前言
上一篇文章简单的介绍了下MaxKB,这一篇文章就讲如何部署MaxKB。
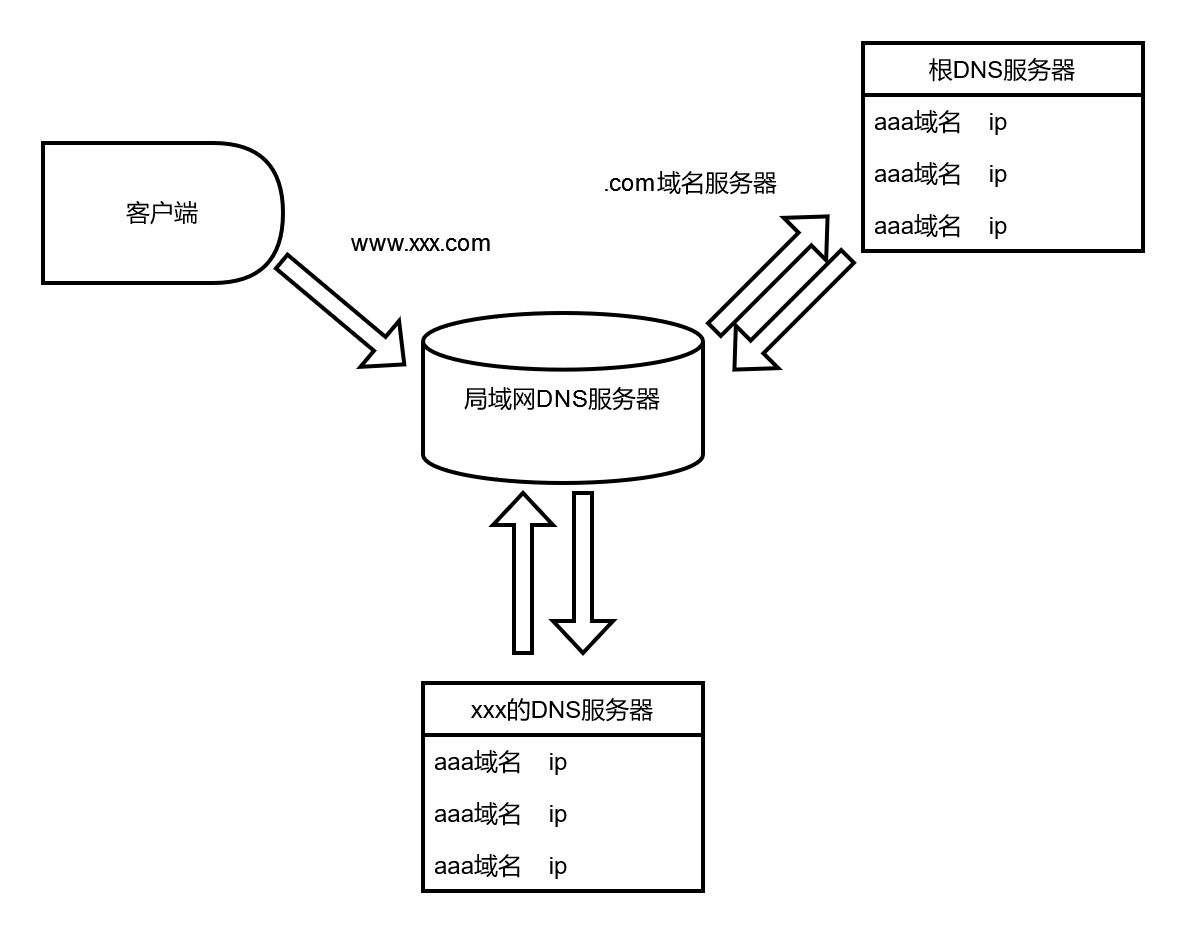
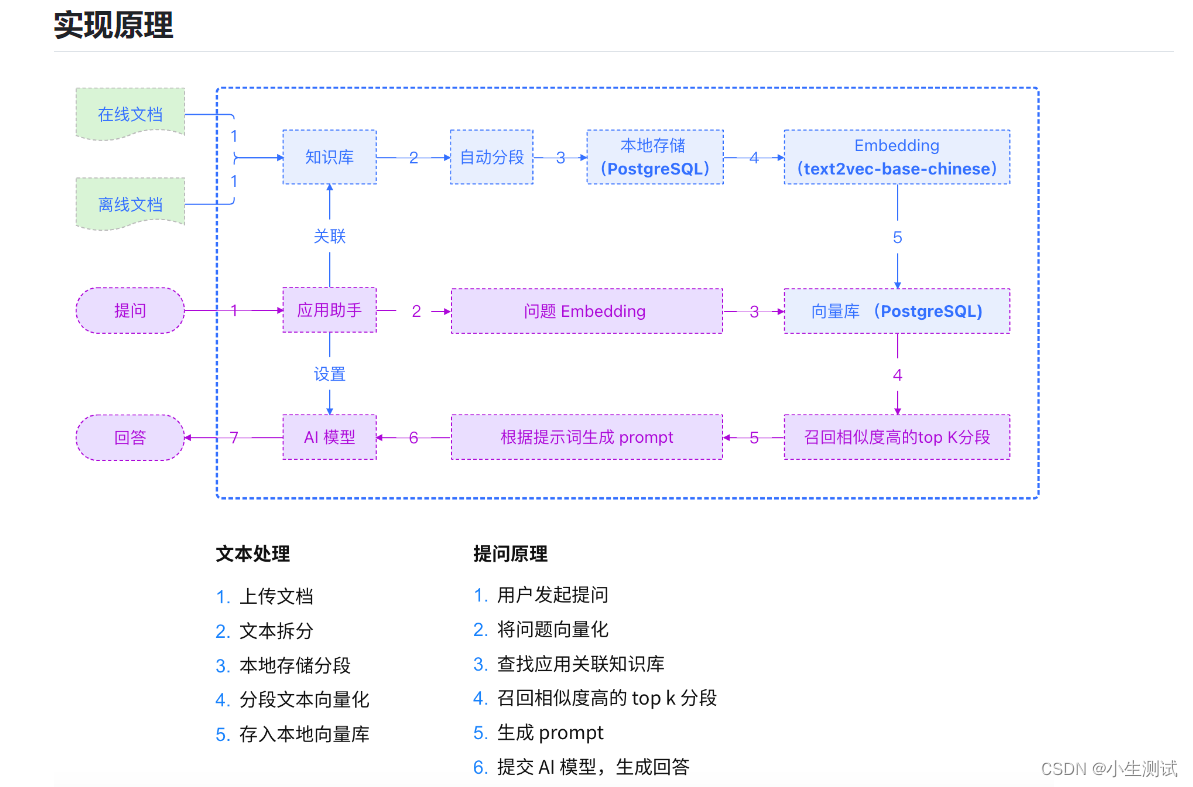
MaxKB实现逻辑也比较简单,如下图。
安装
修改Docker镜像源
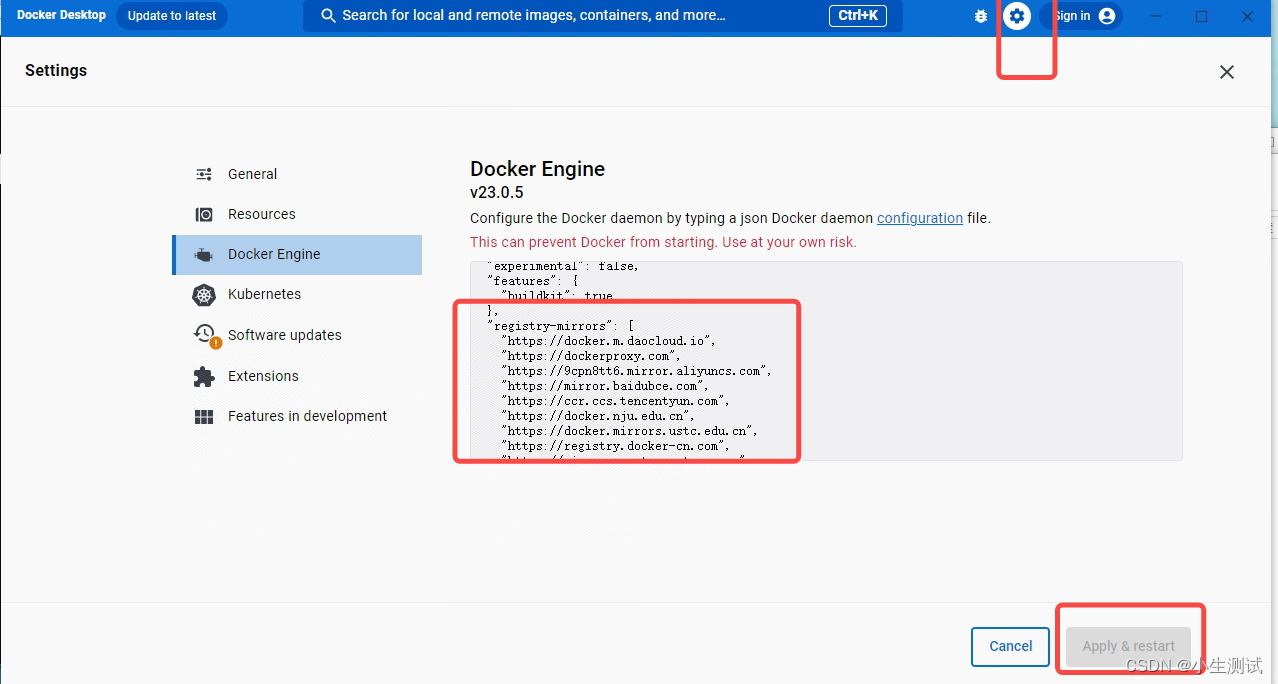
