16.番外:模拟c语言文件流
一,前言
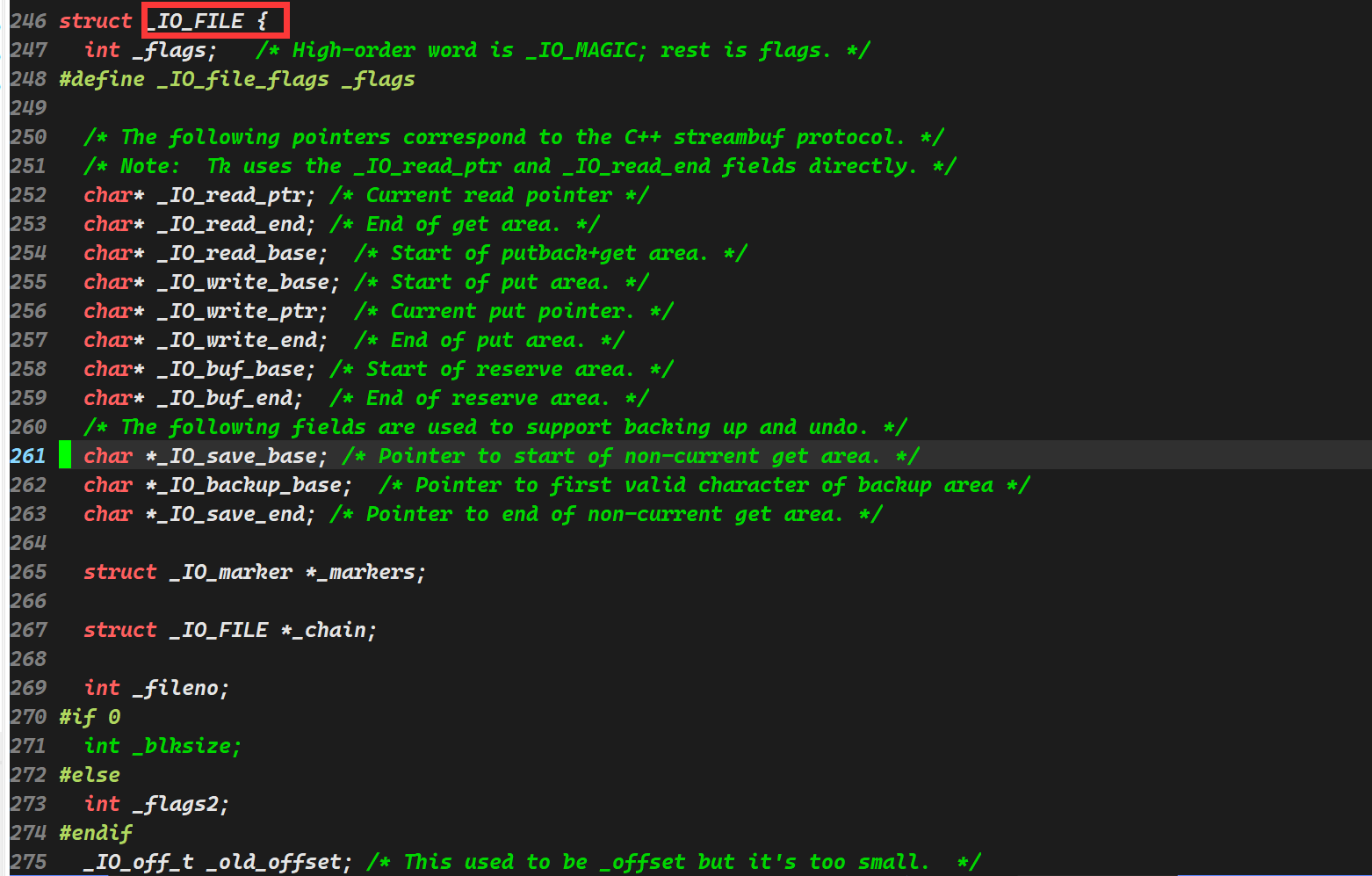
先来看一下Struct _IO_FILE的定义。
grep -rnw '/usr/include/' -e 'struct _IO_FILE'
今天我们要做的就是模拟实现FILE及C语言文件操作相关函数
二,开始!做吧!我们!
