中文标题
- 摘要
- 引言
- 动机举例
- 相关工作
- 时间旅行可视化的属性
- 符号定义
- 邻居保护属性
- 边界距离保持属性
- 逆投影保持属性
- 暂时保存属性
- 方法
- δ \delta δ-边界估计
- (k)-BAVR综合体建设
- 逆投影保持
- 时间连续性
- 评估
- 案例分析
- 结论
- 参考文献

摘要
了解深度学习模型的预测在训练过程中是如何形成的,对于提高模型性能和修复模型缺陷至关重要,特别是当我们需要研究主动学习等非平凡的训练策略,并跟踪意外训练结果的根本原因时,例如性能退化。
在这项工作中,我们提出了一种时间旅行视觉解决方案 DeepVisualInsight (DVI),旨在在训练深度学习图像分类器时体现时空因果关系。时空因果关系展示了梯度下降算法和各种训练数据采样技术如何影响和重塑连续时期中学习输入表示的布局和分类边界。这样的因果关系使我们能够在可见的低维空间中观察和分析整个学习过程。从技术上讲,我们提出了四个空间和时间属性,并设计了我们的可视化解决方案来满足它们。在可见的低维空间和不可见的高维空间之间投影和反投影输入样本以进行因果分析时,这些属性保留了最重要的信息。我们广泛的实验表明,与基线方法相比,我们在空间/时间属性和可视化效率方面实现了最佳可视化性能。此外,我们的案例研究表明,我们的视觉解决方案可以很好地反映各种训练场景的特征,显示出DVI作为分析深度学习训练过程的调试工具的良好潜力。
引言
在训练和分析深度学习模型时,解释模型预测是一项经过充分重新考虑的挑战(Zhang et al. 2021)。人们提出了各种可解释的人工智能技术来理解模型预测,包括输入归因分析、训练数据分析、模型抽象等。一般来说,现有的解决方案侧重于:
- 个体预测分析:识别个体输入的最重要特征来解释模型预测(Sundararajan、Taly 和 Yan 2017;Chattopadhyay 等人 2019;Kapishnikov 等人 2019;Simonyan、Vedaldi 和 Zisserman 2013;Selvaraju 等人2017 年;
- 训练数据切片:识别对模型影响最大的训练样本(Sagadeeva 和 Boehm 2021;Bhatt 等人 2021;Koh 和 Liang 2017);
- 模型抽象:抽象简化且可解释的模型(例如,SVM 和决策树)来解释深度学习模型(Ribeiro、Singh 和 Guestrin 2016;Frosst 和 Hinton 2017;Zhang 等人 2019)。
尽管这些技术对于解释训练模型很有用,但很少有人提出来解释模型预测在训练过程中是如何形成的。虽然一些专注于渐进式训练信息(例如损失和准确性)的工作可能有用,但它们未能抽象底层模型演变的语义。语义问题可以是(但不限于):(1)(重新)训练过程如何逐步提高模型的鲁棒性,并重塑分类边界? (2)模型如何逐渐做出权衡以适应某些样本,同时牺牲其他样本? (3)模型如何努力拟合和学习困难样本?
在这项工作中,我们设计了一种时间旅行可视化解决方案 DeepVisualInsight (DVI),专注于体现深度学习分类器训练进度的时空因果关系。 DVI 将学习到的输入表示及其分类景观投影到可见的低维空间中,从空间和时间的角度显示模型预测在训练过程中是如何形成的。在空间上,DVI 可视化 (1) 学习的输入表示的布局和 (2) 描述每个类别“领土”的分类景观。在时间上,DVI 可视化(1)分类景观和训练输入表示如何在训练中演变,以及(2)新采样的训练输入如何重塑分类边界。时空信息使我们能够观察训练异常(例如噪声数据集)并验证一些特定的训练策略(例如主动学习采样策略的有效性)。
与设计测量来分析特定样本或模型属性(例如 Shapley 值(Ancona、Oztireli 和 Gross 2019)和硬样本检测(Wu 等人 2017))相比,我们设计 DVI 来支持开放式探索。也就是说,DVI忠实地反映了深度模型是如何通过训练过程学习的,不仅可以确认已知的模型属性,还支持发现未知现象和模型缺陷。
我们的方法将输入作为在不同训练阶段及其训练/测试数据集下训练的分类器,然后学习可视化模型(即通过自动编码器)以(1)将高维样本投影到可见的低维空间中,(2)逆-将低维点投影回高维空间(用于可视化分类景观),以及(3)确保可视化模型可以满足一组空间和时间约束。我们为任何时间旅行可视化解决方案提出了四个可视化属性,以保留(1)高维流形和低维流形之间的拓扑结构,(2)训练样本表示和潜在决策边界之间的距离,(3)投影和预测后样本的语义到低/高维空间的逆投影,以及(4)所有经过训练的分类器按时间顺序的可视化景观的连续性。总之,我们做出以下贡献:
- 我们提出了一种时间旅行可视化解决方案 DeepVisualInsight(或 DVI),旨在可视化具有时空因果关系的分类景观的演变,以促进验证模型属性并发现新的模型行为。
- 我们为任何时间旅行可视化技术提出了四个空间和时间属性,并设计了一个深度学习解决方案来满足它们,以反映分类景观。
- 我们构建可视化框架DVI 以支持各种深度分类器的可视化。
- 我们进行了大量的实验和案例研究,展示了 (1) DVI 满足属性的有效性以及 (2) DVI 如何帮助理解训练过程和诊断模型行为。
有关我们工具/实验的更多详细信息,请访问 (DVI 2021)。
动机举例
图 1 显示了我们在 CIFAR-10 数据集上的对抗训练过程的可视化。每个点代表一个样本,每种颜色代表一个类。点的颜色代表其标签,区域的颜色代表预测的类别。例如,位于棕色(狗类)区域内的红色(猫类)点表示它被标记为猫,但被分类为狗。此外,颜色深浅表示预测的置信度,不置信的区域(即分类边界)被可视化为白色区域。总体而言,分类区域和边界形成了分类景观。在这里,模型拟合过程通过以下过程可视化:(1) 分类边界被重塑;(2) 这些数据点被拉向其相应颜色的区域。
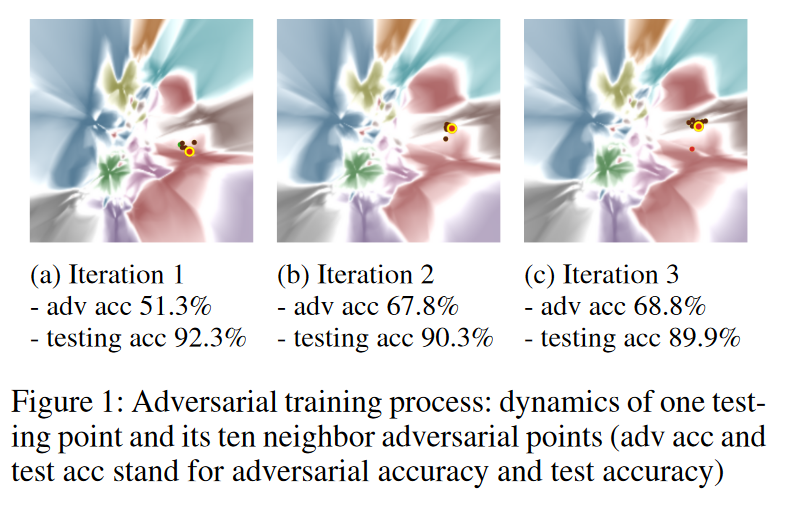
