说明
最近整体进展还比较顺利,不过也因为这样,好几个线头怎么继续平衡和推进需要稍微捋一下。
内容
按重要|紧急方法来看,线头1是重要且紧急的,QTV200也算重要且紧急,其他都算是重要不紧急。
线头1: 数据清洗
虽然用到的技术相对麻烦一点,但还算是数据清洗的内容。业务和某个具体的模型/算法并不是我最关注,在这个项目上我更关心方法与架构。
在这个项目里,方法上要求了模式-模型二级法,这也是之前一直想做的内容,这也可以使QTV200的决策能力提升一个层级。在架构上,很巧的也需要用到之前构想的数据流才能更好的处理。这既有开发上的,也有执行效率上的点。
模式部分,所需要区分的模式我已经标完。这里一个体会是,首先要将特征离散化,然后才好标记模式。离散化本身可能设计到较为复杂的算法,例如HMM。实时上通过这几天也证明了,一般性数据至少有50%是可以非常快穷举出来快速处理的,而不必走大模型。
架构部分,因为之前的积累,所以这次很快就完成了连通性测试,这样也比较容易赶得上接下来的进度。
本次使用了Redis和ClickHouse两种数据库,用于做队列和持久化。由MongoEngine管理任务对象,而Flask-APS-Celery负责流的定义和执行。
还需要做的部分:在进行开发测试的同时,将数据准备好
- 1 在4090主机上建立数据流环境,后续可能需要持续使用1个月
- 2 算网主机上,从clickhouse中分批取出数据,向4090发起持续的数据请求。写入stream1_in
- 3 worker1: 从stream1_in中取数,先将数据进行UCS编号后存4090ch,同时将数据同步写入stream2_in(test),如果不能写入直接抛弃
- 4 worker2 :从stream2_in中取数,进行模式识别,然后将结果分发到二级队列(目前有11个队列),对应的工作是将最近的模式识别程序封装为类似程序包的格式(现在十几个模式识别处理放在一个程序里太冗长了)stream2_tier2_in
- 5 worker3s: 在多个队列下分别进行开发,然后进行调度。结果写入stream2_tier2_out
- 6 worker4: 将stream2_tier2_out的结果汇聚到stream2_out
- 7 worker5: 将stream2_out写到ch进行持久化。
这里会涉及到大量任务设置与调度执行,可以让我更快的完成数据流体系的磨合。另外就是看数据迁移这一块了,如何在ch中设置字段,然后将数据从节点A挪到节点B。
线头2:QTV200
这个是我最期望月底能完成的项目,具有特别重要的意义。
第一步是要建立数据流,从源头上重新
目前把之前的采集程序找到了,本来运行的也没有问题,不过现在转入数据流方法,使用Flask-APS-Celery来进行效率更高的取数。
先尽快把数据流搭好,然后把VV部署为服务。
线头3:GLM4
前不久智谱也开源了GLM4,我相信在Function Call上,应该能初步满足我的要求了
这个再等一等吧,写在这就不会忘了。
线头4:强化学习
开了个头,但没有时间把里面的内容钻一遍