1.FILE的缓冲区及冲刷方式
大小设置为1024刷新方式选择行缓冲
为了方便对缓冲区进行控制,需要下标_current,最重要的描述符_fd。
#define BUFFER_SIZE 1024 //缓冲区大小
//通过位图的方式,控制刷新方式
#define BUFFER_NONE 0x1 //无缓冲
#define BUFFER_LINE 0x2 //行缓冲
#define BUFFER_ALL 0x4 //全缓冲
typedef struct MY_FILE
{
char _buffer[BUFFER_SIZE]; //缓冲区
size_t _current; //缓冲区下标
int _flush; //刷新方式,位图结构
int _fd; //文件描述符
}MY_FILE;
2.函数需求分析
1.**fopen** 打开文件
以多种方式打开,若是以读方式打开时,文件不存在会报错
2.**fclose** 关闭文件
根据 FILE* 关闭指定文件,不能重复关闭
3.**fflush** 进行缓冲区刷新
进行手动刷新
4.**fwrite** 对文件中写入数据
对文件中写入指定数据,一般是借助缓冲区进行写入
5.**fread** 读取文件数据
读取文件数据,同理一般是借助缓冲区先进行读取
3.文件打开
MY_FILE *my_fopen(const char *path, const char *mode); //打开文件
-
根据传入的mode确定打开方式
-
使用系统接口open打开文件
-
返回创建好的MY_FILE 类型的指针
-
初始化各项参数
文件打开失败的情况:权限不对/open失败/malloc失败,失败就返回NULL
O_RDONLY //只读
O_WRONLY //只写
O_APPEND //追加
O_CREAT //新建
O_TRUNC //清空
那么读:O_RDONLY
读+:O_RDONLY | O_WRONLY
写:O_WRONLY | O_CREAT | O_TRUNC
写+:O_WRONLY | O_CREAT | O_TRUNC | O_RDONLY
追加:O_WRONLY | O_CREAT | O_APPEND
追加+:O_WRONLY | O_CREAT | O_APPEND | O_RDONLY
会发现写和追加都有O_WRONLY | O_CREAT,我们放在一起处理。
我们想使用这个可以使用按位或来进行得到!
// 打开文件
MY_FILE *my_fopen(const char *path, const char *mode)
{
assert(path && mode);
// 确定打开方式
int flags = 0; // 打开方式
// 读:O_RDONLY 读+:O_RDONLY | O_WRONLY
// 写:O_WRONLY | O_CREAT | O_TRUNC 写+:O_WRONLY | O_CREAT | O_TRUNC | O_RDONLY
// 追加: O_WRONLY | O_CREAT | O_APPEND 追加+:O_WRONLY | O_CREAT | O_APPEND | O_RDONLY
// 注意:不考虑 b 二进制读写的情况
if (*mode == 'r')
{
flags |= O_RDONLY;
if (strcmp("r+", mode) == 0)
flags |= O_WRONLY;
}
else if (*mode == 'w' || *mode == 'a')
{
flags |= (O_WRONLY | O_CREAT);
if (*mode == 'w')
flags |= O_TRUNC;
else
flags |= O_APPEND;
if (strcmp("w+", mode) == 0 || strcmp("a+", mode) == 0)//如果出现了+号的情况
flags |= O_RDONLY;
}
else
{
// 无效打开方式
assert(false);
}
// 根据打开方式,打开文件
// 注意新建文件需要设置权限
int fd = 0;
if (flags & O_CREAT)
fd = open(path, flags, 0666);
else
fd = open(path, flags);
if (fd == -1)
{
// 打开失败的情况
return NULL;
}
// 打开成功了,创建 MY_FILE 结构体,并返回
MY_FILE *new_file = (MY_FILE *)malloc(sizeof(MY_FILE));