图 1 显示,DVI 体现了(1)模型适应新的对抗样本和训练样本时的边界重塑过程,以及(2)对抗鲁棒性和测试准确性之间进行权衡的过程。为了清楚起见,我们在图 1 中显示了一个测试点(带有黄色边缘的大红点)及其十个最近邻的对抗点(棕色)。在对抗训练期间,(1)对抗点逐渐被拉到其颜色对齐的区域,而(2)测试点也逐渐从其颜色一致的领土“拉”到其敌对邻居的领土上。这种权衡是逐渐形成的。在(DVI 2021)中,我们通过可视化整体数据点的动态进一步证明了这种权衡的存在。 DVI 工具可以进一步将过程可视化为动画。此外,它还支持用户对样本和迭代进行查询,观察感兴趣样本和感兴趣迭代的动态,深入洞察模型训练过程。
相关工作
通过归因技术的可解释人工智能 (XAI) 研究人员提出了将预测跟踪回输入的方法,即归因方法(Selvaraju 等人,2017 年;Sundararajan、Taly 和 Yan,2017 年;Chattopadhyay 等人,2019 年;Simonyan、Vedaldi 和 Zisserman) 2013;卡皮什尼科夫等人,2019)。归因解决方案评估任何输入组件(例如图像中的某些像素)对预测结果的贡献。 (Sundararajan、Taly 和 Yan 2017)提出了每种归因方法都应满足的两个公理,并开发了集成梯度(IG)。 (Chattopadhyay 等人,2019)提出平均因果效应(ACE)来减轻 IG 引入的偏差。为了可视化归因解释,(Selvaraju et al. 2017)提出了 Grad-Cam 解决方案来突出显示输入图像上的像素以解释预测。
DVI 将分类景观的形成过程可视化。 DVI 和归因分析是互补的。 DVI 显示分类情况和输入样本分布的概述,然后使用任何归因技术来检查各个样本。
模型可视化 通常,模型可视化转化为降维问题。现有技术包括线性方法(例如 PCA(Wold、Esbensen 和 Geladi 1987)等)和非线性方法(例如 t-SNE(Van der Maaten 和 Hinton 2008)、UMAP(McInnes、Healy 和 Melville 2018)。非线性解决方案在将数据投影到低维空间后保留邻居关系(Van der Maaten 和 Hinton 2008)提出 t-SNE,它将高维样本的距离转换为高斯分布的条件概率和低维分布的条件概率。将维度样本转换为条件概率,并使用学生 t 分布作为相似性度量(Tang 等人,2016 年)和(McInnes、Healy 和 Melville,2018 年)提出 LargeViz 和 UMAP 来进一步提高性能(Rauber 等人,2016 年)。使用 t-SNE 的样本轨迹。
一项相关工作是 DeepView(Schulz、Hinder 和 Hammer 2019),旨在可视化分类器的决策边界。 DeepView通过UMAP将高维样本投影到低维空间,并根据预测结果和输入空间中的欧几里德距离定制流形距离。 DeepView 逆投影关于其邻居的高维对应点的低维点。 DVI 与 DeepView 有两点不同。首先,DVI 比 DeepView 更加高效且可扩展(参见第 1 节)。其次,DVI 考虑了边界保持属性和时间属性,这在时间旅行可视化中至关重要。
时间旅行可视化的属性
符号定义
我们将 C 类分类器表示为 c(·)。输入空间表示为 S ⊂ R d \mathcal{S}\subset\mathbb{R}^d S⊂Rd。 S = [ s 1 , s 2 , . . . s N ] T \mathbf{S} = [\mathbf{s}_1,\mathbf{s}_2,...\mathbf{s}_N]^T S=[s1,s2,...sN]T 是训练输入集。 f : R d → R h f:\mathbb{R}^d\to\mathbb{R}^h f:Rd→Rh 是一个特征函数,使得 x = f ( s ) x = f (s) x=f(s) 是输入 s ∈ S s ∈ S s∈S 的 h 维表示向量。我们将表示向量的流形空间表示为 X \mathcal{X} X,其中 X ⊂ R h \mathcal{X}\subset\mathbb{R}^h X⊂Rh。训练数据的学习表示表示为 X \mathbf{X} X,其中 X = [ x 1 , x 2 , . . . x N ] T \mathbf{X}=[\mathbf{x}_1,\mathbf{x}_2,...\mathbf{x}_N]^T X=[x1,x2,...xN]T 。令 g : R h → R C g : \mathbb{R}^{h}\to\mathbb{R}^{C} g:Rh→RC为预测函数,其中 g ( x ) i g(\mathbf{x})_i g(x)i 表示第 i 类的 logits。分类器 c c c 由 f f f 和 g g g 组成,即 c = g ∘ f : R d → R C c=g\circ f:\mathbb{R}^d\to\mathbb{R}^C c=g∘f:Rd→RC 。采用 c 及其训练输入,我们得出可视化模型 V = ⟨ ϕ , ψ ⟩ V=\langle\phi,\psi\rangle V=⟨ϕ,ψ⟩:
- 投影函数 ϕ : R h → R l \phi:\mathbb{R}^h\to\mathbb{R}^l ϕ:Rh→Rl,将流形空间 X \mathcal{X} X 投影到可见的低维空间 Y \mathcal{Y} Y,其中 Y = R l \mathcal{Y}=\mathbb{R}^l Y=Rl(l 为 2 或 3)。将 X \mathcal{X} X 投影到 Y \mathcal{Y} Y(即 Y = ϕ ( X ) \mathbf{Y}=\phi(\mathbf{X}) Y=ϕ(X))会产生对应的 Y = [ y 1 , y 2 , . . . y N ] T \mathbf{Y}=[\mathbf{y}_1,\mathbf{y}_2,...\mathbf{y}_N]^T Y=[y1,y2,...yN]T。
- 反投影函数 ψ : R l → R h \psi:\mathbb{R}^l\to\mathbb{R}^h ψ:Rl→Rh,将可见低维空间 Y \mathcal{Y} Y 反投影回表示空间 X \mathcal{X} X。
邻居保护属性
