【Apache Doris】Compaction 原理 | 实践全析
- 一、Compaction 前文概要
- 二、Compaction 版本策略
- 三、Compaction 类型说明
- 四、Compaction 工程实现
- 五、Compaction 生产实践
作者 | 俞剑波
一、Compaction 前文概要
- LSM-Tree 简介
LSM-Tree( Log Structured-Merge Tree)是数据库中最为常见的存储结构之一,其核心思想在于充分发挥磁盘连续读写的性能优势、以短时间的内存与 IO 的开销换取最大的写入性能,数据以 Append-only 的方式写入 Memtable、达到阈值后冻结 Memtable 并 Flush 为磁盘文件、再结合 Compaction 机制将多个小文件进行多路归并排序形成新的文件,最终实现数据的高效写入。
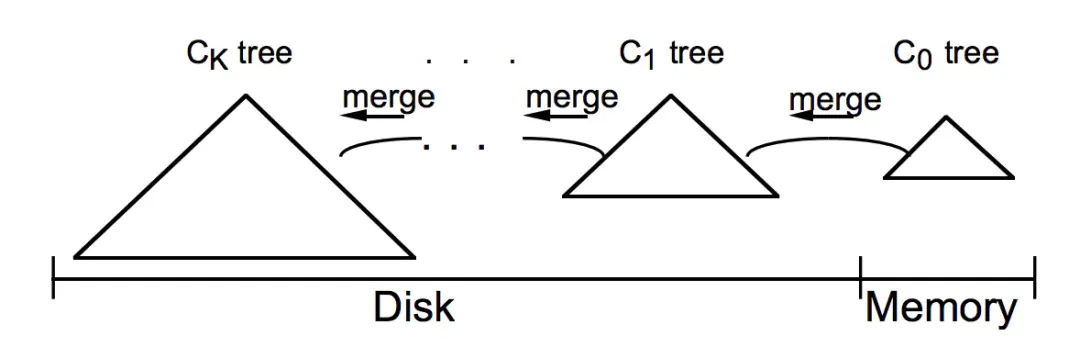
- Compaction 简要流程
Apache Doris 的存储模型也是采用类似的 LSM-Tree 数据模型。用户不同批次导入的数据会先写入内存结构,随后在磁盘上形成一个个的 segment文件,每个segment文件包含了部分数据,并且这些文件会根据一定的规则进一步组织成Rowset逻辑结构,每个 Rowset 对应一次数据导入版本。而 Doris 的 Compaction 操作则是负责将这些 Rowset 进行合并,将多个小的 Rowset 合并成一个 大Rowset 。
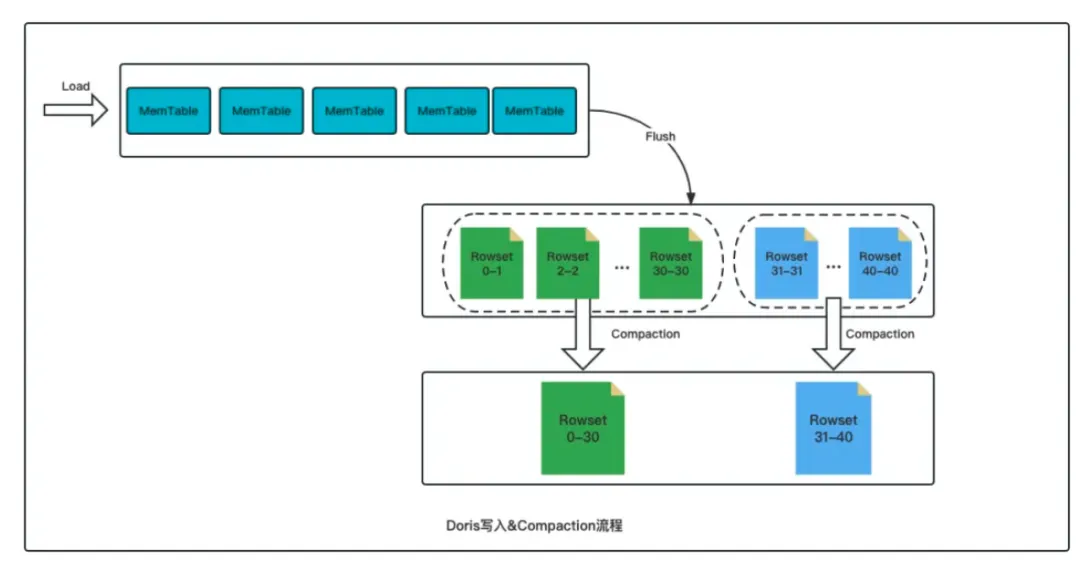
这种数据结构可以将随机写变为顺序写。这是一种面向写优化的数据结构,他能增强系统的写入吞吐,但是在读逻辑中,需要通过 Merge-on-Read 的方式,在读取时合并多次写入的数据,从而处理写入时的数据变更。
Merge-on-Read 会影响读取的效率,为了降低读取时需要合并的数据量,基于 LSM-Tree 的系统都会引入后台数据合并的逻辑,以一定策略定期的对数据进行合并。Doris 中这种机制被称为 Compaction。
Compaction 的逻辑本质上是要将多个无序的 Rowset 合并成一个有序的 Rowset,在大部分场景中,Rowset 内或者 Rowset 间的数据并不是完全无序的,可以充分利用局部有序性进行数据合并,在同一时间仅需加载有序文件中的第一个,这样随着合并的进行再逐渐加载。利用数据的局部有序性按需加载,能够极大减少数据合并过程中的内存消耗。
- Compaction 的优缺点
① Compaction的优点
-
数据更加有序
- 每个 Rowset 内的数据是按主键有序的,但 Rowset 与 Rowset 之间数据是无序的,Compaction 会将多个 Rowset 的数据从无序变为有序,提升数据在读取时的效率;
-
消除数据变更
- 数据以 Append-only 的方式进行写入,因此 Delete、Update 等操作都是标记写入,Compaction 会将标记的数据进行真正删除或更新,避免数据在读取时进行额外的扫描及过滤;
-
增加数据聚合度
- 在 Aggregate 模型上,Compaction 还可以将不同 Rowset 中相同 Key 的数据进行预聚合,减少数据读取时的聚合计算,进一步提升读取效率。
② Compaction的问题
-
Compaction 速度低于数据写入速度
- 在高频写入场景下,短时间内会产生大量的数据版本。如果 Compaction 不及时,就会造成大量版本堆积,最终严重影响写入速度。
-
写放大问题
- Compaction 本质上是将已经写入的数据读取后重写写回的过程,这种数据重复写入被称为写放大。一个好的Compaction策略应该在保证效率的前提下,尽量降低写放大系数。过多的 Compaction 会占用大量的磁盘IO资源,影响系统整体效率。
二、Compaction 版本策略
- 数据版本的产生(Rowset)
首先,用户的数据表会按照分区和分桶规则,切分成若干个数据分片(Tablet)存储在不同 BE 节点上。每个 Tablet 都有多个副本(默认为3副本)。每个 BE 节点上的 Compaction 操作都是独立进行的。Compaction 的对象是单个 BE 节点上的全部数据分片。
前文说到,Doris的数据都是以追加的方式写入系统的。Doris目前的写入依然是以微批的方式进行的,每一批次的数据针对每个 Tablet 都会形成一个 rowset。而一个 Tablet 是由多个Rowset 组成的。每个 Rowset 都有一个对应的起始版本和终止版本。对于新增Rowset,起始版本和终止版本相同,表示为 [6-6]、[7-7] 等。多个Rowset经过 Compaction 形成一个大的 Rowset,起始版本和终止版本为多个版本的并集,如 [6-6]、[7-7]、[8-8] 合并后变成 [6-8]。
