1.概述
一年来多以来,大语言模型发展和变化越来越快,总体呈现出模型尺寸越变越大,算力需求越来越多,模型推理要求越来越高的特点。在这种背景下,现在不同的人关于垂域 LLM 出现了一些争议,一部分人认为随着大模型的能力越来越强,垂类的知识会加训融合到大模型。 尤其当下,在 GPT-4o 效果一枝独秀的前提下,其他无论是通用模型,还是基于垂类模型都被 GPT-4o 吊打,一个典型的对比就是 GPT-4o 加持的Code Colpliot的代码能力一点都不逊色与Devins等智能体工程师。同时另一种声音则认为垂类模型必然存在,也是具体落地到业务场景尤其是 ToB 业务场景时是必然的选择,近来模型社区不断放出来的 DB-GPT、CodeGPT、LawGPT、FinGPT 等项目。由于ToB行业对数据敏感性的高要求,所以不可能将一个企业的核心数据资产去做通用大模型训练,所以垂域大模型是存在的。目前,许多大语言模型已经在多个垂直领域有了微调实践,以提高它们在特定任务上的表现。例如,在医疗领域的华佗大模型、金融方面的轩辕大模型、法律上的韩非大模型。微调后的模型可以更好地理解和处理专业术语,提供更准确的回答。目前大模型微调的方法基本思路就是在通用LLM上结合目标领域的小规模有标注数据上进行有监督学习(SFT)。这可以通过在模型的训练过程中添加领域相关的知识和信息,来提高模型的适应性。在微调实践中,通过总结经验人们得出了一些宝贵的经验,但是在垂直领域微调如何在低成本的条件下实现针对性的高质量微调还是存在一些困难。
2.基座模型选择
在垂直领域LLM微调时选择合适的基座模型是十分重要的。垂直领域(纵深领域)一般都是建立在通识知识之上的, 基座模型选择的好环会对后期微调模型的好坏产生深远的影响。模型选择的不好就相当于是让一个本科阶段知识都没有学的学生直接跨入到研究生阶段,学起来不仅会很吃力(成本),是很难学会的(结果)。在选择基座模型进行垂直领域微调时,需要综合考虑模型性能、规模、社区支持与文档、可扩展性与兼容性、训练数据的适用性、训练与推理效率、安全以及成本等多个因素。一般来说需要可以考虑以下原则:
1、首先选择那些在通用任务中表现优异且在各种基准测试中取得高分的预训练模型,同时并确保其参数量和计算资源需求在可承受范围内。
2、选择具有良好社区支持和文档丰富度的LLM也是关键,可以保证在微调中能够提供及时帮助和丰富资源。
3、模型应具备良好的扩展能力,并与现有工具和框架兼容,以便于集成和部署。
4、预训练数据与目标领域数据的匹配度和模型在训练与推理过程中的效率也需考虑。
下图是常见底座模型的对比:
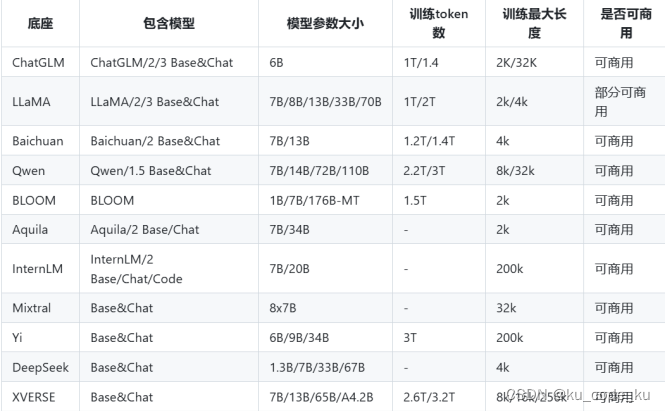
在考虑到目前是中文垂直领域知识问答。要求基座大模型应该具有:
文本理解能力包括但不限于
-
