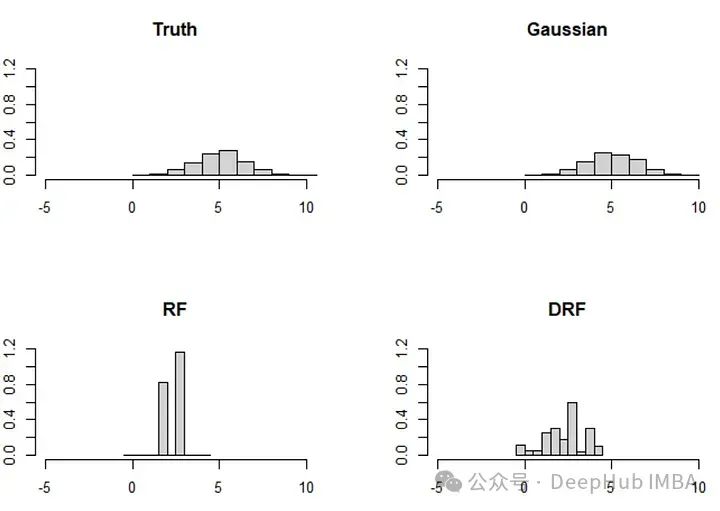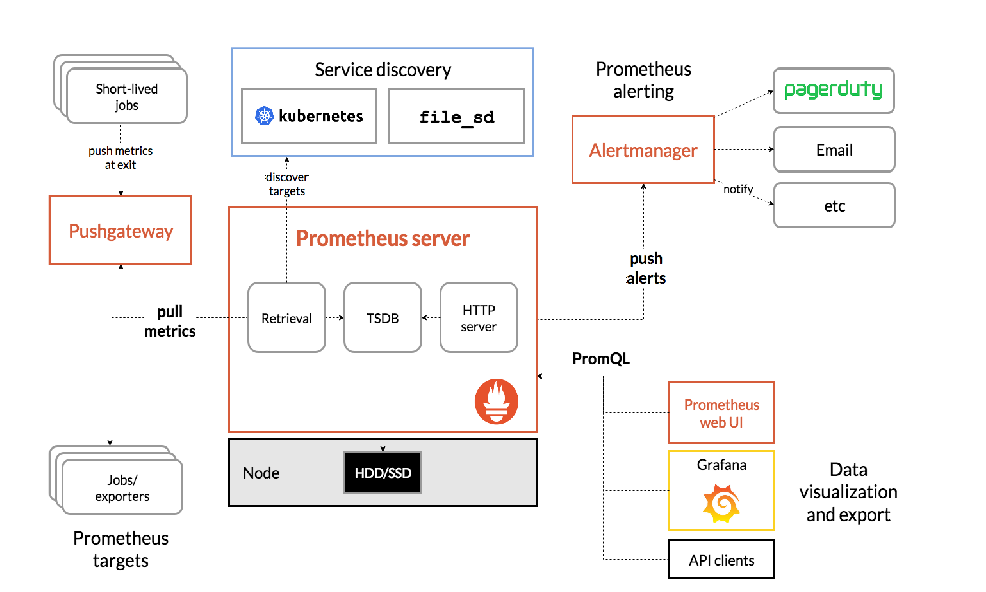
1. Prometheus Server(Prometheus服务器)
技术原理:
- Retrieval(检索模块):定期从配置的Targets(目标)拉取监控数据。使用HTTP协议,通过拉取的方式收集数据。
- TSDB(时间序列数据库):存储时间序列数据,每个数据点包含一个时间戳和一组标签(用于唯一标识数据点)。
- HTTP Server(HTTP服务器):提供PromQL查询接口,通过HTTP API供外部查询。
应用场景:
适用于需要持续监控和分析大量时间序列数据的场景,如服务器资源使用情况监控、应用性能监控等。
举例:
在一个微服务架构的应用中,每个服务的CPU、内存使用情况需要被监控。配置Prometheus从这些服务的exporter拉取数据,并存储在TSDB中。通过PromQL查询,可以实时查看每个服务的资源使用情况。
2. Service Discovery(服务发现)
技术原理:
- kubernetes:在Kubernetes环境中,Prometheus通过Kubernetes API动态发现需要监控的Pod和Service。
- file_sd:通过静态配置文件定义需要监控的目标。配置文件会被定期读取,更新监控目标。
应用场景:
适用于动态和静态环境下的服务发现。在Kubernetes环境中,可以自动发现新部署的Pod。在传统环境中,通过配置文件手动定义监控目标。
举例:
在一个Kubernetes集群中,Prometheus自动发现所有标记为“监控”的Pod,并开始拉取它们的监控数据。对于一些独立的数据库服务器,可以通过file_sd配置静态文件来定义它们为监控目标。
3. Targets(监控目标)
技术原理:
- Jobs/exporters:通常是应用程序或系统的导出器(Exporter),通过HTTP接口暴露监控指标。
- Short-lived jobs:短时任务或批处理任务,在完成时将监控数据推送到Pushgateway。
应用场景:
适用于需要监控各种系统和应用的场景。Exporter可以是数据库、消息队列、操作系统等各种系统组件。
举例:
使用Node Exporter来监控物理服务器的硬件资源(CPU、内存、磁盘等)。每个服务器运行Node Exporter,Prometheus定期拉取这些数据。
4. Pushgateway(推送网关)
技术原理:
- 用于接收和存储短时任务推送的监控数据。短时任务在完成时将数据推送到Pushgateway,Prometheus再从Pushgateway拉取这些数据。
应用场景:
适用于短时任务或批处理任务,这些任务的生命周期短,无法被Prometheus直接拉取数据。
举例:
定期运行的备份任务在完成时将执行时间和状态信息推送到Pushgateway。Prometheus定期从Pushgateway拉取这些数据,用于监控备份任务的执行情况。
5. Alertmanager(告警管理器)
技术原理:
- 接收Prometheus推送的告警信息。根据配置的告警规则,处理告警并发送通知。
应用场景:
适用于需要及时告警和通知的场景,如系统故障告警、性能异常告警等。
举例:
当服务器CPU使用率超过90%时,Prometheus生成告警并推送到Alertmanager。Alertmanager根据配置发送邮件通知运维团队。
6. Data Visualization and Export(数据可视化和导出)
技术原理:
- Prometheus web UI:提供基本的Web界面,用于数据查询和可视化。
- Grafana:与Prometheus集成,通过仪表板展示数据。
- API clients(API客户端):通过Prometheus提供的HTTP API访问和查询数据。
应用场景:
适用于需要直观展示和分析监控数据的场景,如运维监控大屏、性能分析报告等。
举例:
使用Grafana创建一个仪表板,展示多个服务的实时资源使用情况和性能指标。运维团队可以通过Grafana实时监控整个系统的健康状态。
Prometheus通过其组件的协同工作,实现了强大的监控、告警和数据可视化功能。各组件相互配合,适应不同的应用场景,提供了灵活和高效的监控解决方案。