Rowset 的数量直接影响到 Compaction 是否能够及时完成。那么一批次导入会生成多少个 Rowset 呢?这里我们举一个例子:
假设集群有3个 BE 节点。每个BE节点2块盘。只有一张表,2个分区,每个分区3个分桶,默认3副本。那么总分片数量是(2分区 * 3分桶 * 3副本)18 个,如果均匀分布在所有节点上,则每个盘上3个tablet。假设一次导入涉及到其中一个分区,则一次导入总共产生9个Rowset,即平均每块盘产生1-2个 Rowset。(这里仅考虑数据完全均匀分布的情况下,实际情况中,可能多个 Tablet 集中在某一块磁盘上)
从上面的例子我们可以得出,rowset的数量直接取决于表的分片数量。举个极端的例子,如果一个Doris集群只有3个BE节点,但是有9000个分片。那么一次导入,每个BE节点就会新增3000个rowset,则至少要进行3000次compaction,才能处理完所有的分片。所以:
合理的设置表的分区、分桶和副本数量,避免过多的分片,可以降低Compaction的开销。
- 数据分片的管理策略
Compaction 的目的是合并多个数据版本,一是避免在读取时大量的 Merge 操作,二是避免大量的数据版本导致的随机IO。因此,Compaction 策略的重点问题,就是如何选择合适的 tablet,以保证节点上不会出现数据版本过多的数据分片。
① 生产者与消费者
Compaction 是一个 生产者-消费者 模型。由一个生产者线程负责选择需要做 Compaction 的数据分片,而多个消费者负责执行 Compaction 操作。
生产者线程只有一个,会定期扫描所有 tablet 来选择合适的 compaction 对象。因为 Base Compaction 和 Cumulative Compaction 是不同类型的任务,因此目前的策略是每生成 9 个 CC 任务,生成一个 BC 任务。任务生成的频率由以下两个参数控制(这两个参数通常情况下不需要调整,2.0版本查不到对应的参数):
-
cumulative_compaction_rounds_for_each_base_compaction_round
- 多少个CC任务后生成一个BC任务,这是tablet的参数
-
generate_compaction_tasks_min_interval_ms
- 任务生成的间隔
生产者线程产生的任务会被提交到消费者线程池。因为 Compaction 是一个IO密集型的任务,为了保证 Compaction 任务不会过多的占用IO资源,Doris 限制了每个磁盘上能够同时进行的 Compaction 任务数量,以及节点整体的任务数量,这些限制由以下参数控制:
-
compaction_task_num_per_disk
- 每个磁盘(HDD)可以并发执行的compaction任务数量,默认4
-
compaction_task_num_per_fast_disk
- 每个高速磁盘(SSD)可以并发执行的compaction任务数量,默认8
-
max_base_compaction_threads
- Base Compaction 线程池中线程数量的最大值。默认为 4
-
max_cumu_compaction_threads
- Cumulative Compaction 线程池中线程数量的最大值。默认为 10
-
max_single_replica_compaction_threads
- Single Replica Compaction 线程池中线程数量的最大值。默认为 10
举个例子,假设compaction_task_num_per_disk设置为2,一个 BE 节点配置了3个数据目录(即3块磁盘),每个磁盘上的任务数配置为2,总线程数为6。则同一时间,最多有6个 Compaction 任务在进行,而每块磁盘上最多有2个任务在进行。并且最多有3个 BC 任务在进行,因为每块盘上会自动预留一个线程给CC任务。
另一方面,Compaction 任务同时也是一个内存密集型任务,因为其本质是一个多路归并排序的过程,每一路是一个数据版本。如果一个 Compaction 任务涉及的数据版本很多,则会占用更多的内存,如果仅限制任务数,而不考虑任务的内存开销,则有可能导致系统内存超限。因此,Doris 在上述任务个数限制之外,还增加了一个任务配额限制:
-
total_permits_for_compaction_score
- Compaction 任务配额,默认 10000
每个 Compaction 任务都有一个配额,其数值就是任务涉及的数据版本数量。假设一个任务需要合并100个版本,则其配额为100。当正在运行的任务配额总和超过配置后,新的任务将被拒绝。
② 数据版本选择策略
一个 Compaction 任务对应的是一个数据分片(Tablet)。消费线程拿到一个 Compaction 任务后,会根据 Compaction 的任务类型,选择 tablet 中合适的数据版本(Rowset)进行数据合并。下面分别介绍 Base Compaction 和 Cumulative Compaction 的数据分片选择策略。
