Java面试题
1. JVM & JDK & JRE
Java虚拟机(JVM)是运行Java字节码的虚拟机,JVM有针对不同系统的特定实现,目的是使用相同的字节码,他们都会给出相同的结果。字节码和不同系统的JVM实现是Java语言“一次编译、随处可以运行”的关键。
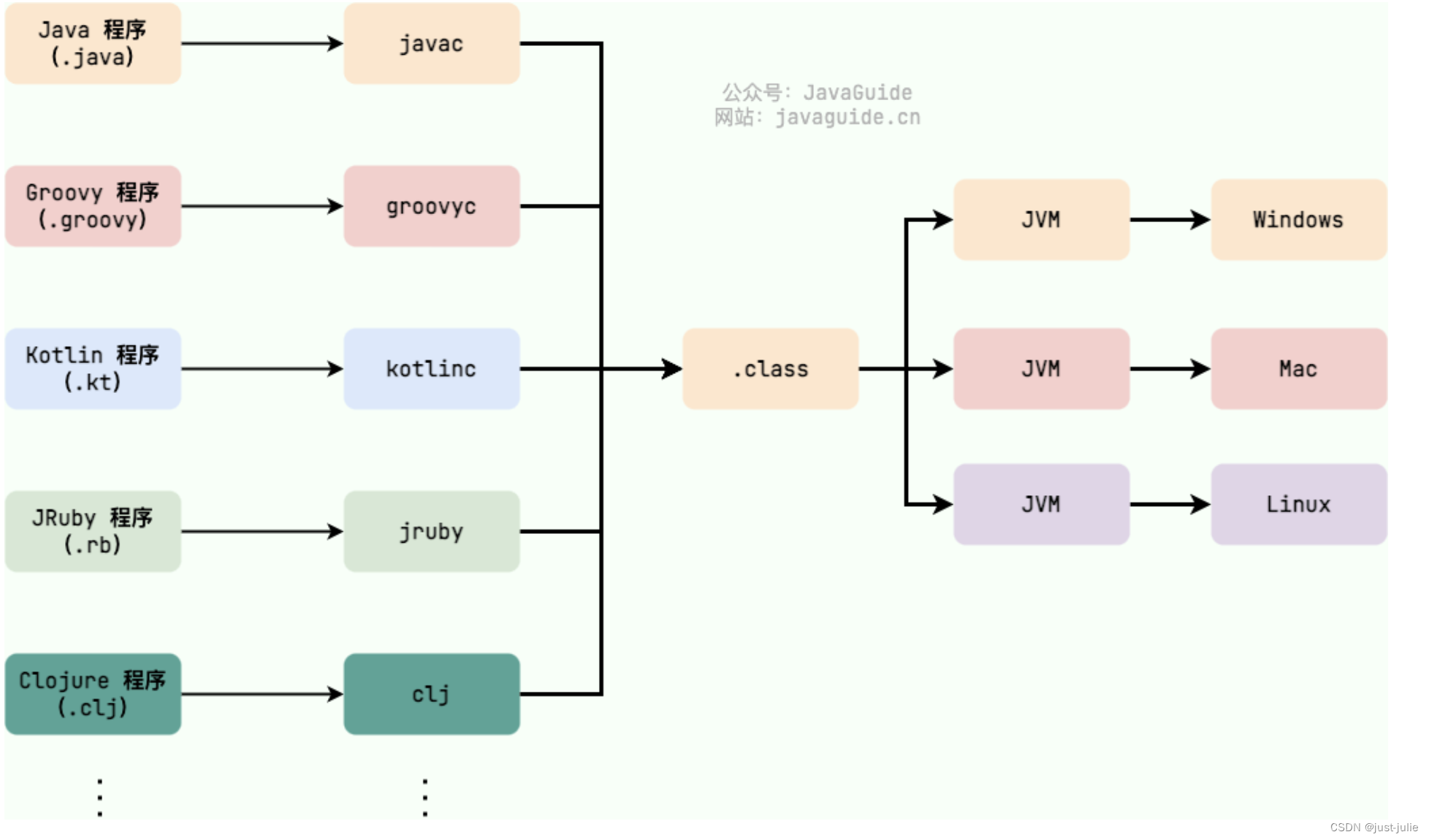
JDK和JRE
JDK是功能齐全的Java SDK,提供给开发者使用,能够创建和编译Java程序的开发套件。