,m in zip(unique_lables,colors,markers):
tmp=data.loc[data['Y']==k,:]
tmp['Weight']=10+tmp['Weight']/(tmp['Weight'].max()-tmp['Weight'].min())*100
axes.scatter(tmp['X1'],tmp['X2'],color=col,s=tmp['Weight'],marker=m)
axes.set_xlabel('X1')
axes.set_ylabel('X2')
axes.set_title("高权重的样本观测点(迭代次数=%d)"%b)
plt.savefig("../4.png", dpi=500) 运行结果如下图所示:
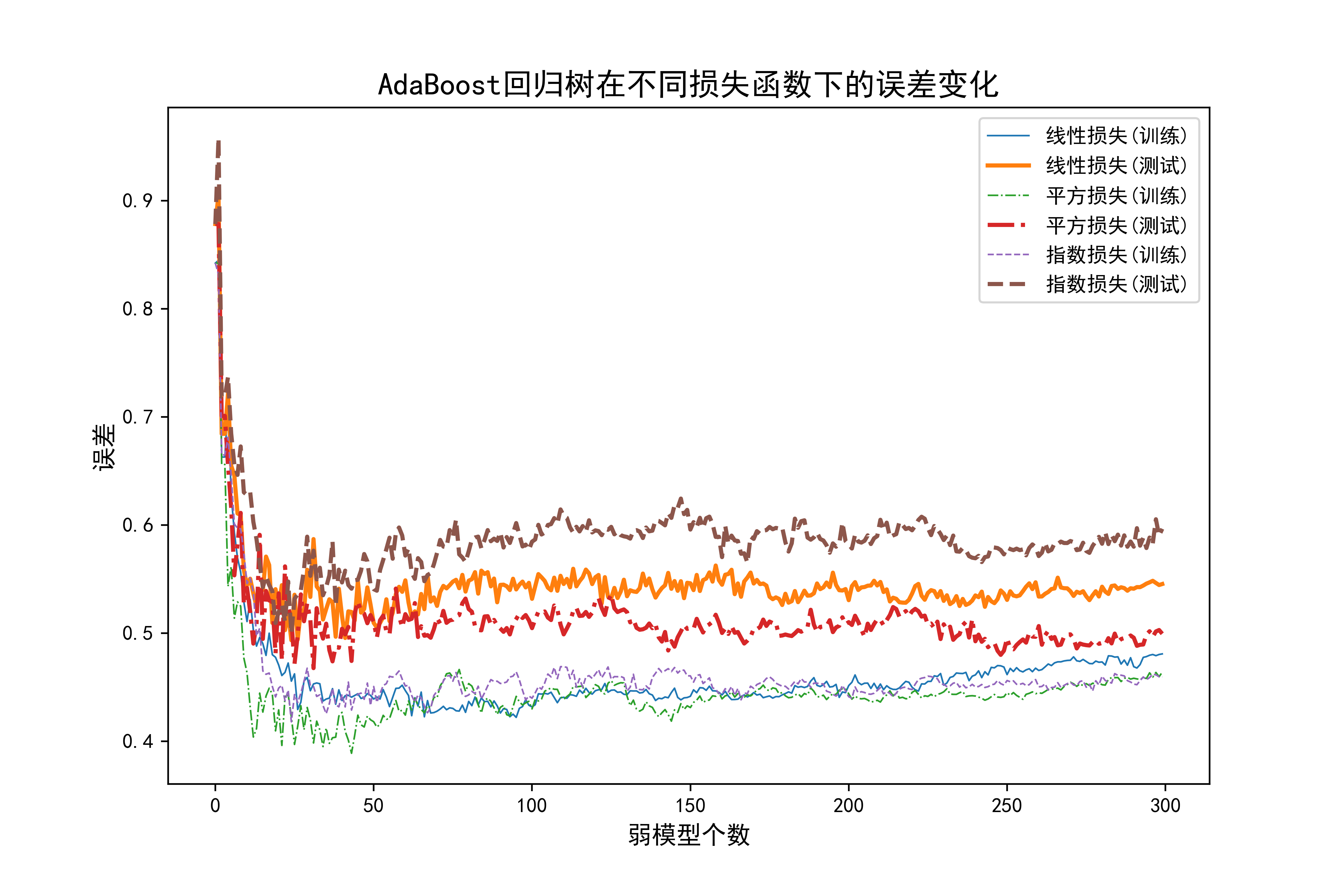
04-AdaBoost回归树在不同损失函数下的误差变化
这部分代码是在Python环境下使用Scikit-Learn进行AdaBoost回归树模型的实验和结果可视化。让我来逐步解释:
导入模块:
- 导入了常用的数据处理(NumPy、Pandas)、警告管理、绘图(Matplotlib)、机器学习模型相关的库(Scikit-Learn)、XGBoost等模块。
生成数据:
- 使用
make_regression生成了1000个样本,每个样本包含10个特征,并将数据分为训练集(70%)和测试集(30%)。定义AdaBoost模型参数:
B=300:设定弱学习器的数量为300。dt_stump:定义了一个决策树回归模型作为基础估计器,限定了最大深度为1,叶子节点最小样本数为1。损失函数设置:
- 定义了三种损失函数的名称(中文)和对应的英文名,以及绘图时使用的线型。
循环绘制学习曲线:
- 对每种损失函数,循环进行如下操作:
- 创建一个AdaBoost回归器(
ensemble.AdaBoostRegressor),使用前面定义的决策树回归器作为基础模型,设定300个弱学习器,指定损失函数。- 在训练集上拟合AdaBoost模型,并使用
staged_predict方法获取每个阶段(每个弱学习器)的预测结果。- 计算每个阶段的训练误差(1 - R^2分数)和测试误差,并保存在
TrainErrAdaB和TestErrAdaB数组中。- 绘制训练误差曲线和测试误差曲线,使用不同的线型区分不同损失函数。
绘图设置:
- 设置图形的标题、横轴标签、纵轴标签,添加图例,并保存为PNG格式的文件(
4.png)。这段代码的目的是比较不同损失函数在AdaBoost回归树中的表现,通过绘制训练误差和测试误差随弱模型数量变化的曲线,来评估不同损失函数对模型性能的影响。
#本章需导入的模块
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
N=1000
X,Y=make_regression(n_samples=N,n_features=10,random_state=123)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
B=300
dt_stump = tree.DecisionTreeRegressor(max_depth=1, min_samples_leaf=1)
Loss=['linear', 'square', 'exponential']
