最近学习torch的一个小demo。
什么是LSTM?
长短时记忆网络(Long Short-Term Memory,LSTM)是一种循环神经网络(RNN)的变体,旨在解决传统RNN在处理长序列时的梯度消失和梯度爆炸问题。LSTM引入了一种特殊的存储单元和门控机制,以更有效地捕捉和处理序列数据中的长期依赖关系。
通俗点说就是:LSTM是一种改进版的递归神经网络(RNN)。它的主要特点是可以记住更长时间的信息,这使得它在处理序列数据(如文本、时间序列、语音等)时非常有效。
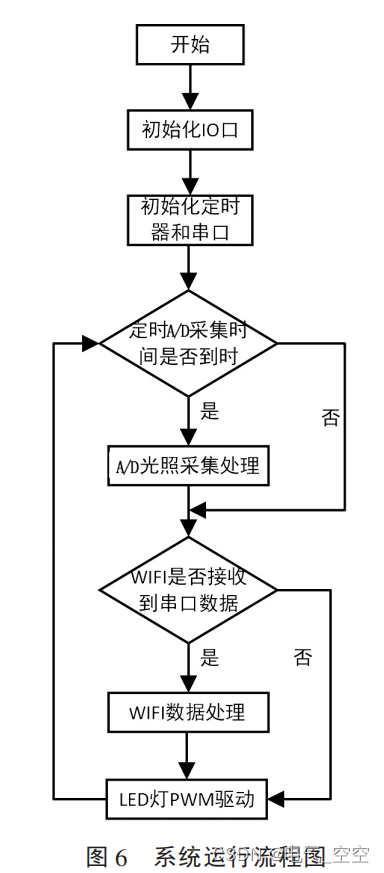
步骤如下
数据准备
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
import string
import os
# 数据加载和预处理
def load_data(filepath):
with open(filepath, 'r', encoding='utf-8') as file:
text = file.read()
return text
def preprocess_text(text):
text = text.lower()
text = text.translate(str.maketrans('', '', string.punctuation))
return text
data_path = 'poetry.txt' # 替换为实际的诗歌数据文件路径
text = load_data(data_path)
text = preprocess_text(text)
chars = sorted(list(set(text)))
char_to_idx = {char: idx for idx, char in enumerate(chars)}
idx_to_char = {idx: char for char, idx in char_to_idx.items()}
vocab_size = len(chars)
print(f"Total characters: {len(text)}")
print(f"Vocabulary size: {vocab_size}")

模型构建
定义LSTM模型:
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=2):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, x, hidden):
lstm_out, hidden = self.lstm(x, hidden)
output = self.fc(lstm_out[:, -1, :])
output = self.softmax(output)
return output, hidden
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = (weight.new(self.num_layers, batch_size, self.hidden_size).zero_(),
weight.new(self.num_layers, batch_size, self.hidden_size).zero_())
return hidden
训练模型
将数据转换成LSTM需要的格式:
def prepare_data(text, seq_length):
inputs = []
targets = []
for i in range(0, len(text) - seq_length, 1):
seq_in = text[i:i + seq_length]
seq_out = text[i + seq_length]
inputs.append([char_to_idx[char] for char in seq_in])
targets.append(char_to_idx[seq_out])
return inputs, targets
seq_length = 100
inputs, targets = prepare_data(text, seq_length)
# Convert to tensors
inputs = torch.tensor(inputs, dtype=torch.long)
targets = torch.tensor(targets, dtype=torch.long)
batch_size = 64
input_size = vocab_size
hidden_size = 256
output_size = vocab_size
num_epochs = 20
learning_rate = 0.001
model = LSTMModel(input_size, hidden_size, output_size)
