1.引言
1.1.EANet模型简介
EANet(External Attention Transformer)是一种深度学习模型,它结合了Transformer架构和外部注意力机制,特别适用于图像分类等计算机视觉任务。以下是关于EANet的详细解释:
1.1.1 定义与背景
EANet是一种创新的神经网络架构,旨在通过引入外部注意力机制来改进传统的Transformer模型。传统的Transformer模型在计算自注意力时,需要对输入序列中的每个位置与其他所有位置进行交互,这导致了计算复杂度的增加。而EANet通过引入外部注意力机制,有效地降低了计算复杂度,并提高了模型的性能。
1.1.2.技术特点
- 外部注意力机制:EANet的核心是外部注意力机制,它通过使用两个可学习的外部存储器(一个用于键,一个用于值)来替代传统的自注意力计算。这两个存储器在整个数据集中共享,并通过线性层实现,因此可以通过端到端的反向传播来优化。这种外部注意力的轻量级本质使得模型能够以线性的计算复杂度处理输入数据。
- 泛化能力:由于外部存储器独立于单个样本并在整个数据集中共享,因此它们能够学习整个数据集中最具鉴别力的特征,并排除其他样本中的干扰信息。这种机制增强了模型的泛化能力,使其能够更好地适应不同的视觉任务。
- 可扩展性:EANet可以很容易地融入现有的基于自注意力的架构中,如DANet、SAGAN和T2T Transformer等。这使得模型能够灵活地应用于各种视觉任务,如图像分类、语义分割、图像生成、点云分类和分割等。
1.1.3.模型结构
EANet的模型结构通常包括编码器部分和解码器部分(尽管在某些应用中可能只使用编码器部分)。编码器部分由多个编码器层堆叠而成,每个编码器层包含外部注意力层和前馈全连接层。解码器部分(如果存在)则包含类似的结构,但还额外包括一个多头注意力层,用于处理编码器-解码器之间的交互。
1.1.4.性能表现
实验表明,EANet在多个视觉任务上均取得了与原始自注意力机制及其变体相当或更好的性能,同时以低得多的计算成本和内存开销。这证明了外部注意力机制的有效性以及EANet架构的优越性。
总体而言,EANet是一种结合了Transformer架构和外部注意力机制的深度学习模型,它通过引入两个可学习的外部存储器来降低计算复杂度并提高模型的性能。EANet具有泛化能力强、可扩展性好等优点,可以灵活地应用于各种视觉任务中。
1.2.Transformer架构
Transformer架构是一种在深度学习中广泛应用的模型,尤其在自然语言处理(NLP)和计算机视觉领域取得了显著成果。以下是关于Transformer架构的详细解释:
1.2.1 定义与背景
Transformer架构是Google在2017年的论文“Attention is All You Need”中提出的,它使用自注意力(Self-Attention)机制来捕捉输入序列中各个位置之间的依赖关系,从而有效地建模长距离依赖关系。相比传统的循环神经网络(RNN)或卷积神经网络(CNN),Transformer架构具有更好的并行计算能力,可以处理更长的序列。
1.2.2.架构组成
Transformer架构主要由以下几个部分组成:
- 输入部分:包括输入嵌入层(Input Embedding Layer)和位置编码层(Positional Encoding Layer)。输入嵌入层将输入的词汇或像素转换为向量表示,而位置编码层则为这些向量添加位置信息,以便模型能够理解序列中的位置关系。
- 编码器部分(Encoder):由多个编码器层(Encoder Layer)堆叠而成,每个编码器层包含两个子层:多头自注意力层(Multi-Head Self-Attention Layer)和前馈全连接层(Feed-Forward Network Layer)。在每个子层后都接有一个规范化层(Normalization Layer)和一个残差连接(Residual Connection),以加速训练并提高模型的性能。
- 解码器部分(Decoder):同样由多个解码器层(Decoder Layer)堆叠而成,每个解码器层包含三个子层:带掩码的多头自注意力层(Masked Multi-Head Self-Attention Layer)、多头注意力层(Encoder-Decoder Multi-Head Attention Layer)和前馈全连接层。解码器部分的自注意力层使用掩码来确保在预测某个位置的输出时,只能看到该位置之前的序列信息。
- 输出部分:解码器的输出经过线性层和Softmax层处理后,得到最终的输出序列。
1.2.3.模型特点
- 全局信息关系建模:通过自注意力机制,Transformer能够捕捉输入序列中各个位置之间的依赖关系,从而更好地建模长距离依赖关系。
- 并行计算能力:由于自注意力机制的计算是并行的,因此Transformer在处理长序列时具有更高的计算效率。
- 适用于多种任务:除了自然语言处理任务外,Transformer还可以应用于计算机视觉、语音识别等领域。
综合而言,Transformer架构是一种高效、灵活的深度学习模型,它通过自注意力机制实现了对长距离依赖关系的有效建模,并在多个领域取得了显著成果。随着计算资源的不断发展和模型优化技术的不断提高,相信Transformer架构将在未来发挥更加重要的作用。
1.3.外部注意力机制
外部注意力机制(External Attention Mechanism)是深度学习领域中的一种重要技术,特别是在处理序列数据或图像数据时,它能够帮助模型更好地关注输入数据中的关键部分。