包含了JRE,同时还包含了编译java源码的编译器javac、调试器jdb、等一系列工具。
JRE是Java运行时环境,他是运行已编译Java程序所需的所有内容的集合,主要包括Java虚拟机(JVM)、Java基础类库(Class Library)。
JRE是Java运行时环境,仅包含Java应用程序运行时环境和必要的类库。JDK包含JRE。
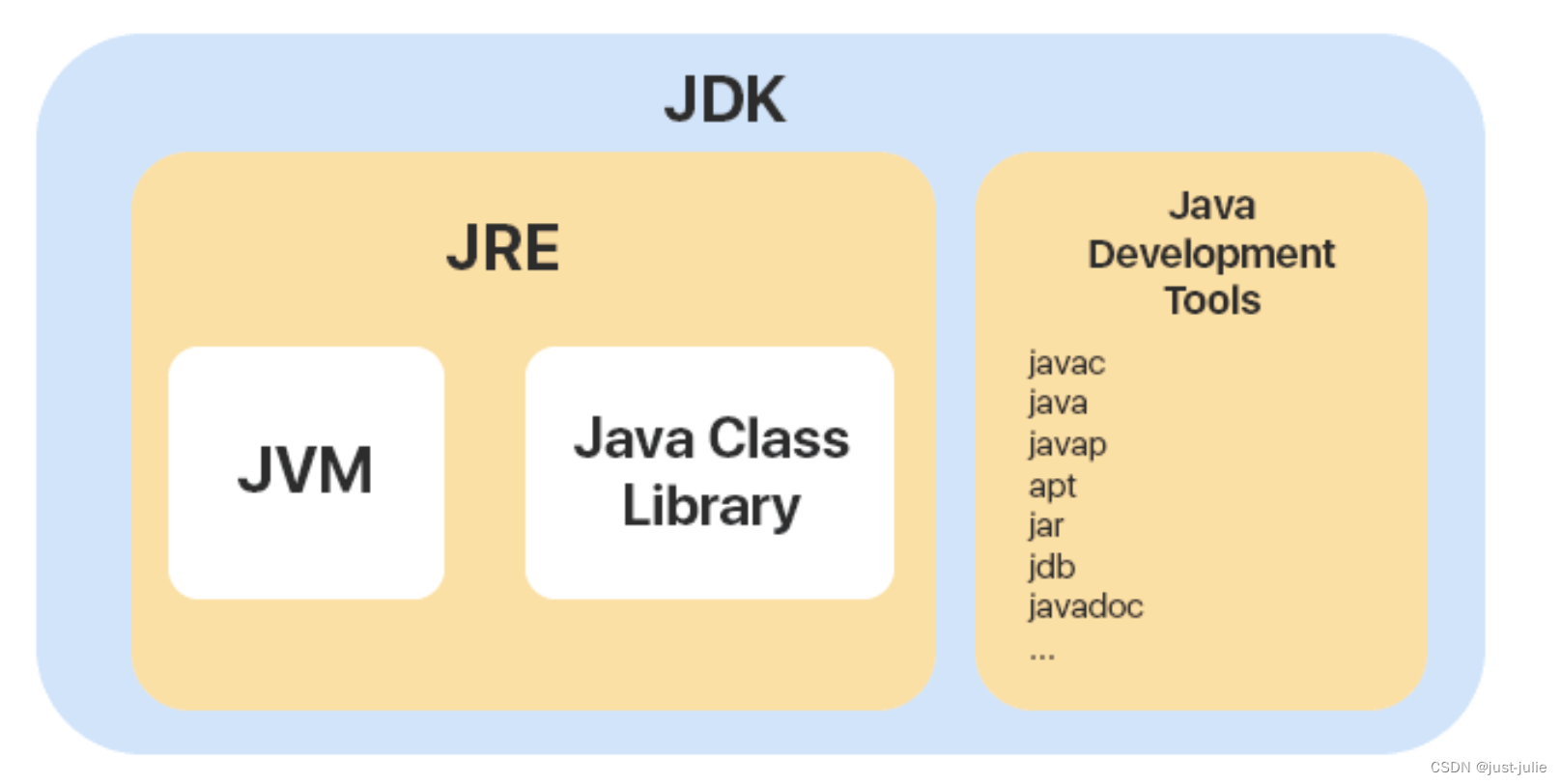
2. 什么是字节码?采用字节码有什么好处?