修辞手法理解与分析:理解文字中使用的各类修辞手法,能对相关修辞手法进行分析与解释。
-
文字内容总结:针对给定内容进行内容总结和信息抽取。。
语言能力包括但不限于:
-
字词理解与生成:从字词层面理解语言,并能完成诸如字词识别与分类,字词含义解释,字词生成等任务。
-
语法理解与修改:理解文字中的语法,并能错误语法表达进行识别和修改。
针对基座模型在各方面的表现,一站式测评平台司南模型测试排行榜单如下:

根据司南基座模型评测榜单以及目前公布的在法律,金融,医疗等垂直领域大模型的选择基座模型实际情况。综合考虑ChatGLM3-6B-Base 作为基座模型是当前比较推荐的。
ChatGLM3-6B-Base模型的司南基准测试结果如下:
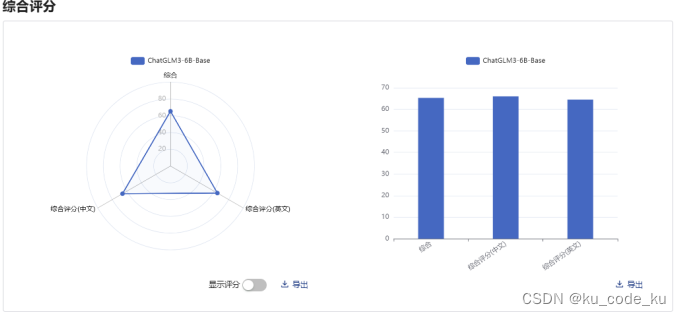
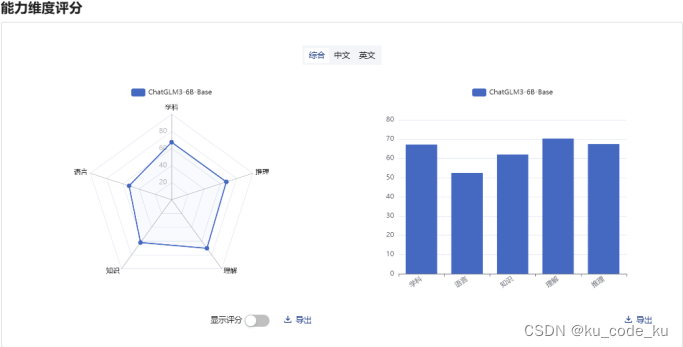
3.数据设计
在进行大模型微调前的数据设计的好坏也是直接影响后期微调性能的重要因素之一。一般来说数据设计分为数据构造和数据选择和数据使用三个阶段。
3.1 数据构造
在数据构造中,去收集语料集是简单的,但是根据语料集去编写高质量的微调数据是十分困难且成本不可控的。目前只考虑模型微调的情况下(不考虑二次预训练构建领域大模型基座),通常构建微调数据的方法大的方面来说有人工标注和格式化已有数据集。在格式化已有数据集中常见的方式有Self-Instruction和Self-QA以及Self-KV三种方式。其中Self-Instruction是指根据提前编写好的种子指令,让大模型比如GPT-4去参考种子指令去生成更多的微调数据;如果提前没有种子数据,就可以采用Self-QA方法直接根据非结构化的文档来来生成微调数据;Self-KV是指如果存在高质量的知识图谱就可以根据知识图谱来生成微调数据,这种方式就叫Self-KV。人工标注和格式化已有数据集的图解如下图:
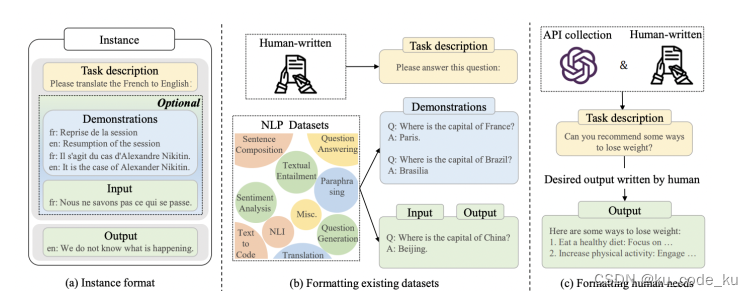
不同的构造方式存在不同的存在不同的特定如下图:
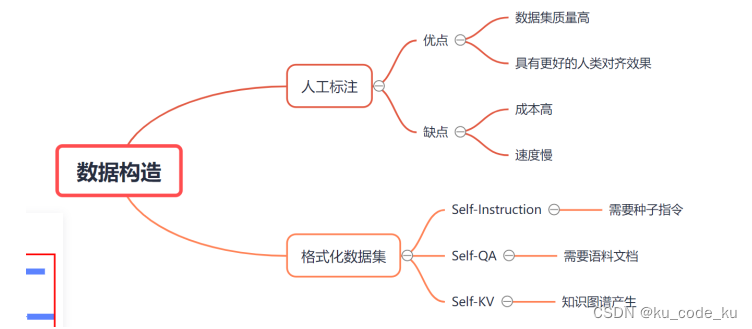
在调研中,目前在垂域大模型正式微调中在通用情况采用Self-QA和人工编写少量种子指令(一般来说正式微调中种子指令应该以100以上)再采用Self-Instrucion进行微调指令数据集的构建。
以基座模型ChatGLM3-6B-Base为例,官方公布的微调数据格式如下:
[
{
“instruction”: “Give three tips for staying healthy.”,
“input”: “”,
“output”: “1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule.”