1)Base Compaction
前文说过,BC 任务是增量数据和基线数据的合并任务。并且只有比 Cumulative Point(CP) 小的数据版本才会参与 BC 任务。因此,BC 任务的数据版本选取策略比较简单。
首先,会选取所有版本在 0 到 CP之间的 rowset。然后根据以下几个配置参数,判断是否启动一个 BC 任务:
-
base_compaction_min_rowset_num
- BaseCompaction 触发条件之一:Cumulative 文件数目要达到的限制,达到这个限制之后会触发 BaseCompaction。默认值:5
-
base_compaction_min_data_ratio
- BaseCompaction 触发条件之一:Cumulative 文件大小达到 Base 文件的比例。默认值:0.3(30%)
-
base_compaction_num_cumulative_deltas
- 一次 BC 任务最小版本数量限制。默认为5。该参数主要为了避免过多 BC 任务。当数据版本数量较少时,BC 是没有必要的。
-
base_compaction_interval_seconds_since_last_operation
- 第一个参数限制了当版本数量少时,不会进行 BC 任务。但我们需要避免另一种情况,即某些 tablet 可能仅会导入少量批次的数据,因此当 Doris 发现一个 tablet 长时间没有执行过 BC 任务时,也会触发 BC 任务。这个参数就是控制这个时间的,默认是 86400,单位是秒
2)Cumulative Compaction
CC 任务只会选取版本比 CP 大的数据版本。其本身的选取策略也比较简单,即从 CP 版本开始,依次向后选取数据版本。最终的数据版本集合由以下参数控制:
-
compaction_min_size_mbytes
- cumulative compaction 进行合并时,选出的要进行合并的 rowset 的总磁盘大小大于此配置时,才按级别策略划分合并。小于这个配置时,直接执行合并。单位是 m 字节。一般情况下,配置在 128m 以内,配置过大会导致 cumulative compaction 写放大较多。默认值:64
-
cumulative_compaction_min_deltas
- cumulative compaction 策略:一次 CC 任务最少的版本数量限制。这个配置是和 cumulative_size_based_compaction_lower_size_mbytes 配置同时判断的。即如果版本数量小于阈值,并且数据量也小于阈值,则不会触发 CC 任务。以避免躲过不比较的 CC 任务。默认是5
-
cumulative_compaction_max_deltas
- cumulative compaction 策略:一次 CC 任务最大的版本数量限制。以防止一次 CC 任务合并的版本数量过多,占用过多资源。默认是1000
-
cumulative_compaction_policy
- 配置 cumulative compaction 阶段的合并策略,目前实现了两种合并策略,num_based 和 size_based。详细说明,ordinary,是最初版本的 cumulative compaction 合并策略,做一次 cumulative compaction 之后直接 base compaction 流程。size_based,通用策略是 ordinary 策略的优化版本,仅当 rowset 的磁盘体积在相同数量级时才进行版本合并。合并之后满足条件的 rowset 进行晋升到 base compaction 阶段。能够做到在大量小批量导入的情况下:降低 base compact 的写入放大率,并在读取放大率和空间放大率之间进行权衡,同时减少了文件版本的数据。默认值:size_based
CC 任务还有一个重要步骤,就是在合并任务结束后,设置新的 Cumulative Point。CC 任务合并完成后,会产生一个合并后的新的数据版本,而我们要做的就是判断这个新的数据版是 “晋升” 到 BC 任务区,还是依然保留在 CC 任务区。举个例子:
假设当前 CP 是 10。有一个 CC 任务合并了 [10-13] [14-14] [15-15] 后生成了 [10-15] 这个版本。如果决定将 [10-15] 版本移动到 BC 任务区,则需修改 CP 为 15,否则 CP 保持不变依然为 10。CP 只会增加,不会减少。以下参数决定了是否更新 CP:
-
compaction_promotion_ratio
- 晋升比率。cumulative compaction 的输出 rowset 总磁盘大小超过 base 版本 rowset 的配置比例时,该 rowset 将用于 base compaction。一般情况下,建议配置不要高于 0.1,低于 0.02。默认值:0.05