字节码就是(.class文件),他不面向任何特定的处理器,只面向虚拟机。Java语言通过字节码的形式,在一定程度上解决了传统解释型语言执行效率低的问题。同时保留了解释型语言可移植特性。所以,Java程序运行时相对高效(但是和C、C++、Go相比仍有差距)。而且,由于字节码并不针对一种特定的机器,因此Java程序无需重新编译便可在多种 不同操作系统上运行。
3. JIT(just-in-time compliation)编译器
Java程序从源代码到运行的过程
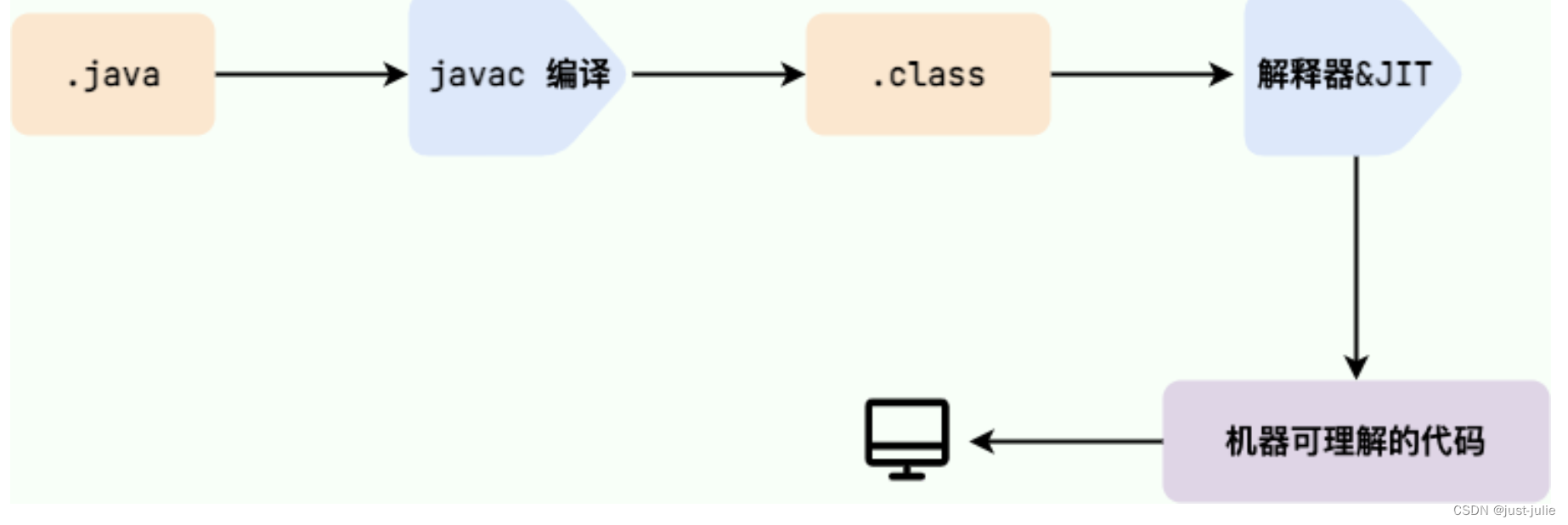
在 .class->机器码这一步。JVM类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会比较慢,而且,有些方法和代码块是经常需要被调用的(即热点代码),所以引进了JIT编译器,JIT属于运行时编译,当JIT编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。 机器码的运行效率肯定是高于Java编译器的,因此Java是编译与解释共存的语言。
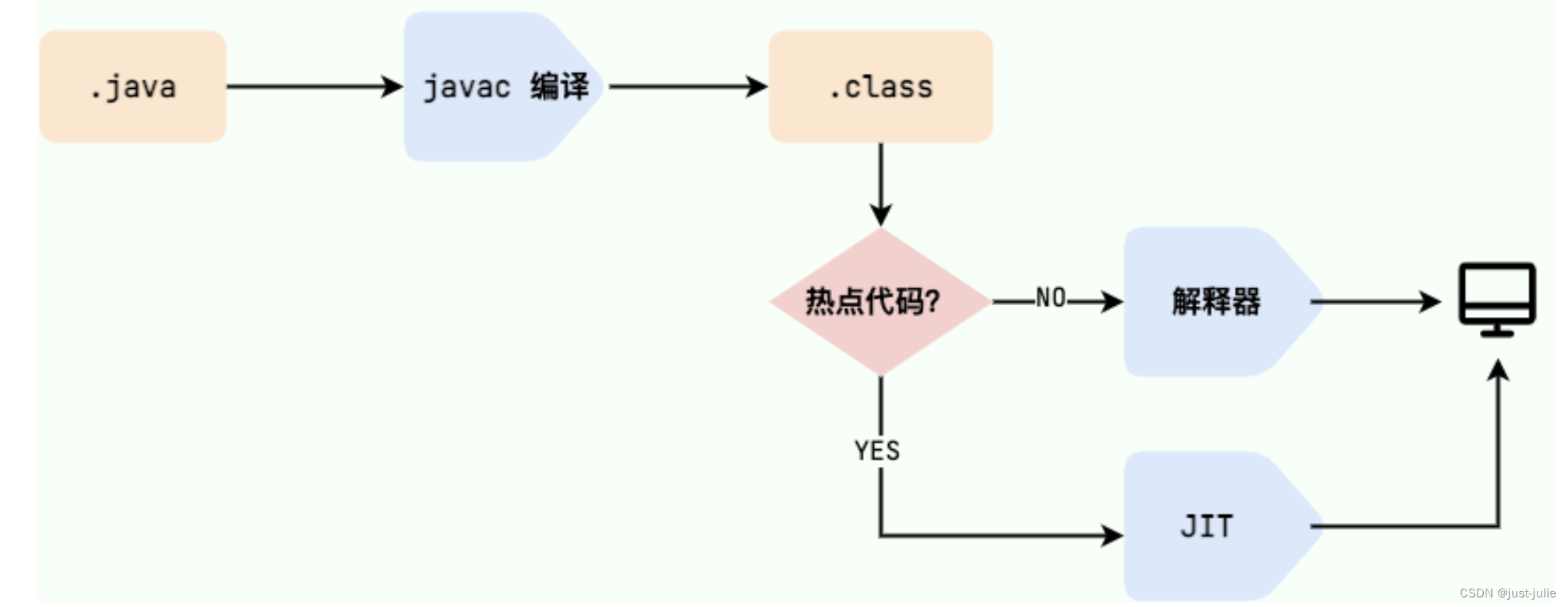
HotSpot采用了惰性评估的做饭,根据二八定律,消耗大部分系统资源的只有一小部分代码(热点代码),而这正是JIT所需要编译的部分 。