if (new_file == NULL)
{
// 此处不能断言,需要返回空
close(fd); // 需要先把 fd 关闭
perror("malloc FILE fail!");
return NULL;
}
// 初始化 MY_FILE
memset(new_file->_buffer, '\0', BUFFER_SIZE); // 初始化缓冲区
new_file->_current = 0; // 下标置0
new_file->_flush = BUFFER_LINE; // 行刷新
new_file->_fd = fd; // 设置文件描述符
return new_file;
}
4.文件关闭
int my_fclose(MY_FILE *fp); //关闭文件
// 关闭文件
int my_fclose(MY_FILE *fp)
{
assert(fp);
// 刷新残余数据
if (fp->_current > 0)
my_fflush(fp);
// 关闭 fd
int ret = close(fp->_fd);
// 释放已开辟的空间
free(fp);
fp = NULL;
return ret;
}
5.缓冲区刷新
// 缓冲区刷新
int my_fflush(MY_FILE *stream)
{
assert(stream);
// 将数据写给文件
int ret = write(stream->_fd, stream->_buffer, stream->_current);
//wirte函数将buffer里的内容写入fd标识的文件中
//stream->_current 是缓冲区下标,表示缓冲区中有效数据的字节数
//(从缓冲区的开始到 _current 下标的内容是有效数据)
stream->_current = 0; // 每次刷新后,都需要清空缓冲区
fsync(stream->_fd); // 将内核中的数据强制刷给磁盘(文件)
if (ret != -1) return 0;
else return -1;
}
内核缓冲区的刷新:在现代操作系统中,文件写操作通常会先写入内核缓冲区,然后再批量写入磁盘。这种机制提高了写操作的效率,但也带来了数据丢失的风险。fsync 可以强制将内核缓冲区中的数据写入磁盘,减少数据丢失的风险。
6.文件写入
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream); //数据写入
-
判断当前用户级缓冲区是否满载,如果满了,需要先刷新,再进行后续操作
if (stream->_current == BUFFER_SIZE)
my_fflush(stream);
2.获取用户想写入的字节数,和缓冲区剩余的可用空间
size_t user_size = size * nmemb; // 用户想写入的字节数
size_t my_size = BUFFER_SIZE - stream->_current; // 缓冲区中剩余可用空间
size_t writen = 0; // 成功写入数据的大小
3.如果缓冲区剩余大小ok,那么直接进行copy
if (my_size >= user_size)
{
// 直接可用全部写入
memcpy(stream->_buffer + stream->_current, ptr, user_size);
stream->_current += user_size;
writen = user_size;
}
4.当缓冲区的大小不足时
else
{
// 一次写不完,需要分批写入
size_t tmp = user_size; // 用于定位 ptr 的读取位置
while (user_size > my_size)
{
// 一次写入 my_size 个数据。user_size 会减小
1.memcpy(stream->_buffer + stream->_current, ptr + (tmp - user_size), my_size);
2.stream->_current += my_size; // 切记实时更新下标
3.my_fflush(stream); // 写入后,刷新缓冲区
4.user_size -= my_size;
5.my_size = BUFFER_SIZE - stream->_current;
}
// 最后空间肯定足够,再把数据写入缓冲区中
6.memcpy(stream->_buffer + stream->_current, ptr + (tmp - user_size), user_size);