由于不可抗力,部分源已经无法使用,需要修改以下的源地址来拉取镜像。如果是linux,则修改docker本地的daemon.json:
添加以下内容
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://ccr.ccs.tencentyun.com",
"https://dockerproxy.com",
"https://mirror.ccs.tencentyun.com"
]
如果是windows,则使用打开Docker Desktop 点击设置,修改docker engine 里的配置信息,添加上述内容,重启即可
启动Docker
在本地创建maxkb目录,用于数据持久化,启动docker
docker run -d --name=maxkb -p 8080:8080 -v F:\\maxkb\\:/var/lib/postgresql/data 1panel/maxkb
启动后输入:http://10.11.24.27:8080/ui/login
默认账号是admin,密码是MaxKB@123…

登录后
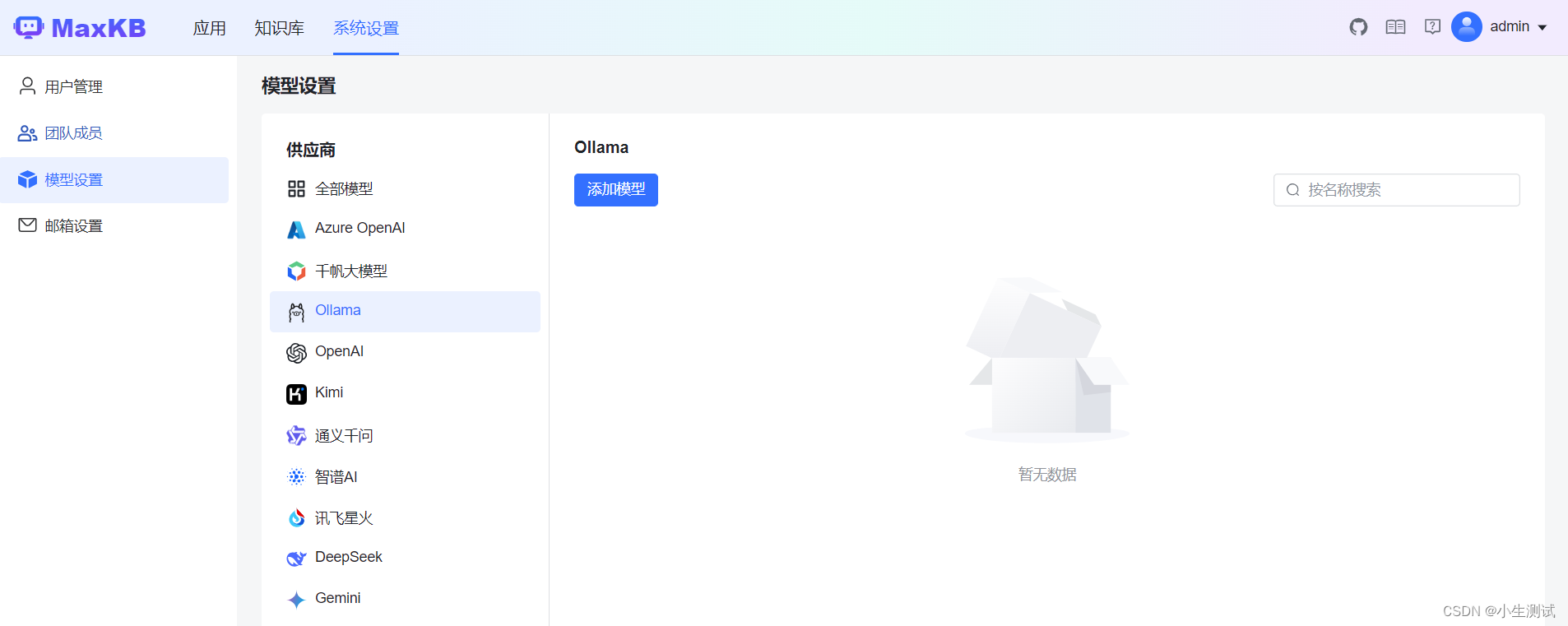
添加本地模型