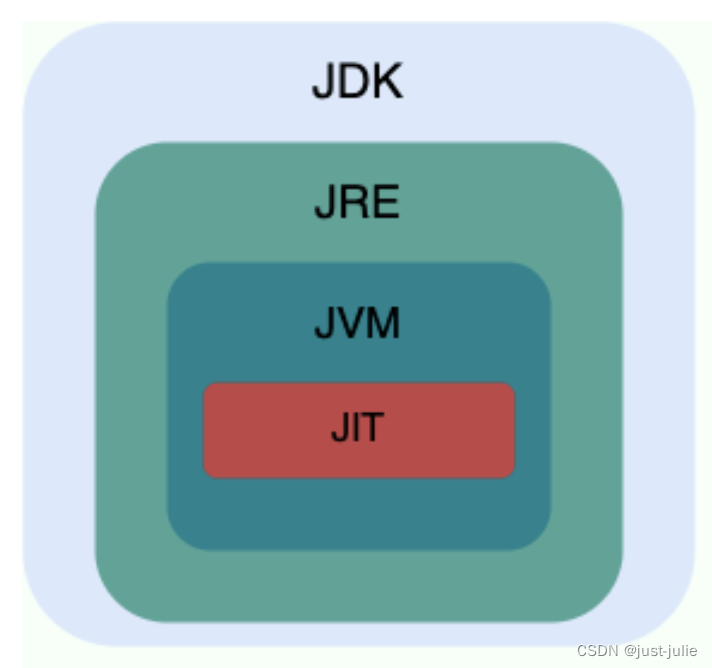
4. JDK、JRE、JVM、JIT的关系
5. Java位运算符
Java提供了一系列位运算符,这些运算符主要用于操作整数类型(int、long、short、byte),使用位运算符转换成的指令码运行起来更加高效。
- << : 左移运算符,高位丢弃,低位补零。x<<1 相当于x*2(不溢出的情况下)。
int value = 0b0001; // 1
int result = value << 2; // 左移2位,结果为 0b0100,即4
- .>>:带符号右移,向右移动若干位,高位补符号位,低位丢弃。正数高位补0,负数高位补1.x>>1 相当于 x/2
int value = 0b0100; // 4
int result = value >> 2; // 结果为 0b0001,即1
- .>>>:无符号右移,将位向右移动指定位数,左边空出的位用0填充,无论正负。
int value = -1; // 所有位为1
int result = value >>> 1; // 结果为将最高位的1转换为0,其余位保持1
- & :按位与:对两个位进行运算,只有在两个相应位都是1时,结果位1.
int flags = 0b11010; // 二进制表示 0b表示二进制数
int mask = 0b11000; // 要保留的位
int result = flags & mask; // 结果为 0b11000
- ^ : 按位异或 :对两个位进行运算,如果两个相应位一个位1一个为0,则结果为1.
int flags = 0b11010;
int toggle = 0b10101;
int result = flags ^ toggle; // 结果为 0b01111
- |:按位或:对两个位进行运算,如果两个位至少有一个为1,则结果位1.
int flags = 0b11010;
int mask = 0b00101;
int result = flags | mask; // 结果为 0b11111
- ~:按位取反:对位进行单操作,将1变成0,将0变成1.
int flags = 0b11010;
int result = ~flags; // 结果为二进制的反码 0b00101
6. 如果移位的位数超过数值所占有的位数会怎么样
当 int 类型 左移/右移 大于等于32位时,会先求余(%)后在进行相应操作。也就是说 左移/右移32位相当于不进行移位操作(32%32=0), 左移/右移 42位相当于 左移/右移10位。当long类型进行 左移/右移操作时,由于long对应的二进制是64位,因此求余操作的基数也变成了64.
