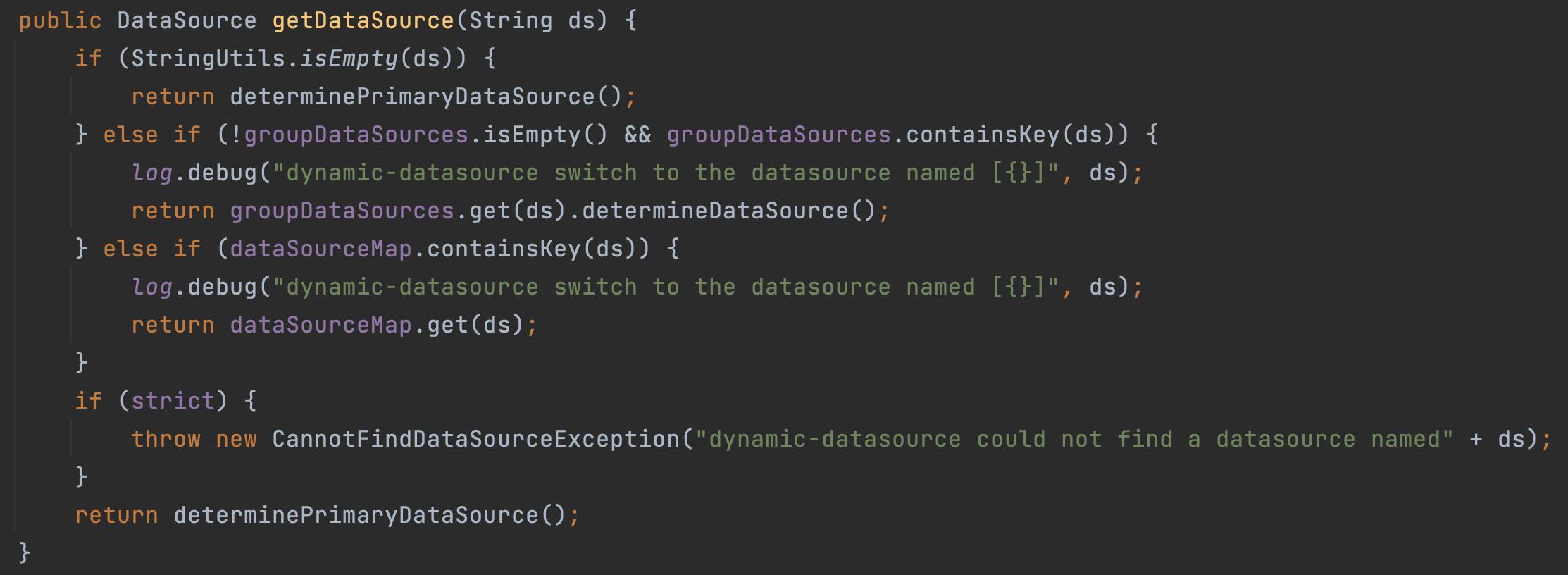
【并发编程十三】c++原子操作(1)
- 一、改动序列
- 1、改动序列
- 2、预测执行
- 二、原子操作及其类别
- 1、原子操作
- 2、非原子操作
- 3、原子类型
- 三、标准原子类型
- 1、标准原子类型的两种实现方式
- 2、原子操作的用途
- 3、原子操作的宏
- 四、操作std:atomic_flag
- 1、简介
- 2、使用说明
- 3、使用std:atomic_flag实现自旋锁
- 3、缺点
- 五、操作std:atomic\<bool>
- 1、简介
- 2、操作
- 3、“比较-交换”操作:依据原子对象当前的值决定是否保存新值。
- 3.1、比较-交换
- 3.2、compare_exchange_weak()
- 3.3、compare_exchange_strong()
- 3.4、compare_exchange_weak()和compare_exchange_strong()使用场景对比
- 五、操作std:atomic\<T*>
- 1、简介
- 2、原子操作、原子运算
- 3、demo
- 六、标准整数原子类型
- 七、泛化的std::\<>类模板
- 八、原子操作的内存次序
- 九、c++原子操作实现自旋锁
一、改动序列
1、改动序列
- 在一个c++程序中,每个对象都有一个改动序列(可以参考原子操作的内存理解std::memory_order)。它由所有线程在对象上的全部写操作构成,其中第一个写操作即为对象的初始化。大部分情况下,这个序列会随程序的多次运行而发生变化,但是在程序的任意一次运行过程中,所含的全部线程都必须形成相同的改动序列。
- 若多个线程共同操作某一对象,但它却不属于原子类型,我们就要自己负责充分实行同步操作,进而确保对于同一个变量,所有线程就其达成一致的改动序列。变量的值会随时间推移形成一个序列。
- 在不同的线程上观察属于同一个变量的序列,如果所见各异,就说明出现了数据竞争和未定义行为。
- 若我们采用了原子操作,那么编译器由责任保证必要的同步操作有效、到位。
2、预测执行
预测执行又称推测执行、投机执行,是一类底层优化技术,包括分支预测、数值预测、预读内存和预读文件等,目的是在多级流水cpu上提高指令的并发度。做法是提前执行指令而不考虑师傅必要,若完成后发现没必要,则抛弃或修正预执行的结果
- 为了实现上述改动序列的保障,要求禁止某些预测执行(speculative execution),原因是该改动序列中,只要某些线程看过过某个对象,则该线程的后续读操作必须获得相对新进的值,并且,该线程就同一对象的后续写操作,必然出现在改动序列的后方。
- 另外,如果某线程先向一个对象写数据,过后再读取它,那么必须读取前面写的值。
- 若在改动序列中,上述读写操作之间还有别的写操作,则必须读取最后写的值。
- 在程序内部,对于同一对象,全部线程都必须就其形成相同的改动序列,并且在多有对象上都要求如此,而多个对象上的改动序列知识相对关系,线程之间不必达成一致。
二、原子操作及其类别
1、原子操作
- 原子操作是不可分割的操作(indivisible operation)。在系统的任一线程内,我们都不会观察到这种操作处于半完成状态;它或者完全好,或者完全没做。