总之,强化学习框架是我下一阶段的主要方法,本身也是设想在QTV200阶段开始应用的。试着跑了一下,看起来是我要的样子,在算力极大丰富的情况下,用分布式强化是非常合适的,机器再也不会有闲着的时候了。做一些有意义的算法,让算力燃烧在对的地方是我的理想。
在conda3下安装包 rllib, 需要pytorch
pip3 install ray[tune] -i https://mirrors.aliyun.com/pypi/simple/
pip3 install gymnasium -i https://mirrors.aliyun.com/pypi/simple/
pip3 install dm_tree -i https://mirrors.aliyun.com/pypi/simple/
pip3 install typer -i https://mirrors.aliyun.com/pypi/simple/
pip3 install scikit-image -i https://mirrors.aliyun.com/pypi/simple/
# 会自己下载并安装对应的gpu版本包 | 很大,最好留够十个G
pip3 install torch -i https://mirrors.aliyun.com/pypi/simple/
Downloading https://mirrors.aliyun.com/pypi/packages/b6/9f/c64c03f49d6fbc56196664d05dba14e3a561038a81a638eeb47f4d4cfd48/nvidia_cuda_nvrtc_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (23.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 23.7/23.7 MB 777.5 kB/s eta 0:00:00
Collecting nvidia-cuda-runtime-cu12==12.1.105 (from torch)
Downloading https://mirrors.aliyun.com/pypi/packages/eb/d5/c68b1d2cdfcc59e72e8a5949a37ddb22ae6cade80cd4a57a84d4c8b55472/nvidia_cuda_runtime_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (823 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 823.6/823.6 kB 786.7 kB/s eta 0:00:00
Collecting nvidia-cuda-cupti-cu12==12.1.105 (from torch)
