英伟达刚刚再次证明了其在AI创新领域的领导地位。
它全新发布的Nemotron-4 340B,是一系列具有开创意义的开源模型,有望彻底改变训练LLM的合成数据生成方式!
这一突破性进展标志着AI行业的一个重要里程碑——
各行各业无需依赖昂贵的真实世界数据集,用合成数据即可创建性能强大的特定领域大语言模型!
论文地址:https://d1qx31qr3h6wln.cloudfront.net/publications/Nemotron_4_340B_8T_0.pdf
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952
Nemotron-4 340B已经取得了辉煌战绩,超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以与GPT-4一较高下!
具体来说,Nemotron-4 340B包括基础模型Base、指令模型Instruct和奖励模型Reward,并构建了一个高质量合成数据生成的完整流程。

模型支持4K上下文窗口、50多种自然语言和40多种编程语言,训练数据截止到2023年6月。
训练数据方面,英伟达采用了9万亿个token,其中8万亿用于预训练,1万亿用于继续训练以提高质量。

值得一提的是,指令模型的训练是在98%的合成数据上完成的。
结果显示,Nemotron-4-340B-Base在常识推理任务,如ARC-Challenge、MMLU和BigBench Hard基准测试中,可以媲美Llama-3 70B、Mixtral 8x22B和Qwen-2 72B模型。
而Nemotron-4-340B-Instruct在指令跟随和聊天能力方面也超越了相应的指令模型。
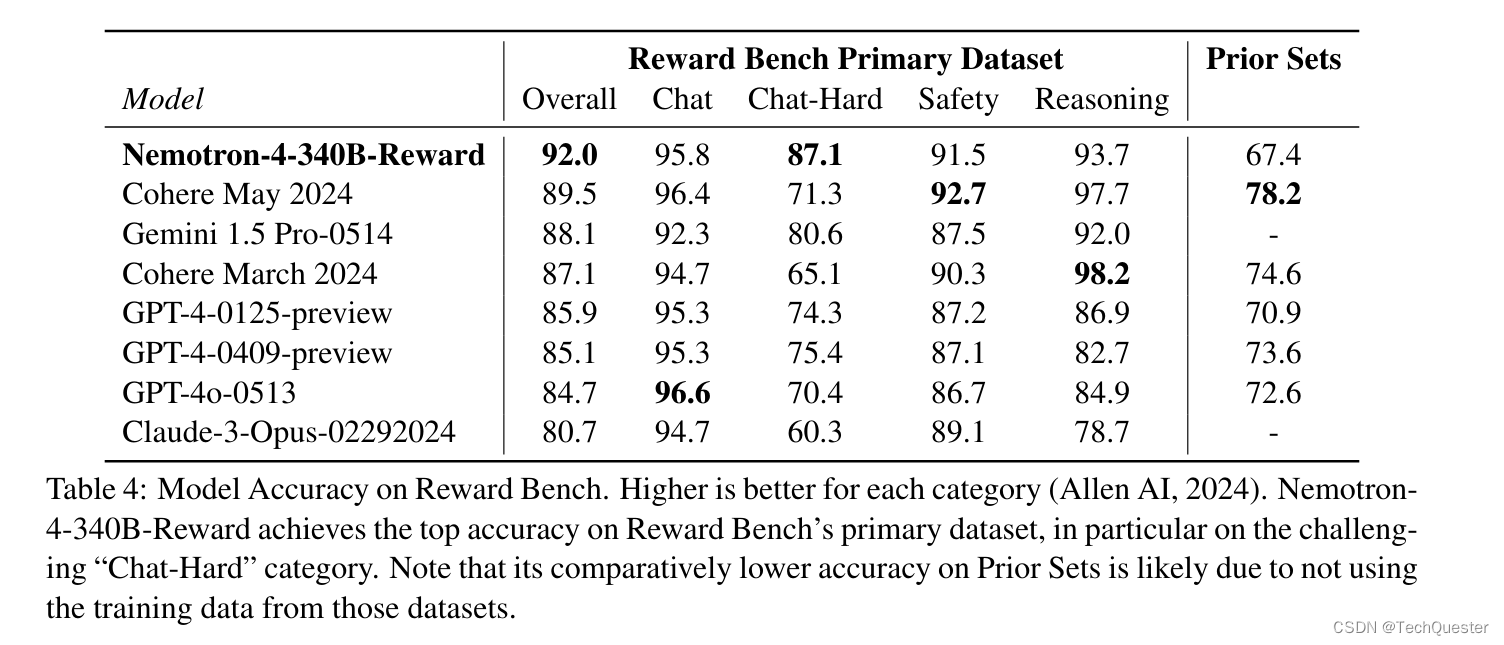
Nemotron-4-340B-Reward在发表时,在RewardBench上实现了最高准确性,甚至超过了GPT-4o-0513和Gemini 1.5 Pro-0514这样的专有模型。
01 无与伦比的合成数据生成
LLM无法获得大规模、多样化标注数据集,怎么办?

