堆栈操作
R1=0x005
R3=0x004
SP=0x80014
STMFD sp!, {r1, r3}
指令STMFD sp!, {r1, r3}是一条ARM架构中的存储多个寄存器到内存的指令,这里用于将r1和r3寄存器的内容存储到栈上。STMFD(Store Multiple Full Descending)是一种全递减模式的多寄存器存储指令,它会先将栈指针(SP)减去将要存储的寄存器数量乘以4(每个寄存器占用4字节),然后将寄存器内容存储到内存中,并最终更新栈指针的值(由于有!后缀,表示更新SP)。
根据给定的值:
R1的值为0x005。
R3的值为0x004。
栈指针SP的初始值为0x80014。
执行STMFD sp!, {r1, r3}指令后的操作结果:
因为要存储R1和R3两个寄存器,所以SP会先减去2 * 4 = 8字节。更新后的SP值为0x80014 - 8 = 0x8000C。
将R1和R3寄存器的内容按顺序(编码小的寄存器先存)存储到栈上,具体为:
R1的内容0x005会被存储到新的SP地址0x8000C。
然后,R3的内容0x004会被存储到0x80010的位置(因为是全递减模式,所以R1存储在更低的地址)。
注意:LDMDB R0!,{R8-R5}指令执行后,R0 - 4执行的地址是传给R8
在ARM汇编语言中,LDMDB R0!, {R8-R5}指令执行的是一个具有递减和写回的多寄存器加载操作。这条指令的含义可以拆解为以下几个部分:
LDM是Load Multiple的缩写,表示这是一个多寄存器加载指令。
DB代表Decrement Before,意味着在加载之前,基址寄存器(本例中为R0)的地址会先递减。
R0!表示使用R0作为基址寄存器,并在操作完成后,更新R0的值。!是写回(write-back)操作的标识。
{R8-R5}意味着从R8到R5这些寄存器将被加载数据。按照ARM的惯例,这样的范围是倒序的,即首先处理R8,然后是R7,以此类推,最后是R5。
关于R0-4执行后的地址是传给R8还是R5,通常在多寄存器加载/存储指令中,寄存器列表是按照升序排列,即使写作{R8-R5},在实际执行过程中也应当理解为操作是从低编号寄存器向高编号寄存器进行。然而,由于LDMDB指令使用的是递减模式,它实际上是从R8开始向下到R5加载数据,每次加载后基地址R0都会递减。
但是,容易引起混淆的一点是,ARM架构文档通常指示,在LDMDB这类指令中,数据是以升序的方式从内存地址加载的,即最低的寄存器号对应最低的地址。所以,如果从R0开始的一段连续内存被加载到了这些寄存器中,那么实际上:
R0的初始值减去递减的总量(因为是DB,所以操作前R0就已经被递减),通过写回操作更新R0的值;
由于是DB模式,所以加载操作是先将R0的值减少相应的数量后(在此例中,涉及到的寄存器数为4,所以可能是R0减少16(如果是32位系统)或更多(取决于寄存器宽度和具体的架构)),然后加载;
由于寄存器列表倒序的标记方式可能会导致理解上的混淆,实际存取顺序与寄存器编号的升序或降序无关,关键是根据指令的递增(IA/IB)或递减(DA/DB)模式确定加载顺序。
参考:https://blog.csdn.net/u011449588/article/details/44945411?spm=1001.2014.3001.5501
类似操作
在ARM指令集中,NE代表“Not Equal”,意味着该指令仅在零标志(Zero Flag)未被设置时执行。
总结操作结果,R1和R3的值会被存储到栈上,栈指针SP会更新为0x8000C,并且内存地址0x8000C和0x80010分别存储了R1和R3的值。
这是一个ARM架构中常见的利用栈保存现场的操作,常在函数调用前执行,以保护当前函数的局部变量和寄存器值不被调用的函数改变,同时调整SP为新的栈顶位置,以用于可能的后续操作。
LDRLE pc, [pc, r0, LSL #2]执行流程