- 考虑读取某对象的过程,假如其内存加载行为属于原子操作,并且该对象的全部修改行为也都是原子操作,那么通过内存加载行为就可以得到该对象的初始值,或得到某次修改而完整存入的值。
2、非原子操作
- 与之相反,非原子操作(non-atomic operation)在完成到一半的时候,有可能为另一线程所见。
- 假定由原子操作组合出非原子操作,例如向结构体的原子数据成员赋值,那么别的线程有可能观察到其中的某些原子操作已完成,而某些还没开始,若多个线程同时赋值,而底层操作相交执行,本来意图完整存入的数据就会彼此错杂。因此,我们有可能观察到,也有可能得出一个“混合体"的结构体。
- 在任何情况下访问非原子变量却欠缺同步保护,会照成简单的条件竞争,进而引发问题。具体而言,这种级别的访问可能构成数据竞争,并导致未定义行为。
3、原子类型
在c++环境中,多数情况下,我们需要通过原子类型实现原子操作。
三、标准原子类型
标准原子类型的别名,和他们对应的std::atomic<>特化。
| 类型别名 | 定义 |
|---|---|
| std::atomic_bool | std::atomic<bool> |
| std::atomic_char | std::atomic<char> |
| std::atomic_schar | std::atomic<signed char> |
| std::atomic_uchar | std::atomic<unsigned char> |
| std::atomic_short | std::atomic<short> |
| std::atomic_ushort | std::atomic<unsigned short> |
| std::atomic_int | std::atomic<int> |
| std::atomic_uint | std::atomic<unsigned int> |
| std::atomic_long | std::atomic<long> |
| std::atomic_ulong | std::atomic<unsigned long> |
| std::atomic_llong | std::atomic<long long> |
| std::atomic_ullong | std::atomic<unsigned long long> |
| std::atomic_char8_t (C++20) | std::atomic<char8_t> |
| std::atomic_char16_t | std::atomic<char16_t> |
| std::atomic_char32_t | std::atomic<char32_t> |
| std::atomic_wchar_t | std::atomic<wchar_t> |
还有一些其他的类型别名,可以参见std::atomic
1、标准原子类型的两种实现方式
- 标准原子类型的定义位于头文件<atomic>内。这些类型的操作全是原子化的,并且,根据语言的定义,c++内建的原子操作也仅仅支持这些类型。
- 尽管通过采用互斥,我们能够令其他操作实现原子化。
- 他们全部具备成员函数is_lock_free(),准许使用者判定某一给定的类型上的操作是由原子指令(atomic instruction)直接实现(x.is_lock_free()返回true),还是要借助编译器和程序库的内部锁来实现(x.is_lock_free()返回false)。