LossName=['线性损失','平方损失','指数损失']
Lines=['-','-.','--']
plt.figure(figsize=(9,6))
for lossname,loss,lines in zip(LossName,Loss,Lines):
TrainErrAdaB=np.zeros((B,))
TestErrAdaB=np.zeros((B,))
adaBoost = ensemble.AdaBoostRegressor(base_estimator=dt_stump,n_estimators=B,loss=loss,random_state=123)
adaBoost.fit(X_train,Y_train)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_train)):
TrainErrAdaB[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_test)):
TestErrAdaB[b]=1-r2_score(Y_test,Y_pred)
plt.plot(np.arange(B),TrainErrAdaB,linestyle=lines,label="%s(训练)"%lossname,linewidth=0.8)
plt.plot(np.arange(B),TestErrAdaB,linestyle=lines,label="%s(测试)"%lossname,linewidth=2)
plt.title("AdaBoost回归树在不同损失函数下的误差变化",fontsize=15)
plt.xlabel("弱模型个数",fontsize=12)
plt.ylabel("误差",fontsize=12)
plt.legend()
plt.savefig("../4.png", dpi=500) 运行结果如下图所示:
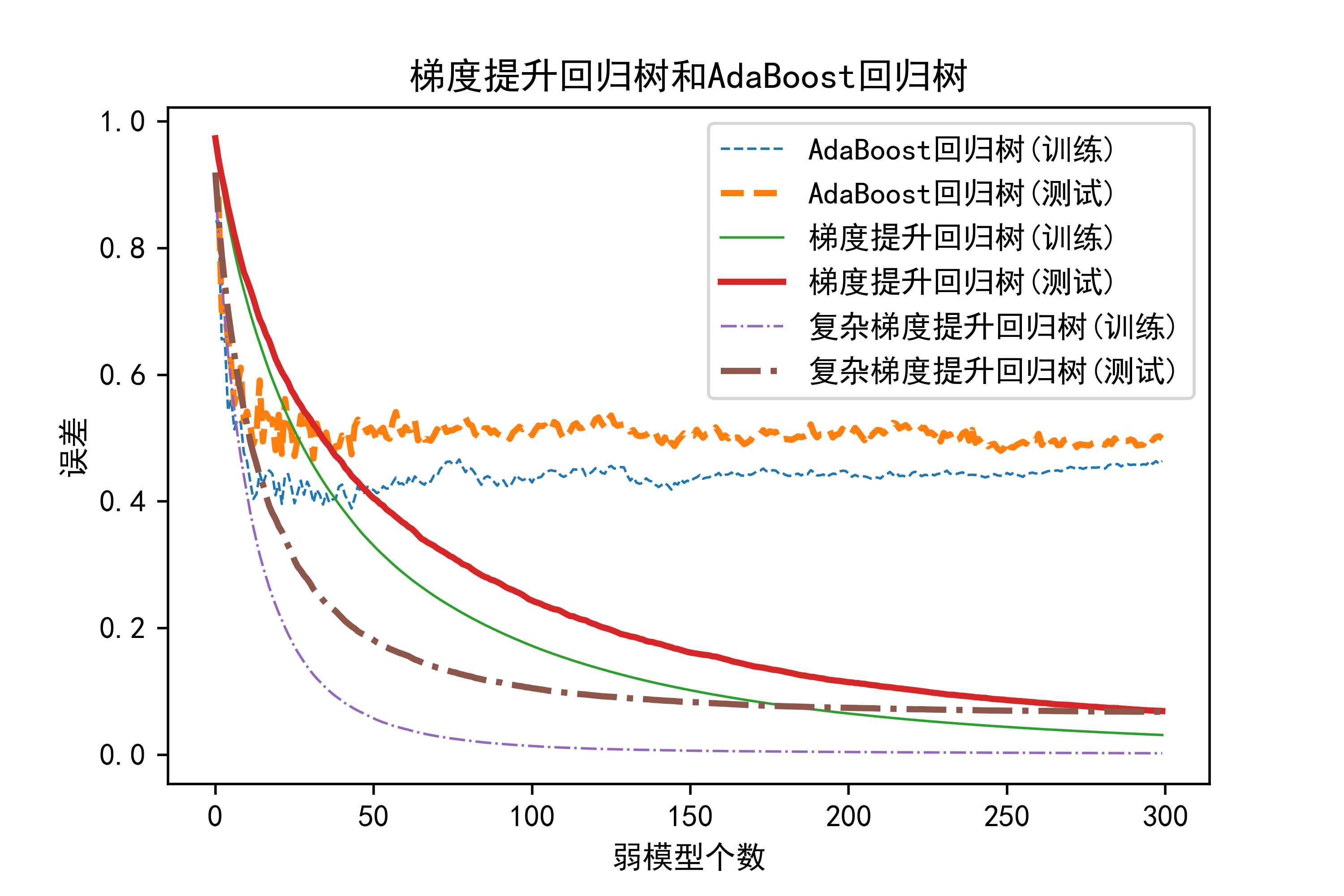
05-基于模拟数据对比梯度提升算法和提升策略回归树的预测性能
这部分代码是在Python环境下使用Scikit-Learn进行梯度提升回归树(Gradient Boosting Regression Trees)和AdaBoost回归树的实验和结果可视化。让我来逐步解释:
导入模块:
- 导入了常用的数据处理(NumPy、Pandas)、警告管理、绘图(Matplotlib)、机器学习模型相关的库(Scikit-Learn)、XGBoost等模块。
生成数据:
- 使用
make_regression生成了1000个样本,每个样本包含10个特征,并将数据分为训练集(70%)和测试集(30%)。定义AdaBoost回归树参数:
B=300:设定弱学习器的数量为300。dt_stump:定义了一个决策树回归模型作为基础估计器,限定了最大深度为1,叶子节点最小样本数为1。拟合和评估AdaBoost回归树:
- 创建一个AdaBoost回归器(
ensemble.AdaBoostRegressor),使用前面定义的决策树回归器作为基础模型,设定300个弱学习器,指定损失函数为平方损失。- 在训练集上拟合AdaBoost模型,并使用
staged_predict方法获取每个阶段(每个弱学习器)的预测结果。- 计算每个阶段的训练误差(1 - R^2分数)和测试误差,并保存在