定义 1 (k-witness). 给定训练数据集 S \mathbf{S} S 和 X \mathbf{X} X 上定义的距离度量, d : R h × R h → R ≥ 0 d : \mathbb{R} ^h \times \mathbb{R}^h\quad\to\quad\mathbb{R}_{\geq0} d:Rh×Rh→R≥0。对于给定的 x i ∈ X \begin{array}{ccc}\mathrm{x}_i&\in&\mathbf{X}\end{array} xi∈X,我们将其 k 个最近邻的索引集表示为 N k ( x i ) = a r g m i n J ⊂ { 1.. N } ∖ { i } , ∣ J ∣ = k ∑ j ∈ J d ( x j , x i ) N_k(\mathbf{x}_i)=\mathop{\mathrm{argmin}}_{\mathcal{J}\subset\{1..N\}\setminus\{i\},|\mathcal{J}|=k}\sum_{j\in\mathcal{J}}d(\mathbf{x}_j,\mathbf{x}_i) Nk(xi)=argminJ⊂{1..N}∖{i},∣J∣=k∑j∈Jd(xj,xi)。如果 j ∈ N k ( x i ) j ∈ N_k(\mathbf{x}_i) j∈Nk(xi),我们说 x j x_j xj由 X \mathbf{X} X 中的 x i x_i xi k-witnessed。
给定一个数据样本 s s s,其表示为 x ∈ X x ∈ X x∈X,低维对应项为 y ∈ Y y ∈ Y y∈Y,任何由 x \mathbf{x} x k-witnessed 的 x ′ \mathbf{x}′ x′都应具有由 y \mathbf{y} y k-witnessed 的其对应项 y ′ \mathbf{y}′ y′,反之亦然。
假设
X
\mathbf{X}
X的流形
X
\mathcal{X}
X已知,我们将流形中
x
i
\mathbf{x}_i
xi 和
x
j
\mathbf{x}_j
xj 之间的距离表示为
d
M
(
x
i
,
x
j
)
d_\mathcal{M}(\mathbf{x}_i,\mathbf{x}_j)
dM(xi,xj)。类似地,我们将欧几里得空间中对应的
y
i
\mathbf{y}_i
yi 和
y
j
\mathbf{y}_j
yj 的距离表示为
d
E
(
y
i
,
y
j
)
d_\mathcal{E}(\mathbf{y}_i,\mathbf{y}_j)
dE(yi,yj)。给定见证值 k,我们定义
N
k
(
x
i
)
:
=
argmin
J
⊂
{
1..
N
}
∖
{
i
}
,
∣
J
∣
=
k
∑
j
∈
J
d
M
(
x
j
,
x
i
)
N_k(\mathbf{x}_i) :=\begin{aligned}\operatorname{argmin}_{\mathcal{J}\subset\{1..N\}\setminus\{i\},|\mathcal{J}|=k}\sum_{j\in\mathcal{J}}d_{\mathcal{M}}(\mathbf{x}_j,\mathbf{x}_i)\end{aligned}
Nk(xi):=argminJ⊂{1..N}∖{i},∣J∣=kj∈J∑dM(xj,xi)和
N
k
(
y
i
)
:
=
a
r
g
m
i
n
J
⊂
{
1..
N
}
∖
{
i
}
,
∣
J
∣
=
k
∑
j
∈
J
d
E
(
y
j
,
y
i
)
N_k(\mathbf{y}_i):=\mathrm{argmin}_{\mathcal{J}\subset\{1..N\}\setminus\{i\},|\mathcal{J}|=k}\sum_{j\in\mathcal{J}}d_{\mathcal{E}}(\mathbf{y}_{j},\mathbf{y}_{i})
Nk(yi):=argminJ⊂{1..N}∖{i},∣J∣=k∑j∈JdE(yj,yi),表示分别由
x
i
\mathbf{x}_i
xi及其对应的
y
i
\mathbf{y}_i
yi k-witnessed的邻居的两个索引集。邻域保持特性要求最大化k空间邻域保持率
n
n
p
v
(
k
)
:
=
1
N
∑
i
=
1
N
∣
N
k
(
x
i
)
∩
N
k
(
y
i
)
∣
k
(1)
nn_{pv}(k):=\frac{1}{N}\sum_{i=1}^{N}\frac{|N_k(\mathbf{x}_i)\cap N_k(\mathbf{y}_i)|}{k}\text{(1)}
nnpv(k):=N1i=1∑Nk∣Nk(xi)∩Nk(yi)∣(1)
边界距离保持属性
定义 2( δ \delta δ–边界)。对于小 δ ∈ [ 0 ; 1 ) \delta ∈ [0; 1) δ∈[0;1)、预测函数 g : R h → R C g : \mathbb{R}^{h}\to\mathbb{R}^{C} g:Rh→RC 和最小-最大缩放函数 r : R C → [ 0 , 1 ] C r : \mathbb{R}^C\to[0,1]^C r:RC→[0,1]C ,设 r ( g ( x ) ) t o p 1 r(g(\mathbf{x}))_{top1} r(g(x))top1和 r ( g ( x ) ) t o p 2 r(g(\mathbf{x}))_{top2} r(g(x))top2分别为 r ( g ( x ) ) r(g(\mathbf{x})) r(g(x))的最大和第二大值。我们说点 x x x 位于 δ \delta δ-Boundary 上,如果 ∣ r ( g ( x ) ) t o p 1 − r ( g ( x ) ) t o p 2 ∣ ≤ δ |r(g(\mathbf{x}))_{top1}-r(g(\mathbf{x}))_{top2}|\leq\delta ∣r(g(x))top1−r(g(x))top2∣≤δ。
我们将分类边界定义为一组点 B = {b|b 在 - 边界上}。与邻居保留性质类似,边界距离保留性质要求任何 xi ∈ X 在通过
ϕ
(
.
)
\phi(.)