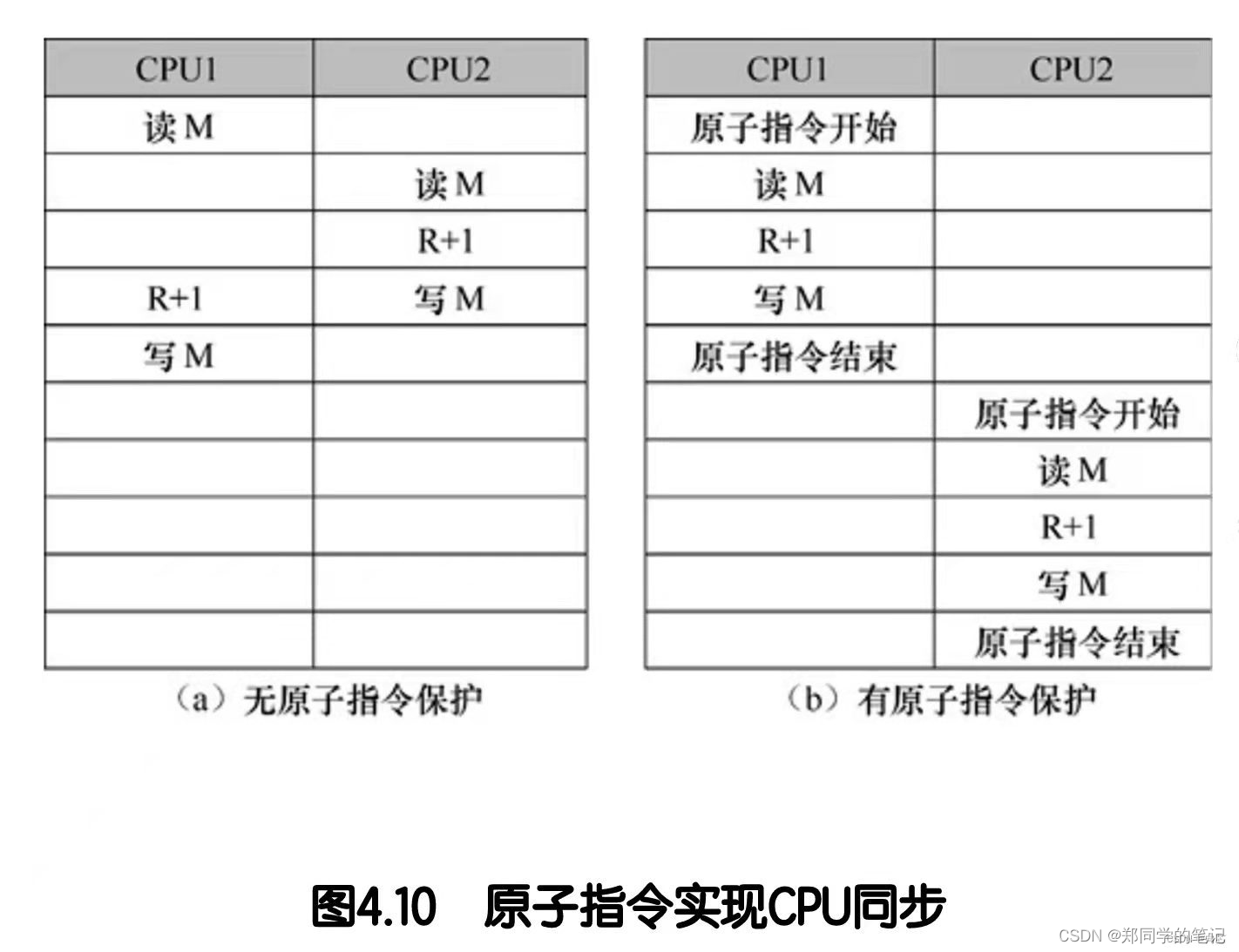
原子指令用于在多个CPU之间维护同步关系。在一些科学计算问题中,通过并行算法把子问题分配到多个cpu上执行,但是各个子问题之间存在合作关系,因此需要硬件机制来实现多个cpu之间同步。
原子指令可以实现一个CPU独占执行时间。使用原子指令把连续多条指令包含起来,计算机保证只有一个cpu处于执行状态,其他cpu必须等待原子指令结束才能继续执行。(b)展示的就是实现“原子加1”的正确方法。
原子指令的实现机制一般是在cpu的互联网络中实现一个全局的原子寄存器,所有cpu对这个原子寄存器的访问是互斥的。cpu使用原子指令申请访问原子寄存器时,互联网络会对所有CPU进行仲裁,确保只有一个cpu可以获得对原子寄存器的访问权;如果有cpu获得了原子寄存器访问权,其他cpu必须等待该cpu释放权限才能继续执行。
原子指令详细介绍参见什么是原子指令
#include <iostream>
#include <atomic>
using namespace std;
int main()
{
atomic<int> x;
bool flag = x.is_lock_free();
cout << flag << endl;
return 0;
}
输出
1
2、原子操作的用途
- 原子操作的关键用途是取代需要互斥的同步方式。但是,假如原子操作本身也在内部使用了互斥,就很可能无法达到所期望的性能提升,而更好的做法是采用基于互斥的方式,该方式更加直观且不易出错。无锁数据结构属于这种情况。
3、原子操作的宏
c++程序库专门为此提供了一组宏。他们的作用是,针对不同整数类型特化而成的各种原子类型,在编译期判定其是否属于无锁数据结构。
#if defined ATOMIC_BOOL_LOCK_FREE
#if defined ATOMIC_CHAR_LOCK_FREE
#if defined ATOMIC_CHAR16_T_LOCK_FREE
#if defined ATOMIC_CHAR32_T_LOCK_FREE
#if defined ATOMIC_WCHAR_T_LOCK_FREE
#if defined ATOMIC_SHORT_LOCK_FREE
#if defined ATOMIC_INT_LOCK_FREE
#if defined ATOMIC_LONG_LOCK_FREE
#if defined ATOMIC_LLONG_LOCK_FREE
#if defined ATOMIC_POINTER_LOCK_FREE
#include <iostream>
//#include <atomic>
using namespace std;
int main()
{
#if defined ATOMIC_BOOL_LOCK_FREE
int a = 2;
#else
int a = 3;
#endif
cout << a << endl;
return 0;
}
输出
2
四、操作std:atomic_flag
1、简介
std::atomic_flag是最简单的标准原子类型,表示一个布尔标志。
该类型的对象只有两种状态:成立或置零。二者必居其一。