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Training loop
for epoch in range(num_epochs):
h = model.init_hidden(batch_size)
total_loss = 0
for i in range(0, len(inputs), batch_size):
x = inputs[i:i + batch_size]
y = targets[i:i + batch_size]
x = nn.functional.one_hot(x, num_classes=vocab_size).float()
output, h = model(x, h)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss/len(inputs):.4f}")
生成
def generate_text(model, start_str, length=100):
model.eval()
with torch.no_grad():
input_eval = torch.tensor([char_to_idx[char] for char in start_str], dtype=torch.long).unsqueeze(0)
input_eval = nn.functional.one_hot(input_eval, num_classes=vocab_size).float()
h = model.init_hidden(1)
predicted_text = start_str
for _ in range(length):
output, h = model(input_eval, h)
prob = torch.softmax(output, dim=1).data
predicted_idx = torch.multinomial(prob, num_samples=1).item()
predicted_char = idx_to_char[predicted_idx]
predicted_text += predicted_char
input_eval = torch.tensor([[predicted_idx]], dtype=torch.long)
input_eval = nn.functional.one_hot(input_eval, num_classes=vocab_size).float()
return predicted_text
start_string = "春眠不觉晓"
generated_text = generate_text(model, start_string)
print(generated_text)
运行结果如下:
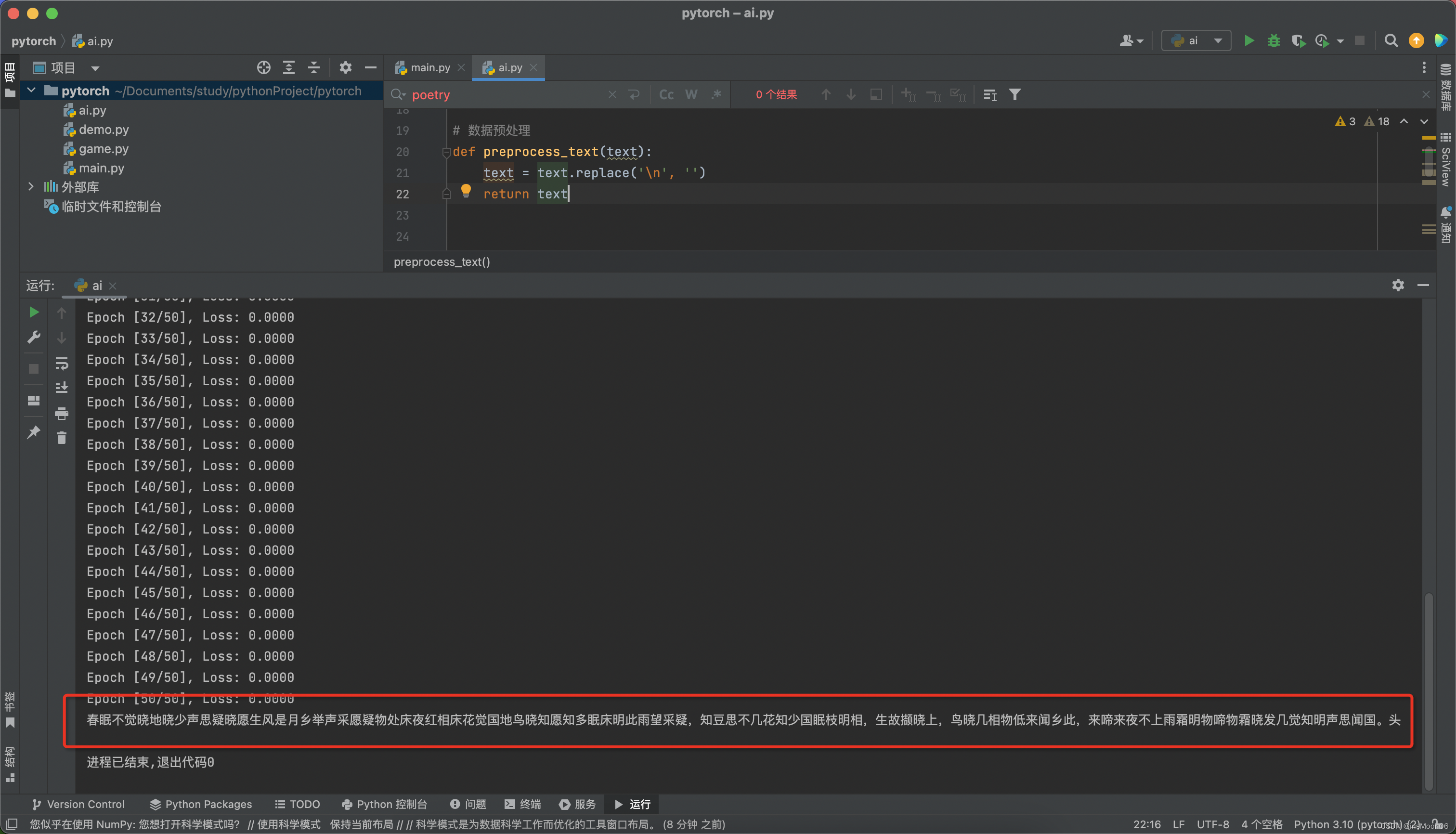
运行的肯定不好,但至少出结果了。诗歌我这边只放了几句,可以自己通过外部文件放入更多素材。
整体代码直接运行即可:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import random
import string
# 预定义一些中文诗歌数据
text = """
春眠不觉晓,处处闻啼鸟。
夜来风雨声,花落知多少。
床前明月光,疑是地上霜。
举头望明月,低头思故乡。
红豆生南国,春来发几枝。
愿君多采撷,此物最相思。
"""
# 数据预处理
def preprocess_text(text):
text = text.replace('\n', '')
return text
text = preprocess_text(text)
chars = sorted(list(set(text)))
char_to_idx = {char: idx for idx, char in enumerate(chars)}
idx_to_char = {idx: char for char, idx in char_to_idx.items()}
vocab_size = len(chars)
print(f"Total characters: {len(text)}")
print(f"Vocabulary size: {vocab_size}")
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_layers=2):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, x, hidden):
lstm_out, hidden = self.lstm(x, hidden)
output = self.fc(lstm_out[:, -1, :])
output = self.softmax(output)
return output, hidden