7.stream->_current += user_size;
8.writen = tmp;
}
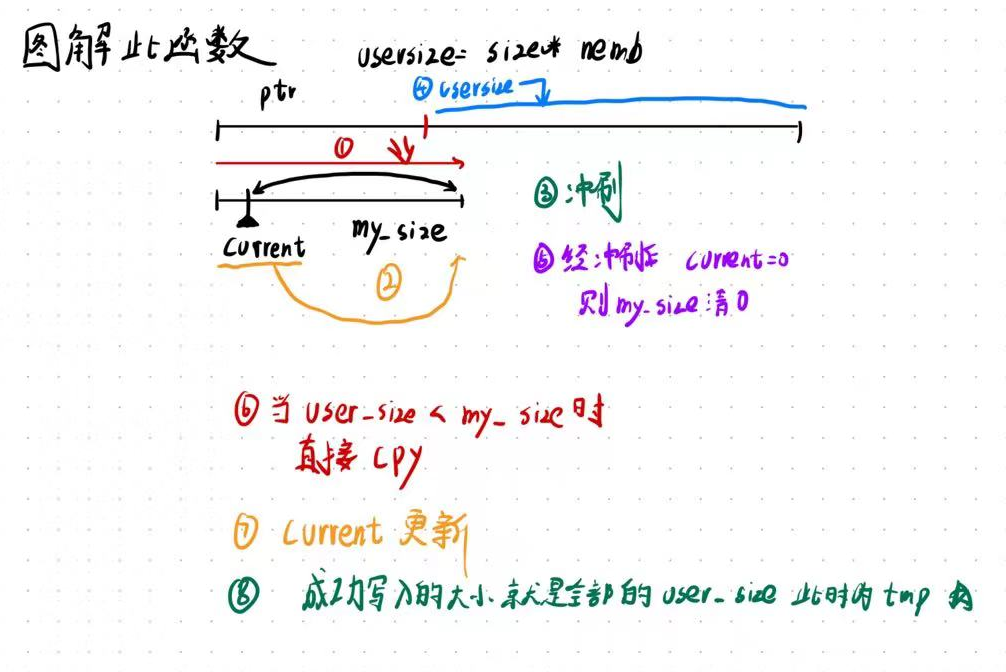
5.通过刷新方式来判断是否进行刷新
// 通过刷新方式,判断是否进行刷新
if (stream->_flush & BUFFER_NONE)
{
// 无缓冲,直接冲刷
my_fflush(stream);
}
else if (stream->_flush & BUFFER_LINE)
{
// 行缓冲,遇见 '\n' 才刷新
if (stream->_buffer[stream->_current - 1] == '\n')
my_fflush(stream);
}
else
{
// 全缓冲,满了才刷新
if (stream->_current == BUFFER_SIZE)
my_fflush(stream);
}
6.简化,返回用户实际写入的字节数
// 为了简化,这里返回用户实际写入的字节数,即 user_size
return writen;
8.总结:
// 数据写入
size_t my_fwrite(const void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
{
// 写入先判断缓冲区是否已满
if (stream->_current == BUFFER_SIZE)
my_fflush(stream);
size_t user_size = size * nmemb; // 用户想写入的字节数
size_t my_size = BUFFER_SIZE - stream->_current; // 缓冲区中剩余可用空间
size_t writen = 0; // 成功写入数据的大小
if (my_size >= user_size)
{
// 直接可用全部写入
memcpy(stream->_buffer + stream->_current, ptr, user_size);
stream->_current += user_size;
writen = user_size;
}
else
{
// 一次写不完,需要分批写入
size_t tmp = user_size; // 用于定位 ptr 的读取位置
while (user_size > my_size)
{
// 一次写入 my_size 个数据。user_size 会减小
memcpy(stream->_buffer + stream->_current, ptr + (tmp - user_size), my_size);
stream->_current += my_size; // 切记实时更新下标
my_fflush(stream); // 写入后,刷新缓冲区
user_size -= my_size;
my_size = BUFFER_SIZE - stream->_current;
}
// 最后空间肯定足够,再把数据写入缓冲区中
memcpy(stream->_buffer + stream->_current, ptr + (tmp - user_size), user_size);
stream->_current += user_size;
writen = tmp;
}
// 通过刷新方式,判断是否进行刷新
if (stream->_flush & BUFFER_NONE)
{
// 无缓冲,直接冲刷
my_fflush(stream);
}
else if (stream->_flush & BUFFER_LINE)
{
// 行缓冲,遇见 '\n' 才刷新
if (stream->_buffer[stream->_current - 1] == '\n')
my_fflush(stream);
}
else
{
// 全缓冲,满了才刷新
if (stream->_current == BUFFER_SIZE)
my_fflush(stream);
}
// 为了简化,这里返回用户实际写入的字节数,即 user_size
return writen;
}
7.数据读取
size_t my_fread(void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
在进行数据读取时,需要经历 文件->内核级缓冲区->用户级缓冲区->目标空间 的繁琐过程,并且还要考虑 用户级缓冲区是否能够一次读取完所有数据,若不能,则需要多次读取.