1.3.1. 定义
外部注意力机制允许模型在处理一个任务时,参考另一个数据源(外部信息)来引导其注意力。这通常意味着模型会学习如何根据一个“查询”(query)从一个“键-值”(key-value)对集合中选择最相关的“值”(value)。
- 查询(Query):这是当前需要关注的部分或请求的信息。
- 键(Key)和值(Value):这些通常来自外部数据源,其中键用于与查询进行匹配,而值则是实际要关注的信息。
在处理时,模型会将查询与所有键进行比较,并基于相似度(如点积、余弦相似度等)为每个键分配一个权重。然后,这些权重被用于计算值的加权和,得到的结果就是注意力加权后的信息。
1.3.2. 应用场景
- 图像处理:在处理图像时,外部注意力机制可以用于帮助模型关注图像的特定部分,例如将注意力集中在人脸检测任务中的人脸区域。
- 自然语言处理:在自然语言处理任务中,如机器翻译或文本摘要,外部注意力机制可以用于帮助模型关注源文本中的关键部分,并在生成目标文本时利用这些关键信息。
1.3.3.与其他注意力机制的区别
- 自注意力(Self-Attention):自注意力机制是在单个输入序列内部进行注意力分配,而外部注意力机制则涉及两个或多个不同的输入序列。
- 多头注意力(Multi-Head Attention):多头注意力是注意力机制的一种变体,它使用多个独立的注意力头来并行地计算注意力权重,从而能够捕获输入数据中的多个不同方面。外部注意力机制可以与多头注意力结合使用,以提高模型的性能。
2.EANet的实现过程
2.1.安装及设置
import keras
from keras.layers import ( # 从keras.layers中导入常用的层
# 这里可以列出您需要的具体层,例如Dense、Conv2D等
Dense, Conv2D, # 示例层,您可以根据需要添加更多
)
# 如果您需要使用Keras的后端函数(例如K.function, K.mean等),您应该从keras.backend中导入
from keras import backend as K
# 导入matplotlib.pyplot用于绘制图像
import matplotlib.pyplot as plt
2.2 数据预处理
2.2.1.准备数据
本节提供的代码的主要功能是加载 CIFAR-100 数据集,并对数据进行预处理,以便用于深度学习模型的训练。
-
导入必要的库和模块:
- 导入
keras库,它是用于构建和训练深度学习模型的高级API。 - 从
keras.datasets导入cifar100,用于加载 CIFAR-100 数据集。 - 从
keras.utils导入to_categorical,用于将整数类别标签转换为独热编码格式。
- 导入
-
设置类别数量和输入数据的形状:
- 设置
num_classes为100,因为 CIFAR-100 数据集包含100个类别。 - 设置
input_shape为(32, 32, 3),因为 CIFAR-100 数据集中的每张图像都是 32x32 像素的 RGB 图像。
- 设置
-
加载 CIFAR-100 数据集:
- 使用
cifar100.load_data()函数加载 CIFAR-100 数据集,该函数返回四个数组:两个用于训练集(图像和标签),两个用于测试集(图像和标签)。
- 使用
-
对标签进行独热编码:
- 使用
to_categorical函数将整数类别标签转换为独热编码的多维数组。这样做是为了适应深度学习模型的输出层,因为输出层通常使用 softmax 激活函数,它期望输入是独热编码格式。
- 使用
-
打印数据集的形状信息:
- 打印训练集和测试集的图像数据(
x_train和x_test)和标签(y_train和y_test)的形状信息。这有助于了解数据集的大小和维度,以便在构建深度学习模型时设置正确的输入形状和输出单元数量。
- 打印训练集和测试集的图像数据(
import keras
from keras.datasets import cifar100
from keras.utils import to_categorical
# 设置类别数量
num_classes = 100
# 设置输入数据的形状
input_shape = (32, 32, 3)
# 加载 CIFAR-100 数据集
# CIFAR-100 是一个包含100个类别、共60000张32x32彩色图像的数据集
(x_train, y_train), (x_test, y_test) = cifar100.load_data()
# 将标签转换为独热编码格式
# to_categorical 函数用于将整数类别标签转换为独热编码的多维数组
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# 打印训练集和测试集的形状信息
# 这里 x_train 和 x_test 是图像数据的数组,y_train 和 y_test 是对应的标签数组
print(f"x_train shape: {x_train.shape} - y_train shape: {y_train.shape}")
print(f"x_test shape: {x_test.shape} - y_test shape: {y_test.shape}")
2.2.2.设置超参数
本节提供的代码的主要功能是设置一系列超参数,用于配置和控制深度学习模型的训练过程以及模型的架构。具体来说,这些超参数包括:
-
权重衰减 (
weight_decay): 控制L2正则化强度,用于防止模型过拟合。 -
学习率 (
learning_rate): 优化算法在每一步更新模型参数时的步长。 -
标签平滑 (
label_smoothing): 用于正则化模型输出,通过给定的标签添加一定程度的不确定性,提高模型泛化能力。 -
验证集划分比例 (
validation_split): 指定用于验证的图像占整个数据集的比例。 -
批量大小 (
batch_size): 每次训练迭代中使用的样本数量。 -
训练周期数 (
num_epochs): 整个数据集用于训练的遍历次数。 -
块大小 (
patch_size): 从输入图像中提取的特征块的大小。 -
图像中块的数量 (
num_patches): 根据图像尺寸和块大小计算得出。 -
嵌入维度 (
embedding_dim): 模型中嵌入层的输出维度。 -
多层感知机维度 (
mlp_dim): Transformer中多层感知机的维度。 -
维度系数 (
dim_coefficient): 用于计算MLP层的隐藏单元数量。 -
注意力头数量 (
num_heads): Transformer中注意力机制的头数。 -
注意力dropout比率 (
attention_dropout): 在注意力层中应用的dropout比率,用于正则化。 -
投影dropout比率 (
projection_dropout): 在投影层中应用的dropout比率。 -
Transformer块数量 (
num_transformer_blocks): 模型中重复的Transformer层的数量。
代码的最后部分打印了块的大小和每张图像中块的数量,这些信息对于理解模型如何处理图像数据很重要。这些超参数通常需要根据具体任务和数据集进行调整,以达到最佳的模型性能。
# 设置权重衰减,用于L2正则化
weight_decay = 0.0001
# 设置学习率
learning_rate = 0.001
# 设置标签平滑,用于改善模型的泛化能力
label_smoothing = 0.1
# 设置数据集划分比例,用于验证集
validation_split = 0.2
# 设置训练时的批量大小
batch_size = 128
# 设置训练的周期数
num_epochs = 50
# 设置从输入图像中提取的块的大小
patch_size = 2
# 计算每个图像中的块的数量
num_patches = (input_shape[0] // patch_size) ** 2
# 设置嵌入的维度,即隐藏单元的数量
embedding_dim = 64
# 设置多层感知机的维度
mlp_dim = 64
# 设置维度系数,用于计算MLP的隐藏层大小
dim_coefficient = 4
# 设置注意力头的数量
num_heads = 4
# 设置注意力层的dropout比率
attention_dropout = 0.2
# 设置投影层的dropout比率
projection_dropout = 0.2
# 设置Transformer块的重复次数
num_transformer_blocks = 8
# 打印块的大小和数量
print(f"块的大小: {patch_size} X {patch_size} = {patch_size ** 2}")
print(f"每张图像的块数量: {num_patches}")
2.2.3.进行数据增强
本节提供的代码定义了一个用于数据增强的Keras序列模型,以及使用训练数据来适应(计算均值和方差)标准化层的过程。
import keras
from keras import layers
# 创建一个数据增强序列模型
data_augmentation = keras.Sequential(
[
# 添加标准化层,用于将数据标准化到零均值和单位方差
layers.Normalization(),
# 添加随机水平翻转层,以增加数据多样性
layers.RandomFlip("horizontal"),
# 添加随机旋转层,旋转因子为0.1,表示最大旋转角度为10度
layers.RandomRotation(factor=0.1),
# 添加随机对比度层,对比度因子为0.1,表示对比度变化范围为10%
layers.RandomContrast(factor=0.1),
# 添加随机缩放层,高度和宽度因子为0.2,表示缩放范围为20%
layers.RandomZoom(height_factor=0.2, width_factor=0.2),
],
name="data_augmentation",
)
# 计算训练数据的均值和方差,以用于标准化处理
# adapt方法将计算x_train数据的统计数据,并存储在Normalization层中
data_augmentation.layers[0].adapt(x_train)
代码通过keras.Sequential创建了一个名为data_augmentation的模型,该模型包含一系列数据增强层,用于在训练过程中提高模型的泛化能力。
