目录
一.认识磁盘
1.1磁盘的物理结构
1.2磁盘的存储结构
1.3磁盘的逻辑存储结构
二.理解文件系统
2.1如何管理磁盘
2.2如何在磁盘中找到文件
2.3关于文件名
哈喽,大家好。今天我们学习文件系统,我们之前在Linux基础IO中研究的是进程和被打开文件之间的关系,以及如何管理被打开的文件。那么,在磁盘中没有被打开的文件应该怎样管理呢?今天,我们一块研究一下。我们开始啦!

一.认识磁盘
磁盘作为硬件中的唯一一个机械结构,在计算机系统中的地位不言而喻,所以,我们有必要好好了解一下我们的磁盘。
1.1磁盘的物理结构
- 随着计算机的更新换代,我们现在的笔记本上很少见到磁盘了。取自换代的是固态硬盘(ssd)。所以固态硬盘也要相对贵一些。磁盘作为一个机械结构,并且是外设,这就决定了访问磁盘的速度是很慢的(相对于CPU或者内存)。
- 在企业中,磁盘依旧是存储的主流。因为:1.固态硬盘比较贵,磁盘相对来说比较便宜。2.磁盘的存储容量比较大,适合海量数据的存储。3.ssd有一个巨大的缺点:ssd如果传输次数过多,就会出现被击穿的情况,造成数据丢失;在企业中,高并发的情况非常常见,所以极其不适合在企业中使用。


磁盘是由很多盘片叠加在一起的。 一个盘片有两个盘面,每个盘面都可以读取数据,每个盘面都有磁头,盘片数=磁头数=盘面数*2
1.2磁盘的存储结构
在宏观的世界里,看起来盘面很光滑,但是在显微镜下,盘面是很粗糙的。
下面,先给大家介绍几个概念

- 在一个盘面中,以中间的马达为圆心,会存在很多的同心圆,这些同心圆叫做磁道。磁头在旋转的过程就是确认在哪一个磁道的过程。
- 磁盘中每一个磁道被等分为若干个相同的弧段,这些弧段便是磁盘的扇区,扇区是磁盘寻址的最小的单位。扇区的大小都是512字节。虽然距离圆心越远,扇区的长度越大,但是,我们可以使用存储的密度加以控制。使其存储的数据量相同,便于管理。盘片在旋转的过程就是确认在哪一个扇区的过程。
- 为了方便管理,我们可以对不同的磁道进行编号,然后在同一磁道下对不同扇区再进行编号。
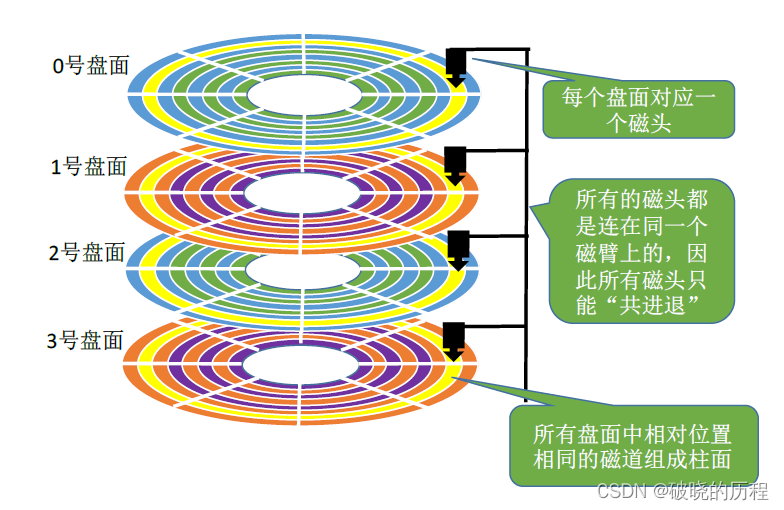
每个盘面对应一个磁头。所有的磁头都是连在同一个磁臂上的,因此所有磁头只能“共进退”。
所有盘面中相对位置相同的磁道组成
柱面。如上图,柱面的存在使得更为方便的找到每一块扇区。
如何在多块磁片中,定位到一块扇区呢?
先定位在哪一个磁盘(cylinder),也就是柱面(Track),再定位在哪一个盘面(head),最后定位扇区(sector)。我们可以定位任何一个扇区,也就可以定位任意多个扇区。
 磁盘中定义一个扇区,采用硬件的方式:CHS定位法。
磁盘中定义一个扇区,采用硬件的方式:CHS定位法。
1.3磁盘的逻辑存储结构
大家有没有见过磁带:

等待一盘磁带不用了,我们总是把里面黑色的磁带给扯出来,然后玩!磁带卷起来是圆形的(也是由很多同心圆构成的),扯出来是线性的。我们再看我们的磁盘,怎么和磁带这么相似呢?我们可以把整个磁盘全部抽象给一个线性结构。
磁盘物理上是一种圆形结构,我们可以想象成线性结构!如图:假设一块磁盘由2块盘片组成,所以就有4个盘面,一个盘面由7条磁盘构成,一个磁道又分成了8个沙区

就这样,我们把磁盘从逻辑上看做一个sector arr[4*7*8]的数组,所以由原来的对磁盘的管理变成了对数组的管理,这不就是我们常提到的先描述,再组织嘛!!
现在,这该死的磁盘已经被我们给想象成了一个数组,要找到一个扇区,该怎么找呢?
只要知道这个扇区的下标,就算定位了一个扇区。在操作系统内部,我们称这个下标为LBA地址(逻辑块地址)。
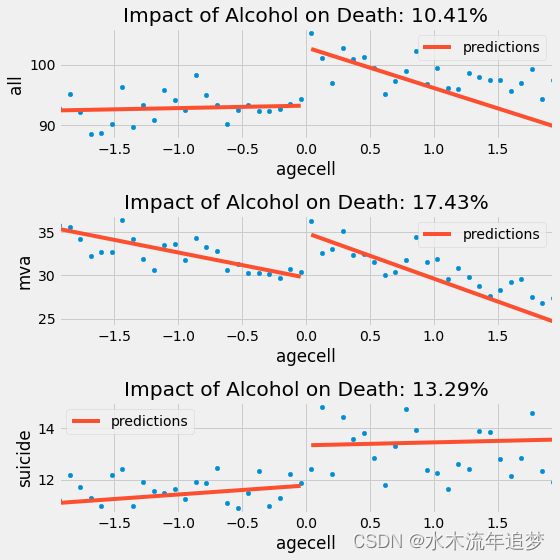
现在有一块磁盘,相关数据如下:问:LBA地址为123的扇区位置?

为什么OS要对存储结构做逻辑抽象呢?直接用CHS不可以吗?
- 便于管理。
- 不想让代码和硬件强耦合。
虽然磁盘访问的最小单位是512字节,但是依旧很小!OS内的文件系统定制的进行多个扇区的读取(一次读取4KB的数据)哪怕只想读取一个比特位,必须将4KBload到内存,进行读取或者读取。如果有必要再写回磁盘。这是一种以空间换时间的方式。
但这样,有时会显得非常浪费,比如我要读取的数据只有几个字节的大小,OS也要给我们一次性的读取4KB的数据。但这背后有一个原理叫做:局部性原理:从理论上证明了计算机要访问一段数据时,这段数据周围的数据也有较大的可能性被访问到。所以,真实的内存是以4KB为单位被操作系统读取的。磁盘中的文件(尤其是可执行文件),按4KB大小划分好的区域。
二.理解文件系统
2.1如何管理磁盘
假设一个磁盘为500GB。操作系统说:“卧槽,这么大,怎么管呀?”。 虽然难管,但是这点问题难不住我们的工程师。他们将整个磁盘分区,每个区分出100GB甚至更小的空间,然后对每个区进行分组,每组分出5GB的空间,就这样分下去,直到方便管理为止。虽然5GB的空间很小了,但是对于500GB来说这就是小巫见大巫。这种思想叫做分治思想。一个5GB的空间管理好了,然后对刮管理方法进行复制,不就管理好整个磁盘了嘛 !。
就像我们同学在学校一样:一位同学,必定属于哪一个宿舍,这件宿舍必定属于哪一个班级,这个班级必定是属于哪一个专业,这个专业必定是属于哪一个学院,这个学院一定属于学校。这不就是在利用分治思想来进行管理嘛!