Downloading https://mirrors.aliyun.com/pypi/packages/7e/00/6b218edd739ecfc60524e585ba8e6b00554dd908de2c9c66c1af3e44e18d/nvidia_cuda_cupti_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (14.1 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 14.1/14.1 MB 859.9 kB/s eta 0:00:00
Collecting nvidia-cudnn-cu12==8.9.2.26 (from torch)
Downloading https://mirrors.aliyun.com/pypi/packages/ff/74/a2e2be7fb83aaedec84f391f082cf765dfb635e7caa9b49065f73e4835d8/nvidia_cudnn_cu12-8.9.2.26-py3-none-manylinux1_x86_64.whl (731.7 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╸ 723.9/731.7 MB 829.6 kB/s eta 0:00:10
import ray
from ray import tune
from ray.rllib import train
# 初始化Ray
ray.init()
# 运行一个简单的PPO算法示例
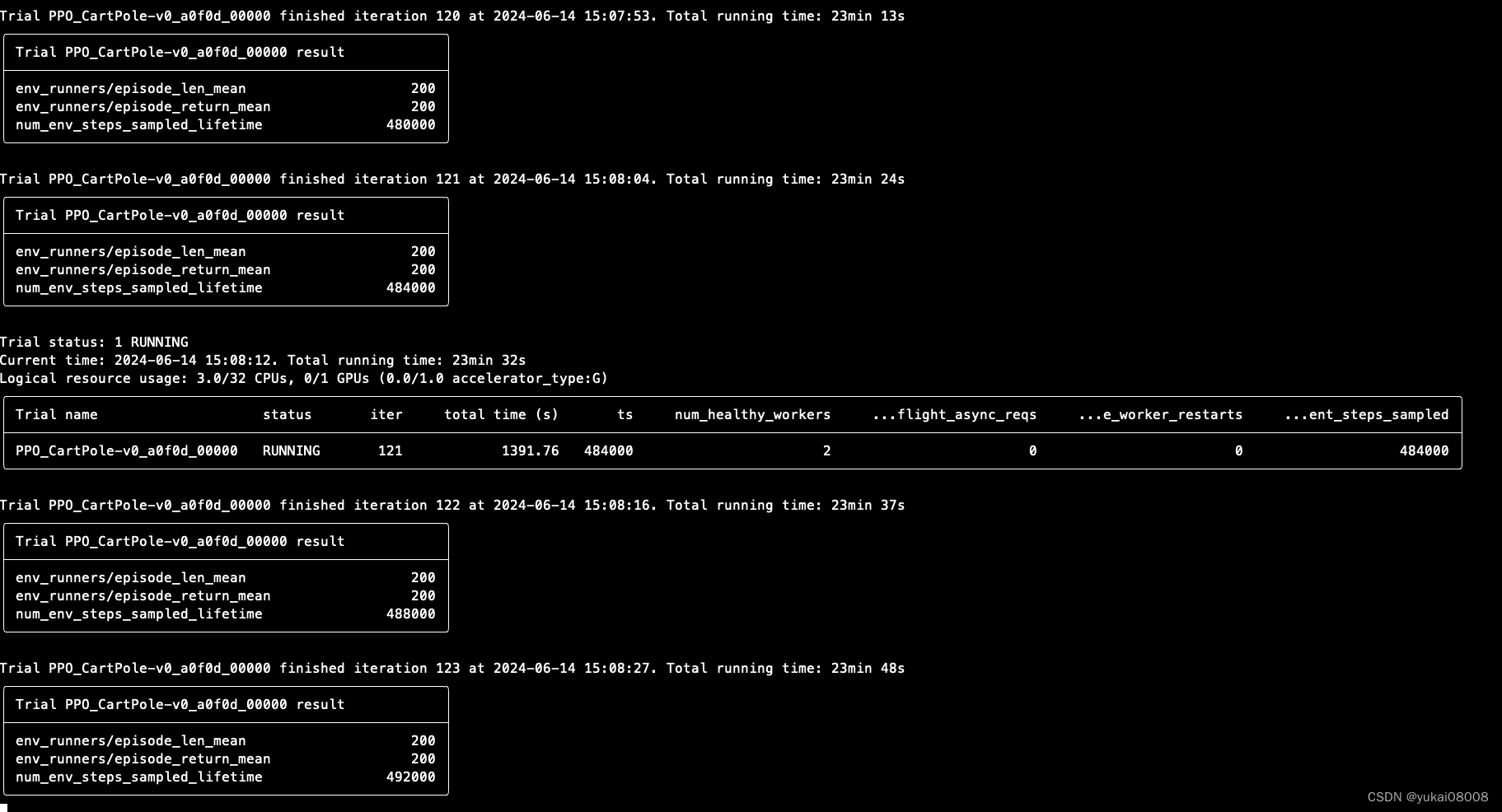
tune.run("PPO", config={"env": "CartPole-v0"})
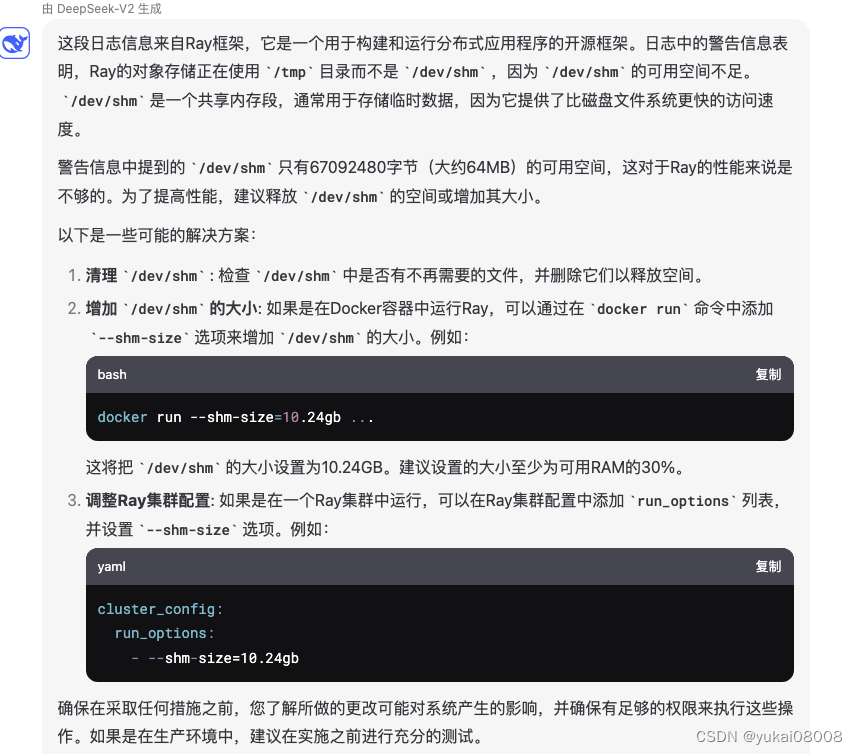
2024-06-14 14:44:30,330 WARNING services.py:2009 -- WARNING: The object store is using /tmp instead of /dev/shm because /dev/shm has only 67092480 bytes available. This will harm performance! You may be able to free up space by deleting files in /dev/shm. If you are inside a Docker container, you can increase /dev/shm size by passing '--shm-size=10.24gb' to 'docker run' (or add it to the run_options list in a Ray cluster config). Make sure to set this to more than 30% of available RAM.
2024-06-14 14:44:30,449 INFO worker.py:1753 -- Started a local Ray instance.

线头5:遗传算法
正好有一个场景可以开始这个实践
可以先这么干,把要做的随机任务先发到RabbitMQ,然后算力机使用不同模型和数据进行随机训练打分。
然后,使用遗传算法优化随机选取的效率。