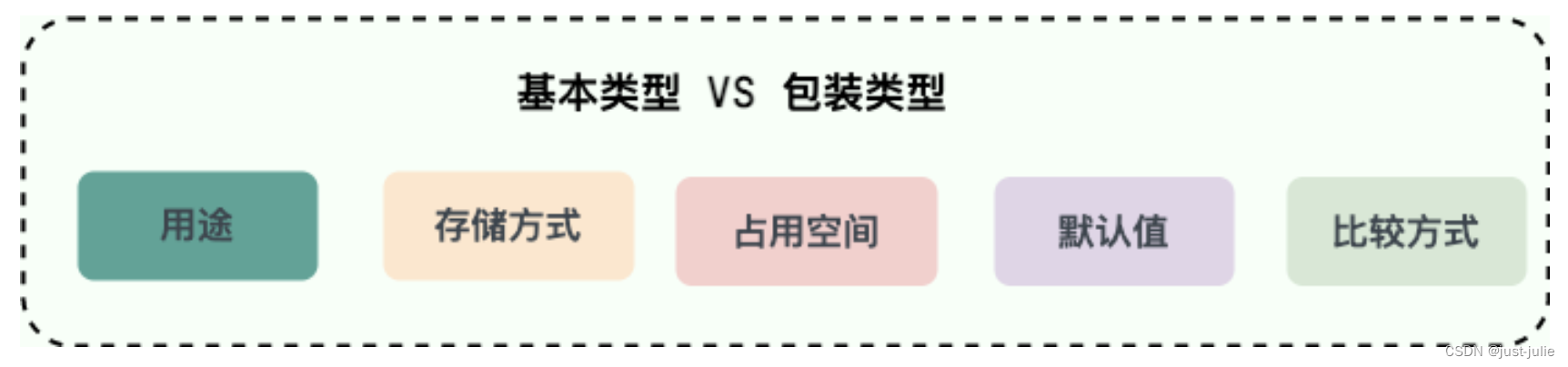
7. 基本类型和包装类型的区别
-
用途:除了定义一些常量和局部变量之外,我们在其他地方比如方法参数、对象属性中很少会使用基本类型来定义变量。并且,包装类型可用于泛型,而基本类型不可以。
-
存储方式:基本数据类型的局部变量存放在Java虚拟机栈中的局部变量表,基本数据类型的成员变量(未被static修饰)存放在Java虚拟机的堆中。包装类型属于对象类型,我们知道几乎所有对象实例都存在于堆中。
-
占用空间: 相比于包装类型,基本数据类型占用的空间往往非常小。
-
默认值:成员变量包装类型不赋值就是null,而基本类型有默认值且不是null。
-
比较方式:基本数据类型采用 == 比较的是值,对于包装类型 == 比较的是内存地址。所有整型包装类对象之间值的比较,全部使用equals()方法。
!注意:基本数据类型存放在栈中是一个常见的误区!基本数据类型的存储位置取决于他们的作用域和声明方式,如果他们是局部变量,那么他们会存放在栈中,如果他们是成员变量,那么他们会存放在堆中。
public class Test {
// 成员变量,存放在堆中
int a = 10;
// 被 static 修饰,也存放在堆中,但属于类,不属于对象
// JDK1.7 静态变量从永久代移动了 Java 堆中
static int b = 20;
public void method() {
// 局部变量,存放在栈中
int c = 30;
static int d = 40; // 编译错误,不能在方法中使用 static 修饰局部变量
}
}
8. 包装类型的缓存机制
Java基本数据类型的包装类型大部分都利用到了缓存机制来提升性能。
Byte、Short、Integer、Long这4种包装类型默认创建了数值 [-128,127]的相应类型的缓存数据,Character创建了数值在[0,127]范围的缓存数据,Boolean直接返回True or False。
Integer 缓存源码:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static {
// high value may be configured by property
int h = 127;
}
}
Character缓存源码
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character(c);
}
private static class CharacterCache {
private CharacterCache(){}
static final Character cache[] = new Character[127 + 1];
static {
for (int i = 0; i < cache.length; i++)
cache[i] = new Character((char)i);
}
}
Boolean 缓存源码
public static Boolean valueOf(boolean b) {
return (b ? TRUE : FALSE);
}
例:
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2); //输出结果为false
Integer i1 = 40;这一行代码会发生装箱,等价于Integer.valueOf(40), 因此 i1直接使用的是缓存中的对象,而Integer i2 = new Integer(40);会直接创建对象,因此两者地址比较为false。
强制:所有整型包装类对象之间值的比较,全部使用equals方法比较。
说明:对于Integer var = ? 在-128至127之间的赋值,Integer对象是在IntegerCache.cache产生,会复用已有对象,这个区间内的Integer值可以使用 == 进行判断,但是这个区间之外的所有数据,都会在堆上产生,并不会复用已有对象,因此,推荐所有的整形包装类对象都使用equals方法进行判断。
9. 自动装箱和拆箱的原理
什么是自动装箱拆箱
- 装箱:将基本类型用他们对应的引用类型包装起来。
- 拆箱:将包装类型转换为基本数据类型。
举例