-
compaction_promotion_min_size_mbytes
- 最小晋升大小,Cumulative compaction 的输出 rowset 总磁盘大小低于此配置大小,该 rowset 将不进行 base compaction,仍然处于 cumulative compaction 流程中。单位是 m 字节。一般情况下,配置在 512m 以内,配置过大会导致 base 版本早期的大小过小,一直不进行 base compaction。默认值:64
-
compaction_promotion_size_mbytes
- 最大晋升大小,cumulative compaction 的输出 rowset 总磁盘大小超过了此配置大小,该 rowset 将用于 base compaction。单位是 m 字节。一般情况下,配置在 2G 以内,为了防止 cumulative compaction 时间过长,导致版本积压。默认值:1024
以上参数比较难理解,这里我们先解释下 “晋升” 的原则。一个 CC 任务生成的 rowset 的晋升原则,是其数据大小和基线数据的大小在 “同一量级”。这个类似 2048 小游戏,只有相同的数字才能合并形成更大的数字。而上面三个参数,就是用于判断一个新的rowset是否匹配基线数据的数量级。举例说明:
在默认配置下,假设当前基线数据(即所有 CP 之前的数据版本)的数据量为 10GB,
则晋升量级为 (10GB * 0.05)512MB。这个数值大于 64 MB 小于 1024 MB,满足条件。
所以如果 CC 任务生成的新的 rowset 的大小大于 512 MB,
则可以晋升,即 CP 增加。而假设基线数据为 50GB,则晋升量级为(50GB * 0.05)2.5GB。
这个数值大于 64 MB 也大于 1024 MB,因此晋升量级会被调整为 1024 MB。
所以如果 CC 任务生成的新的 rowset 的大小大于 1024 MB,则可以晋升,即 CP 增加。
从上面的例子可以看出,compaction_promotion_ratio 用于定义 “同一量级”,0.05 即表示数据量大于基线数据的 5% 的 rowset 都有晋升的可能,
而 compaction_promotion_min_size_mbytes 和 compaction_promotion_size_mbytes 用于保证晋升不会过于频繁或过于严格。
这三个参数会直接影响 BC 和 CC 任务的频率,尤其在高频导入场景下需要适当调整。
我们会在后续文章中举例说明。
③ 其他 Compaction 参数和注意事项
还有一些参数和 Compaction 相关,在某些情况下需要修改:
-
disable_auto_compaction
- 默认为 false,修改为 true 则会禁止 Compaction 操作。该参数仅在一些调试情况,或者 compaction 异常需要临时关闭的情况下才需使用。
Delete 灾难
通过 DELETE FROM 语句执行的数据删除操作,在 Doris 中也会生成一个数据版本用于标记删除。这种类型的数据版本比较特殊,我们称为 “删除版本”。删除版本只能通过 Base Compaction 任务处理。因此在在遇到删除版本时,Cumulative Point 会强制增加,将删除版本移动到 BC 任务区。因此数据导入和删除交替发生的场景通常会导致 Compaction 冲突。比如以下版本序列:
[0-10]
[11-11] 删除版本
[12-12]
[13-13] 删除版本
[14-14]
[15-15] 删除版本
[16-16]
[17-17] 删除版本
…
在这种情况下,CC 任务几乎不会被触发(因为CC任务只能选择一个版本,而无法处理删除版本),所有版本都会交给 Base Compaction 处理,导致 Compaction 进度缓慢。目前Doris还无法很好的处理这种场景,因此需要在业务上尽量避免。下面生产应用中会提到具体的情况。
三、Compaction 类型说明
- Cumulative Compaction(CC) 和 Base Compaction(BC)
Doris 中有两种基础的 Compaction 操作,分别称为 Base Compaction(BC) 和 Cumulative Compaction(CC),由Cumulative Point(CP) 划分,根据一定策略,选择一组rowset进行Compaction。
BC 是将基线数据版本(以0为起始版本的数据)和增量数据版本合并的过程,而CC是增量数据间的合并过程。BC操作因为涉及到基线数据,而基线数据通常比较大,所以操作耗时会比CC长。