},
…]
其中:instruction为用户指令;input为用户输入;output为模型回答;其中还有可选参数system和history用于更加复杂微调数据集的构建。在正式微调的过程中,指令量一般需要达到1W以上。
3.2 数据选择
在构建好微调数据之后就需要进行数据的选择。数据选择就是在微调数据中选择最适合模型训练的数据子集作为最终的训练数据集。数据选择中目前常见的做法就是通常首先要先进行数据去重,然后基于Nuggets方法来实现最优数据集的选择。
在进行数据去重时核心就是相似度的度量。一般目前来说最常用的就是基于对比学习构造的语义向量这套思路。在实现相似度度量之后就可以根据带条件约束聚类这种无监督学习算法让其保证多样性的同时让数据集的量最小。比如常见的K-center-greedy方法就可以实现条件约束的聚类。算法伪代码如下:

在从微调数据中选择最后数据子集时可以考虑采用Nuggets方法。它的具体做法可以参考下图:
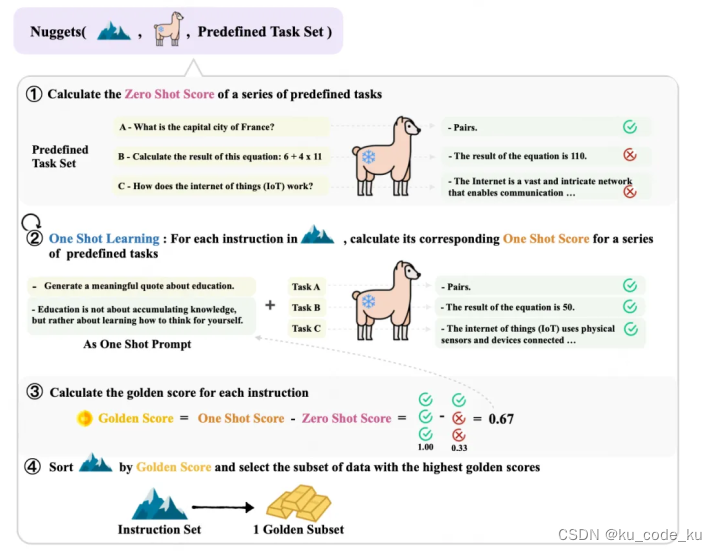
这个方法有三个输入分别是:一个大模型,用来评估数据好坏;Predefined Task Set 用来辅助评估数据好坏;Instruction Set就是等待筛选的大数据集。
输出目标就是Instruction Set的优秀子集,被称为Golden Set。
它认为,如果一条数据作为one-shot的那个shot,即作为一条例子作为参考,能使得大模型有这个参考后,比zeroshot提升很多,就认为这是一条高质量的数据。用公式表达就是:
![]()
3.3 数据使用
现在通过大模型微调实践,在具体使用数据进行大模型微调时目前通常达成的共识一般由以下几点:
-
在设计训练数据时数据的质量远比数据的数量要重要的多。
-
为防止灾难性遗忘,在微调时通常会考虑将专业领域知识和通用领域知识混合在一起进行训练。
-
如果涉及二次预训练,需要将一般添加5-10倍的原始训练的数据集中的数据。
-
在微调过程找出模型学习不好的那部分数据(对应模型PPL值变小)进行质量判断后进行针对性的加强训练。
4.设备选型
设备选型需要综合考虑到基座模型大小,训练数据量,以及成本等多种因素。由于大模型微调训练过程中设计大量的复杂的矩阵运算。因此目前在设备选型中一般会优先考虑GPU以及CPU的性能。然后是内存以及磁盘大小。最后是网络以及散热性能。
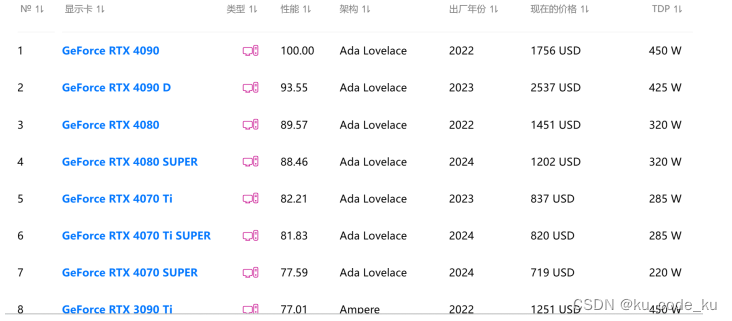
在GPU选型上,除少量公司如GOOGLE 采用TPU做大模型训练与推理外, 目前主流采用英伟达的GPU显卡作为大模型训练微调主要设备。在技术测评网上公布的英伟达显卡性能排行榜如下:
