主要内容
在电力系统调度研究过程中,由于全年涉及的风、光和负荷曲线较多,为了分析出典型场景,很多时候就用到聚类算法,而K-means聚类就是常用到聚类算法,但是对于K-means聚类算法,需要自行指定分类数,如果没有方法支撑、纯自行确定分类数的话,显得随意性较大,很难令人信服,本次介绍一个方法——手肘法。
方法介绍
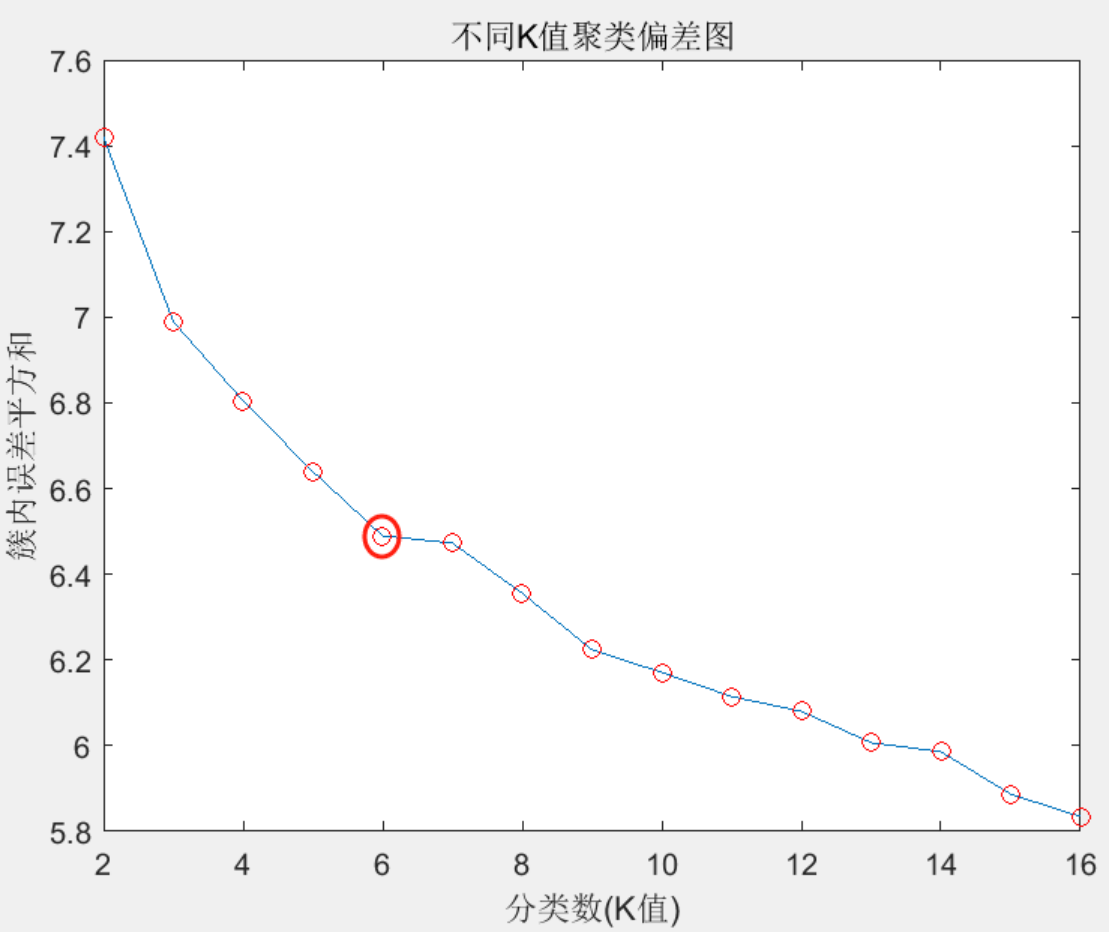
手肘法,很形象的命名方式,通过该方法得到的误差曲线类似手肘曲线,就以手肘位置的数作为最佳分类数。下面结合曲线特点来具体分析:
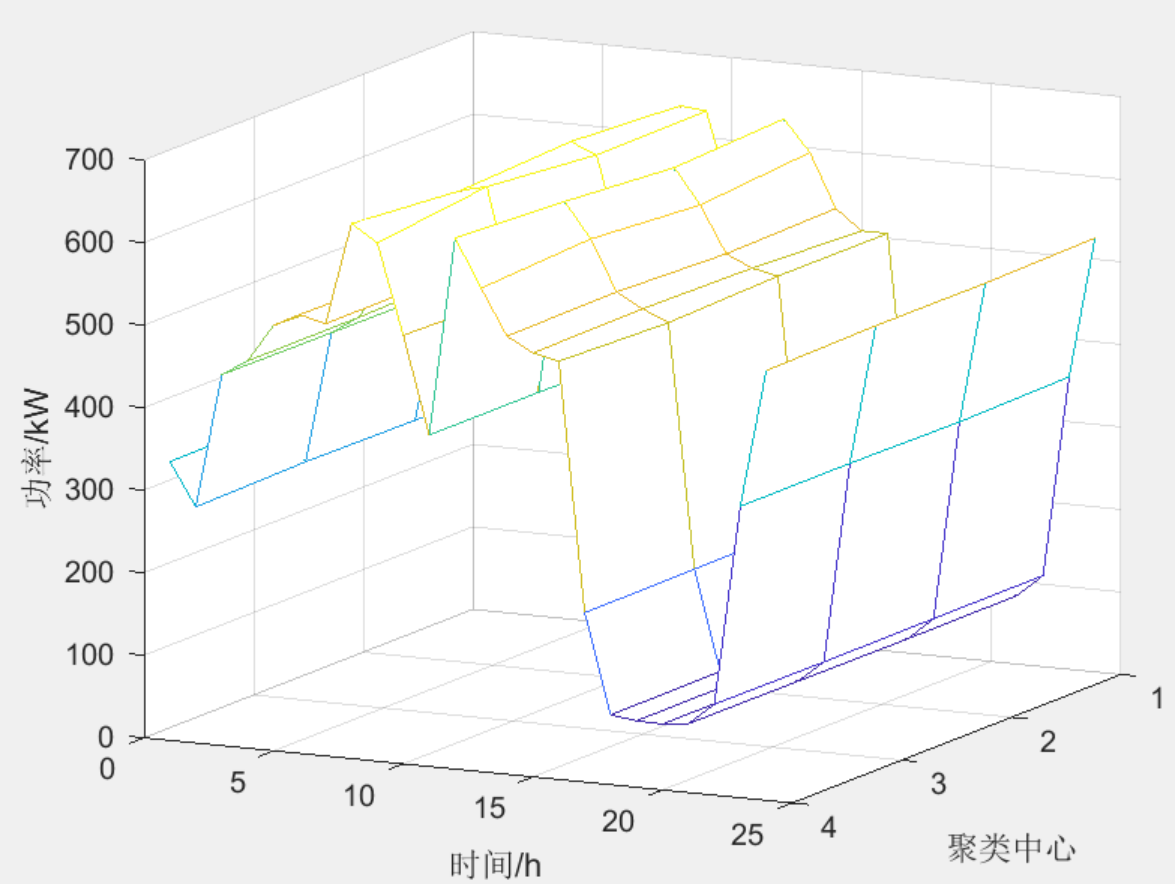
在 K-means 算法聚类过程中,分类数 k 值越大,样本数据被划分得越为精细,各类内样本数据的聚合程度越高,对应得到的误差平方和 SSE 值越小。在 k~SSE折线关系图中,折线的变化情况分为两个阶段:第一阶段,当 k 值小于最优分类数时,随着k值的增长,SSE 值越来越小,变化的幅度比较大,反映到 k~SSE 折线关系图中就是相邻两点之间的连线较陡。第二阶段,当 k 值大于最优分类数后,伴随着 k 值的增长,SSE 值仍是越来越小,但变化的幅度却比较小,反映到折线关系图中就是相邻两点之间的连线较为平缓。因此,随着k值的增长,k值与SSE 值的折线图会呈“手肘形”,而“肘部”对应的k 值即为最优分类数。下图中,最优分类数为肘部部位对应的4 。