如果只有 Base Compaction,则每次增量数据都要和全量的基线数据合并,写放大问题会非常严重,并且每次 Compaction 都相当耗时。因此我们需要引入 Cumulative Compaction 来先对增量数据进行合并,当增量数据合并后的大小达到一定阈值后,再和基线数据合并。这里我们有一个比较通用的 Compaction 调优策略:在合理范围内,尽量减少 Base Compaction 操作。
BC 和 CC 之间的分界线成为 Cumulative Point(CP),这是一个动态变化的版本号。比CP小的数据版本会只会触发 BC,而比CP大的数据版本,只会触发CC。
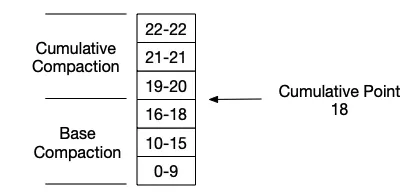
整个过程有点类似 2048 小游戏:只有合并后大小足够,才能继续和更大的数据版本合并。(等CP合并大小足够大后才会进行BC)

- Vertical Compaction
Vertical compaction 是 Doris 1.2.2 版本中实现的新的 Compaction 算法,用于解决大宽表(上千的场景)场景下的 Compaction 执行效率和资源开销问题。可以有效降低 Compaction 的内存开销,并提升 Compaction 的执行速度。
Vertical compaction 中将按行合并的方式改变为按列组合并,每次参与合并的粒度变成列组,降低单次 compaction 内部参与的数据量,减少 compaction 期间的内存使用。
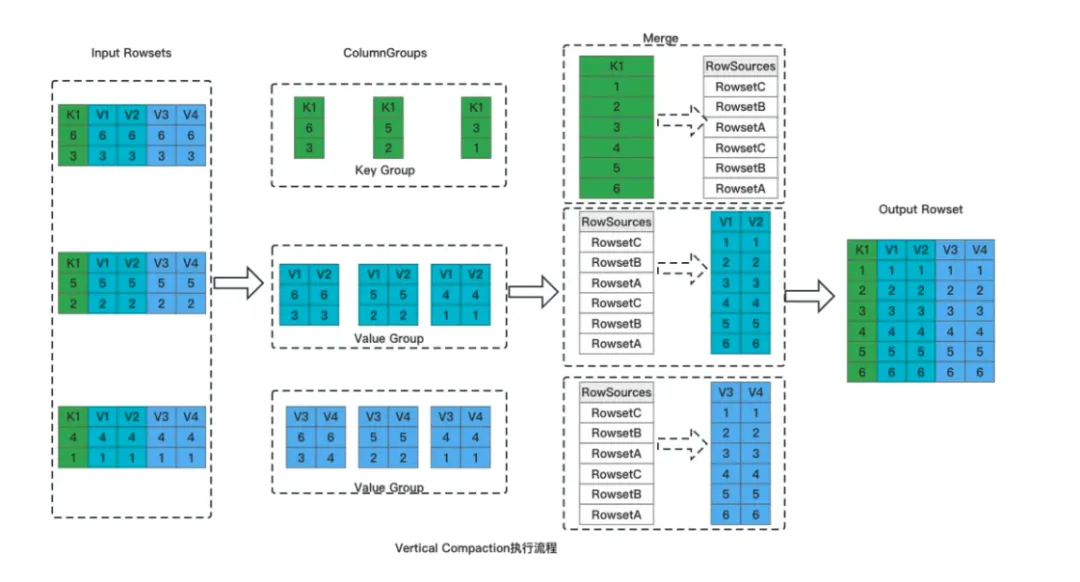
整体分为如下几个步骤:
-
切分列组。将输入 Rowset 按照列进行切分,所有的 Key 列一组、Value 列按 N 个一组,切分成多个 Column Group。
-
Key 列合并。Key 列的顺序就是最终数据的顺序,多个 Rowset 的 Key 列采用堆排序进行合并,产生最终有序的 Key 列数据。在产生 Key 列数据的同时,会同时产生用于标记全局序 RowSources。
-
Value 列的合并。逐一合并 Column Group 中的 Value 列,以 Key 列合并时产生的 RowSources 为依据对数据进行排序。
-
数据写入。数据按列写入,形成最终的 Rowset 文件。
由于采用了按列组的方式进行数据合并,Vertical Compaction 天然与列式存储更加贴合,使用列组的方式进行数据合并,单次合并只需要加载部分列的数据,因此能够极大减少合并过程中的内存占用。在实际测试中,Vertical Compaction 使用内存仅为原有 Compaction 算法的 1/10,同时 Compaction 速率提升 15%。
- Segment compaction
Segment compaction 主要应对单批次大数据量的导入场景。和 Vertical compaction 的触发机制不同,Segment compaction 是在导入过程中,针对一批次数据内,多个 Segment 进行的合并操作。这种机制可以有效减少最终生成的 Segment 数量,避免 -238(OLAP_ERR_TOO_MANY_SEGMENTS)错误的出现。Segment compaction 有以下特点:
-
可以减少导入产生的 segment 数量
-
合并过程与导入过程并行,不会额外增加导入时间
-
导入过程中的内存和计算资源的使用量会有增加,但因为平摊在整个导入过程中所以涨幅较低
-
经过 Segment compaction 后的数据在进行后续查询以及标准 compaction 时会有资源和性能上的优势
开启和配置方法 (BE 配置):
-
enable_segcompaction = true
- 可以使能该功能
-
segcompaction_batch_size
- 用于配置合并的间隔。默认 10 表示每生成 10 个 segment 文件将会进行一次 segment compaction。一般设置为 10 - 30,过大的值会增加 segment compaction 的内存用量
如有以下场景或问题,建议开启此功能:
-
导入大量数据触发 OLAP_ERR_TOO_MANY_SEGMENTS (errcode -238) 错误导致导入失败。此时建议打开 segment compaction 的功能,在导入过程中对 segment 进行合并控制最终的数量。
-
导入过程中产生大量的小文件:虽然导入数据量不大,但因为低基数数据,或因为内存紧张触发 memtable 提前下刷,产生大量小 segment 文件也可能会触发 OLAP_ERR_TOO_MANY_SEGMENTS 导致导入失败。此时建议打开该功能。
-
导入大量数据后立即进行查询:刚导入完成、标准 compaction 还没有完成工作时,此时 segment 文件过多会影响后续查询效率。如果用户有导入后立即查询的需求,建议打开该功能。
-
导入后标准 compaction 压力大:segment compaction 本质上是把标准 compaction 的一部分压力放在了导入过程中进行处理,此时建议打开该功能。