以ChatGLM3-6B-Base作为基座模型为例,不考虑二次预训练,只做微调的情况下,目前公布的ChatGLM系列模型的在微调的时间消耗如下图:
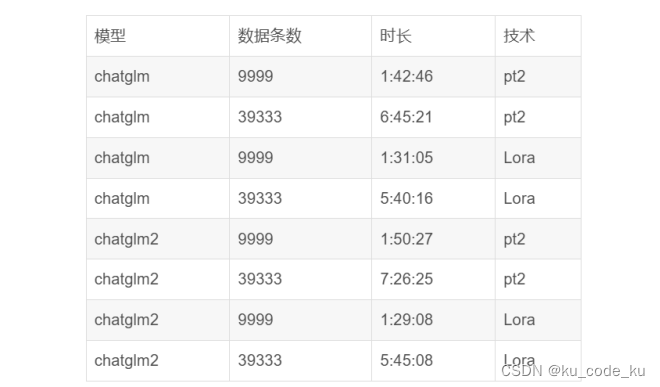
上面采用的数据均为在4卡4090显卡上分布式微调的测试结果。
在GPU价格上,截止2023年12月,公布的数据中,常见大模型微调的GPU价格如下:
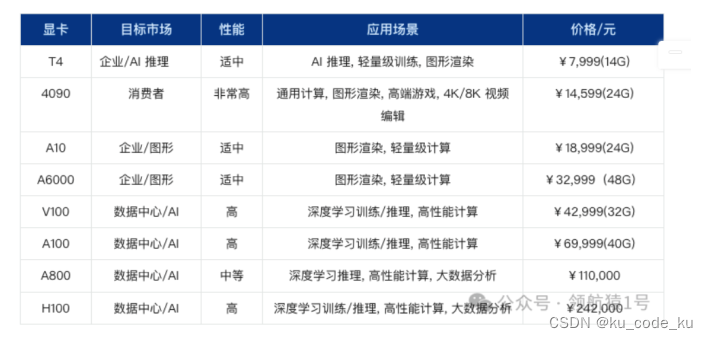
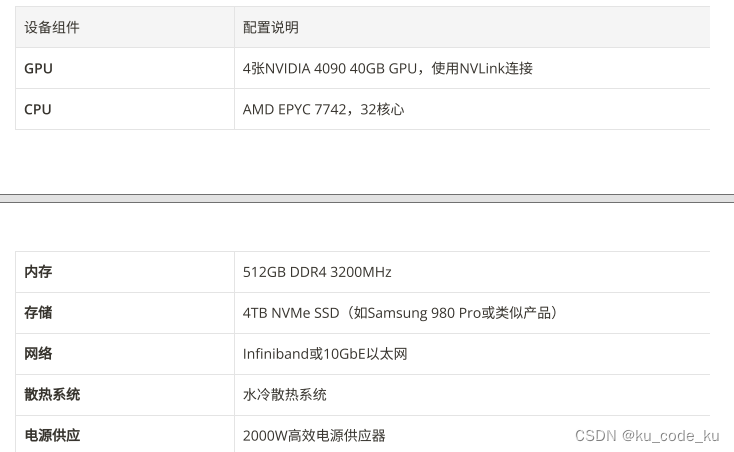
综上所述:综合考虑之下,微调情况下设备选择可以考虑:
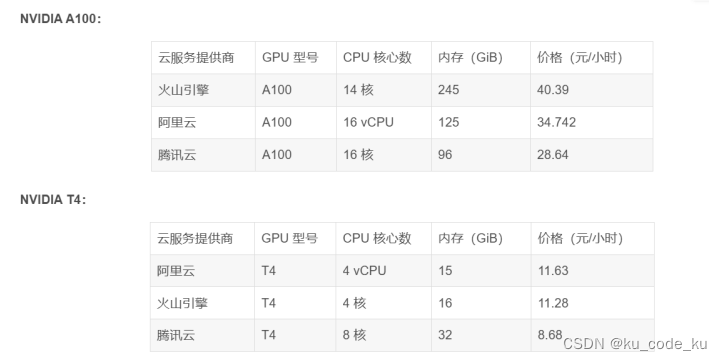
同时目前对于核心的GPU算力,目前都有一些主流的云服务厂商来提供。下面是NIVIDA A100 以及T4这两款主流的针对复杂企业级别的数据计算需求的GPU的价格对比,可做参考。
5.模型微调
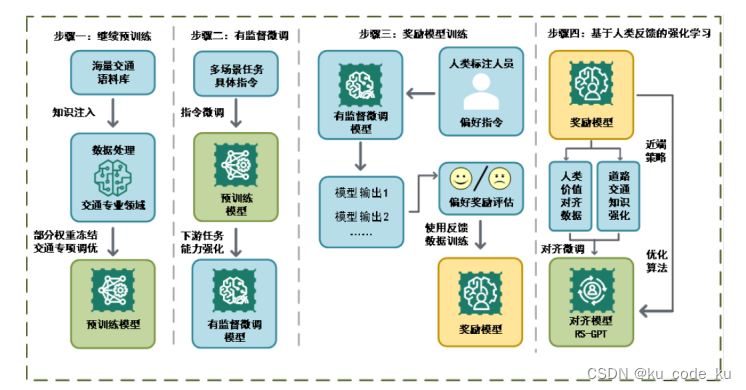
在针对垂域大模型搭建的过程中完整的流程一般为继续预训练,有监督微调,对齐微调,人类反馈强化学习(Reinforcement learning from human feedback)。比如一个完整的交通领域大模型,它的整个垂域模型的搭建的流程如下:
在调研中发现在目前的微调实践中,一般来说有监督微调+对齐微调就可以达到一个比较好的表现,可以满足一般需求。所以前期不考虑继续预训练和RLHF的的情况下,模型的微调就只涉及监督微调和对齐微调(奖励模型)。
5.1 有监督微调
在模型微调的过程中,微调涉及两种方法,一种是全参微调(Full Fine Tuning)一种是部分参数微调(Parameter-Efficient Fine Tuning)。在部分参数微调中又涉及到集中不同的部分微调方法。他们之间的关系如下图所示:

在上述的微调方法中,目前主要流行的微调的是Lora+Prompt Tuning (DoctorGLM就是采用这种方式)一种用来调整模型内部的参数矩阵来改善模型在垂域的表现,另一种通过外部的输入控制来引导模型的输出。Lora和核心思想就是通过在预训练模型(LLM)的基础上,通过注入可训练层(秩-分解矩阵)来实现模型性能的提升。具体来说,LoRA建议冻结预训练模型的权重,并在每个Transformer块中注入可训练层。Lora整体的思路可以用下图来表示:

在进行Lora微调时,官方ChatGLM3提供了两种微调方式,分别是借助LLAMA-Factory可视化的WEB UI方法和基于微调脚本的方法。具体的微调的步骤可以参考下面的网页链接。