TrainErrAdaB和TestErrAdaB数组中。拟合和评估梯度提升回归树:
- 创建两个梯度提升回归器:一个使用最大深度为1,另一个使用最大深度为3。
- 使用与AdaBoost回归树相同的步骤,在训练集和测试集上拟合和评估模型。
绘图:
- 使用
plt.plot函数绘制三条曲线,分别代表AdaBoost回归树的训练误差、测试误差,以及两个梯度提升回归树的训练误差和测试误差。- 使用不同的线型区分不同的模型。
#本章需导入的模块
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
pd.set_option('display.max_columns', None) # 显示所有列
pd.set_option('display.max_rows', None) # 显示所有行
pd.set_option('display.max_colwidth',1000)
N=1000
X,Y=make_regression(n_samples=N,n_features=10,random_state=123)
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
B=300
dt_stump = tree.DecisionTreeRegressor(max_depth=1, min_samples_leaf=1)
TrainErrAdaB=np.zeros((B,))
TestErrAdaB=np.zeros((B,))
adaBoost = ensemble.AdaBoostRegressor(base_estimator=dt_stump,n_estimators=B,loss= 'square',random_state=123)
adaBoost.fit(X_train,Y_train)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_train)):
TrainErrAdaB[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_test)):
TestErrAdaB[b]=1-r2_score(Y_test,Y_pred)
GBRT=ensemble.GradientBoostingRegressor(loss='ls',n_estimators=B,max_depth=1,min_samples_leaf=1,random_state=123)
GBRT.fit(X_train,Y_train)
TrainErrGBRT=np.zeros((B,))
TestErrGBRT=np.zeros((B,))
for b,Y_pred in enumerate(GBRT.staged_predict(X_train)):
TrainErrGBRT[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(GBRT.staged_predict(X_test)):
TestErrGBRT[b]=1-r2_score(Y_test,Y_pred)
GBRT0=ensemble.GradientBoostingRegressor(loss='ls',n_estimators=B,max_depth=3,min_samples_leaf=1,random_state=123)