文件=内容+属性,Linux下的内容和属性是分批存储的,但是一个未打开的文件的内容和属性信息都存储在哪里呢?
- 文件属性存储在Inode中,Inode是固定大小,一个人文件,一个Inode。一个文件的所有属性几乎都存储在Inode中,但是文件名并不存储在Inode中。
- 文件的内容存储在data block数据块中,数据块随着应用类型的变化,大小也会发生变化。
关于Inode属性集合
- 由于每个文件都有Inode,为了区分彼此,每个Inode都有自己的编号。编号是以组为单位进行编的。

那么,在Linux下,如何查看文件的inode编号呢?

inode table:
保存分组内部所有可用的(已经使用+没有使用)的inode。
Data blocks:
保存分组内部所有可用的(已经使用+没有使用)的数据快。
如果我们要创建一个文件,怎么办?
- 查找没有使用的Inode,然后把属性写入Inode中。
- 查找没有使用的数据块,然后把内容写入数据块。
所以,我们创建文件的过程,离不开查找。如何查找呢?
Inode Bitmap:
Inode对应的位图结构。假设inode一共有n个,位图结构中的比特位的个数至少也为n个。
位图中比特位的位置与当前文件的对应的ID是一一对应的,比特位的1和0表示是否被占用。
block Bitmap:
数据块对应的位图结构。位图中比特位的位置和当前data block对应的数据块的位置是一一对应的。
如果要知道inode一共有多少个,没有使用的是多少个,如果通过计算获取结果,效率太低了,这时Group Descriptor Table出现了。
Group Descriptor Table:
包含对应分组的宏观属性信息,包括:一共有多少个数据块,使用了多少;一共有多少个Inode,使用了多少等等。
Super Block
超级块(Super Block):存放文件系统本身的结构信息。
记录的信息主要有:bolck 和 inode 的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了。并且超级块通常在分组内多个组有一个超级块,在系统中是有一定比例的,假设我一个100G的分区有1000个分组,每20个分组就有一个super block,那么总共就有50个超级块。为什么需要这些超级块呢?本质上还是为了数据备份,如果某个块组或者inode丢失,那么就 可以通过super block来进行恢复。
2.2如何在磁盘中找到文件
查找一个文件,要通过Inode编号。
- 通过inode bitmap 查找对应的比特位的位置是1还是0
- 如果这个编号被占用,在inode Table找到这个Inode,然后确定一下是否是我们要查找的文件。
但是,如果我要得到这个文件的内容呢?
inode在内核中的结构如下:
struct inode {
umode_t i_mode;//文件的访问权限(eg:rwxrwxrwx)
unsigned short i_opflags;
kuid_t i_uid;//inode拥有者id
kgid_t i_gid;//inode拥有者组id
unsigned int i_flags;//inode标志,可以是S_SYNC,S_NOATIME,S_DIRSYNC等
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
#endif
const struct inode_operations *i_op;//inode操作
struct super_block *i_sb;//所属的超级快
/*
address_space并不代表某个地址空间,而是用于描述页高速缓存中的页面的一个文件对应一个address_space,一个address_space与一个偏移量能够确定一个一个也高速缓存中的页面。i_mapping通常指向i_data,不过两者是有区别的,i_mapping表示应该向谁请求页面,i_data表示被改inode读写的页面。
*/
struct address_space *i_mapping;
#ifdef CONFIG_SECURITY
void *i_security;
#endif
/* Stat data, not accessed from path walking */
unsigned long i_ino;//inode号
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
const unsigned int i_nlink;//硬链接个数
unsigned int __i_nlink;
};
dev_t i_rdev;//如果inode代表设备,i_rdev表示该设备的设备号
loff_t i_size;//文件大小
struct timespec i_atime;//最近一次访问文件的时间
struct timespec i_mtime;//最近一次修改文件的时间
struct timespec i_ctime;//最近一次修改inode的时间
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes;//文件中位于最后一个块的字节数
unsigned int i_blkbits;//以bit为单位的块的大小
blkcnt_t i_blocks;//文件使用块的数目
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;//对i_size进行串行计数
#endif
/* Misc */
unsigned long i_state;//inode状态,可以是I_NEW,I_LOCK,I_FREEING等
struct mutex i_mutex;//保护inode的互斥锁
//inode第一次为脏的时间 以jiffies为单位
unsigned long dirtied_when; /* jiffies of first dirtying */
struct hlist_node i_hash;//散列表
struct list_head i_wb_list; /* backing dev IO list */
struct list_head i_lru; /* inode LRU list */
struct list_head i_sb_list;//超级块链表
union {
struct hlist_head i_dentry;//所有引用该inode的目录项形成的链表
struct rcu_head i_rcu;
};
u64 i_version;//版本号 inode每次修改后递增
atomic_t i_count;//引用计数
atomic_t i_dio_count;
atomic_t i_writecount;//记录有多少个进程以可写的方式打开此文件
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct file_lock *i_flock;//文件锁链表
struct address_space i_data;
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS];//inode磁盘限额
#endif
/*
公用同一个驱动的设备形成链表,比如字符设备,在open时,会根据i_rdev字段查找相应的驱动程序,并使i_cdev字段指向找到的cdev,然后inode添加到struct cdev中的list字段形成的链表中
*/
struct list_head i_devices;,
union {
struct pipe_inode_info *i_pipe;//如果文件是一个管道则使用i_pipe
struct block_device *i_bdev;//如果文件是一个块设备则使用i_bdev
struct cdev *i_cdev;//如果文件是一个字符设备这使用i_cdev
};
__u32 i_generation;
#ifdef CONFIG_FSNOTIFY
//目录通知事件掩码
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct hlist_head i_fsnotify_marks;
#endif
#ifdef CONFIG_IMA
atomic_t i_readcount; /* struct files open RO */
#endif
//存储文件系统或者设备的私有信息
void *i_private; /* fs or device private pointer */
};
其中,有一个关于数组块的数组,data block block[15]。