Nemotron-4 340B指令模型,可以帮助开发者生成合成训练数据。
这些多样化的合成数据模仿了真实世界的数据特征,从而显著提升数据质量,进而提高各领域定制LLM的性能和稳定性。
为了进一步提高AI生成数据的质量,开发者还可以使用Nemotron-4 340B奖励模型来筛选高质量的响应。
它会根据有用性、正确性、一致性、复杂性和冗长性这五个属性对响应评分。
此外,研究者可以使用自己的专用数据,再结合HelpSteer2数据集,定制Nemotron-4 340B基础模型,以创建自己的指令或奖励模型。

02 用NeMo微调,用TensorRT-LLM优化推理
利用开源的NVIDIA NeMo和NVIDIA TensorRT-LLM,开发者可以优化指令模型和奖励模型的效率,从而生成合成数据,并对响应进行评分。
所有Nemotron-4 340B模型都利用张量并行性经过TensorRT-LLM优化,这种模型并行性可以将单个权重矩阵分割到多个GPU和服务器上,从而实现大规模高效推理。
基础模型可以使用NeMo框架进行定制,以适应特定的用例或领域。广泛的预训练数据使得我们可以对其进行微调,并为特定的下游任务提供更准确的输出。
通过NeMo框架,英伟达提供了多种定制方法,包括监督微调和参数高效微调方法,如低秩适应(LoRA)。
为了提高模型质量,开发者可以使用NeMo Aligner和由Nemotron-4 340B奖励模型标注的数据集来对齐模型。
03 在各行业的潜在影响:从医疗到金融及其他领域
显然,Nemotron-4 340B对各行业的潜在影响是巨大的。

在医疗领域,生成高质量合成数据可能会带来药物发现、个性化医疗和医学影像方面的突破。
在金融领域,基于合成数据训练的定制大语言模型可能会彻底改变欺诈检测、风险评估和客户服务。
在制造业和零售业,特定领域的LLM可以实现预测性维护、供应链优化和个性化客户体验。
不过,Nemotron-4 340B的发布也提出了一些隐忧,比如数据隐私和安全如何保证?
随着合成数据的普及,企业是否有防护措施来保护敏感信息并防止滥用?
如果用合成数据训练AI模型,是否会引发伦理问题,比如数据中的偏见和不准确可能引发意料外的后果?
但至少在目前,越来越多迹象表明,合成数据是未来的趋势。
04 预训练
预训练数据基于三种不同类型的混合,共有9T token。其中,前8T用于正式预训练阶段,最后1T用于继续预训练阶段。
- 英语自然语言(70%):由不同来源和领域的精选文档组成,包括网页文档、新闻文章、科学论文、书籍等。
- 多语种自然语言(15%):包含53种自然语言,由单语语料库和平行语料库中的文档构成。
- 代码(15%):包含43种编程语言。