GBRT0.fit(X_train,Y_train)
TrainErrGBRT0=np.zeros((B,))
TestErrGBRT0=np.zeros((B,))
for b,Y_pred in enumerate(GBRT0.staged_predict(X_train)):
TrainErrGBRT0[b]=1-r2_score(Y_train,Y_pred)
for b,Y_pred in enumerate(GBRT0.staged_predict(X_test)):
TestErrGBRT0[b]=1-r2_score(Y_test,Y_pred)
plt.plot(np.arange(B),TrainErrAdaB,linestyle='--',label="AdaBoost回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrAdaB,linestyle='--',label="AdaBoost回归树(测试)",linewidth=2)
plt.plot(np.arange(B),TrainErrGBRT,linestyle='-',label="梯度提升回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrGBRT,linestyle='-',label="梯度提升回归树(测试)",linewidth=2)
plt.plot(np.arange(B),TrainErrGBRT0,linestyle='-.',label="复杂梯度提升回归树(训练)",linewidth=0.8)
plt.plot(np.arange(B),TestErrGBRT0,linestyle='-.',label="复杂梯度提升回归树(测试)",linewidth=2)
plt.title("梯度提升回归树和AdaBoost回归树")
plt.xlabel("弱模型个数")
plt.ylabel("误差")
plt.legend()
plt.savefig("../4.png", dpi=500)运行结果如下图所示:
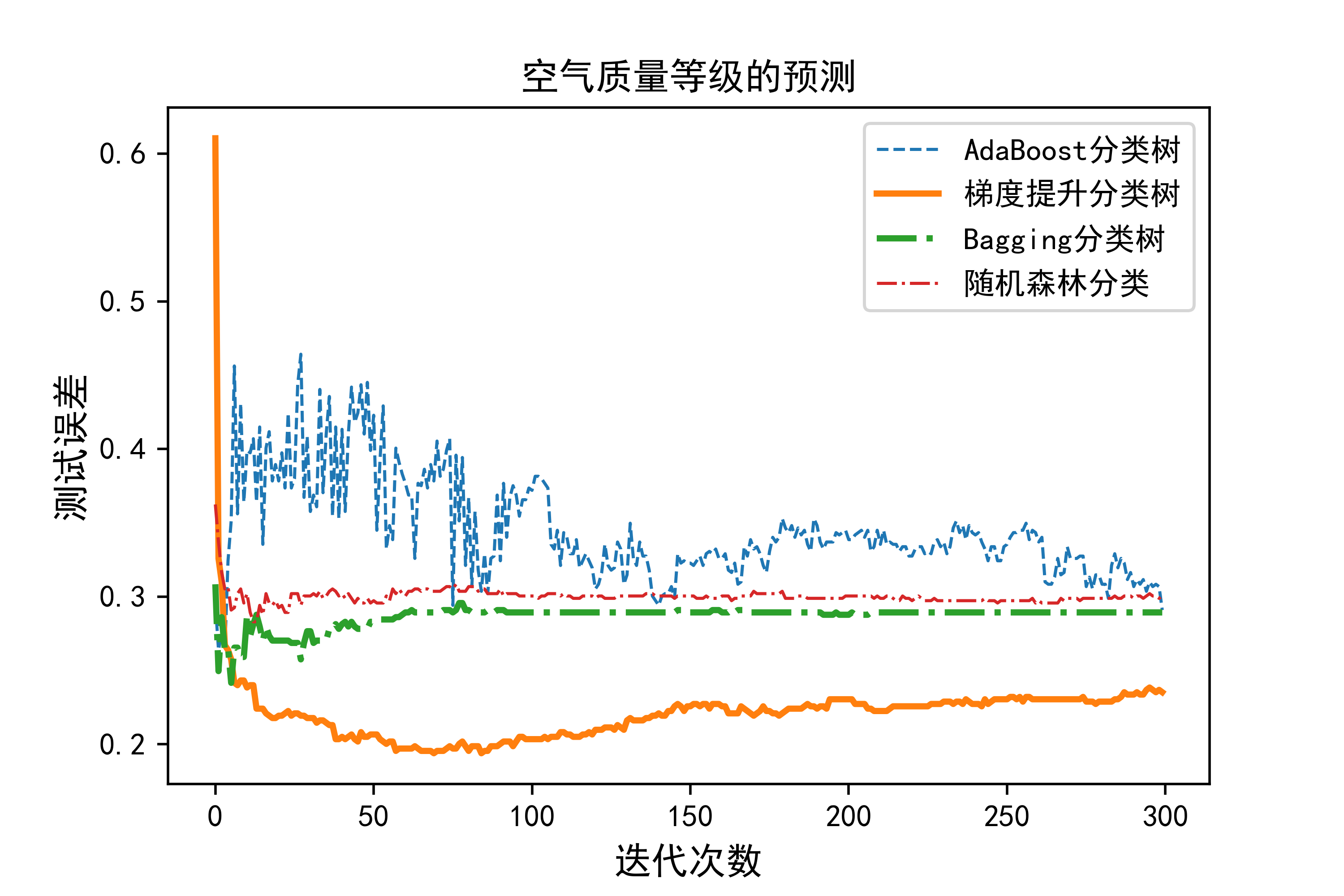
06-基于空气质量监测数据,采用集成学习的不同策略预测空气质量等级
这段代码是一个机器学习模型比较与可视化的示例,主要用于空气质量等级的预测和模型评估。
导入模块和数据加载:
- 首先导入了必要的Python库和模块,包括数据处理、模型建立和评估需要的工具。
- 加载了名为’北京市空气质量数据.xlsx’的Excel文件,将其转换为DataFrame格式,并进行了预处理:将所有值为0的数据替换为NaN,并删除包含NaN值的行。
数据准备和划分:
- 从处理后的数据中选择特征变量和目标变量(质量等级)。
- 使用
train_test_split函数将数据集划分为训练集(70%)和测试集(30%),并设置了随机种子以保证结果的可复现性。AdaBoost分类器:
- 使用
AdaBoostClassifier集成方法,基础分类器为DecisionTreeClassifier,迭代次数为B(此处设定为300)。- 计算每次迭代后的测试误差(zero_one_loss)并存储在
TestErrAdaB数组中。梯度提升分类树(GBRT):
- 使用
GradientBoostingClassifier,设定了损失函数(‘deviance’)、迭代次数B、树的最大深度和叶子节点的最小样本数等参数。- 同样计算每次迭代后的测试误差并存储在