layers.Normalization()层用于对图像进行标准化处理,使其具有零均值和单位方差,这通常有助于模型训练的稳定性和收敛速度。layers.RandomFlip("horizontal")层执行水平随机翻转,增加了图像的对称性变体。layers.RandomRotation(factor=0.1)层在训练时对图像进行随机旋转,旋转幅度最多为10度,增加了图像的方向变体。layers.RandomContrast(factor=0.1)层调整图像的对比度,对比度变化范围为10%,使模型能够学习在不同光照条件下的特征。layers.RandomZoom(height_factor=0.2, width_factor=0.2)层对图像进行随机缩放,缩放范围为20%,模拟了不同视点下的图像变化。- 最后,调用
adapt方法使用训练集x_train的数据来计算标准化层所需的均值和方差,以便在训练和评估时使用相同的标准化参数。
数据增强是一种常见的技术,用于通过在训练过程中人为增加数据集的多样性来提高深度学习模型的鲁棒性。
2.3.构建模型
2.3.1.定义补丁提取和编码层
实现补丁提取和编码层(Patch Extraction and Encoding Layer)通常是在处理图像数据以用于深度学习模型(如 Vision Transformers,ViT)时的一个关键步骤。下面我将提供一个简单的示例,说明如何在Keras中实现这样的层。
在Vision Transformers中,图像通常首先被切分成固定大小的补丁(patches),然后这些补丁被展平并线性地映射到一个固定大小的嵌入向量。这个过程可以被看作是一个特殊的卷积层,其中卷积核的大小等于补丁的大小,步长也等于补丁的大小,且没有填充。
本节的代码定义了两个用于处理图像数据的Keras层:
PatchExtract类:用于从输入图像中提取固定大小的块(patches)。PatchEmbedding类:用于将提取的块嵌入到更高维的空间中,并添加位置信息。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import backend as K
class PatchExtract(layers.Layer):
def __init__(self, patch_size, **kwargs):
super().__init__(**kwargs)
# 保存块的大小
self.patch_size = patch_size
def call(self, x):
# 获取批量大小和通道数
B, C = K.shape(x)[0], K.shape(x)[-1]
# 从图像中提取大小为 self.patch_size 的块
x = K.image.extract_patches(x, self.patch_size)
# 重新排列块的维度,使其成为 [批量大小, 块的数量 * 块的尺寸 * 通道数]
x = K.reshape(x, (B, -1, self.patch_size * self.patch_size * C))
return x
class PatchEmbedding(layers.Layer):
def __init__(self, num_patch, embed_dim, **kwargs):
super().__init__(**kwargs)
# 保存块的数量和嵌入维度
self.num_patch = num_patch
# 创建一个密集层,用于将块投影到嵌入空间
self.proj = layers.Dense(embed_dim)
# 创建一个嵌入层,用于添加位置信息
self.pos_embed = layers.Embedding(input_dim=num_patch, output_dim=embed_dim)
def call(self, patch):
# 生成位置索引
pos = K.arange(start=0, stop=self.num_patch, step=1)
# 将块通过投影层,并加上位置嵌入
return self.proj(patch) + self.pos_embed(pos)
PatchExtract类在call方法中首先使用K.image.extract_patches函数从输入图像x中提取self.patch_size大小的块。然后,使用K.reshape将提取的块重新排列成一个新的维度格式,以便于后续处理。PatchEmbedding类在call方法中首先使用K.arange生成一个位置索引,然后通过投影层将提取的块映射到一个更高维的空间(self.proj(patch))。接着,通过嵌入层为每个块添加位置信息(self.pos_embed(pos)),最后将这两部分相加得到最终的嵌入表示。
这两个类通常用于实现基于Transformer的图像处理模型中,其中 PatchExtract 用于将图像分割成小块,而 PatchEmbedding 用于将这些块嵌入到一个连续的向量空间中,并提供位置感知能力。
2.3.2.定义外部注意力函数
实现外部注意力(External Attention)模块通常涉及在深度学习模型中使用一种特殊的注意力机制,该机制允许模型在外部数据源(如另一个序列或记忆单元)上执行注意力操作。
后面的代码定义了一个名为 external_attention 的函数,实现了一个外部(或称为“自注意力”)机制,它是Transformer模型中的一个关键组成部分。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import backend as K
def external_attention(
x,
dim,
num_heads,
dim_coefficient=4,
attention_dropout=0,
projection_dropout=0,