ϕ(.)投影到 yi 后应保留其 k 个最近的边界邻居。如果我们将 b 表示为 Rh 中的边界点,则将其在 Rl 中的对应点表示为 b’。扩展定义1,我们定义 N (b) k (xi) := argminJ ⊂{1::|B|};|J |=k Σ j∈J dM(bj ; xi), N (b0) k (yi ) := argminJ ⊂{1::|B|};|J |=k Σ j∈J dE (b′ j; yi) 表示由 xi 及其对应的 yi 所见证的 k 边界的两个索引集。我们要求投影函数 (·) 最大化:
b
o
u
n
d
a
r
y
p
v
(
k
)
:
=
1
N
∑
i
=
1
N
∣
N
k
(
b
)
(
x
i
)
∩
N
k
(
b
′
)
(
y
i
)
∣
k
(
2
)
boundary_{pv}(k):=\frac1N\sum_{i=1}^N\frac{|N_k^{(b)}(\mathbf{x}_i)\cap N_k^{(b^{\prime})}(\mathbf{y}_i)|}k\quad(2)
boundarypv(k):=N1i=1∑Nk∣Nk(b)(xi)∩Nk(b′)(yi)∣(2)
逆投影保持属性
为了可视化分类景观,可视化解决方案需要逆投影函数 (·) 从 Y 中的低维向量重建高维表示向量。这种重建需要满足 (1) 从表示投影的任何低维向量 yi向量 xi 应该被重构为尽可能接近 xi 的 x′ i ; (2)它可以推广到任意低维向量。第一个要求确保投影不会导致信息丢失。此外,当将每个类表示为不同的颜色时,第二个要求允许我们为低维画布中的任意点着色。给定 H = {hi|hi ∈ X },要求 (·) 能够最小化重构误差:
r
e
c
p
v
:
=
1
∣
H
∣
∑
i
=
1
∣
H
∣
∥
h
i
−
ψ
(
ϕ
(
h
i
)
)
∥
2
(3)
rec_{pv}:=\frac{1}{|\mathbf{H}|}\sum_{i=1}^{|\mathbf{H}|}\left\|\mathbf{h}_i-\psi(\phi(\mathbf{h}_i))\right\|^2\quad\text{(3)}
recpv:=∣H∣1i=1∑∣H∣∥hi−ψ(ϕ(hi))∥2(3)
暂时保存属性
与现有的 UMAP 和 t-SNE 等静态可视化不同,我们的可视化分类景观需要保持主题分类器的分类景观变化的时间连续性。假设两个分类器 ct 和 ct+1 是在两个连续 epoch 中训练的分类器,它们的分类景观应该是相似的。因此,他们的可视化解决方案 V t 和 V t+1 应提供类似的可视化结果。
我们考虑 (1) 分类器 ct = gt ◦ f t 和 ct+1 = gt+1 ◦ f t+1 按时间顺序排列,以及 (2) 一个测量函数 evalsem(·) 来评估表示 xt = f t 的语义相似性任何输入 s ∈ S 的 (s) 和 xt+1 = f t+1(s) 。在这里,我们将输入的语义评估为其流形空间中 k 个最近邻的索引集。我们将语义相似度表示为 evalsem(xt; xt+1; k)。如果两个纪元具有相似的语义,则可视化解 V t 和 V t+1 应该将 xt 和 xt+1 投影到 Rl 中相似的位置,或者与 dE 负相关 ( t(xt); t+1(xt+1 ))。我们将相关性定义为:
t
e
m
p
o
r
a
l
p
v
(
k
)
:
=
c
o
r
r
(
e
v
a
l
s
e
m
(
x
t
,
x
t
+
1
,
k
)
,
d
E
(
ϕ
t
(
x
t
)
,
ϕ
t
+
1
(
x
t
+
1
)
)
)
(
4
)
\begin{aligned}&temporal_{pv}(k):=\\&corr(eval_{sem}(\mathbf{x}^{t},\mathbf{x}^{t+1},k),d_{\mathcal{E}}(\phi_{t}(\mathbf{x}^{t}),\phi^{t+1}(\mathbf{x}^{t+1})))\end{aligned} \qquad (4)
temporalpv(k):=corr(evalsem(xt,xt+1,k),dE(ϕt(xt),ϕt+1(xt+1)))(4)
然后我们需要投影函数 t(·) 和 t+1(·) 来最小化时间 pv(k):
据我们所知,现有的方法都没有解决所有四个属性。 t-SNE和UMAP仅满足邻居保持性质; DeepView满足邻居保持和逆保持性质。我们针对所有四个属性提出第一个解决方案。
方法
如图 2 所示,DVI 将按时间顺序训练的一系列分类器作为输入,C = {c1; c2; :::; cT } 作为主题模型,并生成相应的可视化模型序列(即自动编码器)V = {V 1; V 2; :::; V T } 导出可视化分类景观。我们使用上标来表示所有符号的时间顺序。对于每个可视化模型 V t = 〈 t; t>,编码器作为投影函数t,解码器作为逆投影函数t。