不建议使用的情况:
- 导入操作本身已经耗尽了内存资源时,不建议使用 segment compaction 以免进一步增加内存压力使导入失败。
关于 segment compaction 的实现和测试结果可以查阅此链接:
https://github.com/apache/doris/pull/12866?spm=wolai.workspace.0.0.4f75767b4cR4GK
- Ordered Data Compaction
随着越来越多用户在时序数据分析场景应用 Apache Doris,我们在 Apache Doris 2.0.0 版本实现了全新的 Ordered Data Compaction。
时序数据分析场景一般具备如下特点:数据整体有序、写入速率恒定、单次导入文件大小相对平均。针对如上特点,Ordered Data Compaction 无需遍历数据,跳过了传统 Compaction 复杂的读数据、排序、聚合、输出的流程,通过文件 Link 的方式直接操作底层文件生成 Compaction 的目标文件。
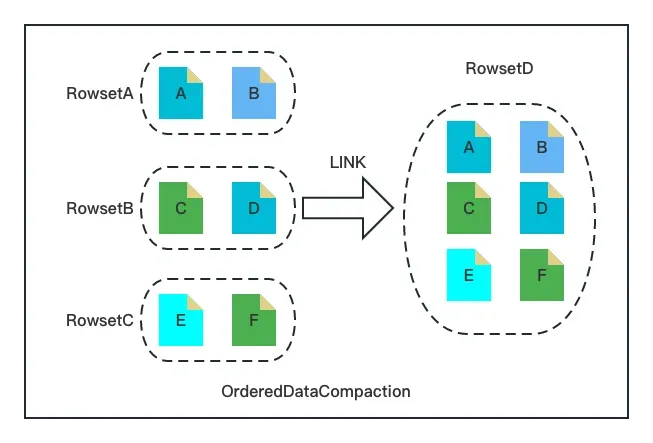
Ordered Data Compaction 执行流程包含如下几个关键阶段:
-
数据上传阶段。记录 Rowset 文件的 Min/Max Key,用于后续合并 Rowset 数据交叉性的判断。
-
数据检查阶段。检查参与 Compaction 的 Rowset 文件的有序性与整齐度,主要通过数据上传阶段的 Min /Max Key 以及文件大小进行判断。
-
数据合并阶段。将输入 Rowset 的文件硬链接到新 Rowset,然后构建新 Rowset 的元数据(包括行数,Size,Min/Max Key 等)。
可以看到上述阶段与传统的 Compaction 流程完全不一样,只需要文件的 Link 以及内存元信息的构建,极其简洁、轻量。针对时序场景设计的 Ordered Data Compaction 能够在毫秒级别完成大规模的 Compaction 任务,其内存消耗几乎为 0,对用户极其友好。
Ordered Data Compaction 在 2.0.0 版本中默认开启状态,如需调整在 BE 配置项中修改 enable_ordered_data_compaction即可。
四、Compaction 工程实现
除了上述在触发策略和 Compaction 算法上的优化之外,Apache Doris 2.0.0 版本还对 Compaction 的工程实现进行了大量细节上的优化,包括数据零拷贝、按需加载、Idle Schedule 等。
- 数据零拷贝
Doris 采用分层的数据存储模型,数据在 BE 上可以分为如下几层:
Tablet -> Rowset -> Segment -> Column -> Page
数据需要经过逐层处理。由于 Compaction 每次参与的数据量大,数据在各层之间的流转会带来大量的 CPU 消耗,在新版本中我们设计并实现了全流程无拷贝的 Compaction 逻辑,Block 从文件加载到内存中后,后续无序再进行拷贝,各个组件的使用都通过一个 BlockView 的数据结构完成,这样彻底的解决了数据逐层拷贝的问题,将 Compaction 的效率再次提升了 5%。
- 按需加载
Compaction 的逻辑本质上是要将多个无序的 Rowset 合并成一个有序的 Rowset,在大部分场景中,Rowset 内或者 Rowset 间的数据并不是完全无序的,可以充分利用局部有序性进行数据合并,在同一时间仅需加载有序文件中的第一个,这样随着合并的进行再逐渐加载。利用数据的局部有序性按需加载,能够极大减少数据合并过程中的内存消耗。
- Idle schedule
在实际运行过程中,由于部分 Compaction 任务占用资源多、耗时长,经常出现因为 Compaction 任务影响查询性能的 Case。这类 Compaction 任务一般存在于 Base compaction 中,具备数据量大、执行时间长、版本合并少的特点,对任务执行的实时性要求不高。在新版本中,针对此类任务开启了线程 Idle Schedule 特性,降低此类任务的执行优先级,避免 Compaction 任务造成线上查询的性能波动。
- 易用性
在 Compaction 的易用性方面,Doris 2.0.0 版本进行了系统性优化。结合长期以来 Compaction 调优的一些经验数据,默认配置了一套通用环境下表现最优的参数,同时大幅精简了 Compaction 相关参数及语义,方便用户在特殊场景下的 Compaction 调优。

五、Compaction 生产实践
- 查看和触发Compaction的方式
① 查看Compaction
GET /api/compaction/run_status GET /api/compaction/show?tablet_id={int}