4.1 架构
与Nemotron-4-15B-Base类似,Nemotron-4-340B-Base基于仅解码器Transformer架构。
具体来说,模型使用因果注意力掩码来确保序列的一致性,并采用旋转位置嵌入(RoPE)、SentencePiece分词器、分组查询注意力(GQA),以及在MLP层中使用平方ReLU激活。
此外,模型没有偏置项,丢弃率为零,输入输出嵌入不绑定。
模型超参数如表1所示,有94亿个嵌入参数和3316亿个非嵌入参数。
4.2 训练
Nemotron-4-340B-Base使用768个DGX H100节点进行训练,每个节点包含8个基于NVIDIA Hopper架构的H100 80GB SXM5 GPU。
每个H100 GPU在进行16位浮点(BF16)运算时,峰值吞吐量为989 teraFLOP/s(不含稀疏运算)。
英伟达采用了8路张量并行、12路交错流水线并行和数据并行相结合的方法,并使用了分布式优化器,将优化器状态分片到数据并行副本上,以减少训练的内存占用。
表2总结了批大小增加的3个阶段,包括每次迭代时间,以及GPU利用率(MFU)等,其中100%是理论峰值。
4.3 评估
在这一部分,我们报告了Nemotron-4-340B-Base的评估结果。我们将该模型与Llama-3 70B、Mistral 8x22和Qwen-2 72B三款开源模型进行比较。
可以看到,Nemotron-4-340B-Base在常识推理任务以及像BBH这样的流行基准测试中拿下了SOTA,并在MMLU和HumanEval等代码基准测试中位列第二。
4.4 对齐
奖励模型构建
奖励模型在模型对齐中起着至关重要的作用,是训练强指令跟随模型时用于偏好排序和质量过滤的重要评判者。
为了开发一个强大的奖励模型,英伟达收集了一个包含10k人类偏好数据的数据集——HelpSteer2。
与成对排名模型不同,多属性回归奖励模型在区分真实有用性和无关伪影(如仅因长度而偏好较长但无用的回复)方面更有效。此外,回归模型在预测细粒度奖励、捕捉相似回复之间的有用性细微差别方面表现更好。
回归奖励模型建立在Nemotron-4-340B-Base模型之上,通过用一个新的奖励「头」替换模型的最终softmax层。
这个「头」是一个线性投影,将最后一层的隐藏状态映射到一个包含HelpSteer属性(有用性、正确性、一致性、复杂性、冗长性)的五维向量。
在推理过程中,这些属性值可以通过加权求和聚合为一个总体奖励。

在整个对齐过程中,英伟达仅使用了大约20K的人工标注数据,而数据生成管线则生成了用于监督微调和偏好微调的98%以上的数据。
生成合成提示是合成数据生成(SDG)的第一步。
这些提示在不同维度上的多样性至关重要,包括任务多样性(如写作、开放问答、封闭问答)、主题多样性(如STEM、人文、日常生活)和指令多样性(如JSON输出、段落数量、是或否回答)。
对此,英伟达使用Mixtral-8x7B-Instruct-v0.1作为生成器,分别对这些任务的合成提示进行了生成。
为了收集多样化的主题,英伟达先引导生成器输出一组多样化的宏观主题,然后再为每个合成的宏观主题生成相关的子主题。
加上人工收集的,最终得到的主题达到了3K个。
如何使用WildCard正确方式打开GPT-4o,目前 WildCard 支持的服务非常齐全,可以说是应有尽有!
官网有更详细介绍:WildCard

推荐阅读:
更强大Mamba-2正式发布啦!!!
黎曼猜想取得重大进展!!


![[RL9] Rocky Linux 9.4 搭载 PG 16.1](https://img-blog.csdnimg.cn/img_convert/03db51c62e1123f472d7c581090ceed7.png)