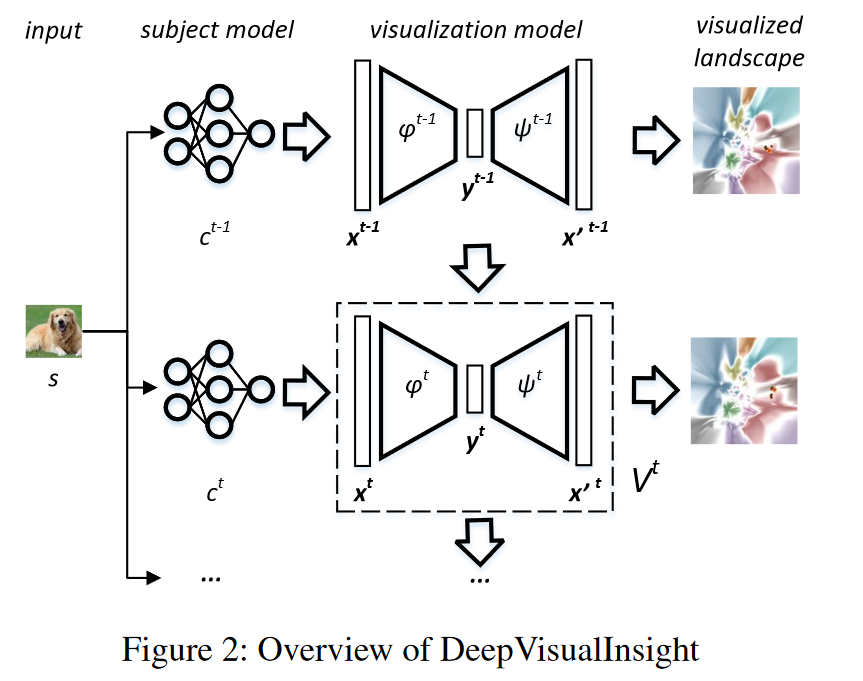
为每个类分配一种非白色,V t 可以(1)通过 t(f t(s)) 计算每个输入 s ∈ S 的坐标,(2)通过 gt( t(y) 为任意点 y 着色)。如果 y 位于边界上(参见定义 2),则其颜色为白色;否则,它以类 gt( t(y))top1 的代表颜色着色。
每个 ct 的可视化模型 V t 都根据四个空间和时间属性进行训练。我们(1)估计 ct 的代表性边界点; (2) 构建边界/训练表示向量的拓扑复合体,并在投影后保留其结构以满足(边界)邻居保留性质; (3) 最小化 x 与重构 t( t(x)) 之间的距离以满足逆投影保持性质; (4) 在 (1) t+1 和 t 以及 (2) t+1 和 t (t ≥ 1) 之间建立连续性以满足时间保持性质。
δ \delta δ-边界估计
我们通过综合边界样本来估计 -boundary,考虑到效率、真实性和多样性。
效率和真实性 我们提出了一种新颖的基于 mixup 的点合成方法。给定一个分类器 c(·) 和两个输入图像 si; sj ∈ S 来自两个不同的预测类别,我们的基本原理在于,
-
他们的混合输入(即图像)仍然可以在很大程度上保留其固有的 S 分布(见图 3);

-
假设c(:)连续,线性插值sb = · si + (1 − ) · sj; ε [0; 1],我们可以在 O(log2 dE (si;sj ) width( ) ) 轮二分查找内找到 sb 位于 -boundary 上,其中 width( ) 是连接 si 的线段上 -boundary 的宽度和 sj 在欧几里得空间中。
为了合成真实的边界样本,我们设置了 的上限。与搜索开销昂贵的对抗样本生成技术(例如 DeepFool(Moosavi-Dezfooli、Fawzi 和 Frossard 2016))相比,我们基于混合的方法更有保证在有限的搜索预算内合成边界样本。
多样性 给定分类器 c(·) 中的 C 个类别,我们合成 (C 2 ) 个类别对的边界样本。考虑到合成的多样性和效率,我们倾向于(1)迄今为止生成的边界样本数量较少的对和(2)具有高成功合成率的对。具体来说,
P
r
(
p
=
(
C
i
,
C
j
)
)
=
α
⋅
P
r
(
s
(
C
i
,
C
j
)
)
(5)
+
(
1
−
α
)
⋅
s
u
c
c
(
C
i
,
C
j
)
\begin{aligned} \mathrm{Pr}(p=(C_{i},C_{j}))& =\alpha\cdot\mathrm{Pr}(s(C_{i},C_{j})) \\ &&\text{(5)} \\ &+(1-\alpha)\cdot succ(C_{i},C_{j}) \end{aligned}
Pr(p=(Ci,Cj))=α⋅Pr(s(Ci,Cj))+(1−α)⋅succ(Ci,Cj)(5)
在方程 5 中,我们引入了一个权衡参数 ε [0; 1],在Pr(s(Ci; Cj))(即相对边界样本丰度)和succ(Ci; Cj)(即合成边界点的成功率)之间。具体来说,
Pr
(
s
(
C
i
,
C
j
)
)
=
m
a
x
(
0
,
ρ
−
n
u
m
(
C
i
,
C
j
)
)
∑
k
≠
m
m
a
x
(
0
,
(
ρ
−
n
u
m
(
C
k
,
C
m
)
)
)
(
6
)
\Pr(s(C_i,C_j))=\frac{max(0,\rho-num(C_i,C_j))}{\sum_{k\neq m}max(0,(\rho-num(C_k,C_m)))} \qquad{(6)}
Pr(s(Ci,Cj))=∑k=mmax(0,(ρ−num(Ck,Cm)))max(0,ρ−num(Ci,Cj))(6)
num((Ci; Cj)) 是迄今为止类 Ci 和 Cj 之间生成的边界点,并且是所有类对上生成点的平均数。
我们估计一对的成功合成率如下:
s
u
c
c
(
C
i
,
C
j
)
=
n
u
m
b
(
C
i
,
C
j
)
n
u
m
s
y
n
(
C
i
,
C
j
)
(
7
)
succ(C_i,C_j)=\frac{num_b(C_i,C_j)}{num_{syn}(C_i,C_j)}\quad(7)
succ(Ci,Cj)=numsyn(Ci,Cj)numb(Ci,Cj)(7)
numsyn(·) 是合成一对之间边界的试验次数,numb(·) 是搜索预算内成功试验的次数。
(k)-BAVR综合体建设
给定表示向量集 X 及其派生边界向量 B,我们在 U := X ∪ B 上构建 (k)-Boundary-Augmented Vietoris-Rips 复形,以采样边的代表性子集 (ui; uj) ∈ U × U用于训练编码器以保留边界/非边界邻居。