指令LDRLE pc, [pc, r0, LSL #2]是一条条件加载(Load)指令,它的目的是根据某条件将数据从内存加载到程序计数器pc中。这条指令的各个部分代表的含义如下:
LDRLE:这是一个条件加载指令的前缀。LE代表"Less than or Equal",意味着只有当标志寄存器中的条件标志满足小于或等于(Z标志位为1或N不等于V)时,指令才会执行。如果条件不满足,则指令不执行任何操作,相当于NOP(无操作)。
pc:这是目标寄存器,即指令加载数据后的存储位置。这里的pc(程序计数器)用于控制程序的执行流程。
[pc, r0, LSL #2]:这是源操作数,表示加载操作的地址。该地址是通过将寄存器r0的值逻辑左移2位(LSL #2)然后加上当前pc的值来计算得到的。左移2位相当于乘以4,是用于访问数组或跳转表中元素的常用技巧。
执行流程大致如下:
检查条件标志位,判断是否满足"Less than or Equal"的条件。
如果条件满足,计算地址[pc, r0, LSL #2]。
从计算得到的内存地址处加载数据。
将加载得到的数据存储到pc寄存器中,实现程序的跳转。
LE判断
LE在LDRLE pc, [pc, r0, LSL #2]这条指令中代表的是“Less than or Equal to Zero”的意思,不是直接比较两个特定寄存器的值。
在ARM指令中,条件码如LE用于基于程序状态寄存器(condition flags)中的标志来决定是否执行某条指令。具体来说,LE条件码会检查零标志(Zero flag,Z)和符号标志(Negative flag,N)与溢出标志(Overflow flag,V)的关系。当Z标志被设置(表示前一运算的结果为零)或者N和V标志不等(表示负数结果不如预期那样大)时,LE条件满足,此时与LE相关的指令才会执行。因此,LE条件的比较是基于条件标志而不是直接比较寄存器之间的值。
在LDRLE pc, [pc, r0, LSL #2]指令的上下文中,如果条件满足(即程序认为上一个结果小于等于零),则加载指令被执行,否则该指令会被处理器忽略。这允许程序基于状态寄存器中的条件标志来有选择性地执行代码路径,支持分支、循环和条件执行等程序结构。
需注意,由于加载操作改变了pc的值,这实际上完成了一次条件分支操作,改变了程序的执行流程,可能用于实现如函数调用返回、条件分支等操作。此外,由于ARM的pc是流水线结构,对pc的操作通常涉及到流水线的处理,具体的影响需要根据处理器的具体实现来判断。
中断号有什么用
中断号在计算机系统中用于唯一标识每个中断源,它允许处理器和中断控制器正确识别和处理各种中断信号。每个中断源如外设(键盘、鼠标、网络接口)或内部事件(如定时器溢出、软件中断指令等)都分配有唯一的中断号。中断号的具体用途包括:
确定中断源:中断号可以帮助处理器确定触发中断的具体设备或条件。当多个中断源同时请求中断服务时,处理器或中断控制器通过中断号能够区分这些中断源。
中断向量表寻址:处理器使用中断号来访问中断向量表(IVT)或中断描述符表(IDT),这些表包含了每个中断号对应的中断服务程序(ISR)的入口地址。处理器根据中断号索引向量表,获得相应的中断处理程序地址,并跳转执行该程序。
确定中断优先级:在一些系统中,中断号还决定了中断请求的优先级,如recall slice 1所提及的LoongArch指令系统实现了向量中断,采用固定优先级仲裁机制,硬件中断号越大优先级越高。
实现向量化中断:向量化中断(recall slice 2和recall slice 3)通过为每个中断分配不同的号码和处理程序,简化了中断处理过程,省去了识别具体中断源的开销,从而可以加速中断的处理。
因此,中断号对于处理器正确、高效地响应和处理中断至关重要,使得系统能够实现快速的任务切换,及时响应外设请求,保障了运行时的实时性和稳定性。
如何通过__swi(中断号) function给中断函数指定中断号(一般在C代码中撰写)