经过刻意设计,它相当简单,唯一用途是充当构建单元,因此我们认为普通开发者一般不会直接使用它。尽管这样,我们从std:atomic_flag切入,仍能借以说明原子类型的一些通用原则,方便进一步讨论其他原子类型。
2、使用说明
1、atomic_flag类型的对象必须由宏 ATOMIC_FLAG_INIT 初始化,它把标志初始化为置零状态。
2、完成std::atomic_flag对象的初始化后,我们只能执行3种操作:销毁、置零、读取原有的值并设置标志成立。这分别对应于析构函数、成员函数clear()、成员函数test_and_set();
3、我们可以为clear()、test_and_set()指定内存次序。clear()是存储操作,而test_and_set()是”读-改-写“,因此能采用任何内存次序。对于上面两个原子操作,默认内存次序都是std::memory_order_seq_cst。
3、使用std:atomic_flag实现自旋锁
这个互斥非常简单,但已经能够配合lock_guard<>使用
- 最开始令原子标志置零,表示没有互斥加锁。
- 我们反复调用test_and_set()尝试锁住互斥,一旦读取的值变为false,则说明线程已经将标志设置成立(新值为true),则循环终止。
- 而简单的将标志置零既可解锁互斥。
class spinlock_mutex
{
public:
spinlock_mutex()
{
}
//spinlock_mutex(const spinlock_mutex& origin); // add this line
~spinlock_mutex() {};
void lock()
{
while (flag.test_and_set(memory_order_acquire));
}
void unlock()
{
flag.clear(memory_order_release);
}
private:
atomic_flag flag = ATOMIC_FLAG_INIT;
};
3、缺点
由于atomic_flag严格受限,甚至不支持单纯的无修改查值操作,无法用作普通的布尔标志,因此最好还是使用atomic<bool>
五、操作std:atomic<bool>
1、简介
- std:atomic是基于整数类型的最基本的原子类型。
- 相比std:atomic_flag,它是一个功能更加齐全的布尔标志。
- 尽管std:atomic也无法拷贝构造和拷贝赋值,但是我们还是能依据非原子布尔量创建其对象,初始值是true或false皆可。(该类型的实例还能接收非原子布尔量的赋值)
std::atomic<bool> b(true);
b=false;
2、操作
- store()是写操作,true和false皆可;(相当于std:atomic_flag的成员函数clear())
- load()是读取操作;
- exchange()是”读-改-写“,(替代test_and_set())
- 原子地以 desr 的值替换 obj 所指向的值,并返回 obj 先前保有的值,如同以 obj->exchange(desr) 。
- 原子地以 desr 的值替换 obj 所指向的值,并返回 obj 先前保有的值,如同以 obj->exchange(desr, order) 。