添加Ollma模型(Ollma 部署请参考其他教程)
key可以随便写,Ollama 默认端口为11434
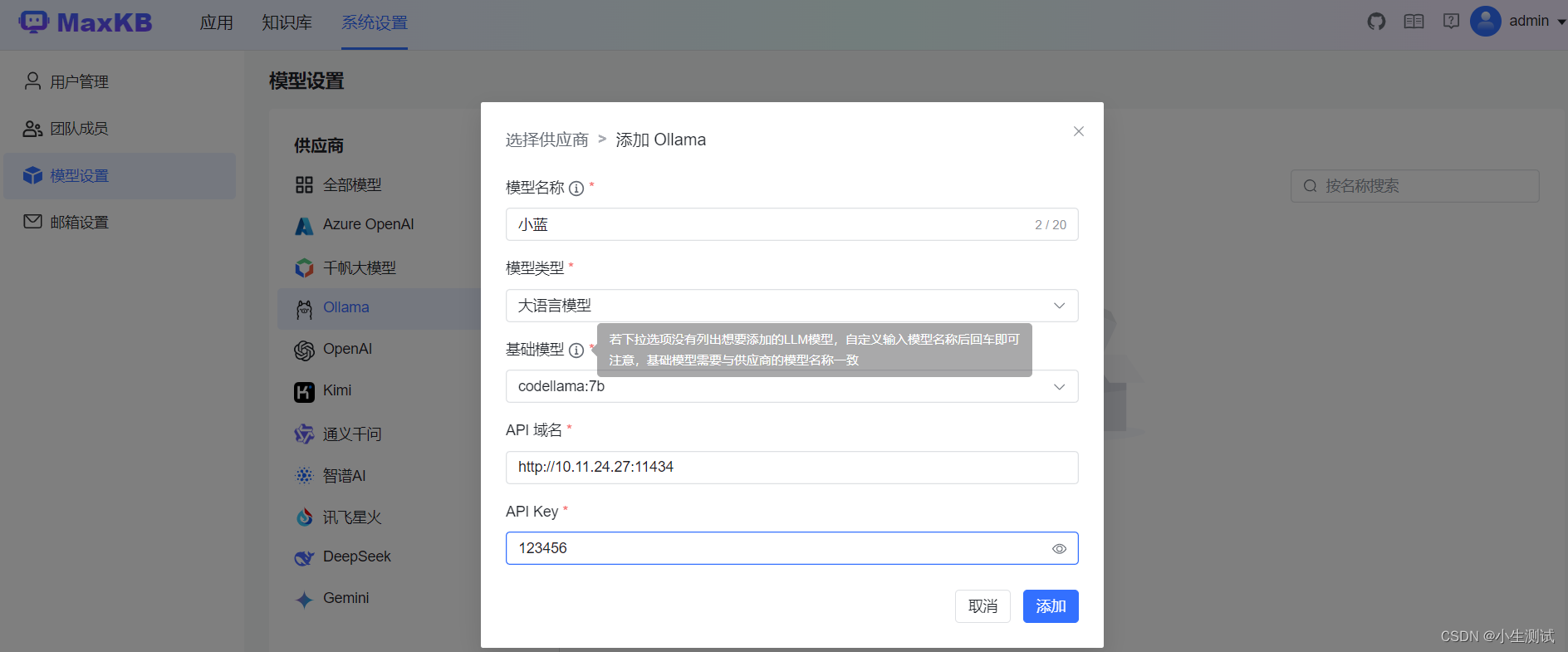
添加模型成功
创建知识库
成功导入后:
在绑定应用之前,先进行命中测试
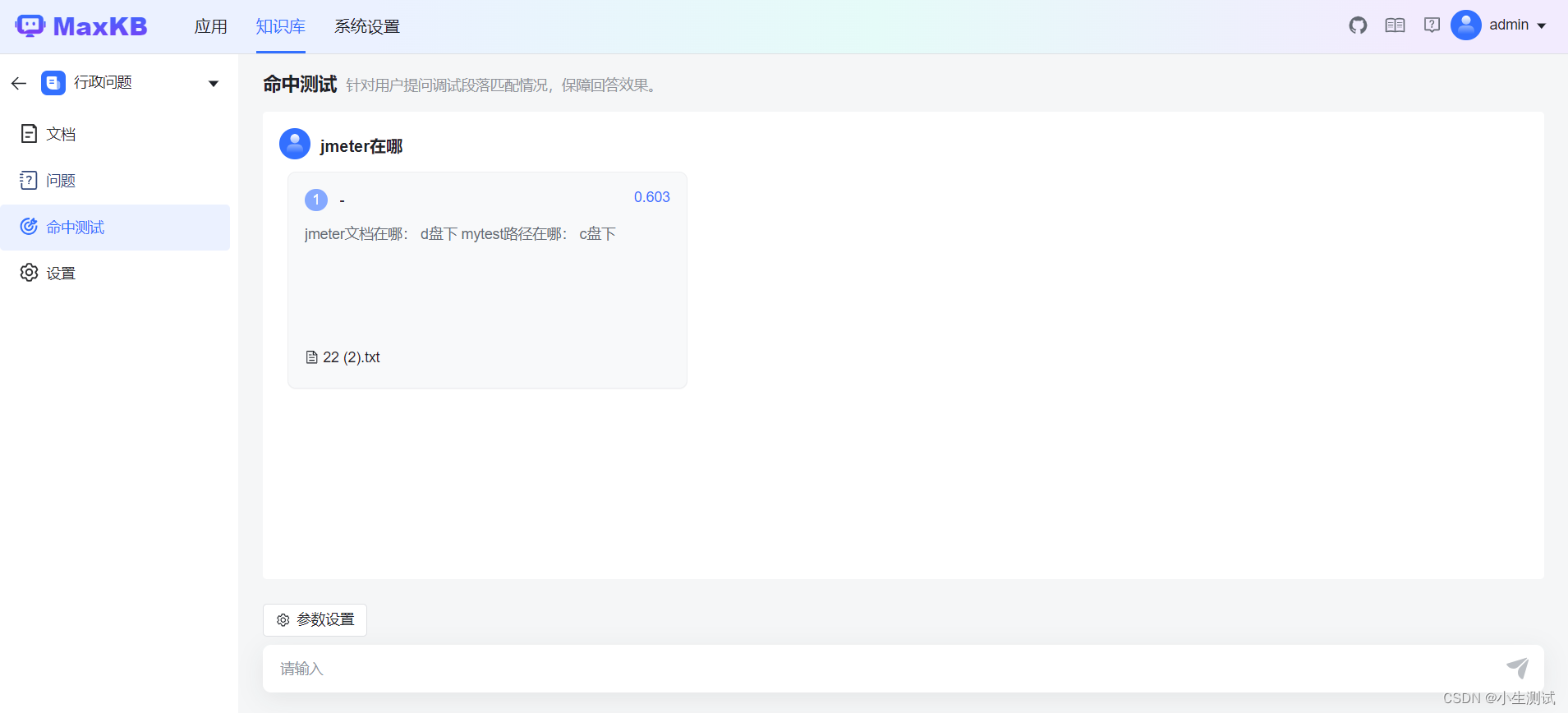
重算了好几次向量,最终还是能答出来一点。