):
# 获取输入张量的形状:批量大小, 块的数量, 通道数
_, num_patch, channel = x.shape
# 确保维度可以被头数整除
assert dim % num_heads == 0
# 计算每个头处理的特征维度
num_heads = num_heads * dim_coefficient
# 通过全连接层将输入x的通道数映射到新的维度
x = layers.Dense(dim * dim_coefficient)(x)
# 重新排列张量形状,以便于进行多头注意力计算
x = K.reshape(x, (-1, num_patch, num_heads, dim * dim_coefficient // num_heads))
# 转置张量,使得注意力机制可以作用于不同的头
x = K.transpose(x, axes=[0, 2, 1, 3])
# 通过一个线性层M_k来计算注意力分数
attn = layers.Dense(dim // dim_coefficient)(x)
# 对注意力分数应用Softmax进行归一化
attn = layers.Softmax(axis=2)(attn)
# 双归一化:确保每行的和为1,增强数值稳定性
attn = layers.Lambda(
lambda a: K.divide(
a,
K.convert_to_tensor(1e-9) + K.sum(a, axis=-1, keepdims=True),
)
)(attn)
# 应用注意力dropout
attn = layers.Dropout(attention_dropout)(attn)
# 通过另一个线性层M_v将注意力分数应用于输入x
x = layers.Dense(dim * dim_coefficient // num_heads)(attn)
# 转置和重新排列张量,以恢复到原始形状
x = K.transpose(x, axes=[0, 2, 1, 3])
x = K.reshape(x, [-1, num_patch, dim * dim_coefficient])
# 通过一个线性层将特征维度映射回原始维度
x = layers.Dense(dim)(x)
# 应用投影dropout
x = layers.Dropout(projection_dropout)(x)
return x
external_attention函数接收输入张量x,以及一系列参数(dim,num_heads,dim_coefficient,attention_dropout,projection_dropout),用于控制注意力机制的行为。- 输入张量
x首先通过一个全连接层来增加其维度,然后重新排列以适应多头注意力的计算。 - 使用
Dense层和Softmax层来计算注意力分数,并通过Lambda层进行双归一化处理。 - 应用
Dropout层来控制注意力分数的dropout,以增强模型的泛化能力。 - 通过另一个全连接层将加权的输入特征映射回原始的维度,然后应用最终的
Dropout层。
这种注意力机制允许模型在处理序列数据时,能够关注于当前处理元素最重要的部分,这是Transformer架构的核心优势之一。
2.3.3.定义MLP
MLP (Multi-Layer Perceptron) 指的是多层感知机,是深度学习中的一个基础模块,它由多个全连接层(或称为密集层、线性层)组成,通常还包含激活函数。
后面的代码定义了一个多层感知机(MLP)模块的函数,该函数可以用于Transformer架构中的前馈网络(feed-forward network)。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import backend as K
def mlp(x, embedding_dim, mlp_dim, drop_rate=0.2):
# 对输入x应用一个全连接层,使用GELU激活函数
x = layers.Dense(mlp_dim, activation='gelu')(x)
# 应用dropout层,dropout率为drop_rate,以增强模型的泛化能力
x = layers.Dropout(drop_rate)(x)
# 将MLP的输出映射回原始的嵌入维度
x = layers.Dense(embedding_dim)(x)
# 再次应用dropout层
x = layers.Dropout(drop_rate)(x)
return x
mlp函数接收一个输入张量x,嵌入维度embedding_dim,MLP的隐藏层维度mlp_dim,以及dropout率drop_rate。- 输入张量首先通过一个全连接层(
Dense),其激活函数为GELU(Gaussian Error Linear Unit),这是一种近年来在自然语言处理领域流行起来的激活函数。 - 紧接着是一个dropout层,用于随机丢弃一部分激活值,dropout率由
drop_rate参数指定,这有助于防止模型过拟合。 - 然后,另一个全连接层将MLP的输出映射回原始的嵌入维度,以便与Transformer架构中的其他部分兼容。
- 最后,再次应用一个dropout层,以保持一致的正则化效果。
这种MLP模块通常用于Transformer中的编码器和解码器层内的中间部分,位于注意力机制之后,用于进一步处理和提取特征。
2.3.4.定义Transformer函数