定义 3((k)-边界增强-Vietoris-Rips 复合体)。 (k)-Boundary-Augmented-Vietoris-Rips Complex ((k)-BAVR Complex) (k > 0) 是由 0-单纯形和 1-单纯形组成的单纯复形,使得 (1) 每个 0-单纯形是来自 U := X ∪ B 的点,并且 (2) 每个 1-单纯形由 U 中的两个点及其连接边组成,满足以下条件之一:
(a) {(xi; xj) : ∀xi ∈ X; j ∈ Nk(xi)} 其中 Nk(xi) 是 X 中 xi 所 k 见证的点的索引集。 j ∈ N
(b) k (xi) } ,其中 N (b) k (xi) 是 xi 所见证的 k 边界点的索引集。
(c ) {(bi; bj) : ∀bi ∈ B; j ∈ Nk(bi)},其中 Nk(bi) 是 bi 的 k 个最近边界邻居的索引集。
直观上,(k)-BAVR Complex 捕获了 U := X ∪ B 的拓扑结构。基于该 Complex,我们对正对集 Px×x+ ⊂ X × X 进行采样,其中 p = (xi; xj) ∈ Px×x+使得 xi 和 xj 形成 1-单纯形。类似地,我们得到 Px×b+ ⊂ X × B 和 Pb×b+ ⊂ B × B。此外,我们从 X × X、X × B 和 B × B 中随机选择对来构造三个负对集合,即 Px ×x− ⊂ X × X、Px×b− ⊂ X × B 和 Pb×b− ⊂ B × B。
最后,给定 P = Px×x+ ∪ Px×x− ∪ Px×b+ ∪ Px×b− ∪ Pb×b+∪Pb×b− ,我们遵循 (McInnes, Healy, and Melville 2018) 中定义的参数 umap 损失函数和(Sainburg、McInnes 和 Gentner 2020)来训练我们的编码器。
逆投影保持
编码器和解码器的损失函数为:
L
r
e
c
:
=
1
N
h
∑
i
=
1
N
∑
m
=
1
h
(
1
+
g
r
a
d
i
m
)
β
∣
∣
x
i
m
−
ψ
(
ϕ
(
x
i
m
)
)
∣
∣
2
(
8
)
g
r
a
d
i
:
=
a
b
s
(
∂
g
(
x
i
)
t
o
p
1
∂
x
i
)
+
a
b
s
(
∂
g
(
x
i
)
t
o
p
2
∂
x
i
)
(
9
)
\begin{aligned} \mathcal{L}_{rec}& :=\frac1{Nh}\sum_{i=1}^N\sum_{m=1}^h(1+grad_i^m)^\beta||\mathbf{x}_i^m-\psi(\phi(\mathbf{x}_i^m))||^2 \quad(8) \\ &grad_{i}:=abs(\frac{\partial g(\mathbf{x}_{i})_{top1}}{\partial\mathbf{x}_{i}})+abs(\frac{\partial g(\mathbf{x}_{i})_{top2}}{\partial\mathbf{x}_{i}})\quad(9) \end{aligned}
Lrec:=Nh1i=1∑Nm=1∑h(1+gradim)β∣∣xim−ψ(ϕ(xim))∣∣2(8)gradi:=abs(∂xi∂g(xi)top1)+abs(∂xi∂g(xi)top2)(9)
其中 h 是维度数,g(xi)top1 是 g(xi) 中的最大值,g(xi)top2 是 g(xi) 中的第二大值。基本原理在于,我们需要在将表示向量x投影和逆投影回原始空间后保留最关键的信息。这些信息位于 g(·)(用于预测其类别)和 g(xi)top2(用于测量边界)的 top-1 维度中。
时间连续性
我们通过迁移学习和时间损失函数来保持时间连续性。给定 V t−1(t ≥ 2),V t 使用 V t−1 的权重进行初始化。我们通过定义关于时间邻居保留率的时间损失来限制 V t 从 V t−1 的变化。
L t : = 1 N ∑ i = 1 N e v a l s e m ( x i t − 1 , x i t , k ) ⋅ ∥ W t − 1 − W t ∥ 2 (10) \mathcal{L}_t:=\frac1N\sum_{i=1}^Neval_{sem}(\mathbf{x}_i^{t-1},\mathbf{x}_i^t,k)\cdot\left\|\mathbf{W}_{t-1}-\mathbf{W}_t\right\|^2\text{(10)} Lt:=N1i=1∑Nevalsem(xit−1,xit,k)⋅∥Wt−1−Wt∥2(10)
我们将输入相似性语义定义为其连续历元之间共享的 k 见证邻居,令 Nk (xt−1 i ) 为历元 t − 1 中 xt−1 i 所 k 见证的所有点的索引集,并且 Nk(xt i) 在 t 纪元,