TestErrGBRT数组中。Bagging和随机森林分类器:
- 使用
BaggingClassifier和RandomForestClassifier,基础分类器均为DecisionTreeClassifier。- 分别计算每个集成中不同数量基础分类器(从1到B)后的测试误差,并存储在
TestErrBag和TestErrRF数组中。可视化:
- 利用Matplotlib库绘制四种集成方法在不同迭代次数下的测试误差曲线。
- 设置图表的标题、坐标轴标签和图例,以及保存生成的图像文件到当前工作目录的上层目录(‘…/4.png’)。
总体来说,这段代码展示了如何使用Python中的
sklearn库进行集成学习模型(AdaBoost、梯度提升、Bagging和随机森林)的建模、评估和可视化过程,用于预测北京市空气质量等级,并通过测试误差来比较各模型的表现。
#本章需导入的模块
import numpy as np
import pandas as pd
import warnings
warnings.filterwarnings(action = 'ignore')
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei'] #解决中文显示乱码问题
plt.rcParams['axes.unicode_minus']=False
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn import tree
import sklearn.linear_model as LM
from sklearn import ensemble
from sklearn.datasets import make_classification,make_circles,make_regression
from sklearn.metrics import zero_one_loss,r2_score,mean_squared_error,accuracy_score
import xgboost as xgb
data=pd.read_excel('北京市空气质量数据.xlsx')
data=data.replace(0,np.NaN)
data=data.dropna()
X=data.iloc[:,3:-1]
Y=data['质量等级']
Y=Y.map({'优':'1','良':'2','轻度污染':'3','中度污染':'4','重度污染':'5','严重污染':'6'})
X_train, X_test, Y_train, Y_test = train_test_split(X,Y,train_size=0.70, random_state=123)
B=300
dt_stump = tree.DecisionTreeClassifier(max_depth=3, min_samples_leaf=1)
TestErrAdaB=np.zeros((B,))
adaBoost = ensemble.AdaBoostClassifier(base_estimator=dt_stump,n_estimators=B,random_state=123)
adaBoost.fit(X_train,Y_train)