在ARM架构下,__swi关键字用于在C代码中声明软件中断(Software Interrupt)函数,并为其指定一个特定的中断号。使用这种方法可以实现C代码与特定的中断服务例程(ISR)之间的接口,通常用于嵌入式系统或者操作系统内核的开发中。下面是一个使用__swi关键字来声明软件中断函数的例子:
c
__swi(0x123) void MyInterruptFunction(int argument);
在这个例子中,__swi关键字后跟着括号内的0x123是指定给该软件中断函数的中断号。接下来,void MyInterruptFunction(int argument);声明了一个名为MyInterruptFunction的软件中断函数,它接受一个int类型的参数。
当需要触发这个软件中断时,可以通过以下方式调用这个函数:
c
MyInterruptFunction(argument_value);
此调用将导致产生一个0x123号软件中断,并将argument_value作为参数传递给对应的处理函数。在底层实现中,编译器会将软件中断的调用转换为相应的软件中断指令(如ARM指令集中的SWI指令),并附带正确的中断号。
需要注意的是,具体的__swi关键字的语法和使用方式可能会根据不同的编译器稍有差异。此外,中断服务例程的实现和注册方式也依赖于具体的系统架构和操作系统的要求。
CMN
CMN指令应用示例
假设我们有以下两个寄存器的值:
R1寄存器的值为5
R2寄存器的值为3
我们执行如下指令:
CMN R1, R2
这条指令会将R1和R2的值相加,但不会将结果存储在任何寄存器中。CMN R1, R2等效于R1+R2的操作,但只是用来更新状态寄存器中的标志位,不存储结果。
结果说明
执行上述CMN指令后,R1和R2相加的结果是5 + 3 = 8。根据这个结果,程序状态寄存器(CPSR)将会这样更新:
零标志(Z flag)不会被设置,因为结果8不为零。
负标志(N flag)不会被设置,因为结果8是一个正数。
溢出标志(V flag)和进位标志(C flag)的设置取决于操作数的范围和具体的计算结果。在这个例子中,由于加法未产生位溢出或超过寄存器容量的情况,这两个标志通常不会被设置。
综上所述,CMN指令通过相加操作测试两个数相加的结果,主要用于影响接下来的条件指令,例如BNE(Branch if Not Equal)、BGT(Branch if Greater Than)等,根据CMN操作后状态寄存器中的标志位来决定程序的下一步执行路径。
报错分析
C 编译阶段的错误,语法错误
A 汇编时的错误,汇编语法有问题
L 库不全,地址分配、资源不够的问题
报错
处理器模式
功耗
功率: Dynamic>Standby>Sleep(idle)>off
优先级

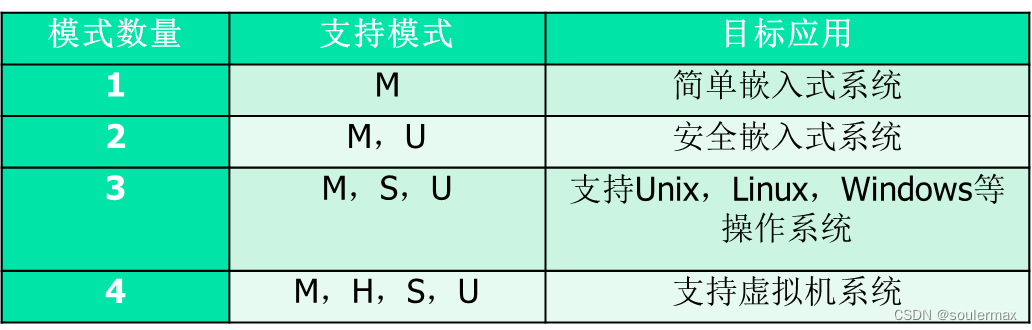
改变操作
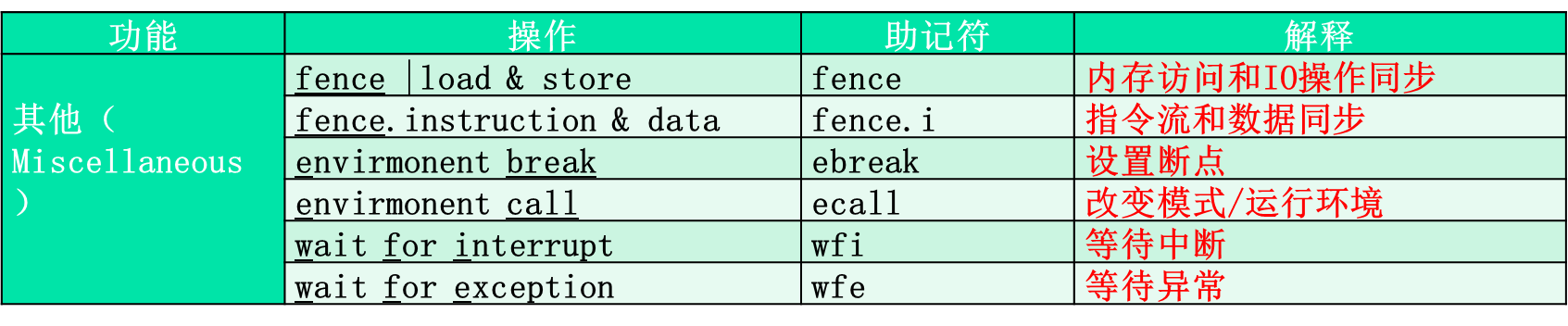
休眠模式WFI,WFE
Startup.s文件的功能和作用?
设置中断向量与中断服务程序地址
分配堆栈空间
设置时钟,看门狗Timer,内存控制,IO端口
设置中断入口IRQ_Entry
实现Reset_Handler
超过四个参数的处理情况
在ARM架构中,当发生软件中断(SWI)时,通常前四个参数会通过寄存器R0到R3传递给中断服务例程(ISR),如果有更多参数,则会通过堆栈传递。以下是处理超过4个参数的一个简单示例:
首先,假设我们有一个函数ExampleFunction,它需要6个参数,我们希望通过SWI来调用这个函数:
c
Copy
void ExampleFunction(int param1, int param2, int param3, int param4

![[C++] vector list 等容器的迭代器失效问题](https://img-blog.csdnimg.cn/direct/56ce869c0374425a9e0cafbf8d9971a9.png)