基于LLAMA-Factory微调方案:
GitHub - hiyouga/LLaMA-Factory: Easy-to-use LLM fine-tuning framework (LLaMA, BLOOM, Mistral, Baichuan, Qwen, ChatGLM)
基于官方脚本的微调方案:
ChatGLM3/finetune_demo at main · THUDM/ChatGLM3
Prompt-Tuning通过设计和调整提示词(prompts)来引导预训练模型更好地理解和执行特定任务。这些提示词通常是附加在输入数据前的文本片段。模型在接收到包含提示词的输入后,通过预训练过程中学到的语言知识,生成对应的输出。Prompt-Tuning到目前为止一共经理过由Prefix-Tuning、P-Tuning v1、Parameter-Efficient Prompt Tuning、P-Tuning v2 5个阶段,到目前最新的Prompt-tuning 微调方法是P-Tuning v2。P-Tuning v2在模型的每一层上都加上了layer prompt,不同任务可以共享相同的网络参数,支持多任务学习。具体原理可以参考原始下图:

在Prompt-Tuning时,在上面官方的脚本中也提供了微调脚本。下面是官方微调脚本的实现:
ChatGLM-6B/ptuning at main · THUDM/ChatGLM-6B
5.2 对齐微调
在大模型微调后进行对齐(Alignment)来确保模型的输出符合预期行为、伦理规范和应用需求。这个过程核心是要收集真实多样的指令以及回复,来形成指令跟随数据集(Instruction Following Dataset)。之后通过收集到的数据集对大模型进行指令调优。使其符合更加符合人类的价值观与偏好,同时能够更好的回答垂域领域的知识问答。在进行对齐微调的时候,最可靠的方法就是根据用户提问的问题,聘请专业人才去生成可靠的回复来构建指令跟随数据集,但是这种方法成本要求巨大,除非具有特定条件负责很难复现。目前的微调实践中,一般通过SFT的微调模型就可以达到一个较好的对齐效果。但是为了实现良好的对齐,一般需要针对微调好的SFT模型在设计一个奖励模型(Reward Model)对SFT模型的回答进行打分结合PPO强化学习算法来优化模型表现。
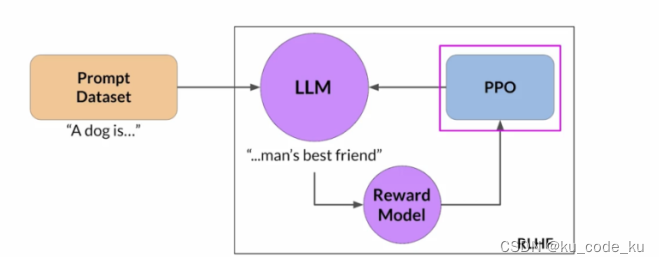
整个的对齐过程可以采用下图来表示:
- 奖励模型构建