在深度学习和自然语言处理(NLP)中,Transformer是一种基于自注意力(self-attention)机制的神经网络架构,被广泛用于各种NLP任务中,如机器翻译、文本分类、文本生成等。Transformer模型主要由多个Transformer block(Transformer模块)堆叠而成,每个模块包含两个主要部分:一个多头自注意力(multi-head self-attention)机制和一个前馈神经网络(feed-forward neural network,FFN)。
本段的代码定义了一个名为 transformer_encoder 的函数,实现了Transformer模型中的编码器层。
import tensorflow as tf
from tensorflow.keras import layers
def transformer_encoder(
x,
embedding_dim,
mlp_dim,
num_heads,
dim_coefficient,
attention_dropout,
projection_dropout,
attention_type="external_attention" # 指定注意力机制的类型,默认为"external_attention"
):
# 保存第一层的输入,用于残差连接
residual_1 = x
# 应用层归一化
x = layers.LayerNormalization(epsilon=1e-5)(x)
# 根据指定的注意力类型,应用不同的注意力机制
if attention_type == "external_attention":
# 使用自定义的外部注意力机制
x = external_attention(
x,
embedding_dim,
num_heads,
dim_coefficient,
attention_dropout,
projection_dropout,
)
elif attention_type == "self_attention":
# 使用Keras提供的多头自注意力机制
x = layers.MultiHeadAttention(
num_heads=num_heads,
key_dim=embedding_dim,
dropout=attention_dropout,
)(x, x)
# 应用残差连接并跳跃连接
x = layers.add([x, residual_1])
# 保存第二层的输入,用于残差连接
residual_2 = x
# 再次应用层归一化
x = layers.LayerNormalization(epsilon=1e-5)(x)
# 应用MLP模块
x = mlp(x, embedding_dim, mlp_dim, drop_rate=projection_dropout)
# 应用第二个残差连接并跳跃连接
x = layers.add([x, residual_2])
return x
transformer_encoder函数接收多个参数,包括输入张量x、嵌入维度embedding_dim、MLP维度mlp_dim、头数num_heads、维度系数dim_coefficient、注意力dropout比率attention_dropout、投影dropout比率projection_dropout,以及注意力类型attention_type。- 函数开始时,首先对输入
x应用层归一化。 - 根据
attention_type参数的值,选择使用“external_attention”自定义注意力机制或Keras内置的MultiHeadAttention多头自注意力机制。 - 在应用了注意力机制之后,使用残差连接将原始输入
residual_1加回到注意力层的输出上。 - 接着,再次应用层归一化,然后通过MLP模块进一步处理数据。
- 最后,再次使用残差连接将原始输入
residual_2加回到MLP层的输出上,完成编码器层的处理。
这种编码器层的设计是Transformer模型的核心,通过注意力机制和前馈网络的结合,能够有效地捕捉序列数据中的长距离依赖关系。残差连接和层归一化有助于避免深层网络训练中的梯度消失或爆炸问题。
2.3.5.定义EANet模型
EANet模型利用了外部注意力机制。传统自注意力的计算复杂度为O(d * N ** 2),其中d是嵌入尺寸,N是补丁(patch)的数量。作者发现,大多数像素仅与少数其他像素密切相关,而N到N的注意力矩阵可能是冗余的。因此,他们提出了一种替代方案,即外部注意力模块,其中外部注意力的计算复杂度为O(d * S * N)。由于d和S是超参数,所提出的算法在像素数量上是线性的。实际上,这相当于一种丢弃补丁的操作,因为图像中一个补丁中包含的很多信息是冗余和不重要的。
本节的代码定义了一个名为 get_model 的函数,用于创建一个基于Transformer架构的图像分类模型。
from tensorflow.keras import layers
def get_model(attention_type="external_attention"):
# 定义输入层,输入图像的形状
inputs = layers.Input(shape=input_shape)
# 数据增强
x = data_augmentation(inputs)
# 提取图像块
x = PatchExtract(patch_size)(x)
# 创建块嵌入表示
x = PatchEmbedding(num_patches, embedding_dim)(x)