这个数组元素的个数是固定的。但并表示这个文件可以写入的数据量是一定的。如图:每一个数据块都有自己的编号,这个数组中存放的就是该文件所使用的数据块的编号,通过这个数组就可以实现我们查找内容的行为。虽然只有15元素,但并不代表我们仅可以使用15个数据块。从下表为12的元素开始,所指向的数据块里边保存的是其他数据块的编号,下一级数据块中的内容可以使下下一级数据块的编号。如此,就可以增加我们可使用数据块的个数。为了便于大家理解,做如下图:

所以,我们就顺利完成了文件的查找工作,那么,如何删除一个文件呢?
删除文件就太简单了,只需要找到这个文件,然后将这个文件的Inode编号对应的比特位由1置为0就可以了。然后将block bitmap由1置为0就可以了。(惰性删除)
这里并没有直接删除数据块,所以Linux下删除是可以恢复的。
2.3关于文件名

这是什么鬼?我们不是说可以根据inode编号查找文件嘛,这里为什么不可以使用编号查找呀 ?
我们说:Linux下一切皆是文件。其实,目录本身就是一个文件,文件的属性容易理解,但是,文件的内容是什么呢?
目录文件的内容就是编号和文件名之间的映射关系,所以,我们之前提到再inode中不需要存储文件名。记录文件名是目录的事情。
写到最后,因水平有限,文中难免会出现错误,请各位大佬指正!!




![[图解]建模相关的基础知识-09](https://img-blog.csdnimg.cn/direct/564084005134496695a01330e896bda1.png)