奖励建模(Reward Modeling)阶段的目标是构建一个文本质量对比模型,它完成的主要工作就是对于同一个提示词SFT 模型会给出的多个不同输出结果,需要对这些输出结果的的质量进行排序。奖励建模是大语言模型构建中的关键环节,尤其在需要模型生成高质量文本时。这里的奖励模型本质上就是一个SFT(exculde softmax layer)+MLP的结构。整个的流程如下:
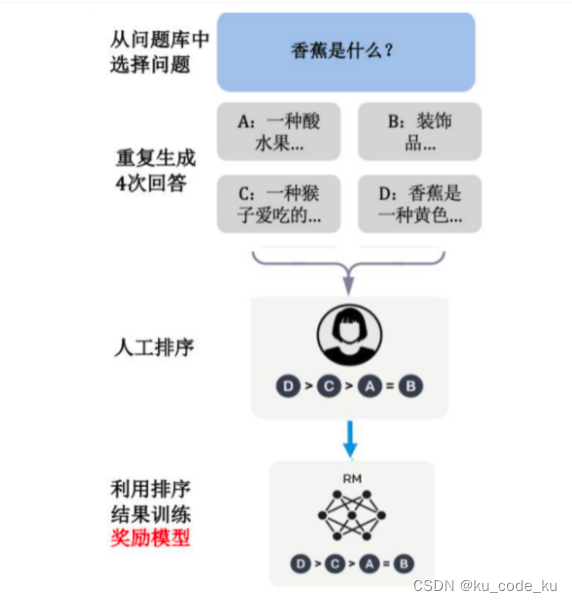
对于每个问题,给出若干答案,然后工人进行排序,而奖励模型就是利用排序的结果来进行反向传播训练。整个神经网络训练的损失函数为:奖励模型的损失函数采用 Pairwise Ranking Loss,公式如下所示:

其中:
D:人工对答案进行排序的数据集;
x:数据集D中的问题;
K:每个问题对应的答案数量;
yw和yl:问题x对应的K个答案中的两个,且yw的排序比yl高,由于是一对,也称 pairwise; rθ(x,y):需要训练的 RM 模型,对于输入的一对x和y得到的标量分数;
θ:RM 模型需要优化的参数。
- PPO(Proximal Policy Optimization)强化学习
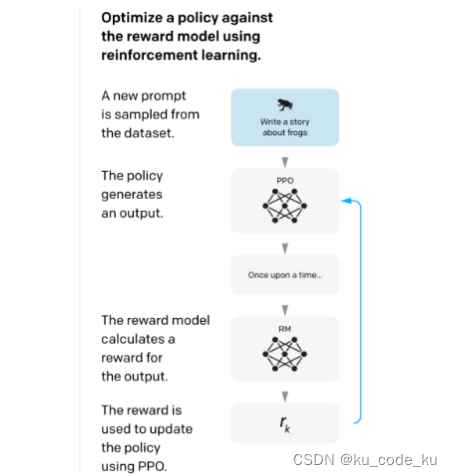
PPO是一种策略优化算法,通过对策略的限制更新,确保更新后的策略不会偏离旧策略过远,从而稳定训练过程。PPO的核心思想是通过剪辑(clipping)和信任域(trust region)的机制,来控制策略更新的幅度。在微调中以SFT为初始策略,基于RM对策略打分,使用强化学习优化策略,得到强化版本的模型PPO。训练的目标是使得PPO生成的答案能够获得高回报。训练的方法是根据RM的打分来更新PPO的参数。最后通通过多轮的训练,初始策略PPO模型将成为调整好的模型,可以完成更好的对齐,
这个过程可以采用下图来表示:
在对齐训练上可以考虑采用的下面开源框架来实现。
GitHub - hiyouga/ChatGLM-Efficient-Tuning: Fine-tuning ChatGLM-6B with PEFT | 基于 PEFT 的高效 ChatGLM 微调
6. 模型验证与评估
在模型微调完成后,需要对模型的实际表现进行评估和验证。在垂域大模型的评估主要从模型在行业知识问答和在通用能力的表现两个主要方面进行评估。目前存在许多流行的评测框架:
以下是一些总结对比:
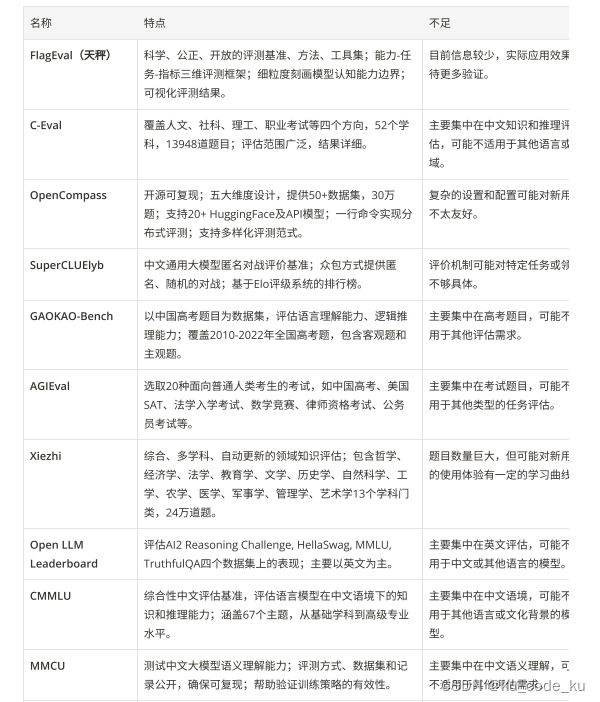
