大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
上下文长度是衡量AI模型/工具的一个重要指标。从表面上来看,它决定了模型能够记住多少信息,从本质上来看,它决定了信息的连贯性和AI的深度理解能力。这也是为什么国内的AI厂商在2024年初掀起了一波“卷”上下文长度的风潮。比如Kimi Chat本身就支持20万汉字上下文,后又开启了200万字上下文的内测(目前还在内测中...);以及阿里的通义千问在3月免费向所有用户开放了1000万字长文档处理功能(是的,你没有看错,就是1000万)。
那么,问题来了,引领了生成式AI浪潮的ChatGPT上下文长度是多少?
可能会有小伙伴下意识的回答出“128K”这个答案,因为GPT-4系列模型,不论是GPT-4 Turbo,还是最新的GPT-4o模型的上下文长度都是128K tokens。

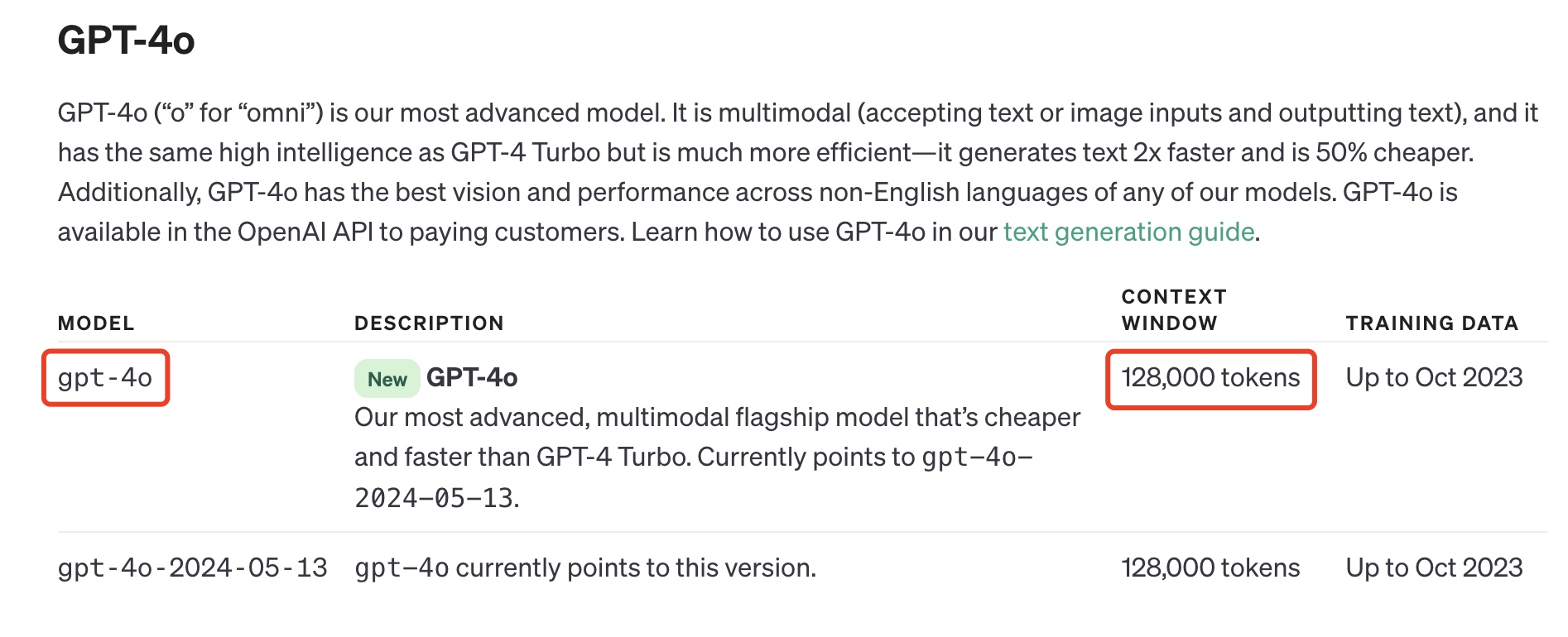
但这其实是一个误区。GPT-4模型的上下文长度是128K tokens这完全没有问题,但ChatGPT是一个建立在GPT-4模型上的独立的AI工具,它的上下文长度和模型的上下文长度是两个概念,因为可能还受到应用层面的一些限制,比如前端UI和架构设计。这些限制通常是为了优化性能和用户体验。
最典型的一个例子就是Kimi。Kimi以其20万汉字的上下文长度而为人熟知,但需注意,这是指Kimi Chat这款AI工具的上下文长度,而不是指Kimi家的AI模型——moonshot大模型。对于目前已经开放使用的moonshot-v1模型来说,最长的模型长度也仅仅是128K,离20万汉字还