参数
obj - 指向要修改的原子对象的指针
desr - 要存储于原子对象的值
order - 此操作所用的内存同步顺序:容许所有值。
#include <iostream>
#include <atomic>
using namespace std;
int main()
{
atomic<bool> b;
bool x = b.load(std::memory_order_acquire);
b.store(true);
x = b.exchange(false, std::memory_order_acq_rel);
cout << "b=" << b << endl;
cout << "x=" << x << endl;
return 0;
}
输出
b=0
x=1
3、“比较-交换”操作:依据原子对象当前的值决定是否保存新值。
std::atomic还引入了一种操作,若原子对象当前的值符合预期,就赋予新值。它与exchage()一样,同为”读-改-写“操作。
3.1、比较-交换
- 这一操作被称为”比较-交换“(compare-exchange),实现形式是成员函数compare_exchange_weak()和compare_exchange_strong()。
比较交换操作是原子类型的编程基石。使用者给定一个期望值,原子变量将它和自身的值做比较,如果相等,就传入另一个既定的值;否则,更新期望值所属的变量,向它赋予原子变量的值。
比较交换函数返回布尔类型,如果完成了保存动作(前提是两值相等),则操作成功,函数返回ture,反之操作失败,函数返回false.
3.2、compare_exchange_weak()
- 对于compare_exchange_weak(),即使原子变量的值等于期望值,保存动作还是有可能失败,在这种情形下,原子变量维持不变,compare_exchange_weak()返回false;
原子化的比较-交换必须由一条指令单独完成,而某些处理器没有这种指令,无法保证该操作按原子化方式完成。
要实现比较-交换,负责的线程则必须改为连续运行一些列指令,但在这些计算机上,只要出现线程数量多于处理器数量的情形,线程就有可能执行到中途因系统调度而切出,导致操作失败。
这种计算机最有可能引发上述的保存失败,我们称之为佯败(spurious failure)。其因败因不算变量值本身存在问题,而是函数执行时机不对。
因为compare_exchange_weak()可能佯败,所以它必须配合循环使用。
#include <iostream>
#include <atomic>
using namespace std;
int main()
{
bool expected = false;
extern atomic<bool> b; //由其他源文件的代码设定变量的值
while(!b.compare_exchange_weak(expected, true) && !expected);
{
cout << "b=" << b << endl;
}
return 0;
}
atomic<bool> b;
输出
b=1
3.3、compare_exchange_strong()
- 只有当原子变量的值不符合预期时,compare_exchange_strong()才返回false.