这些框架和基准测试工具各有优缺点。结合测评框架特定可以推荐采用目前流行的评测框架中Open Commpass 。它是有由上海AI实验室发布的面向大模型评测的一站式平台。它具有开源可复现;五大全面的能力维度设计,提供 50+ 个数据集约 30 万题的的模型评测方案;丰富的模型支持:已支持 20+ HuggingFace 及 API 模型;分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测;多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板;灵活化拓展等多种特定,同时目前OpenCommpress已经发布了2.0的版本。它目前有三个核心组件构成它主要由三大核心模块构建而成:Compasskit CompassHub 以及Compass Rank。其中CompassRank目前不仅囊括了开源基准测试项目,还包含了私有基准测试。针对行业内各类模型进行有针对性的测评。整体框架如下:
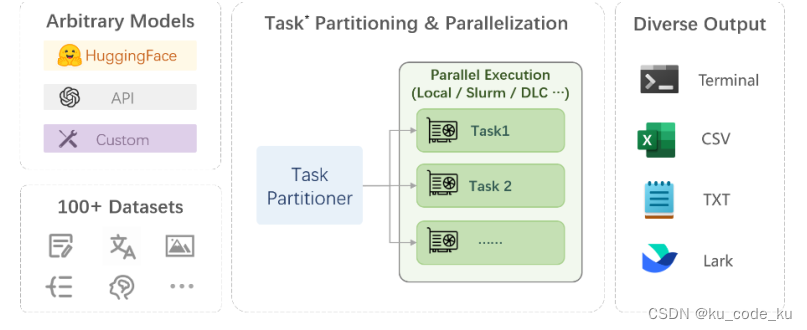
在Compress评估框架中,产生的评估指标如下图:

下面是openCommpress 评估框架仓库地址。
GitHub - open-compass/opencompass: OpenCompass is an LLM evaluation platform, supporting a wide range of models (Llama3, Mistral, InternLM2,GPT-4,LLaMa2, Qwen,GLM, Claude, etc) over 100+ datasets.
7. 模型部署
在进行模型部署时,目前常见的开源的部署框架以及对应的优缺点如下:
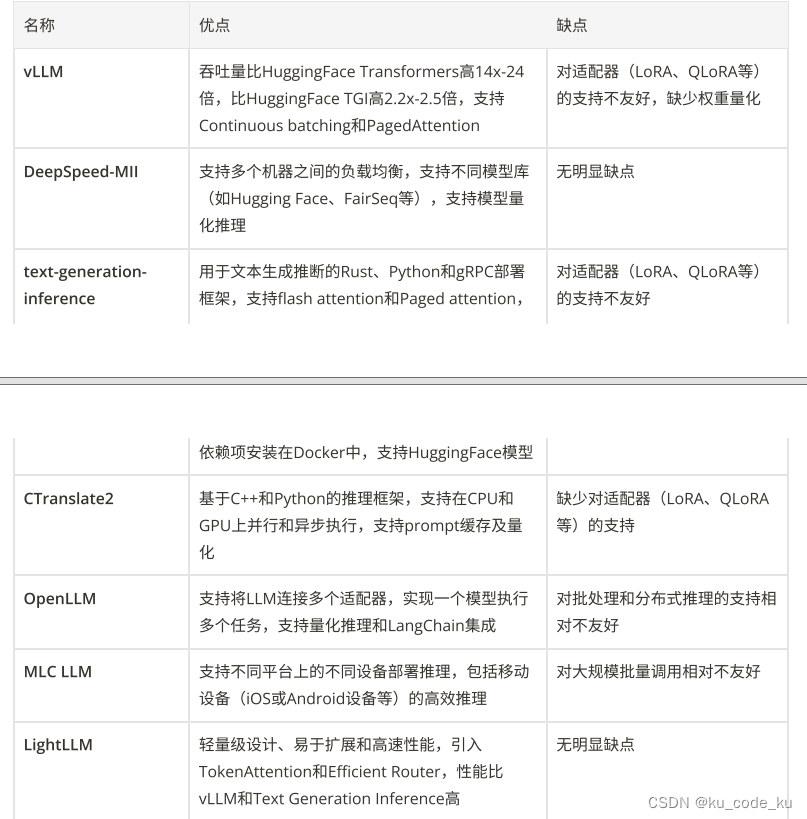
通过上述表格,综合项目的优缺点,建议可以采用目前比较流行的LightLLM框架来进行部署。该框架采用轻量级设计、易于扩展和高速性能,同时LightLLM引入了一种更细粒度的kv cache管理算法 TokenAttention,并设计了一个与TokenAttention高效配合的Efficient Router调度实现。在TokenAttention 和 Efficient Router的相互作用下,LightLLM在大部分场景下都能获得比vLLM 和 Text Generation Inference 得到更高的吞吐,部分场景下可以得到4倍左右的性能提升。
下面是框架的项目地址:
GitHub - ModelTC/lightllm: LightLLM is a Python-based LLM (Large Language Model) inference and serving framework, notable for its lightweight design, easy scalability, and high-speed performance.