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = (weight.new(self.num_layers, batch_size, self.hidden_size).zero_(),
weight.new(self.num_layers, batch_size, self.hidden_size).zero_())
return hidden
def prepare_data(text, seq_length):
inputs = []
targets = []
for i in range(0, len(text) - seq_length, 1):
seq_in = text[i:i + seq_length]
seq_out = text[i + seq_length]
inputs.append([char_to_idx[char] for char in seq_in])
targets.append(char_to_idx[seq_out])
return inputs, targets
seq_length = 10
inputs, targets = prepare_data(text, seq_length)
# Convert to tensors
inputs = torch.tensor(inputs, dtype=torch.long)
targets = torch.tensor(targets, dtype=torch.long)
batch_size = 64
input_size = vocab_size
hidden_size = 256
output_size = vocab_size
num_epochs = 50
learning_rate = 0.003
model = LSTMModel(input_size, hidden_size, output_size)
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# Training loop
for epoch in range(num_epochs):
h = model.init_hidden(batch_size)
total_loss = 0
for i in range(0, len(inputs), batch_size):
x = inputs[i:i + batch_size]
y = targets[i:i + batch_size]
if x.size(0) != batch_size:
continue
x = nn.functional.one_hot(x, num_classes=vocab_size).float()
output, h = model(x, h)
loss = criterion(output, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {total_loss / len(inputs):.4f}")
def generate_text(model, start_str, length=100):
model.eval()
with torch.no_grad():
input_eval = torch.tensor([char_to_idx[char] for char in start_str], dtype=torch.long).unsqueeze(0)
input_eval = nn.functional.one_hot(input_eval, num_classes=vocab_size).float()
h = model.init_hidden(1)
predicted_text = start_str
for _ in range(length):
output, h = model(input_eval, h)
prob = torch.softmax(output, dim=1).data
predicted_idx = torch.multinomial(prob, num_samples=1).item()
predicted_char = idx_to_char[predicted_idx]
predicted_text += predicted_char
input_eval = torch.tensor([[predicted_idx]], dtype=torch.long)
input_eval = nn.functional.one_hot(input_eval, num_classes=vocab_size).float()
return predicted_text
start_string = "春眠不觉晓"
generated_text = generate_text(model, start_string, length=100)
print(generated_text)