for b,Y_pred in enumerate(adaBoost.staged_predict(X_test)):
TestErrAdaB[b]=zero_one_loss(Y_test,Y_pred)
TestErrGBRT=np.zeros((B,))
GBRT=ensemble.GradientBoostingClassifier(loss='deviance',n_estimators=B,max_depth=3,min_samples_leaf=1,random_state=123)
GBRT.fit(X_train,Y_train)
for b,Y_pred in enumerate(GBRT.staged_predict(X_test)):
TestErrGBRT[b]=zero_one_loss(Y_test,Y_pred)
TestErrBag=np.zeros((B,))
TestErrRF=np.zeros((B,))
for b in np.arange(B):
Bag=ensemble.BaggingClassifier(base_estimator=dt_stump,n_estimators=b+1,oob_score=True,random_state=123,bootstrap=True)
Bag.fit(X_train,Y_train)
TestErrBag[b]=1-Bag.score(X_test,Y_test)
RF=ensemble.RandomForestClassifier(max_depth=3,n_estimators=b+1,oob_score=True,random_state=123,
bootstrap=True,max_features="auto")
RF.fit(X_train,Y_train)
TestErrRF[b]=1-RF.score(X_test,Y_test)
plt.figure(figsize=(6,4))
plt.plot(np.arange(B),TestErrAdaB,linestyle='--',label="AdaBoost分类树",linewidth=1)
plt.plot(np.arange(B),TestErrGBRT,linestyle='-',label="梯度提升分类树",linewidth=2)
plt.plot(np.arange(B),TestErrBag,linestyle='-.',label="Bagging分类树",linewidth=2)
plt.plot(np.arange(B),TestErrRF,linestyle='-.',label="随机森林分类",linewidth=1)
plt.title("空气质量等级的预测",fontsize=12)
plt.xlabel("迭代次数",fontsize=12)
plt.ylabel("测试误差",fontsize=12)
plt.legend()
plt.savefig("../4.png", dpi=500)运行结果如下图所示:
总结
总结:这些模型各有特点,选择适当的模型取决于数据特性、问题复杂度以及对预测性能和解释性的需求。在实际应用中,通常需要通过交叉验证等方法来评估和比较它们的性能。

![[AIGC] 图论基础入门](https://img-blog.csdnimg.cn/img_convert/1b1b033c7735acd2549ae12a15d86dba.png)