这让我们得以明确知悉变量是否成功修改,或者是否存在另一线程抢先切入而导致佯败,从而能够摆脱上例所示的循环。
3.4、compare_exchange_weak()和compare_exchange_strong()使用场景对比
- 在某些平台上,虽然使用compare_exchange_weak()可能导致佯败,但改用compare_exchange_strong()却会形成双重循环(因为compare_exchange_strong()自身内部含有一个循环),那么采用compare_exchange_weak()比较有利于性能。
- 反之,如果存入的值需要耗时的计算,选择compare_exchange_strong()则更加合理。因为只要预期值没有变化,就可避免重复计算。
另外比较-交换函数中,关于内存次序这个参数我们就不再说了,感兴趣的可以看书籍。
五、操作std:atomic<T*>
1、简介
- 指向类型T的指针,其原子化形式为 std::atomic<T*> 类似于原子化的布尔类型std::atomic。
- 两者的接口相同,但操作目标从布尔类型变成相应的指针类型。
- 它与std::atomic相似,同样不能拷贝复制或拷贝赋值。
2、原子操作、原子运算
- 原子操作
根据类模板的定义,std:atomic<T*>也具备成员函数:is_lock_free()、load()、store()、exchange()、compare_exchange_weak()和compare_exchange_strong(),它们与std::atomic<bool>中的对应函数有着相同的语义,但接收的参数和返回值不再是布尔类型,而是T*类型。 - 原子运算
std:atomic<T*>提供的新操作是算术形式的指针运算。成员函数
fetch_add():就对象中存储的地址进行原子化加;
fetch_sub():就对象中存储的地址进行原子化减;
3、demo
#include <iostream>
#include <atomic>
#include<cassert>
using namespace std;
class foo {};
int main()
{
foo foo_array[5];
// 可以和boo类型类比,定义一个foo*指针,初始值是数组的第一个对象。
atomic<foo*> p(foo_array);
foo* x = p.fetch_add(2); // 令p+2,返回旧址。
assert(x==foo_array);
assert(p.load() == &foo_array[2]);
x = (p -= 1); //令p-1,返回新值
assert(x == &foo_array[1]);
assert(p.load() == &foo_array[1]);
return 0;
}
六、标准整数原子类型
在std::atomic<int>或std::atomic<unsigned long long>这样的整数类型上,我们可以指向的操作颇为齐全。包括:
- 常用原子操作:is_lock_free()、load()、store()、exchange()、compare_exchange_weak()、compare_exchange_strong();
- 原子运算:fetch_add()、fetch_sub()、fetch_and()、fetch_or()、fetch_xor();
- 这些运算的符合赋值形式:+=、-=、&=、|=、^=;
- 前后缀形式的自增、自减:++x、x++、–x、x–;
七、泛化的std::<>类模板
-
主模板的存在,在除了标准原子类型之外,允许用户使用自定义类型创建一个原子变量。不 是任何自定义类型都可以使用std::atomic<> 的:需要满足一定的标准才行。为了使用 std::atomic (UDT是用户定义类型),这个类型必须有拷贝赋值运算符。这就意味着这个类型不能有任何虚函数或虚基类,以及必须使用编译器创建的拷贝赋值操作。不仅仅是这 些,自定义类型中所有的基类和非静态数据成员也都需要支持拷贝赋值操作。这(基本上)就允 许编译器使用memcpy(),或赋值操作的等价操作,因为它们的实现中没有用户代码。
-
最后,这个类型必须是“位可比的”(bitwise equality comparable)。这与对赋值的要求差不多; 你不仅需要确定,一个UDT类型对象可以使用memcpy()进行拷贝,还要确定其对象可以使用 memcmp()对位进行比较。之所以要求这么多,是为了保证“比较/交换”操作能正常的工作。
八、原子操作的内存次序
内存次序共6种,分3种模式:
- 先后一致次序 :memory_order_seq_cst;
- 宽松次序 :memory_order_relaxed;
- 获取释放次序 :memory_order_consume、memory_order_acquire、memory_order_release、memory_order_acq_rel;
库中所有原子操作的默认行为提供先后一致次序(也叫序列一致顺序)。
至于每个的区别我们在这里就不讨论了,感兴趣的可以通过文后的参考链接和书籍,自行研究。
九、c++原子操作实现自旋锁
参见【并发编程十四】c++原子操作实现自旋锁
参考:
1、https://www.apiref.com/cpp-zh/cpp/thread.html
2、《c++并发编程实战(第二版)》安东尼.威廉姆斯 著;吴天明 译;



![[前端笔记——CSS] 14.图像、媒体和表单元素](https://img-blog.csdnimg.cn/aab46af1361f445fa2fc0c3314945663.png)