② 触发Compaction
–取值为base或cumulative或full,只有table才能指定full
POST /api/compaction/run?tablet_id={int}&compact_type={enum}
POST /api/compaction/run?table_id={int}&compact_type=full
③ Tablet中实际Compaction详细过程
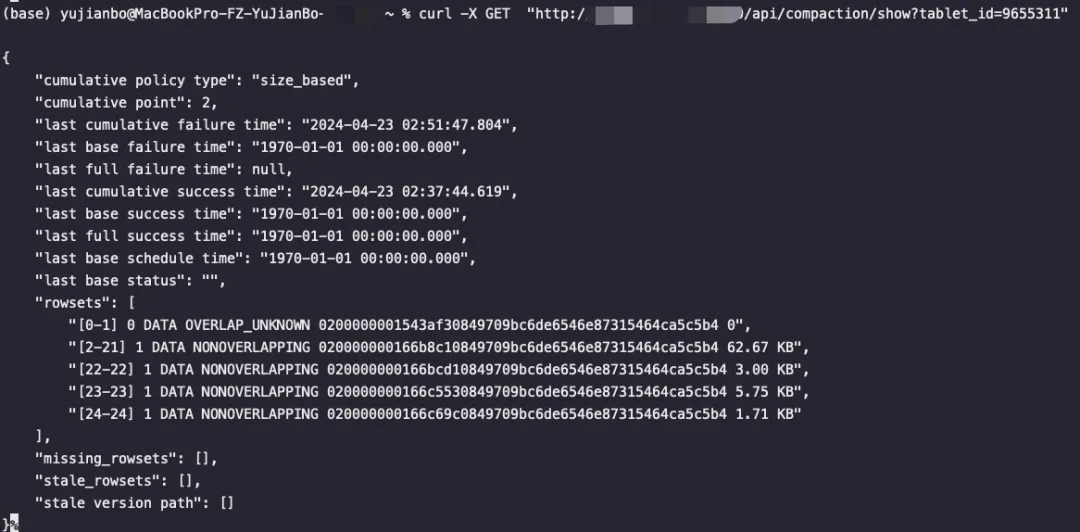
- 以9025274这个Tablet为例,讲解Compaction过程,下图可以看到数据正常写入,CP为106034,CP上面的rowset都是经过CC后变成大块头晋升到BC区域等待BC。CP下面就是等待CC的rowset:
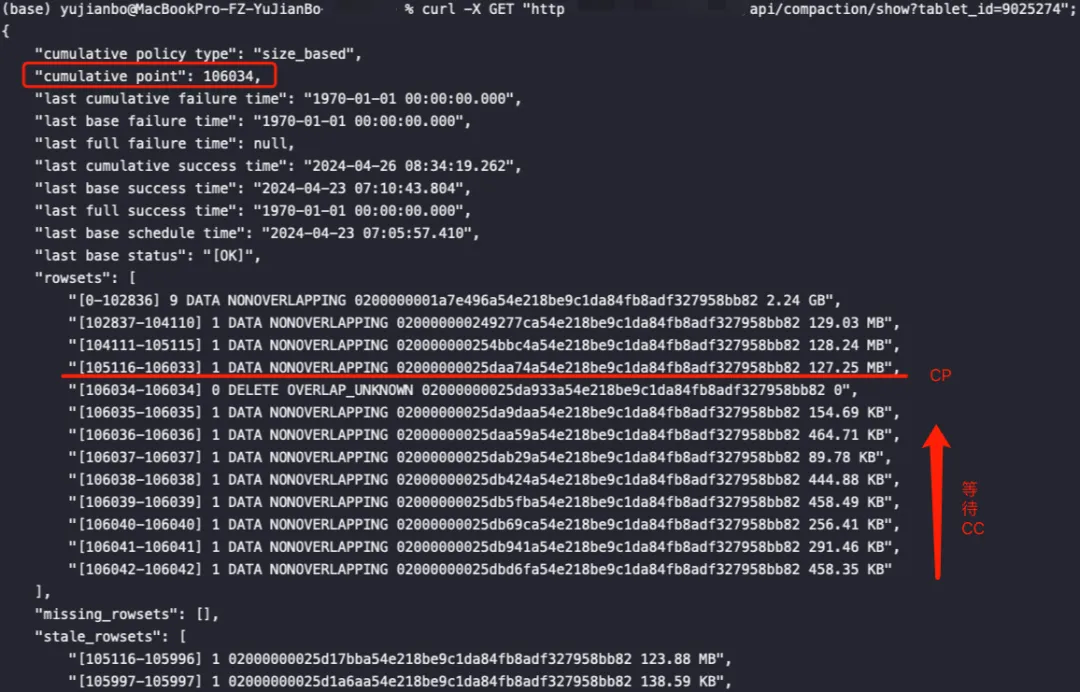
- 当CP遇到类型为DELETE类型的rowset就不会进行CC,而是会等待BC。delete版本为[106034, 106034]就不进行CC,后续的高版本的rowset进行CC合并成2.75MB大小的rowset[106035, 106046]。后续又来一个delete版本rowset[106049, 106049]:
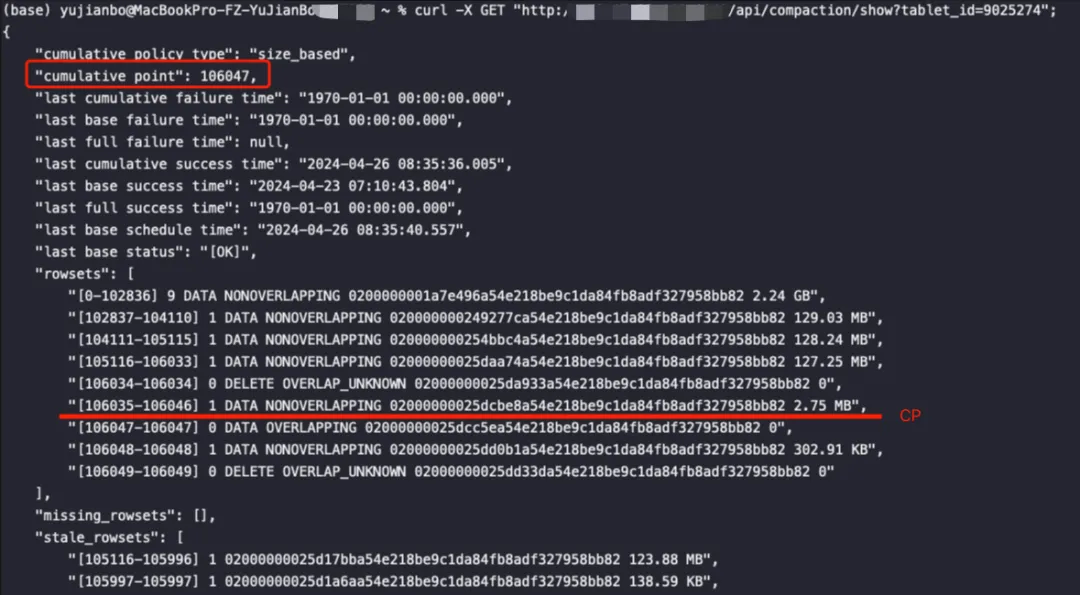
- 从下图可知,上图这些版本为[0-1062836]、[1062837-104110]、[104111-105115]、[105116-106033]、[106034-106034]、[106035-106046]的rowsets经过一次BC得到版本为[0-106046]的rowset,其中delete版本为[106034, 106034]验证上面说的,只有BC的时候才会进行compaction:
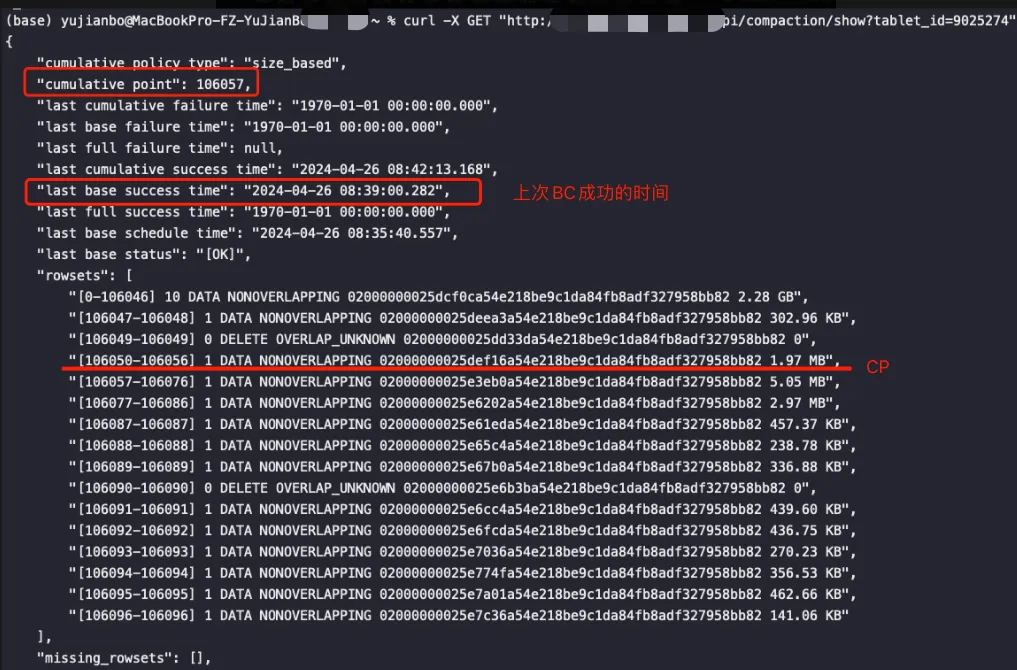
- 从下面这张图更明显,delete版本为[106049, 106049]、[106090, 106090]的rowset不进行CC,等待BC:
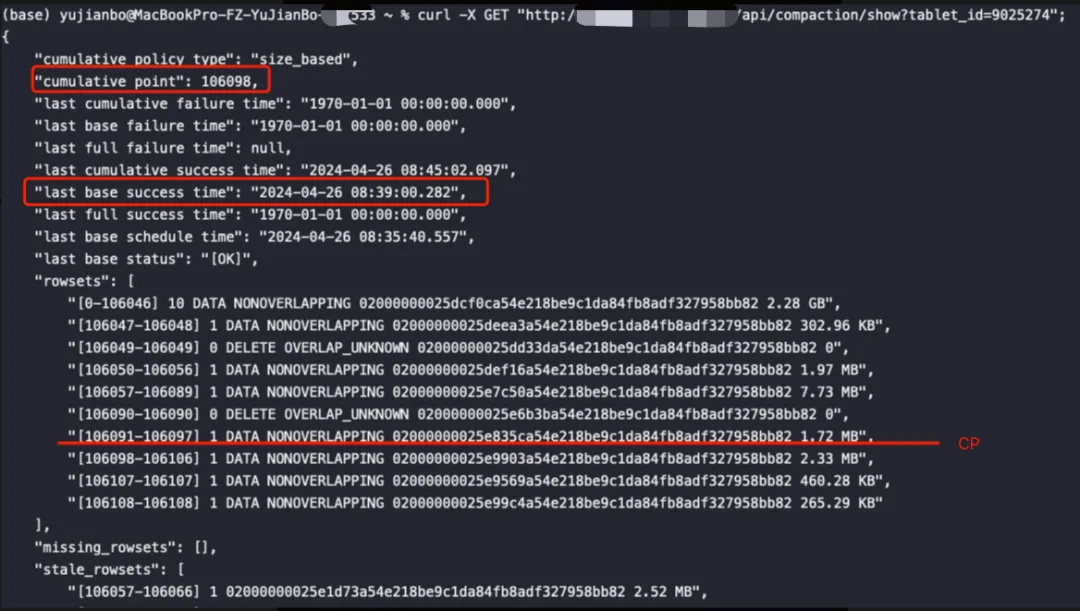
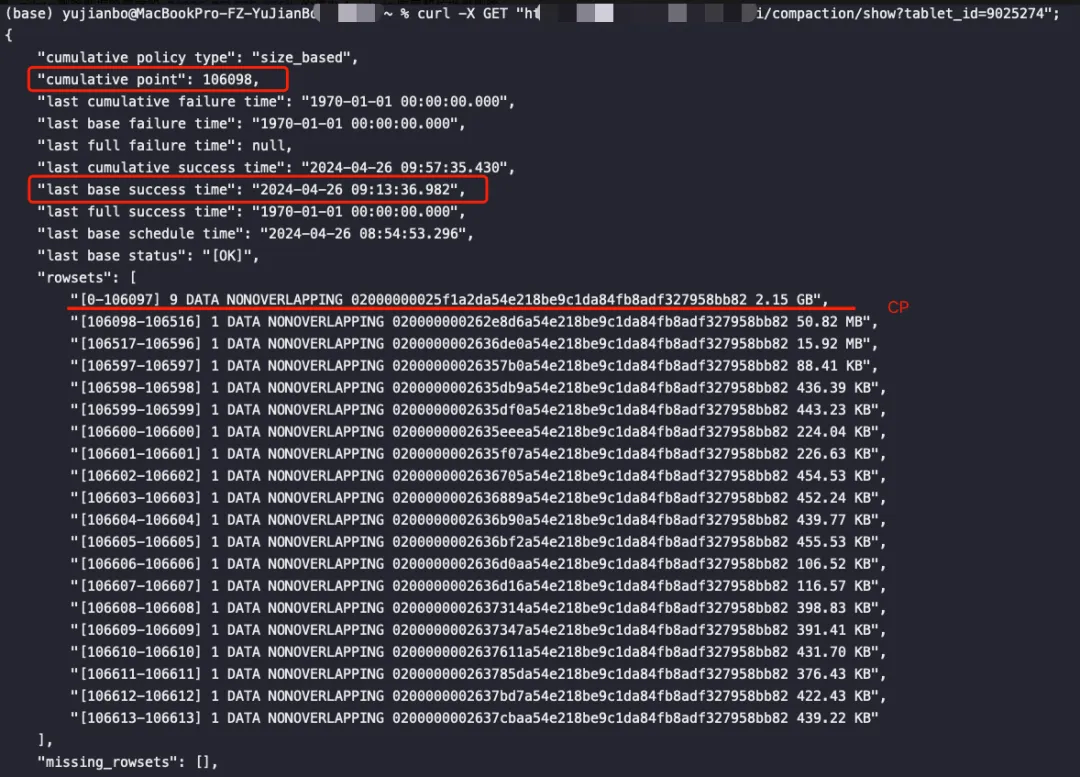
- 下图可知,上图在09:13分的时候经过一次BC,两个delete版本的rowset都在其中。CP以下的rowset正常进行CC,没有delete版本的rowset进行阻塞,达到一定阈值触发BC,减少BC对集群资源的占用,也是比较合理的Compaction状态:
- 生产查看Compaction的状态
① 查看数据版本数量变化趋势
可以看到下图12点到14点期间在测试大数据量数据写入测试,各个BE节点的BE Compaction Score统计值很高,简单来说就是特定的tablet中有很多的rowsets正在等待Compaction:
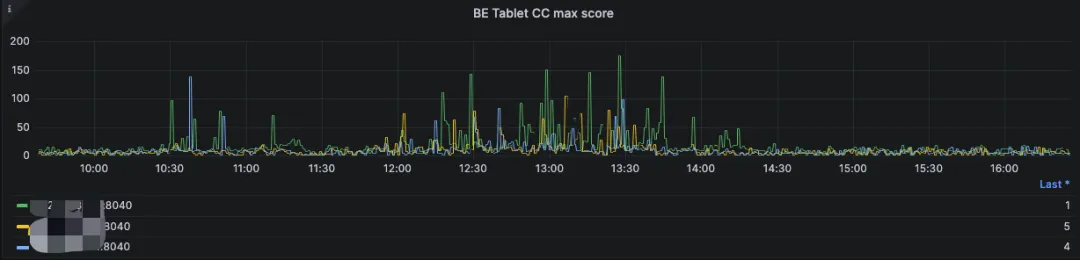
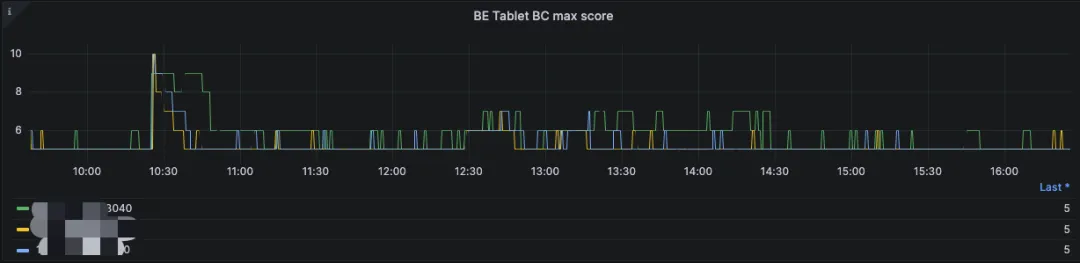
doris_be_tablet_base_max_compaction_score、doris_be_tablet_cumulative_max_compaction_score 代表的是集群中所有 Backend (BE) 节点上观察到的某个特定 tablet 的最大CC、BC compaction 分数。这个指标用于监控现有 tablet 中的最高 的CC、BC compaction 需求,通常反映出数据存储层面可能存在的问题或对优化操作的需求。如果这个分数过高,可能意味着相应的 tablet 需要优先进行 compaction,以改善查询性能和数据存储的效率。
② 查看Compaction效率


③ 查看Compaction资源占用
Compaction 资源占用主要是 IO 和 内存:
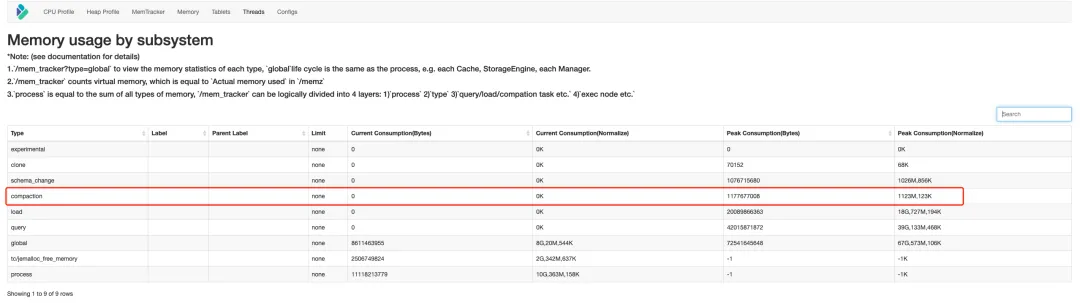
- Compaction 内存
http://be_host:http_port/mem_tracker
通过上面的链接可以查看当前Compaction的内存开销和历史峰值开销:
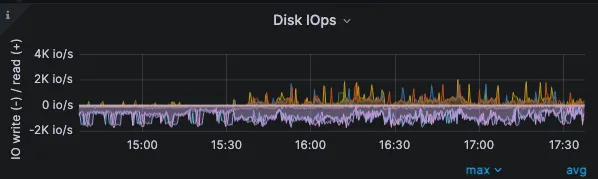
- Compaction IO
而对于 IO 操作,目前还没有提供单独的 Compaction 操作的 IO 监控,我们只能根据集群整体的 IO 利用率情况来做判断。通过自建的监控页面查看:
④ Compaction 调优策略
目前我们刚开始使用Doris,对Compaction的了解还不够深入,同时社区雨神建议没有遇到问题新版本不建议进行调整,遇到实际情况再具体分析。如果有遇到某些tablet有很多版本没有合并,集群的Compaction策略没有覆盖到,可以参考上面进行手动触发Compaction。