# 堆叠Transformer编码器块
for _ in range(num_transformer_blocks):
x = transformer_encoder(
x,
embedding_dim,
mlp_dim,
num_heads,
dim_coefficient,
attention_dropout,
projection_dropout,
attention_type
)
# 使用全局平均池化层
x = layers.GlobalAveragePooling1D()(x)
# 分类头:使用全连接层输出分类结果,使用softmax激活函数
outputs = layers.Dense(num_classes, activation="softmax")(x)
# 创建Keras模型
model = keras.Model(inputs=inputs, outputs=outputs)
return model
get_model函数根据提供的attention_type参数(默认为"external_attention")来创建一个完整的Transformer模型。- 函数开始时定义了一个输入层,接收具有特定形状
input_shape的图像数据。 - 接着,数据通过
data_augmentation序列进行增强,增加了图像的多样性。 - 然后,使用
PatchExtract层从增强后的图像中提取固定大小patch_size的块。 PatchEmbedding层将提取的块嵌入到一个连续的向量空间,并添加位置信息。- 接下来,根据
num_transformer_blocks参数的值,堆叠多个transformer_encoder编码器块,每个块中都包含注意力机制和前馈网络。 - 经过Transformer编码器处理后,使用
GlobalAveragePooling1D层对特征进行池化,减少特征的空间维度,保留最重要的信息。 - 最后,通过一个全连接层
Dense进行分类,使用softmax激活函数输出每个类别的概率。 - 函数返回一个编译好的Keras模型,该模型可以接受图像输入并输出分类结果。
这个模型结合了数据增强、Transformer架构的编码器、位置编码和分类头,适用于图像分类任务。
2.4.使用CIFAR-100训练模型
本节代码演示了如何使用前面定义的 get_model 函数来创建一个Transformer模型,并对其进行编译和训练。
# 调用get_model函数创建模型,使用外部注意力机制
model = get_model(attention_type="external_attention")
# 编译模型
model.compile(
# 使用分类交叉熵作为损失函数,并添加标签平滑
loss=keras.losses.CategoricalCrossentropy(label_smoothing=label_smoothing),
# 使用AdamW优化器,它结合了Adam和权重衰减
optimizer=keras.optimizers.AdamW(
learning_rate=learning_rate, # 设置学习率
weight_decay=weight_decay # 设置权重衰减
),
# 选择评价指标,包括分类准确率和Top-5分类准确率
metrics=[
keras.metrics.CategoricalAccuracy(name="accuracy"),
keras.metrics.TopKCategoricalAccuracy(5, name="top-5-accuracy"),
],
)
# 训练模型
history = model.fit(
x_train, # 训练数据
y_train, # 训练标签
batch_size=batch_size, # 批量大小
epochs=num_epochs, # 训练周期数
# 指定训练数据中用于验证的比例
validation_split=validation_split,
)
- 使用
get_model函数创建了一个Transformer模型实例model,其中指定了使用外部注意力机制"external_attention"。 - 通过
model.compile方法编译模型,设置了损失函数为带有标签平滑的分类交叉熵CategoricalCrossentropy,优化器为AdamW(Adam优化器的变体,包含权重衰减),以及评价指标,包括准确率和Top-5准确率。 - 使用
model.fit方法训练模型,提供了训练数据x_train和标签y_train,设置了批量大小batch_size,训练周期数num_epochs,以及用于验证的数据比例validation_split。 - 训练过程中,模型将在每个epoch结束时在验证集上评估,并返回训练和验证的损失值及评价指标结果,这些信息存储在
history对象中,可用于后续的性能分析和模型调优。
这段代码是深度学习模型训练流程的典型示例,涵盖了模型创建、编译和训练的主要步骤。
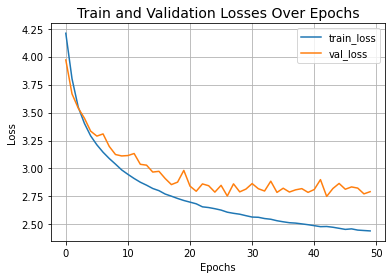
2.4.1. 训练过程可视化
本节的代码是使用 matplotlib 库绘制训练过程中损失函数值变化的图表。
import matplotlib.pyplot as plt
# 绘制训练损失和验证损失随着训练周期(Epochs)变化的曲线
plt.plot(history.history["loss"], label="train_loss") # 绘制训练损失