SSE为,其计算公式为:

其中,Ci是第i个类,p是Ci类中的所有样本点,mi是Ci类的质心。
程序亮点
- 程序内置风电功率和光伏发电功率的拉丁超立方抽样算法,形成了数据集。
- 明确了数据更改方式,增加了详尽的修改方法注释,方便上手改成自己的数据。
- 可以得到不同聚类场景的概率以及聚类中心数据,程序注释清楚,方便研究使用。
- 采用两种方式进行分析,第一种是全年365天实测风力数据,第二种是拉丁超立方抽样方式。
部分代码
clc;clear all
% 基于LHS的可再生能源出力场景生成
ns=1000;
wind_predict = [339,287,449,471,512,530,527,641,634,519,401,634,589,530,512,505,206,85,81,80,83,110,353,523];%风电预测
pv_predict = [0,0,0,0,0,0,99,137,150,178,189,191,176,171,138,104,77,0,0,0,0,0,0,0 ];%光伏预测
wind_equ = 800 * ones(1,24);%风机装机容量
pv_equ = 240 * ones(1,24);%光伏装机容量
wind_sigma = 0.2 * wind_predict + 0.02* wind_equ ;
pv_sigma = 0.2 * pv_predict + 0.02 * pv_equ ; % 预测偏差的标准差
m1=ones(24,1000);%风生成
m2=ones(24,1000);%光生成
m=ones(24,1000);%可再生生成
wind_covariance_matrix = zeros (24,24);
pv_covariance_matrix = zeros (24,24);
for i= 1:24
wind_covariance_matrix(i,i) = wind_sigma(i)^2;
pv_covariance_matrix(i,i) = pv_sigma(i)^2;
end
for t=1:24
m1(t,:)=lhsnorm(0,wind_sigma(t),ns);%拉丁超立方采样
m2(t,:)=lhsnorm(0,pv_sigma(t),ns);
end
mpw=m1+wind_predict.';
mpv=m2+pv_predict.';
%手肘法确定k值
data = mpw';
%修改成自己的数据集的方式如下
结果一览
第一种:全年365天实测风力的效果图


第二种:拉丁超立方抽样
下载链接