目标:这个函数将读取的数据写入到了ptr上,void*ptr指向用户缓冲区的指针,用于存储读取的数据。
TIP:
-
读取前,如果用户级缓冲区中有数据的话,需要先将数据刷新给文件,方便后续进行操作.
-
读取与写入不同,读取结束后,需要考虑
**\0**的问题(在最后一个位置加),如果不加的话,会导致识别错误;系统(内核)不需要**\0**,但C语言中的字符串结尾必须加**\0**,现在是 系统->用户(C语言)
实现函数:
// 数据读取
size_t my_fread(void *ptr, size_t size, size_t nmemb, MY_FILE *stream)
{
// 数据读取前,需要先把缓冲区刷新
if (stream->_current > 0)
my_fflush(stream);
size_t user_size = size * nmemb;//读取用户需要的大小
size_t my_size = BUFFER_SIZE;//读取缓存区大小
// 先将数据读取到FILE缓冲区中,再赋给 ptr
if (my_size >= user_size)
{
// 此时缓冲区中足够存储用户需要的所有数据,只需要读取一次
//从文件中读取my_size个字符到缓存区中
read(stream->_fd, stream->_buffer, my_size);
memcpy(ptr, stream->_buffer, my_size);
//将内核缓冲区(buffer)的数据复制到用户提供的缓冲区(ptr)中
*((char *)ptr + my_size) = '\0';
//(char *)将ptr强制转换为指向字符类型的指针,这一步的操作目的是让解引用后的位置赋值为字符串终止符‘\0’
//确保用户提供的缓冲区以字符串终止符结尾
//为什么-1,比如说读取了2个,0+2=2 0空间存储了一个东西 1
}
//需要反复读的情况,内核缓存区容量不够
else
{
int ret = 1;
size_t tmp = user_size;
while (ret)
{
// 一次读不完,需要多读取几次
1.ret = read(stream->_fd, stream->_buffer, my_size);
2.memcpy(ptr + (tmp - user_size), stream->_buffer, my_size);
3.stream->_current = 0;
4.user_size -= my_size;
}
*((char *)ptr + my_size) = '\0';
}
size_t readn = strlen(ptr);
return readn;
}
8.实现
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <unistd.h>
int main()
{
//打开文件,写入一段话
FILE* fp = fopen("log.txt", "w+");
assert(fp);
char inPutBuff[512] = "2110年1月1日,距离地球能源完全枯竭还有3650天。为了解决地球能源危机,\n人类制造了赛尔机器人和宇宙能源探索飞船赛尔号,去寻找神秘精灵看守的无尽能源。";
int n = fwrite(inPutBuff, 1, strlen(inPutBuff), fp);
printf("本次成功写入 %d 字节的数据", n);
fclose(fp);
printf("\n==============================\n");
//重新打开文件
fp = fopen("log.txt", "r");
assert(fp);
char outPutBuff[512] = { '\0' };
n = fread(outPutBuff, 1, sizeof(outPutBuff), fp);
printf("本次成功读取 %d 字节的数据,具体内容为: \n%s\n", n, outPutBuff);
fclose(fp);
fp = NULL;
return 0;
}
三,升华提升
printf和scanf的原理
printf
1.根据格式读取数据,如整型、浮点型,并将其转为字符串
2.定义缓冲区,然后将字符串写入缓冲区(stdout)
3.最后结合一定的刷新策略,将数据进行冲刷
scanf
1.读取数据至缓冲区(stdin)
2.根据格式将字符串扫描分割,存入字符指针数组
3.最后将字符串转为对应的类型,赋值给相应的变量