plt.plot(history.history["val_loss"], label="val_loss") # 绘制验证损失
# 设置x轴标签
plt.xlabel("Epochs")
# 设置y轴标签
plt.ylabel("Loss")
# 设置图表标题和字体大小
plt.title("Train and Validation Losses Over Epochs", fontsize=14)
# 显示图例
plt.legend()
# 显示网格线
plt.grid()
# 显示图表
plt.show()
- 使用
plt.plot方法绘制两个曲线,分别代表训练集上的损失(train_loss)和验证集上的损失(val_loss),这两个值是从模型训练的history对象中获取的。 - 使用
plt.xlabel和plt.ylabel方法分别设置X轴和Y轴的标签。 - 使用
plt.title方法设置图表的标题,并指定字体大小。 - 使用
plt.legend方法显示图例,以区分不同的曲线。 - 使用
plt.grid方法添加网格线,以便于观察和分析数据点。 - 使用
plt.show方法展示最终的图表。
这种损失曲线图是监控模型训练过程中性能的常用方式,有助于分析模型是否过拟合或欠拟合。如果训练损失远小于验证损失,可能是过拟合;如果两者都很高,可能是欠拟合。通过观察损失曲线的变化趋势,可以决定是否需要提前停止训练或调整模型参数。
2.4.2.训练结果
本节代码演示了如何使用训练好的模型在测试集上进行评估,并打印测试损失和准确率。
# 使用模型在测试集上进行评估
loss, accuracy, top_5_accuracy = model.evaluate(x_test, y_test)
# 打印测试损失值,四舍五入到小数点后两位
print(f"测试损失: {round(loss, 2)}")
# 打印测试准确率,四舍五入到小数点后两位,并转换为百分比形式
print(f"测试准确率: {round(accuracy * 100, 2)}%")
# 打印测试Top-5准确率,四舍五入到小数点后两位,并转换为百分比形式
print(f"测试Top-5准确率: {round(top_5_accuracy * 100, 2)}%")
- 使用
model.evaluate方法在x_test和y_test测试数据上评估模型的性能。 - 该方法返回三个值:测试损失(
loss),测试准确率(accuracy),和测试Top-5准确率(top_5_accuracy)。 - 打印出测试损失值,它衡量了模型在测试集上预测的平均误差。
- 打印出测试准确率,表示模型在测试集上正确分类的样本比例,乘以100转换为百分比形式,并四舍五入到小数点后两位。
- 打印出测试Top-5准确率,表示在测试集上,对于每个样本,模型预测的前5个最可能类别中至少包含正确类别的比例,同样转换为百分比形式,并四舍五入。
这段代码是模型评估的标准流程,通过这些指标可以了解模型在未见过的数据上的泛化能力。
3.总结和展望
3.1.总结
本文详细介绍了EANet(External Attention Transformer)模型,这是一种结合了Transformer架构和外部注意力机制的深度学习模型,特别适用于图像分类等计算机视觉任务。EANet通过引入两个可学习的外部存储器(一个用于键,一个用于值)来降低计算复杂度并提高模型的性能。模型的泛化能力强、可扩展性好,可以灵活地应用于各种视觉任务中。
文章首先对EANet模型进行了全面介绍,包括其定义、技术特点、模型结构和性能表现。接着,文章深入探讨了Transformer架构,解释了其定义、组成、特点以及在不同领域的应用。此外,文章还详细阐述了外部注意力机制的定义、应用场景和与其他注意力机制的区别。
在实现过程方面,文章提供了详细的代码示例,包括模型构建、数据预处理、超参数设置、数据增强、模型定义、训练和评估等步骤。这些代码示例为读者提供了如何使用Keras框架实现EANet模型的实际操作指导。
文章最后展示了模型训练过程的可视化,以及如何在测试集上评估模型性能并打印结果。通过这些结果,读者可以了解模型的泛化能力。
3.1. 展望
随着深度学习技术的不断发展,EANet模型及其外部注意力机制有望在未来发挥更加重要的作用。以下是一些可能的发展方向:
-
模型优化:进一步研究和优化EANet模型的结构和参数,以提高其在各种视觉任务上的性能。
-
多任务学习:探索EANet模型在多任务学习场景中的应用,例如同时进行图像分类、检测和分割。
-
跨领域应用:将EANet模型扩展到其他领域,如自然语言处理、语音识别等,以验证其通用性和有效性。
-
计算效率:研究如何进一步提高EANet模型的计算效率,减少训练和推理时间,使其更适合实时应用。
-
模型泛化:通过更多的数据增强技术和正则化方法,提高模型的泛化能力,减少过拟合的风险。
-
可解释性:提高模型的可解释性,帮助研究人员和开发者更好地理解模型的决策过程。
-
开源社区:通过开源社区的力量,共同推动EANet模型及其变体的发展,分享最佳实践和应用案例。
EANet模型作为一种创新的深度学习架构,其在未来的研究和应用中具有巨大的潜力。随着计算资源的日益丰富和模型优化技术的进步,我们期待EANet能够在更多的领域和任务中展现其优越性。
参考文献
[1]Keras团队. (2023-7-18). EANet模型示例. Keras官方文档. 检索自: https://keras.io/examples/vision/eanet/。