e v a l s e m ( x i t − 1 , x i t , k ) : = ∣ N k ( x i t − 1 ) ∩ N k ( x i t ) ∣ k ( 11 ) eval_{sem}(\mathbf{x}_i^{t-1},\mathbf{x}_i^t,k):=\frac{|N_k(\mathbf{x}_i^{t-1})\cap N_k(\mathbf{x}_i^t)|}k\quad(11) evalsem(xit−1,xit,k):=k∣Nk(xit−1)∩Nk(xit)∣(11)
在等式10中,Wt是(·)和(·)的权重,而Wt−1是上一时期学习的(·)和(·)的权重。训练 (·) 和 (·) 的最终损失函数是所有损失函数的加权和,即
L t o t a l = λ 1 ⋅ L u m a p + λ 2 ⋅ L r e c + λ 3 ⋅ 1 ( t ≥ 2 ) ⋅ L t (12) \mathcal{L}_{total}=\lambda_1\cdot\mathcal{L}_{umap}+\lambda_2\cdot\mathcal{L}_{rec}+\lambda_3\cdot\mathbb{1}(t\geq2)\cdot\mathcal{L}_t\text{(12)} Ltotal=λ1⋅Lumap+λ2⋅Lrec+λ3⋅1(t≥2)⋅Lt(12)
评估
属性测量。 我们测量空间和时间属性,即 n n p v ( k ) nn_{pv}(k) nnpv(k)、 b o u n d a r y p v ( k ) boundary_{pv}(k) boundarypv(k)、 r e c p v rec_{pv} recpv 和 t e m p o r a l p v ( k ) temporal_{pv}(k) temporalpv(k),如下所示。
- 保留邻居和边界距离:我们使用 n n p v ( k ) nn_{pv}(k) nnpv(k) 和 b o u n d a r y p v ( k ) boundary_{pv}(k) boundarypv(k),并令k = 10; 15; 20.
- 保留逆投影:我们评估预测保留率,即 P P R : = ∣ Q ∣ N PPR~:=~\frac{|\mathcal{Q}|}N PPR := N∣Q∣ 其中 Q : = { x ∣ arg max c g c ( x ) = arg max c g c ( ψ ( ϕ ( x ) ) ) , x ∈ X } \mathcal{Q}:=\{\mathbf{x}|\arg\max_cg_c(\mathbf{x})=\arg\max_cg_c(\psi(\phi(\mathbf{x}))),\mathbf{x}\in\mathbf{X}\} Q:={x∣argmaxcgc(x)=argmaxcgc(ψ(ϕ(x))),x∈X}。
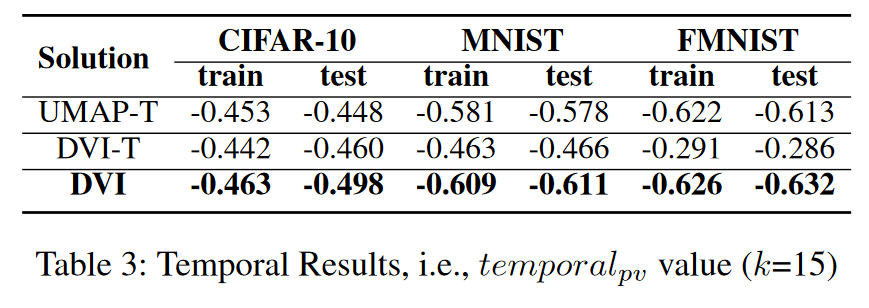
- 保持时间连续性:对于 t e m p o r a l p v ( k ) temporal_{pv}(k) temporalpv(k),我们使用Pearson 相关性并将k 设置为10、15 和20。
数据集和主题模型。 我们选择三个数据集,即 MNIST、Fashion-MNIST 和 CIFAR-10。我们使用 ResNet18(He et al. 2016)作为主题分类器,全局平均池化层的输出作为特征向量(即 512 维)。
基线。 我们选择 PCA、t-SNE、UMAP 和 DeepView 作为基线。我们在整个数据集上将 DVI 与 PCA、t-SNE、UMAP 进行比较,由于其可扩展性的限制,在数据集子集上将 DeepView 与 DeepView 进行比较。子集训练/测试大小设置为 1000/200(适合 DeepView 的经验大小),并且实验重复 10 次以减轻偏差。
运行时配置。 我们设计自动编码器的方式如下。给定特征向量的维度是h,我们让编码器和解码器分别具有
(
h
,
h
2
,
h
2
,
h
2
,
h
2
,
2
)
(h,\frac h2,\frac h2,\frac h2,\frac h2,2)
(h,2h,2h,2h,2h,2)和
(
2
,
h
2
,
h
2
,
h
2
,
h
2
,
h
)
(2,\frac h2,\frac h2,\frac h2,\frac h2,h)
(2,2h,2h,2h,2h,h)的形状。学习率初始设为0.01,并且每8个周期按因子10衰减。用于判定边界点的阈值设定为0.1。我们生成0.1*N个边界点,这些点被所有解共享。在生成边界点时,给参数γ设置的上限为0.4,在公式5中给λ设定的值为0.8,在公式8中给σ设定的值为1.0,而在总体损失(公式12)中的权衡超参数分别设为1.0,1.0,和0.3。