不过我也整理了一下关于be.conf的参数,提供参考:
-
磁盘相关
-
compaction_task_num_per_disk
- 每个磁盘(HDD)可以并发执行的compaction任务数量,默认4
-
compaction_task_num_per_fast_disk
- 每个高速磁盘(SSD)可以并发执行的compaction任务数量,默认8
-
-
compaction_threads 相关的bc cc参数
-
max_base_compaction_threads
- Base Compaction 线程池中线程数量的最大值。默认为 4
-
max_cumu_compaction_threads
- Cumulative Compaction 线程池中线程数量的最大值。默认为 10
-
max_single_replica_compaction_threads
- Single Replica Compaction 线程池中线程数量的最大值。默认为 10
-
-
其他
-
max_tablet_version_num
- tablet版本号,写入频率高的话可以调大
-
max_segment_num_per_rowset
- 用于限制导入时,新产生的rowset中的segment数量
-
⑤ 关于Compaction额外的建议
其实很多Compaction不合理除了突发的高频、巨量的写入会带来突然的Compaction异常,其实也有很多是来自于生产操作不规范带来的:
-
生产建表不规范案例
-
创建的bucket数量不合理,建议建表前进行评估,一个tablet大概1-10G原则
-
建表时使用了自动分区,导致tablet小文件过多
-
建表时启用了动态分区、创建历史分区,导致创建出一堆无用的历史分区,这些分区创建非常多的tablet小文件,也会引发集群后续的问题
-
-
生产删除数据规范
-
Unique模型/Aggregate模型
-【建议】建分区表,由dba drop分区老化数据
- 【万不得已】提供删除脚本,由dba定时删除
-
Duplicate
-
【建议】提供删除脚本,由dba定时批量update删除数据隐藏字段DORIS_DELETE_SIGN的值为1,doris底层帮忙批量删除(如果想看隐藏字段或者delete完还未真正清除的数据,可以通过设置SET show_hidden_columns=true;查看)
-
【万不得已】cdc的方式,替换delete操作,用update删除数据隐藏字段DORIS_DELETE_SIGN的值为1,doris底层帮忙批量删除
-
-
- 参考文档
https://blog.csdn.net/ucanuup_/article/details/114976379
https://blog.csdn.net/huzechen/article/details/114313481?utm_source=miniapp_weixin
https://zhuanlan.zhihu.com/p/653821192
https://mp.weixin.qq.com/s?__biz=Mzg5MDEyODc1OA==&mid=2247485585&idx=1&sn=0386d66451d36d6298b0c3aafed832d5&chksm=cfe01888f897919ecffc717e7f15cab18ede2df87339b03fc88d3d3abe219db96e0664a54457&scene=21#wechat_redirect
https://mp.weixin.qq.com/s/a2HeKSY2worSn9trt270nA
https://mp.weixin.qq.com/s/cZmXEsNPeRMLHp379kc2aA
https://mp.weixin.qq.com/s?__biz=Mzg5MDEyODc1OA==&mid=2247485136&idx=1&sn=a10850a61f2cb6af42484ba8250566b5&chksm=cfe016c9f8979fdf100776d9103a7960a524e5f16b9ddc6220c0f2efa84661aaa95a9958acff&scene=21#wechat_redirect
https://mp.weixin.qq.com/s?__biz=Mzg3Njc2NDAwOA==&mid=2247514956&idx=1&sn=c3671bd603d80239b52a108942cccda6&chksm=cf2fb54bf8583c5da2158bcbe85b1818d5a050ad7af4db18fd614ccf41aa06fb2fd2ebbdbdb5&token=1182037412&lang=zh_CN#rd
https://doris.apache.org/zh-CN/docs/2.0/admin-manual/maint-monitor/be-olap-error-code
本文由mdnice多平台发布