Integer i = 10; //装箱
int n = i; //拆箱
原理
- Integer i = 10; 等价于 Integer i = Integer.valueOf(10)
- int n = i; 等价于 int n = i.intValue();
注意:如果频繁拆装箱的话,也会严重影响系统性能。我们应该尽量避免不必要的拆装箱操作。
private static long sum() {
// 应该使用 long 而不是 Long
Long sum = 0L;
for (long i = 0; i <= Integer.MAX_VALUE; i++)
sum += i;
return sum;
}
这里 sum是引用类型,i是基本类型,每次执行sum+i会将sum转换为基本类型进行操作,操作完成后在将sum转换为引用类型,因此需要将sum修改为long类型
10. 为什么浮点数运算的时候有精度丢失的风险
浮点数精度丢失演示:
float a = 2.0f - 1.9f;
float b = 1.8f - 1.7f;
System.out.println(a);// 0.100000024
System.out.println(b);// 0.099999905
System.out.println(a == b);// false
问题的原因和计算机保存浮点数的机制有很大关系,计算机是二进制的,而且计算机在表示一个数字时,宽度是有限的,无限循环的小数存储在计算机中,只能被截断,所以会导致小数精度损失的情况。
11. 如何解决浮点数运算精度丢失问题
BigDecimal可以实现对浮点数的运算,不会造成精度丢失。
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
BigDecimal c = new BigDecimal("0.8");
BigDecimal x = a.subtract(b);
BigDecimal y = b.subtract(c);
System.out.println(x.compareTo(y));// 0
强制:禁止使用构造方法BigDecimal(double) 的方式把double值转化为BigDecimal对象。
说明:BigDecimal(double) 存在精度丢失风险,在精确计算或者值比较的场景中可能会导致业务逻辑异常。正例 new BigDecimal(“0.1”)
12. 超过long整形的数据应该如何表示
BigInteger内部使用 int[] 数组来存储任意大小的整型数据。
13. 成员变量和局部变量有什么区别

- 语法形式:成员变量是属于类的,局部变量是属于方法的。成员变量可以被private、static等修饰,局部变量不可以。
- 存储方式:从变量在内存中的存储方式看,如果成员变量被static修饰,那么这个成员变量属于类。如果没有,那么这个成员变量属于实例。成员变量存在于堆内存,而局部变量中的基本数据类型存储于栈内存。
- 生存时间:成员变量是对象的一部分,随着对象的创建而存在。而成员变量如果被static修饰更是随着类的存在而存在,而局部变量随着方法的调用产生,调用的结束消亡。
- 默认值:成员变量如果没有赋初值,则会自动以类型的默认值而赋值(除非final修饰的成员变量必须显示的赋值),而局部变量不会自动赋值。
14. 静态变量有什么作用
静态变量也就是被static修饰的变量,他可以被类的所有实例共享,无论一个类创建了多少个对象,他们都共享同一份静态变量。也就是说,静态变量只会分配一次内存,即使创建多个对象,这样可以节省内存。
15. 静态方法为什么不能调用非静态成员
- 静态方法是属于类的,在类加载的时候就会分配内存,可以通过类名直接访问。而非静态成员属于实例对象,只有在对象创建的时候才会存在,需要通过类的实例对象访问。
- 在类的非静态成员不存在的时候静态方法就已经存在了,此时调用在内存中不存在的静态成员,属于非法操作。
16. 静态方法和实例方法有何不同
- 调用方式:调用静态方法无需创建对象。
- 访问类成员是否存在限制:静态方法在访问类的成员变量时只能访问静态成员,不允许访问实例成员。而实例方法不存在
17. 重载和重写的区别
- 重载是同一个方法根据输入参数的不同,做出不同的处理。
- 重写是子类继承父类,重写父类的方法。