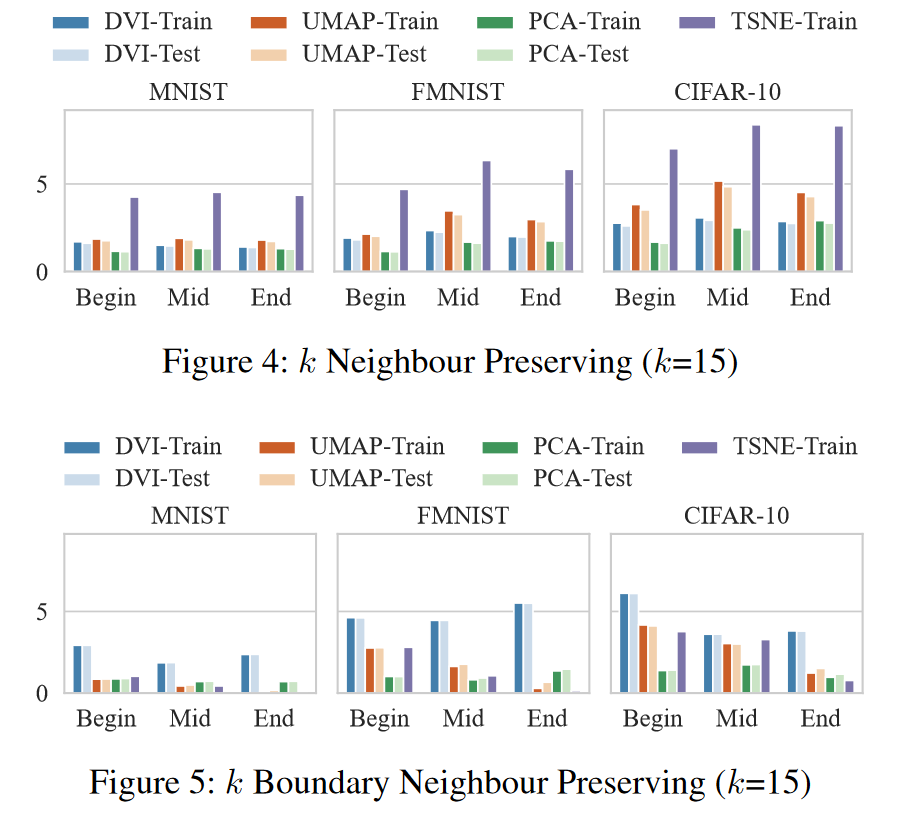
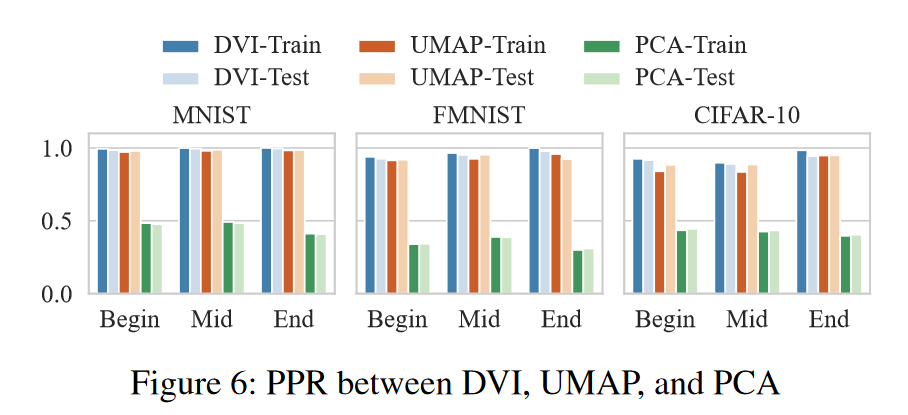
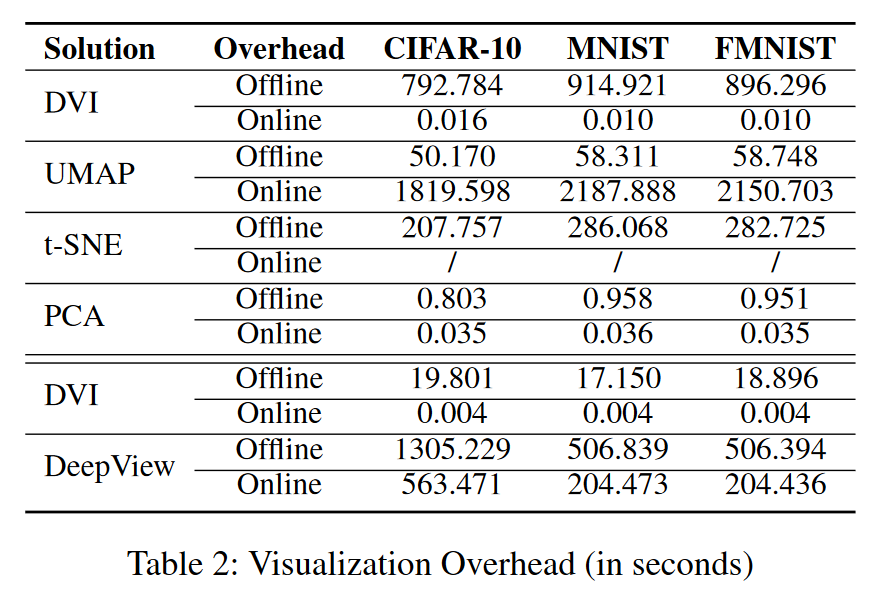
结果(空间属性)。 图 4、5、6 和表 2 显示了 DVI 和 PCA、UMAP 和 t-SNE 在三个数据集上的空间属性的性能。考虑到空间限制,我们展示了当k等于15时的结果,这个结果与 k ∈ { 10 , 20 } k ∈ \{10,20\} k∈{10,20} 范围内的表现相似(参见(DVI 2021))。我们报告了三个代表性时期的结果,即第 1 时期(代表开始时期)、第 ⌊ 1 + n 2 ⌋ \lfloor\frac{1+n}{2}\rfloor ⌊21+n⌋时期(代表中间时期)和第 n 时期(代表最终时期)。我们观察如下:
- PCA 与 DVI:PCA 是一种高效的解决方案(参见表 2)。但其线性变换有局限性,因此优于DVI和UMAP(见图4、5、6)。
- t-SNE 与 DVI:在训练数据集上,t-SNE 在投影后保留的邻居方面显着优于所有其他方法。然而,它不能(1)将投影推广到任何未见过的样本,以及(2)将二维点逆投影回特征向量空间。此外,t-SNE 无法像 DVI 和 UMAP 那样保留边界邻居(见图 5)。
- UMAP 与DVI:UMAP 在邻居保留投影和预测保留逆投影方面具有与DVI 相当的性能(如图4 和图6 所示)。然而,即使使用边界样本进行训练,在边界邻居保留投影方面,UMAP 的性能也大大优于 DVI。值得注意的是,当将低维点反投影到特征空间时,UMAP 比 DVI 需要更大的运行时间开销(UMAP 为 16.8 秒,DVI 为 0.002 秒,请参见表 2)。
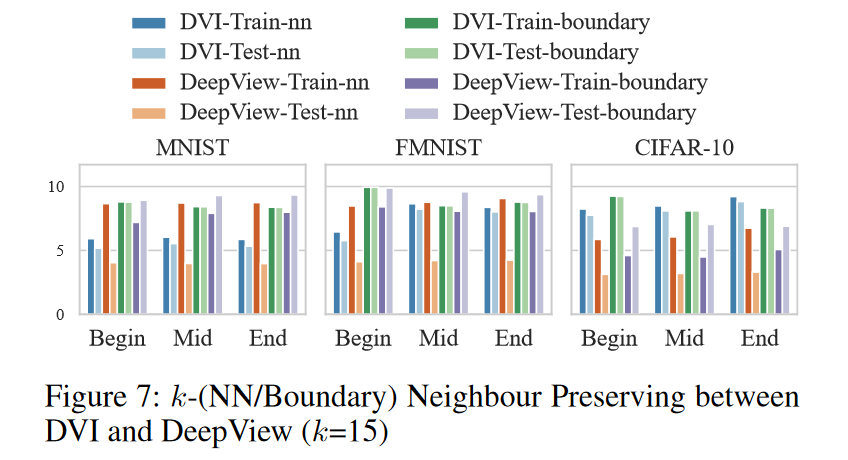
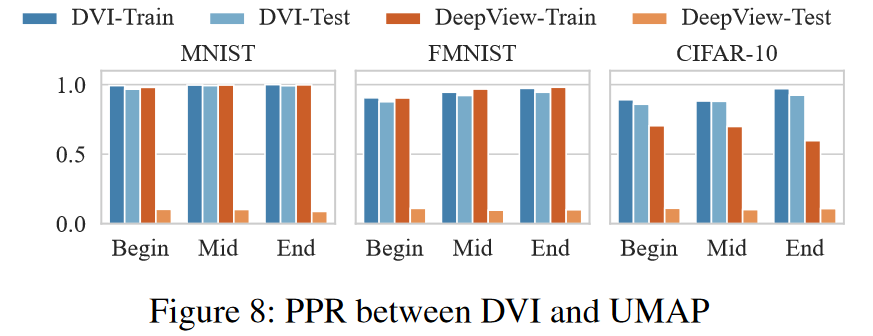
- DeepView 与 DVI:尽管 DeepView 的可扩展性有限,但 DeepView 在以下方面优于 DVI:
-
DeepView 更容易对训练数据集进行过拟合,因此其在测试集上保留的邻居远小于训练集上的邻居(见图 7)。
-
DeepView很难保存投影和反投影后的预测结果(见图8)。
-
结果(时间)。 我们比较了 (1) 通过迁移学习训练的 UMAP(表示为 UMAP-T)上的时间 pv 值; (2)通过迁移学习训练但没有时间损失的DVI(表示为DVI-T); (3)DVI(记为DVI),如表3所示。总体而言,DVI在时间连续性方面优于UMAP-T和DVI-T。
运行时效率。 表 2 显示了所有解决方案的运行效率。离线开销是训练可视化模型所花费的时间;在线开销是可视化新样本所花费的时间。总体而言,DVI 需要更多时间来训练编码器和解码器,而可视化运行时新数据的效率较高。相比之下,UMAP 的训练效率很高,但需要相当长的时间才能将低维点反投影回表示向量空间。此外,DVI 在离线和在线效率上都优于 DeepView。
案例分析
噪声(硬)样本检测 我们翻转 10% 的 CIFAR-10 样本的标签来训练分类器。图 9 显示了训练过程中如何学习干净/噪声样本嵌入。橙色点代表干净的样本,黑色点代表噪声样本。与在前几个时期顺利拉入其颜色对齐区域的干净样本相比,嘈杂的样本表现出“不愿意”被拉动(即学习)。这些“困难”样本在 epoch 的早期和中期停留在其“原始”区域,但在 epoch 的晚期被强行拉入其“预期”区域。

DVI 允许用户搜索他们感兴趣的样本并跟踪他们的动作,这可以作为潜在的模型调试工具。
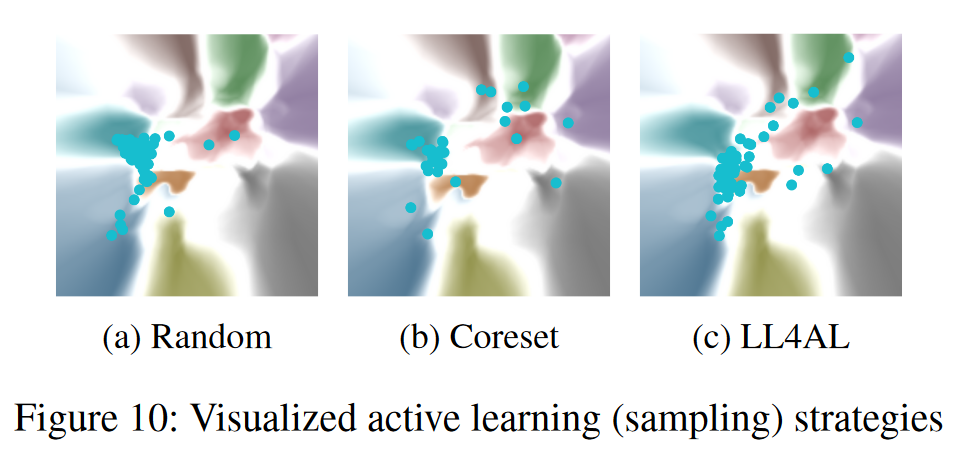
主动学习策略比较 主动学习算法对信息最丰富的未标记样本进行采样,以重新训练分类器。各种算法根据数据的多样性和不确定性对数据进行采样。图 10 比较了同一分类环境中不同主动学习算法的新采样数据。我们选择 Core-set(Sener 和 Savarese 2017)和 LL4AL(Yoo 和 Kweon 2019)作为基于多样性和不确定性的方法。与随机(点集中在颜色对齐的区域)相比,核心集选择均匀分布在整个景观中的样本,LL4AL 选择更接近决策边界的样本,证实了 DVI 可视化的有效性。
结论
我们提出 DVI 来可视化分类预测的形成方式。 DVI 可以用于模型训练过程的教育、异常诊断和采样策略比较。在这项工作中,我们正式定义了任何可视化工具在时空因果分析中都应满足的四个属性。我们开发了 DVI 来满足他们的需求,它可以可视化输入样本的布局和分类边界。在我们未来的工作中,我们将研究 DVI 的交互式解决方案,例如(Lin 等人,2017 年)和(Wang 等人,2019 年),以获取用户的反馈,帮助他们探索培训过程。
参考文献