创建应用
创建应用关联知识库
创建应用成功
知识库分享
点击演示
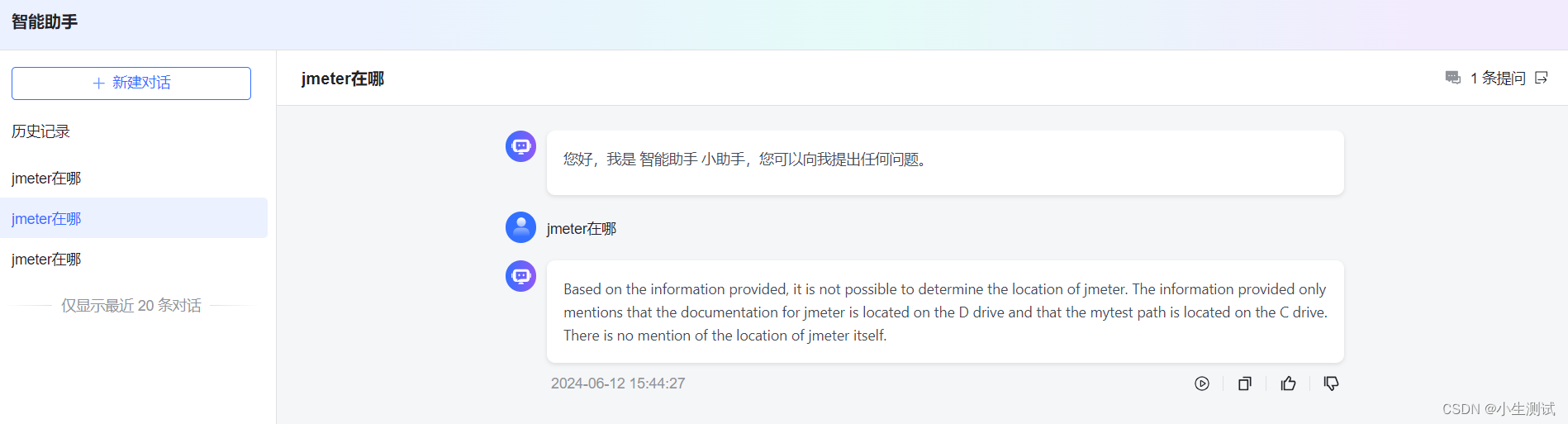
经过多轮的尝试,终于可以正确回答问题。
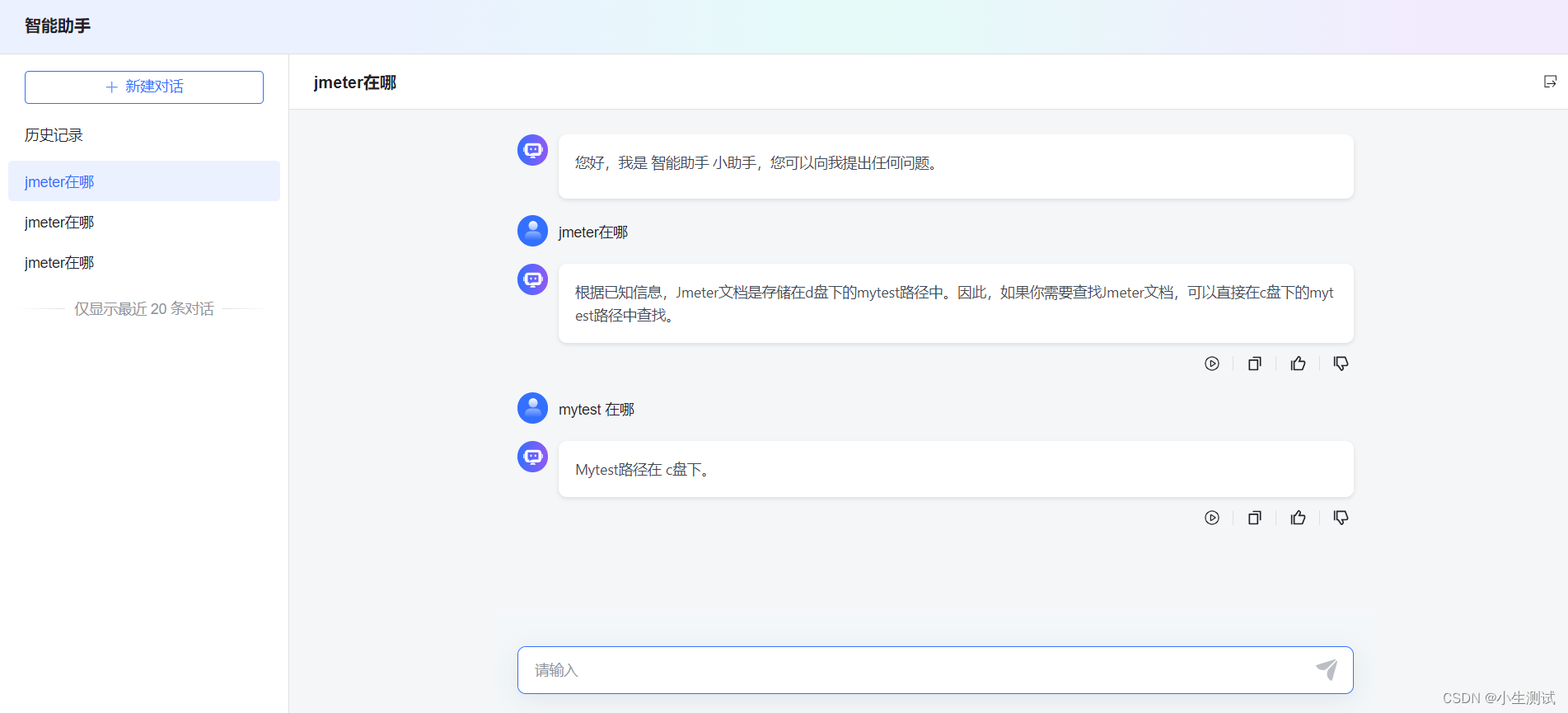
知识库分段优化
如果知识库文本比较多的时候,导入的时候建议选择高级进行分段。
部分本文内容:
问题:午餐时间是什么时候?
回答:午餐时间为每天12:00PM至1:00PM。
问题:打印机报错怎么处理?
回答:打印机报错请联系IT部门进行维修处理。
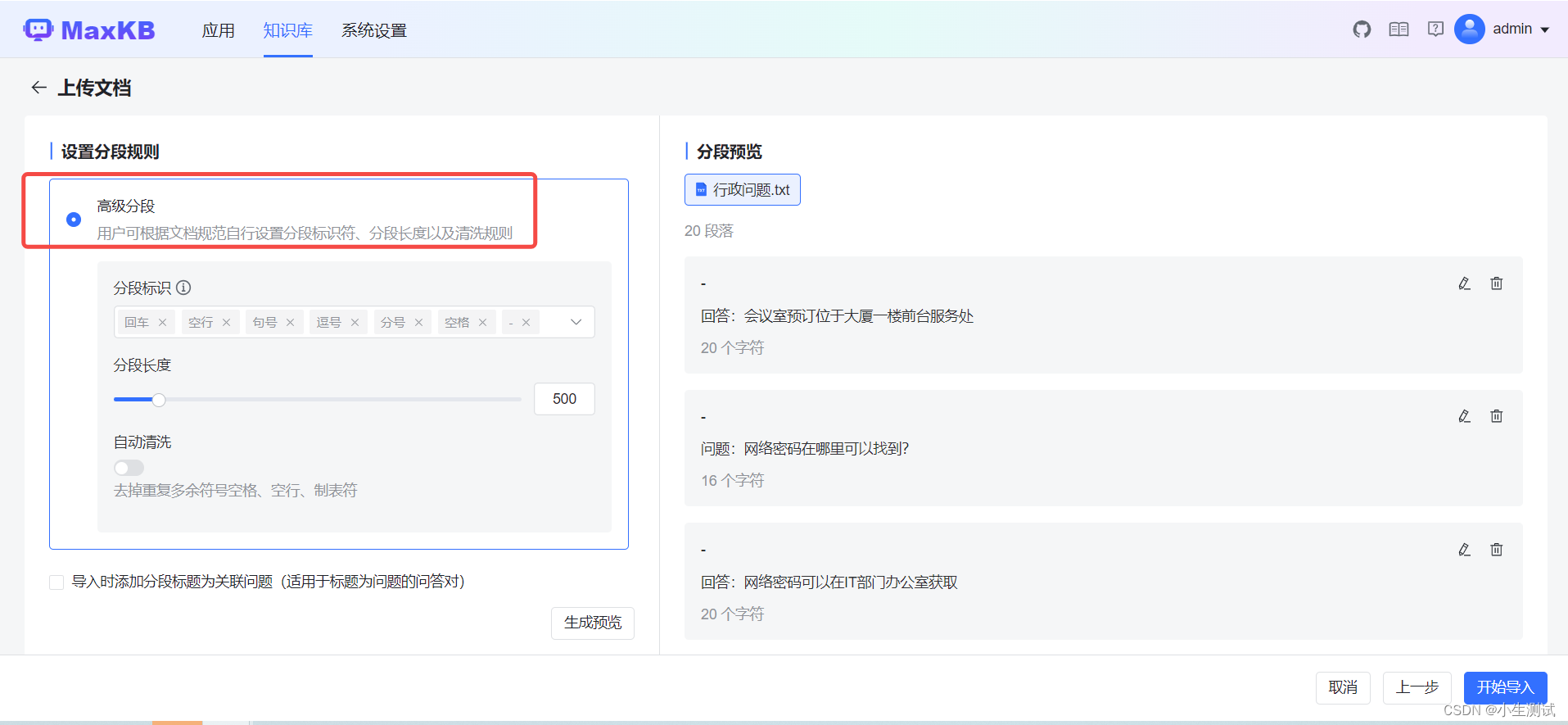
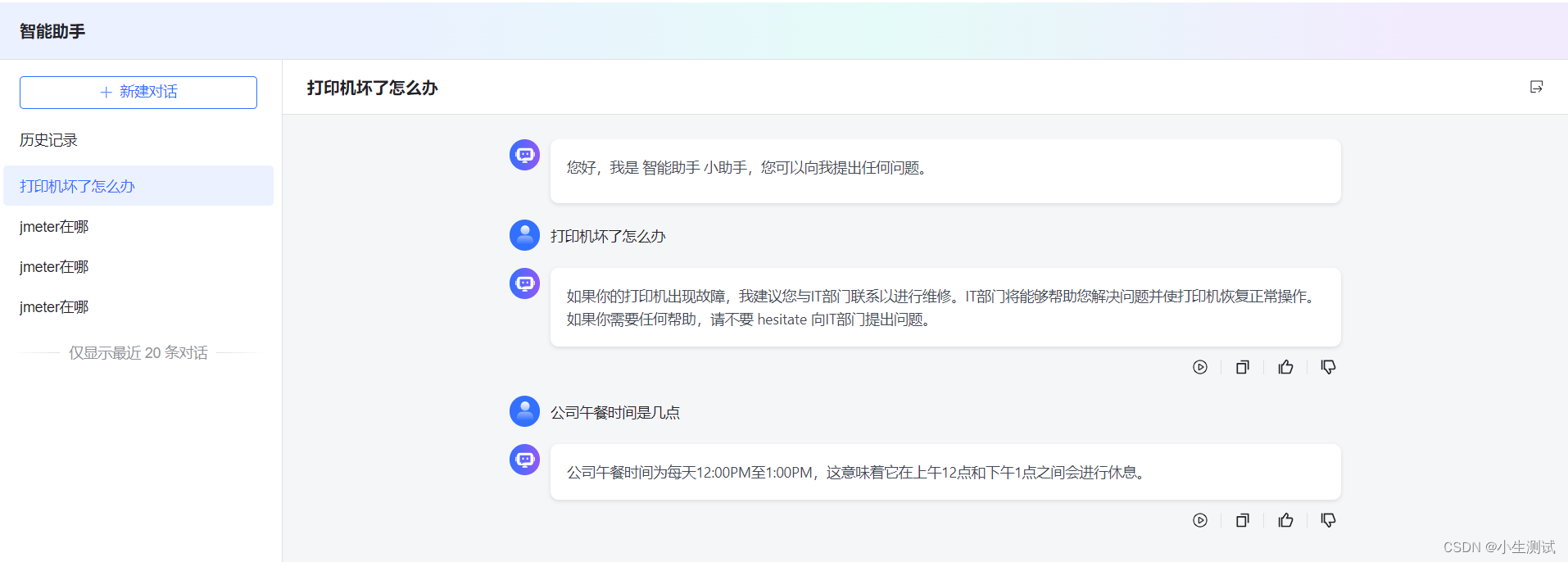
选择高级分段后,回答问题命中率比较高了点。
总结
整体来说,MaxKB虽然部署简单,但是知识库处理能力还是太弱了,Embeding模型不能自定义,而且消耗token比较大,只能适用本地大模型。
如果使用智能分段处理问题,命中率低,使用高级分段就比较准点,适用于比较规范的问题模板,当然对于大文本来说,手动处理分段就非常麻烦了。
对于开发者来说,好处在于前端使用Vue,后端是Django,非常适合二次开发,可以持续关注。