8. 平台接入
在上一步模型部署成功之后会有一个URL地址提供,通过URL+参数请求就可以进行模型的调用和推理。在实际业务场景中,常需要将大模型通过接入自己的已有业务平台。一般目前来说通过Flask框架来实现。Flask 是一个使用 Python 编写的轻量级 Web 应用框架。它基于 Werkzeug WSGI 工具包和 Jinja2 模板引擎,旨在提供一个简单、灵活且易于扩展的开发平台。Flask 被设计为一个微框架,意味着它有很小的核心,主要关注基本功能,而不是包含大量内置功能和库。开发者可以根据需要扩展和定制 Flask 应用。Flask可以实现搭建应用的后端。目前在机器学习领域,Gradio 是一个用于快速搭建和共享机器学习模型和数据科学应用的 Python 库。它可以轻松地创建交互式的用户界面(UI),让用户无需编写前端代码就能与模型进行交互。Gradio 提供了一种简单的方法来部署模型并与他人共享,包括在本地运行、通过链接共享,甚至嵌入到网页中。通过Gradio+Flask基本可以实现一个WEB UI 知识问答系统。
下面是Flask框架的项目地址:
GitHub - pallets/flask: The Python micro framework for building web applications.
前端Gradio框架项目地址:
Gradio
9. 持续优化
在模型正式接入之后,用户可以通过UI界面来使用大模型。在用户使用的过程中,可以收集用户对话历史,同时在聊天界面中添加用户反馈机制,让用户可以对每次对话进行评分或提供反馈。用户反馈机制的构建可以参考CHATGPT以及Gmeemi等机制。
CHATGPT的反馈机制:

Gmeemi的多草稿机制

将收集到的数据通过构建数据库系统进行持久化的存储。数据库目前开源的postgresql 和mysql都是良好的选择。之后定期提取用户互动数据,并对数据库中的数据进行数据清洗,整理形成新的训练数据集,对模型进行增量训练。之后可以设置定时任务,将新的模型部署到生成环境之中。
参考资源
[1]
垂域LLM应用实践大模型csunny_InfoQ写作社区
[2]
垂直领域大模型微调实践经验最全总结 - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI
[3]
GitHub - l-show/RoadSafety-Gpt: 交通垂直领域微调大模型
[4]
GitHub - LlamaFamily/Llama-Chinese: Llama中文社区,Llama3在线体验和微调模型已开放,实时汇总最新Llama3学习资料,已将所有代码更新适配Llama3,构建最好的中文Llama大模型,完全开源可商用
[5]
GitHub - HqWu-HITCS/Awesome-Chinese-LLM: 整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主,包括底座模型,垂直领域微调及应用,数据集与教程等。
[6]
数据分析场景下,企业大模型选型的思路与建议
[7]
大模型微调方案设计和能力整合 - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI
[8]
ChatGLM3-6B大模型部署、微调【0到1小白教程】_chatglm3 6b最低部署要求-CSDN博客
[9]
AI大模型探索之路-训练篇23:ChatGLM3微调实战-基于P-Tuning V2技术的实践指南_p-tuning 微调实战glm3-CSDN博客
[10]
纯干货!一文带你了解大模型(LLMs)对齐,非常详细~_大模型对齐-CSDN博客
[11]
LLM (大模型)评估框架知多少? - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI
[12]
LLMs: 近端策略优化PPO Proximal policy optimization_llm ppo-CSDN博客